1. 調査の趣旨・目的
ビッグデータ処理に用いられている、ラムダアーキテクチャについて理解する
- バッチレイヤ
- スピードレイヤ
- サービスレイヤ
2. 調査方法
参考ページ
3. 調査結果概要(要約)
- ラムダアーキテクチャとは、三層構造を用いることで、ビッグデータを処理する設計概念
- リアルタイム&低精度のスピードレイヤと、バッチ処理&高精度のバッチレイヤから、クエリに応じて適切なデータパスで処理を行う
4. 調査詳細(具体的な内容)
4.1. ラムダアーキテクチャとは
Apacheの作者が提唱した、三層構造でデータ基盤の拡張性や、保守性を実現する設計概念
ストリーミングデータとバッチ処理の定期実行で得られる集計結果を組み合わせて分析できる
ビッグデータの処理システムの設計指針
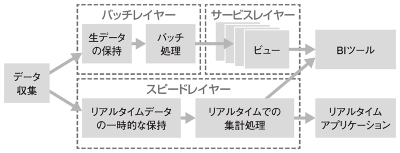
4.2. 三層構造とは
- バッチレイヤ(Cold path)
- 生データの保存、定期的なバッチ処理
- 全てのデータ(主に過去のデータ)に対して、バッチ処理を実行
- バッチビューを生成
- スピードレイヤ(Hot path)
- リアルタイムで送られてくるストリーミングデータを一時的に保持、リアルタイム処理
- 精度と引き換えに、待機時間が短くなるように設計
- ストリーミングデータからリアルタイムビューを生成
- サービスレイヤ
- バッチ処理で得られるビューをクライアントに提供
- BIツールとか、SQLで参照可能
- バッチビュー、リアルタイムビューから計算
- リアルタイム性を求める場合には精度が低い可能性のあるスピードレイヤのデータ
- 正確性を求める場合には、多くのデータから計算され、精度の高いバッチレイヤのデータを
4.3. 登場の背景
- 従来の状況
- 個別の課題を対処療法的に解決する
- コストもかかるし、プロジェクトごとに同じ仕事を繰り返し行う
- ラムダアーキテクチャ
- 課題を整理、一般化し、それらを包括的に解決
- 枠組みに昇華
4.4. 原理
- 全ての処理はデータの集合に対するクエリ
- クエリはデータに対する関数
4.5. ラムダアーキテクチャのメリット
- 計算フローを2層に分けることで、下記のトレードオフ回避
- 正確性 と レイテンシー
- クエリの自由度 と 計算量
- 永続性をマスタデータに飲み求めることで、堅牢性とスケーラビリティを両立
- 冗長化が容易
- DBサーバー管理が不要
5. 所感
やっと言いたいことがわかってスッキリした
リアルタイム&精度落ちる、バッチ処理&高精度は、レイヤ型ディスプレイの考えとかに似ている(NTFとCNN)
最初は何を言っているかわからなかったが、複数サイトで包括的に見ることって大事
6. 不明単語
| 単語 | 意味 | 備考 |
|---|---|---|
| 生データ | バッチレイヤに格納されているデータ、前のデータが上書きされることはないため、データはどんどん追加、精度は向上する | --- |
| バッチ処理 | 大量の生データをまとめて一括で処理すること | --- |
| BIツール | 企業の持つデータを分析、可視化を行うツール | Business Intelligence tool |
| ストリーミングデータ | 無制限に発生する、大量のリアルタイムデータ | --- |
| アドホック | その場の端末だけでグループを形成するモードをアドホックモード | その場だけ |
| マスタデータ | 永続性を必要とする唯一のデータストア | --- |
| バッチビュー | バッチレイヤから生成されたデータ | --- |