概要
Microsoft Azure HDInsightとは、マイクロソフト社が提供する、HadoopのPaaSサービスで、インフラ周りの構築ノウハウをあまり知らなくても、立派なHadoopクラスターが構築できる素晴らしいサービスです。
今回はこのMicrosoft Azure HDInsightを構築し、構築したクラスター上でR言語を並列実行させてみます。
事前に準備するもの
- Azure サブスクリプション
※無償試用版をお使いでない方は必ずお読みください※
このクラスターを構築すると、毎時270円ほどお金がかかります。作成後は必ず削除してください。
削除しないと1日6000円ぐらいかかるので、大変な請求額となります。
構築手順
-
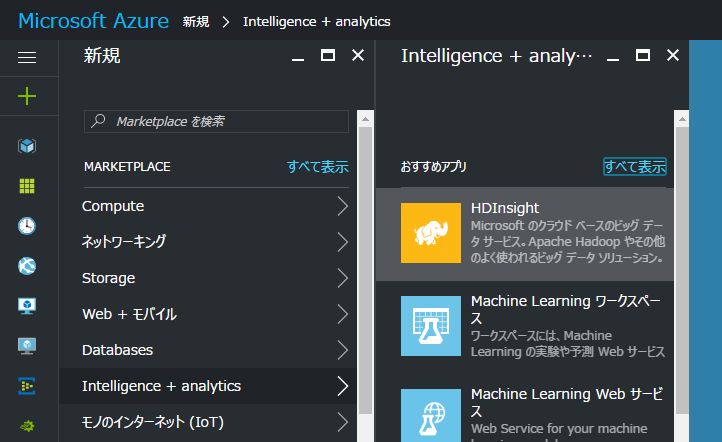
「新規」> 「Intelligence + analytics」のカテゴリーから「HDInsight」を選択します。
-
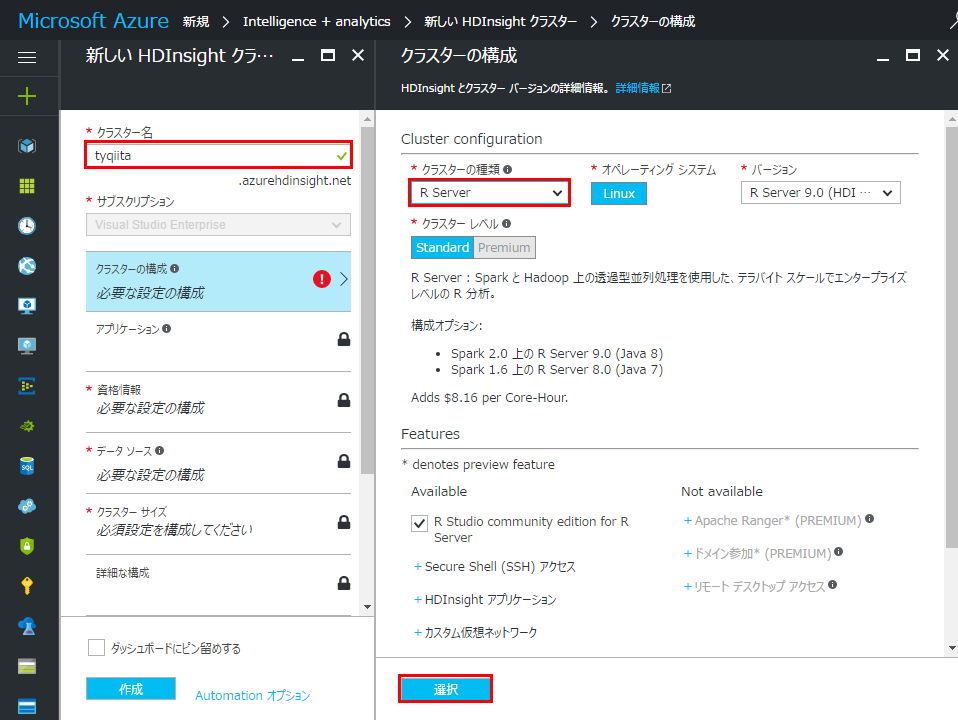
クラスター名を入力し、クラスター構成から「クラスターの種類」を「R Server」にし、「選択」をクリックします。
-
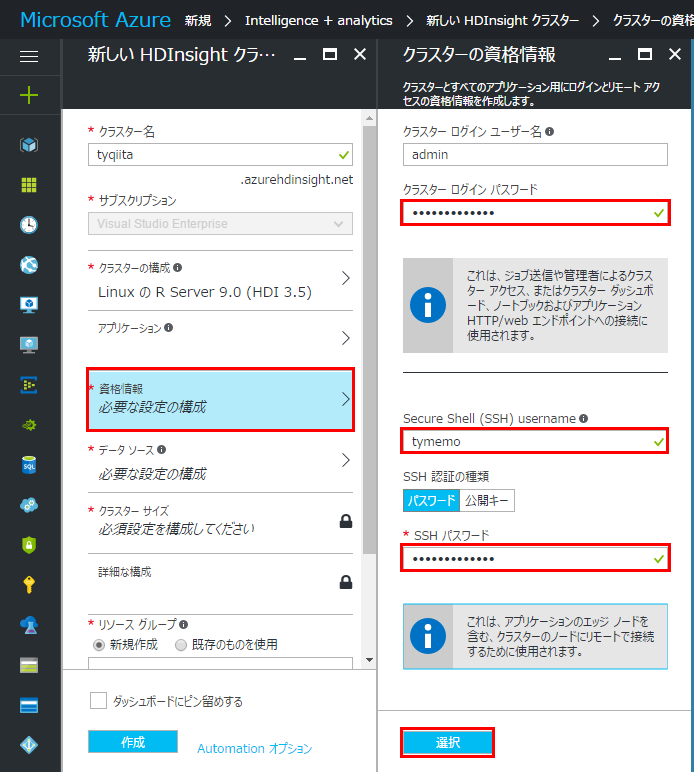
資格情報を設定します。「クラスターログインパスワード」は大文字・小文字と記号を含む12文字以上のパスワードが必要です。
-
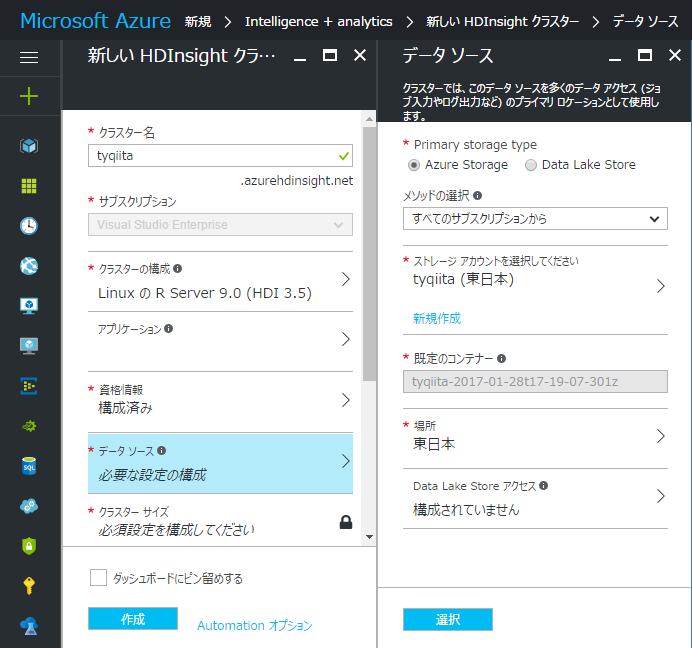
次にデータソースを関連付けます。既存のAzureストレージアカウントや、Data Lake Storeが利用できます。なければ新規作成も可能です。データソースからのデータはこの記事では利用しませんので、どの設定でもOKです。
-
