最初に
本記事は、Datadog Advent Calendar 2024 の12/1の投稿になります。
また、記事の内容については筆者の個人的な見解であり、Datadog公式のものではないことを予めここに明記しておきます。
SREを考える
SREがシステム、インフラの管理・監視、サービス運用の方法論としてだいぶ世に広まってきましたが、このSREという運用とその体制が、AIを取り入れることによって今後どのように(もしかしたらすでに)変化していくのかについて考察してみました。
結果として、それぞれのシチュエーションにおいて、Datadogがカバーできる要素を持っていることがわかりましたので、それについて触れていきたいと思います。
プロアクティブな運用
予兆検知の強化
AIが障害の発生を予測し、対応策を事前に提示する機能が一般的になるでしょう。
ログやメトリクスから異常検知を行うだけでなく、システム全体のコンテキストを理解して、発生し得る問題を詳細に予測します。
これは、DatadogではAnomaly Monitor(異常検知モニター)として機能を提供しています。
また、WatchdogはDatadogのAIエンジンであり、Datadogプラットフォーム全体の可観測性データから抽出した自動化されたアラート、インサイト、根本原因分析を提供します。

リスク軽減の自動化
例えば、スケーラビリティの問題やリソースの過負荷をリアルタイムで認識し、自動でスケールアップやトラフィックの再分配を行うシステムが主流になるでしょう。
Datadogから、例えばKubernetesのオートスケーリングを操作しようと思っても、現時点で直接的にはできません。ですが、Datadogのメトリクスを利用してKubernetesのHorizontal Pod Autoscaler(HPA)を動的に制御する仕組みを構築することが可能です。
このあたりの詳細な手順は、こちらの公式ドキュメントでも解説していますのでご参照下さい。
インシデント対応の自動化
インシデントのリアルタイム分析と対応
