今回は、Google Colaboratoryを利用して、ぼくのフォロワー200名を対象に、フォロー数とフォロワー数の散布図を描いてみました。
※先日この記事を読んで、GoogleDriveから環境構築無しでPythonが使えることがわかったので、実際にやってみました。
Google DriveでPythonの実行環境を整える方法をまとめてみた
今回やったこと
今回のチャレンジは全部で3つの目的のもと行っています。
- 自分のフォロワーの「フォロワー数」を確認する
- 自分のフォロワーの「フォロー数」と「フォロワー数」の関係を可視化する
- Google Colaboratory でAPIを試してみる
1,2については、どちらも知りたいのは、「自分のツイッターをフォローしてくれている人は、どんな人なのか」ということです。
例えばフォロワーがみんな、「フォロー数」はめちゃくちゃ多いけど、「フォロワー数」は大したことないと仮定すると、そんなに影響力がなかったり、そもそもフォローすること自体を目的にしているようなアカウントにフォローされていることになります。
3はこのツールでどこまで出来るのかが試してみたかったので、APIをいじってみたかったというのが主な理由です。どうも機械学習系のライブラリはすでに入っているらしく、しかもGPUが無料で利用できるということなので、この先いろいろと遊べそう。
やり方1:Google Colaboratory を準備する
これは最初の記事に書いてるので、簡単な説明に留めます。やり方はいたって簡単で、下記4ステップです。
- Google Driveにログインする
- 「新規」>「その他」>「アプリを追加」を選択
- 検索窓にて「Google Colaboratory」と検索
- 「+接続」を選ぶ
これで準備完了です。
利用するときには、「新規」>「その他」>「Colaboratory」をクリックでファイルを作成します。
そして三角が横向きに出ている箇所があるので、そこにお馴染みHello Worldのプログラムを書いてみます。
msg = "Hello World"
print(msg)
もうこれだけでとりあえずPythonが動く環境ができています。
やり方2:Tweepyのセットアップ
まず標準ではGoogle ColaboratoryにTweepyが入っていないので、次のプログラムを実行しておきましょう。
!pip install tweepy
正直事前準備はこれくらいです。あとはAPI使ううえでTwitterに事前申請が必要なので、こちらを参照にやっておいてください。
PythonでTwitter API を利用していろいろ遊んでみる
やり方3:実際にコード書いてみる
今回使ったライブラリはTweepyとMatplotlibの2つだけ。
まずコードの全体像はこんな感じです。
# 必要なライブラリをインポート
import tweepy
import matplotlib.pyplot as plt
# 各種キーをセット
CONSUMER_KEY = 'xxxxxxxxxxxxxxxx'
CONSUMER_SECRET = 'xxxxxxxxxxxxxxxx'
ACCESS_TOKEN = 'xxxxxxxxxxxxxxxx'
ACCESS_SECRET = 'xxxxxxxxxxxxxxxx'
auth = tweepy.OAuthHandler(CONSUMER_KEY, CONSUMER_SECRET)
auth.set_access_token(ACCESS_TOKEN, ACCESS_SECRET)
# APIインスタンスを作成
api = tweepy.API(auth)
# 自分のフォロワーのIDを取得
ids = api.followers_ids("taikomegane")
# フォロワー数とフォロー数を格納するリストを用意
follower_list = []
friend_list = []
# 取得したIDそれぞれについて処理を繰り返す
for id in ids:
#IDからユーザ情報を取得
user_info = api.get_user(id)
#ユーザ情報からフォロワー数を取得、格納
follower = int(user_info.followers_count)
follower_list.append(follower)
#ユーザ情報からフォロー数を取得、格納
friend = int(user_info.friends_count)
friend_list.append(friend)
# フォロワー数、フォロー数のヒストグラムをそれぞれ描画
plt.hist(follower_list,bins=30)
plt.hist(friend_list,bins=30)
# フォロワー数、フォロー数の散布図を描画
plt.scatter(follower_lists,friend_list)
print("終了しました")
やっていることは、次の4ステップ。
- TwitterのAPIインスタンスを生成
- 自分のフォロワーのIDを取得
- それぞれのIDについて、フォロワー数、フォロー数を取得
- フォロワー数、フォロー数を用いて、ヒストグラムと散布図を描画
実際の結果はこんな感じで・・・・・・と言いたいところですが、なんだかんだでエラーを処理しているうちにAPIの実行回数が制限を超えてしまいました。データの読み取りは追記で行います。
さて割と簡単なコードだけでここまでできました。しかも全部GoogleDrive上で動く。
少し調べてみると、これスプレッドシートとの連携もできそうです。
もうちょっと何ができるか調べたいところですが、とりあえず今回はここまで。
改めて技術チュートリアルって、最初からそれを書くつもりでやらないとなかなか難しいですね。
多少きれいにしたやつが作れたら、noteで販売しようかな。
それでは、本日も最後までお付き合いいただきありがとうございました。
追記:結果出ました。
このあとダメ押しでもう一度実行したら出来ました。
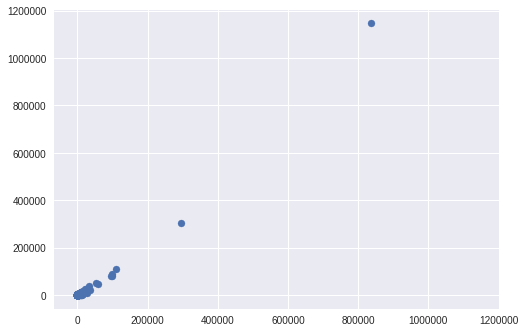
で、お気づきの通り、1つしか出てきませんでした。
matplotlibは複数描画してくれと頼んだ場合、再描画してしまうので、前のものは消えてしまうようです。
本記事はこちらの転載になります
GoogleColaboratoryでTwitterのデータ分析してみた