こんにちは,オタクです.
vの歌配信って,いいですよね......
(これは病気)
今回は歌配信から自動で歌部分だけ抽出するやつを作りました.
これ使って何かしたいんだけど大抵著作権に引っかかりそうで悔しくなっています.
概要
- 配信を10秒で切り刻んでメル周波数スペクトログラムを計算して
- 歌とその他に分けてCNNに入れて
- えいやしました
準備
機械学習の知見は全くないので検索します.
特に こちら を参考に(諸説)モデルをお借りしました.大変ありがとうございます.
前処理
メル周波数スペクトログラムが良さそうなので,配信を10秒に切って求めます.
# メル周波数スペクトラムを返す
def calculate_melsp(x, n_fft=1024, hop_length=128):
stft = np.abs(librosa.stft(x, n_fft=n_fft, hop_length=hop_length))**2
log_stft = librosa.power_to_db(stft)
melsp = librosa.feature.melspectrogram(S=log_stft,n_mels=128)
return melsp
_x, fs = librosa.load("wavファイル", sr=48000, duration=9.9)
_x = calculate_melsp(_x)
librosa.display.specshow(_x, sr=48000)
plt.colorbar()
plt.show()
こんな感じの画像が出ます.(これはわらべだの6兆年のサビです)
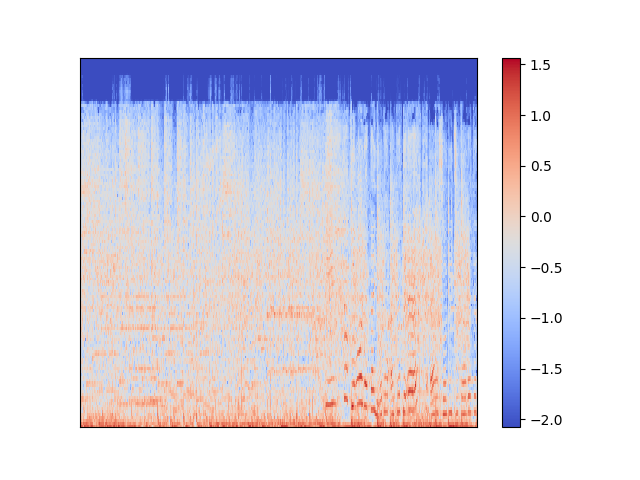
よくわからないですね.これをCNNで学習させます.
CNNで学習する
テストデータを4つの配信から作成しました.歌・それ以外合わせて1200データです.
- 白上フブキ [朝歌枠]
- 戊亥とこ [スナック戊亥]
- 兎田ぺこら [ライブ直前]
- 神楽めあ [アーカイブ削除ずみ]
こちら まんま使いました.データセットの与え方はこんな感じでした.
x_train ... データ数 * 128 * 3713 * 1
y_train ... データ数 * (1 or 0) ← 歌かそれ以外か
model.fit(x_train, y_train, epochs=20, verbose=1, validation_split=0.1, batch_size=5)
model.save("model.h5")
バッチサイズはデフォルト(25) でやったらメモリが死んだので5にしました.
結果はこんな感じです.
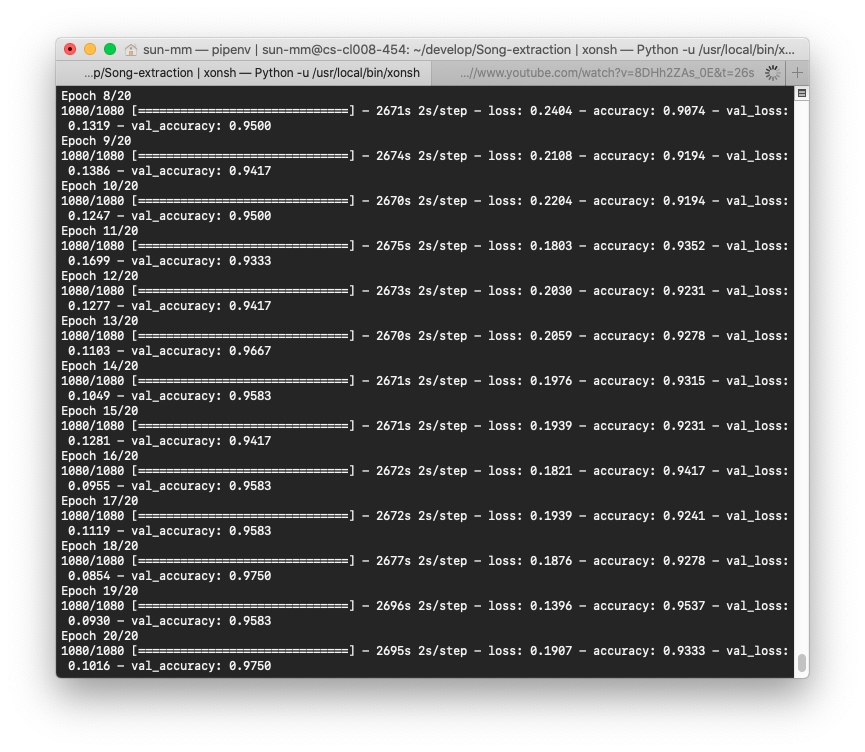
Accuracy 0.9333 val_accuracy 0.9750はなかなか良いのではないでしょうか(全くわからないけど)
推論して切り出してみる
model = load_model("model.h5")
ret = model.predict( 1*128*3713*1のデータ )
# ret[0] -> 歌 の確率
# ret[1] -> それ以外 の確率
100%ではないので確率をうまく使って歌だけ切り出せるように組みました.
- 歌と判定された区間が3つ以上続く,かつ確率の平均が80%を超えている場合に歌と判定する
- 1で判定した歌区間と歌区間の間が2区間以下かつ,歌区間を結合したときに6分を超えない場合に,2つの区間を結合する
- 2の歌区間の前後1区間を見て,確率が40%を超えていたら歌区間に結合する
- 3で得られた歌区間で切り出す
簡単に説明します.
1で大まかな歌区間を出します.エコーのついた雑談や歌っぽく判定された雑談が混じらないように,確率の平均で消し去ります.
これだけだとバラード系楽曲が分割されてしまう問題があるので,1で残った歌区間の間が2区間(=20秒)以下なら結合します.ただ,この方法は「連チャンで歌われると2曲が合体してしまう」問題があります.なので,結合後に6分を超えないようにしました.(歌は大抵6分以内だと思っているためです)
ここまでで大まかに歌が取れます.ただイントロやアウトロが切れてしまう・ぴったりすぎる問題があるので,前後が歌っぽい(確率が40%以上ある)時は結合しました.
結果
データセットにない,「湊あくあ」さんの歌枠を切り取ってみました.
湊あくあ「【Vtuber】1日限定!アイドルメイドの全力Live!【歌枠】」
自動で切り取ったものがこちらです
とてもいい感じに切り出すことができました.
ただ,曲の後を長めに切り出してしまうことがあるので,そこを改善しながらこの技術の使い方を検討していきたいと思います.
これ以上精度上げたい時はどうするのが正解なんだろうか......