AIが問題を特定し、過去の事例や知識ベースを参照して最適な解決方法を自動で実行する仕組みが普及します。これはDatadogではWatchdogやAnomaly Monitoringなどで一部実現ができているかと思います。
ただ、これらはインシデント発生後の対応というよりはプロアクティブな対応に向けたものです。インシデント対応としては、機械学習を活用してインシデントの優先度判定を行ったり、根本原因の特定を行ったり、影響を受けたリソースや関連するメトリクスを可視化し、問題の原因を迅速に特定するなどが可能です。また、過去の関連データを自動的に収集して、発生したイベントを時系列で表示し、インシデントタイムラインを構築することが可能です。
今年の夏のDASHにて発表のあったOnCall機能は、まだ非公開Betaですが、Datadogでの検知をトリガーに、各チームへの連携をスムーズにします。例えば携帯への連絡や、シフトスケジュール管理などもサポートします。
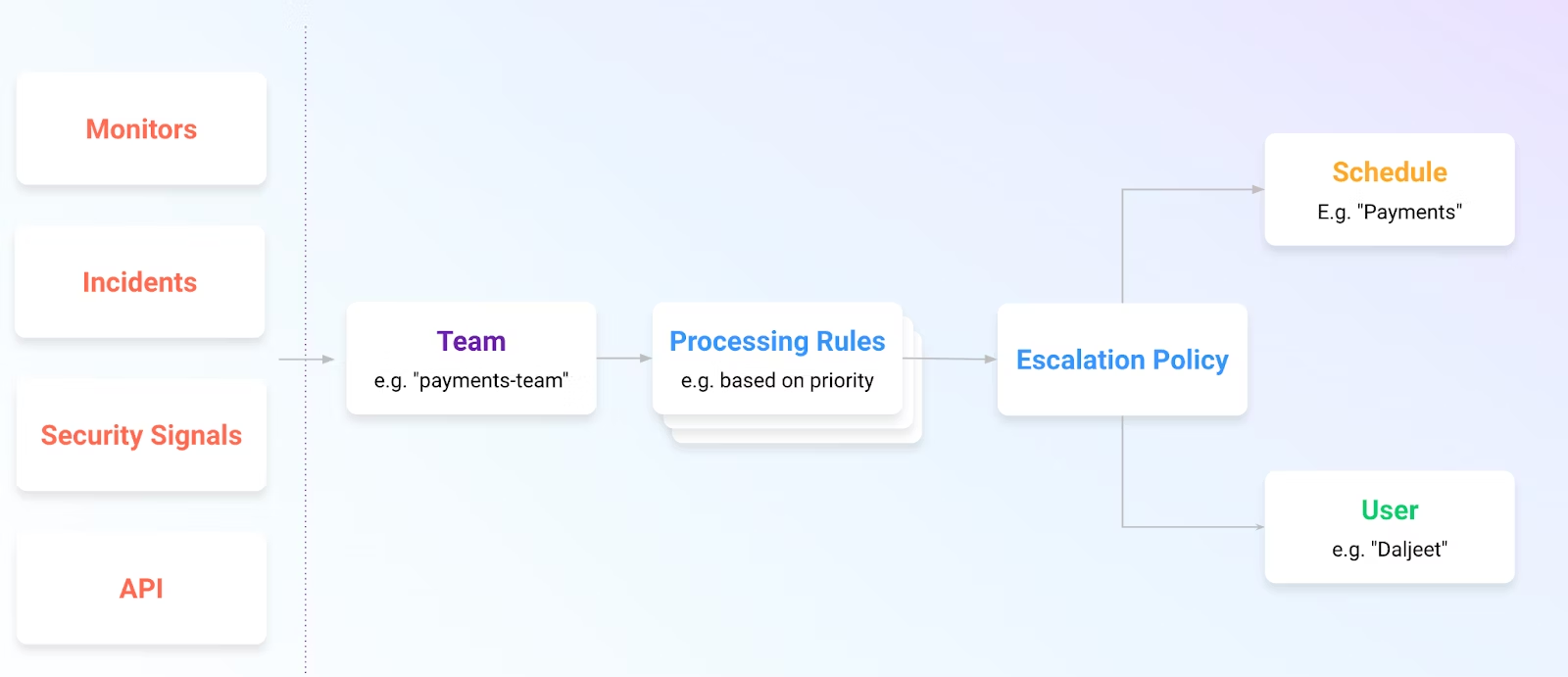

自己修復システムの進化
小規模な障害であれば、AIが自律的に問題を修復し、エスカレーションの必要性を減少させることができるようになっていくでしょう。
現時点では、Datadog自体がAIを活用して完全に自律的に問題を修復する機能は提供していません。しかし、Datadogの監視・分析機能を他のツールやスクリプトと組み合わせることで、AIを用いた自動修復のワークフローを構築することが可能です。
例えば、Datadogがトラフィックスパイクを検知し、Webhookでスケーリングスクリプトを実行し、Kubernetesのポッド数を増やすアプローチや、DatadogのアラートをトリガーとしてJenkinsやGitHub ActionsのようなCI/CDツールを起動し、必要な修復操作を行ったり、と言う感じですね。
効率的なリソース管理
AIによるインフラの最適化
CPU、メモリ、ストレージ、ネットワークの使用状況を継続的にモニタリングし、AIが自動でリソースを調整するようになっていくでしょう。これによりコスト削減が可能になります。
こちらも、Datadog単体ではリソースを直接的にコントロールできるような機能はありませんが、Datadog本丸のインフラメトリクスの監視とAnomaly Monitoringを活用しながら、その手前までをサポートすることは可能でしょう。