クラスターのサイズを指定します。著者はお金がないので一番安い構成にしています(笑) ※それでも1時間 242.76円なので、利用が終わったら必ず削除するように気を付けましょう。あとは「作成」を押して、デプロイされるのを待ちます。大体10分以内にデプロイは完了しているはずです。
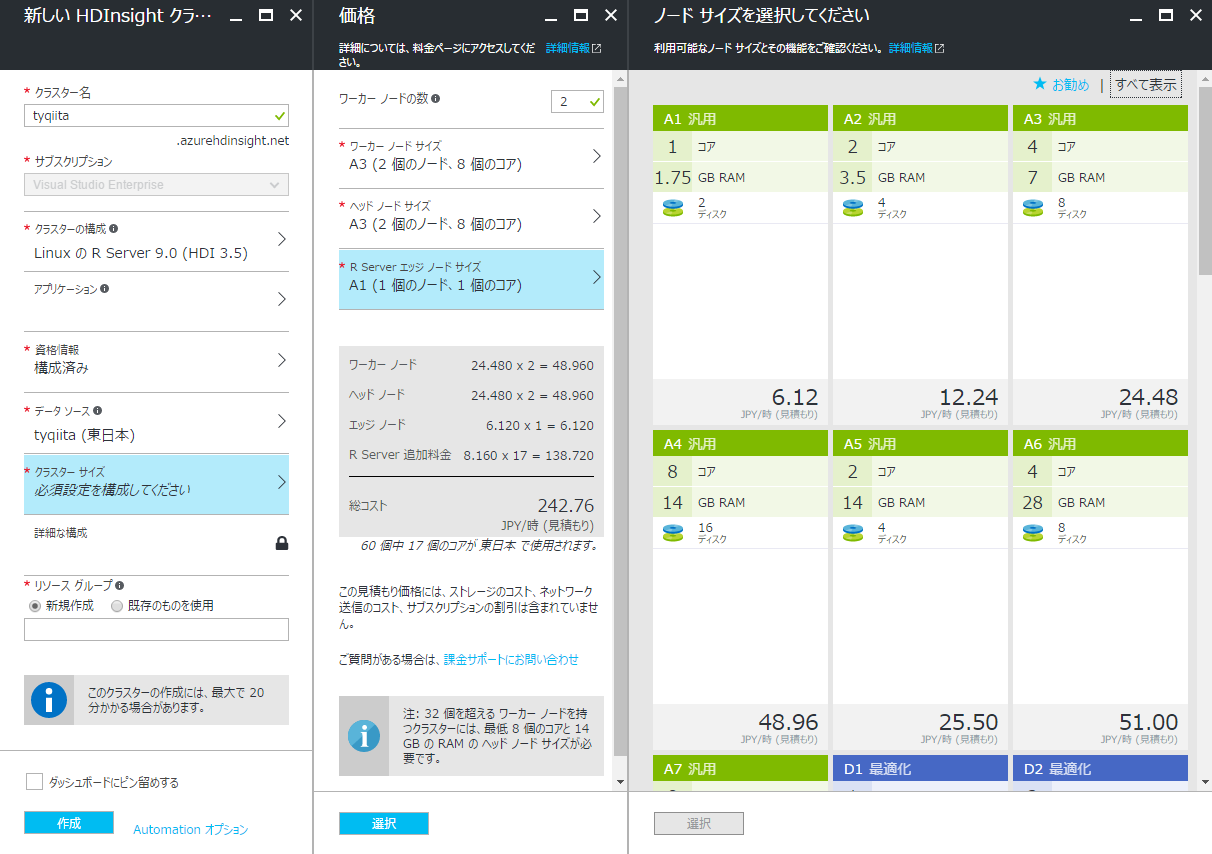
-
「R Server ダッシュボード」をクリックします。
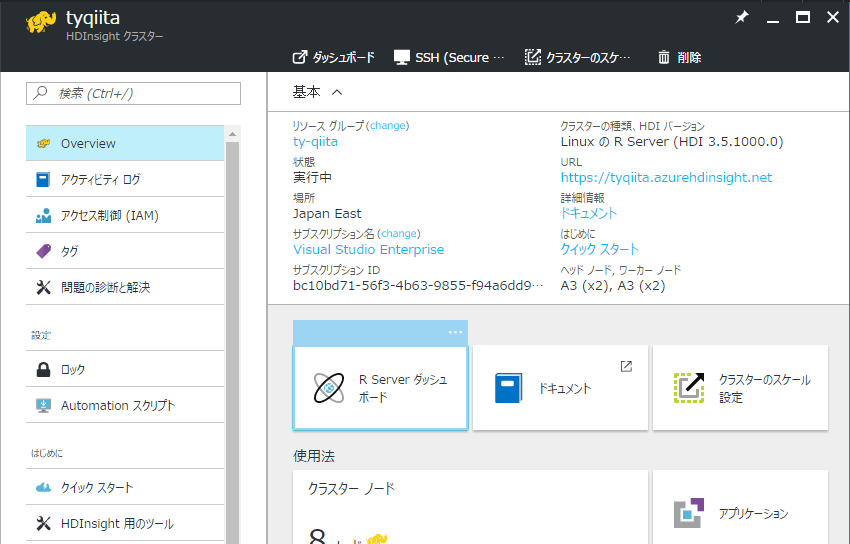
-
「R Studio サーバ」を選択します。
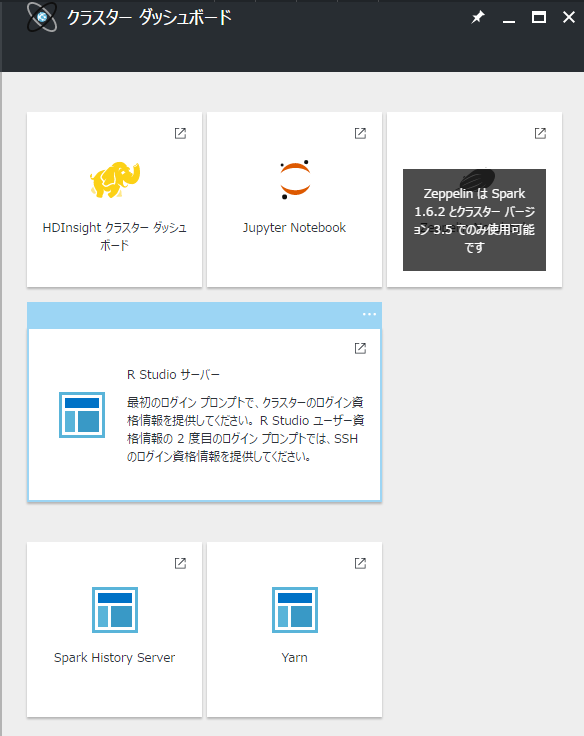
-
ログインが2回求められます。1回目はクラスターログイン情報、2回目はSSHログイン情報です。
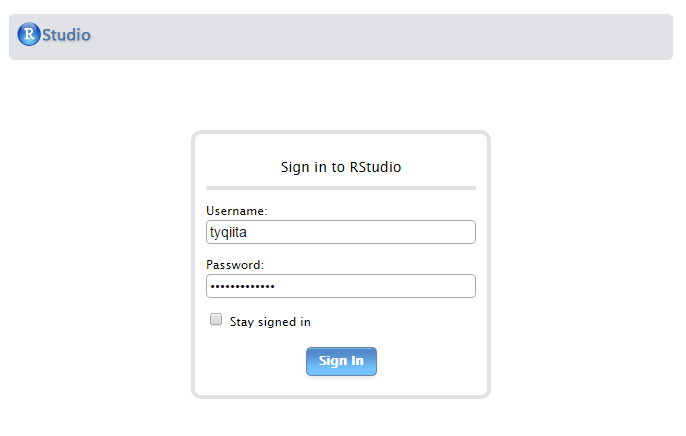
-
これでR言語での実行準備は完了です。
単一のノードで実行する
以下のコードを実行します。
# サンプルデータのHDFS (WASB) 場所を指定します
bigDataDirRoot <- "/example/data"
# 一時的に保管するローカルフォルダーを作成します
source <- "/tmp/AirOnTimeCSV2012"
dir.create(source)
# データを一時フォルダへダウンロードします
remoteDir <- "http://packages.revolutionanalytics.com/datasets/AirOnTimeCSV2012"
download.file(file.path(remoteDir, "airOT201201.csv"), file.path(source, "airOT201201.csv"))