動的な負荷予測
トラフィックパターンや需要の変動を予測し、それに基づいてリソースを動的にスケールさせる技術がさらに洗練されるでしょう。
Datadogには、時系列メトリクスを基に将来の値を予測するForecast(予測値モニター)機能が組み込まれていますので、これを活用することでほぼ実現できると思います。


高度な監視とアラート
多次元データ解析
AIは、システムのログ、メトリクス、分散トレースデータなどの大量のデータを統合的に解析し、関連性のある問題をリアルタイムで特定することが求められてきます。
DatadogではAIというよりは、オブザーバビリティの仕組みとしてこれを実現しています。現状はこの関連性をタグや環境変数などで関連付けていますが、AIが正確な関連性を検出できるようになれば更に問題解決までの時間が短縮されるでしょう。
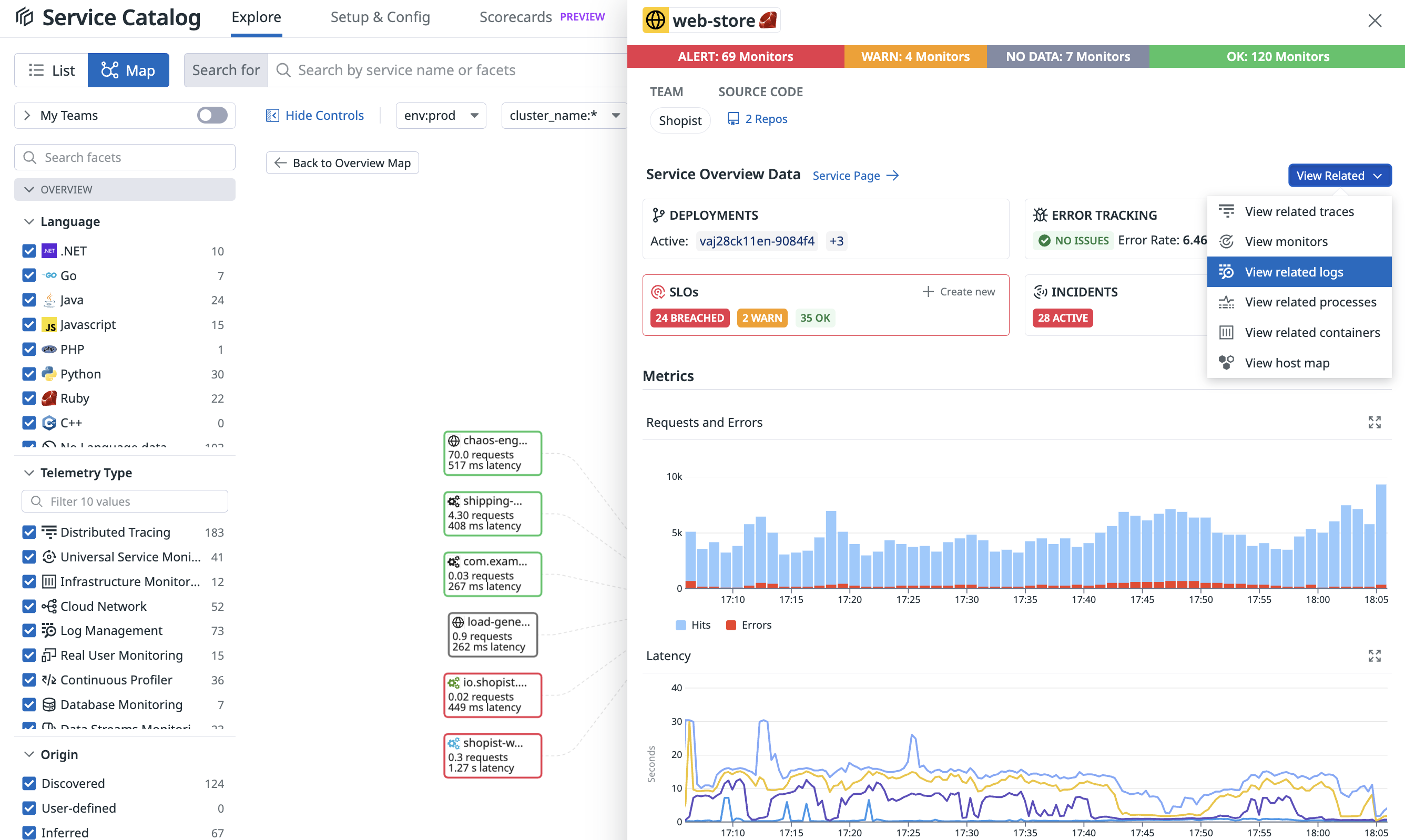
ノイズ削減
不必要なアラートをAIがフィルタリングし、本当に重要なインシデントだけをエスカレーションする機能が進化するでしょう。
例えばDatadogでは、AIを活用したWatchdogや動的しきい値設定、関連性のあるアラートのグループ化を通じて、すでにアラートストームを回避しています。
この仕組みにより、運用チームは不要なノイズを減らし、根本的な問題解決に集中できるようになります。また、Datadogのアラート管理機能を他のツールと統合することで、さらに効率的なインシデント対応を実現できます。
懸念点
倫理的課題の検討
AIの自律的な判断に依存する場合、障害やエラーの原因を人間が理解しにくくなる可能性があります。このようなブラックボックス化を防ぐための透明性の確保や、AIの出力に対する責任範囲の明確化が求められます。
まとめ
AIがSRE業務の中心的な役割を果たす未来が見込まれる中で、SREエンジニアはAIの力を活用しつつ、新たな課題に適応する能力が重要になるでしょう。
そんなSREの成長の一旦をDatadogが担えれば嬉しいですね!