download.file(file.path(remoteDir, "airOT201202.csv"), file.path(source, "airOT201202.csv"))
download.file(file.path(remoteDir, "airOT201203.csv"), file.path(source, "airOT201203.csv"))
download.file(file.path(remoteDir, "airOT201204.csv"), file.path(source, "airOT201204.csv"))
download.file(file.path(remoteDir, "airOT201205.csv"), file.path(source, "airOT201205.csv"))
download.file(file.path(remoteDir, "airOT201206.csv"), file.path(source, "airOT201206.csv"))
download.file(file.path(remoteDir, "airOT201207.csv"), file.path(source, "airOT201207.csv"))
download.file(file.path(remoteDir, "airOT201208.csv"), file.path(source, "airOT201208.csv"))
download.file(file.path(remoteDir, "airOT201209.csv"), file.path(source, "airOT201209.csv"))
download.file(file.path(remoteDir, "airOT201210.csv"), file.path(source, "airOT201210.csv"))
download.file(file.path(remoteDir, "airOT201211.csv"), file.path(source, "airOT201211.csv"))
download.file(file.path(remoteDir, "airOT201212.csv"), file.path(source, "airOT201212.csv"))
# bigDataDirRootのディレクトリを設定し、ロードするデータを指定します
inputDir <- file.path(bigDataDirRoot,"AirOnTimeCSV2012")
# ディレクトリを作成します
rxHadoopMakeDir(inputDir)
# データをソースからインプットへコピーします
rxHadoopCopyFromLocal(source, bigDataDirRoot)
# HDFS (WASB) ファイルシステムを定義します
hdfsFS <- RxHdfsFileSystem()
# 航空会社のリストを作成します
airlineColInfo <- list(
DAY_OF_WEEK = list(type = "factor"),
ORIGIN = list(type = "factor"),
DEST = list(type = "factor"),
DEP_TIME = list(type = "integer"),
ARR_DEL15 = list(type = "logical"))
# カラム名を抽出します
varNames <- names(airlineColInfo)
# hdfs上のデータソースを定義します
airOnTimeData <- RxTextData(inputDir, colInfo = airlineColInfo, varsToKeep = varNames, fileSystem = hdfsFS)
# ローカルシステム上のテキストデータを定義します
airOnTimeDataLocal <- RxTextData(source, colInfo = airlineColInfo, varsToKeep = varNames)
# 利用する関数です
formula = "ARR_DEL15 ~ ORIGIN + DAY_OF_WEEK + DEP_TIME + DEST"
# 演算コンテキストをローカルにします
rxSetComputeContext("local")
# ロジスティクス回帰を実行します(およそ40分ほどかかります)
system.time(
modelLocal <- rxLogit(formula, data = airOnTimeDataLocal)
)
# 結果を表示します
summary(modelLocal)
この実行方法ですと、並列処理ではないため、40分ほど時間がかかります。長いですね…
複数のノードで実行する
複数ノードで実行するには、Sparkを演算コンテキストとして設定することで実行できます。
# Spark演算コンテキストを定義します
mySparkCluster <- RxSpark()
# 演算コンテキストを定義します
rxSetComputeContext(mySparkCluster)
# ロジスティクス回帰を実行します
system.time(
modelSpark <- rxLogit(formula, data = airOnTimeData)
)
# 結果を表示します
summary(modelSpark)
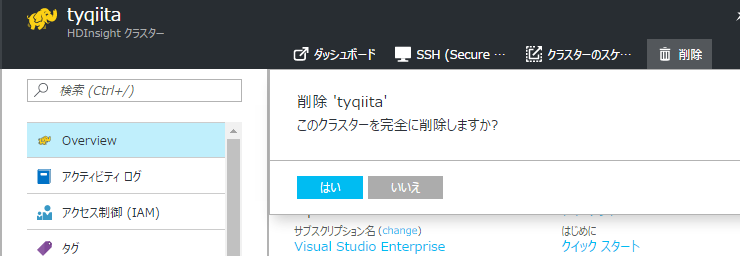
クラスターの削除
利用後は必ずクラスターを削除されることをおすすめします。
参考資料