1. はじめに
料理画像分類においてImageNetで事前学習済みの複数のモデルをファインチューニングして、精度の比較を行いました。
フレームワークとしてはPytorchを使用して、Pytorchのパッケージであるtorchvisionを使って事前学習済みモデルをダウンロードします。
また、学習の際はAWSのサービスであるSagemakerを用いて学習ジョブを投げます。
2. 使用する学習済みモデル
今回比較を行う事前学習済みモデルは以下の6つです。
- AlexNet
- VGG16
- GoogLeNet
- DenseNet-201
- ResNet-152
- Wide ResNet-101-2
3. 学習データ
学習データとして電気通信大学柳井研究室が公開している料理データセットであるUEC FOOD 256を用いたいと思います。
Zipファイルを解凍すると1から256の数値のディレクトリがあり、それぞれのディレクトリに異なる種類の料理画像が配置されています。
データの一例としては以下です。

上記の例のように、一枚の画像に複数の料理があるケースがあるので、一つの画像には一つの料理しかないように前処理を行います。
幸いデータセットには各料理ごとのバウンディングボックスの情報がテキストファイルとして記載されているので、それを用いて画像をトリミングします。また、その際に学習データと検証データに分ける処理も行います。
コードは以下です。
%%sh
import cv2 #OpenCVをインポート
import numpy as np #numpyをインポート
import glob
import os
# 学習データを保存するディレクトリ
train_directory = "data_256/train/"
# 検証データを保存するディレクトリ
valid_directory = "data_256/valid/"
for n in range(1,257):
# 処理対象のファイル名を保持するリスト
file_name = []
# 各料理の左端の座標を保持するリスト
left_x = []
# 各料理の右端の座標を保持するリスト
right_x = []
# 各料理の上端の座標を保持するリスト
upper_y = []
# 各料理の下端の座標を保持するリスト
lower_y = []
# データを読み取るディレクトリ
read_directory = 'UECFOOD256/{}/'.format(n)
with open(read_directory + 'bb_info.txt', mode='rt', encoding='utf-8') as f:
for i,line in enumerate(f):
if i > 0:
file_name.append(int(line.split(" ")[0]))
left_x.append(int(line.split(" ")[1]))
upper_y.append(int(line.split(" ")[2]))
right_x.append(int(line.split(" ")[3]))
lower_y.append(int(line.split(" ")[4]))
# 学習データと検証データを8:2で分割する
train_num = int(len(file_name) * 0.8)
for i in range(0, train_num):
img = cv2.imread(read_directory + str(file_name[i]) + ".jpg") #画像の読み込み
img_trimming = img[upper_y[i] : lower_y[i], left_x[i]: right_x[i]]
DIR = write_directory_train + str(n) + "/"
num_files = (sum(os.path.isfile(os.path.join(DIR, name)) for name in os.listdir(DIR))) + 1
if upper_y[i] < lower_y[i] and left_x[i] < right_x[i]:
cv2.imwrite(train_directory + str(n) + "/" + str(num_files + 1) + ".jpg", img_trimming)
for i in range(train_num, len(file_name)):
img = cv2.imread(read_directory + str(file_name[i]) + ".jpg") #画像の読み込み
img_trimming = img[upper_y[i] : lower_y[i], left_x[i]: right_x[i]]
DIR = write_directory_valid + str(n) + "/"
num_files = (sum(os.path.isfile(os.path.join(DIR, name)) for name in os.listdir(DIR))) + 1
if upper_y[i] < lower_y[i] and left_x[i] < right_x[i]:
cv2.imwrite(valid_directory + str(n) + "/" + str(num_files + 1) + ".jpg", img_trimming)
データ数は学習データ26139枚、検証データ6535枚になりました。
4. 学習処理の実装
学習処理の記述を行います。
4.1 事前準備
まずは必要なモジュールのインポートを行います。
%%sh
# パッケージのimport
import numpy as np
import random
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import models
from tqdm import tqdm
import torch.utils.data as data
from PIL import Image
import glob
import os.path as osp
from torchvision import models, transforms
乱数のシードを設定します。
torch.manual_seed(1234)
np.random.seed(1234)
random.seed(1234)
料理画像へのファイルパスのリストを作成する関数を作ります。
def make_datapath_list(phase="train"):
"""
データのパスを格納したリストを作成する。
Parameters
----------
phase : 'train' or 'val'
訓練データか検証データかを指定する
Returns
-------
path_list : list
データへのパスを格納したリスト
"""
rootpath = "./data_256/"
target_path = osp.join(rootpath+phase+'/**/*.jpg')
print(target_path)
path_list = [] # ここに格納する
# globを利用してサブディレクトリまでファイルパスを取得する
for path in glob.glob(target_path):
path_list.append(path)
return path_list
# 実行
train_list = make_datapath_list(phase="train")
val_list = make_datapath_list(phase="valid")
入力画像の前処理をするクラスを作成します。
訓練時と推論時で処理が異なります。
class ImageTransform():
"""
画像の前処理クラス。訓練時、検証時で異なる動作をする。
画像のサイズをリサイズし、色を標準化する。
訓練時はRandomResizedCropとRandomHorizontalFlipでデータオーギュメンテーションする。
Attributes
----------
resize : int
リサイズ先の画像の大きさ。
mean : (R, G, B)
各色チャネルの平均値。
std : (R, G, B)
各色チャネルの標準偏差。
"""
def __init__(self, resize, mean, std):
self.data_transform = {
'train': transforms.Compose([
transforms.RandomResizedCrop(
resize, scale=(0.5, 1.0)), # データオーギュメンテーション
transforms.RandomHorizontalFlip(), # データオーギュメンテーション
transforms.ToTensor(), # テンソルに変換
transforms.Normalize(mean, std) # 標準化
]),
'val': transforms.Compose([
transforms.Resize(resize), # リサイズ
transforms.CenterCrop(resize), # 画像中央をresize×resizeで切り取り
transforms.ToTensor(), # テンソルに変換
transforms.Normalize(mean, std) # 標準化
])
}
def __call__(self, img, phase='train'):
"""
Parameters
----------
phase : 'train' or 'val'
前処理のモードを指定。
"""
return self.data_transform[phase](img)
料理画像のDatasetを作成するクラスを作ります。
class FoodDataset(data.Dataset):
"""
料理画像のDatasetクラス。PyTorchのDatasetクラスを継承。
Attributes
----------
file_list : リスト
画像のパスを格納したリスト
transform : object
前処理クラスのインスタンス
phase : 'train' or 'test'
学習か訓練かを設定する。
"""
def __init__(self, file_list, transform=None, phase='train'):
self.file_list = file_list # ファイルパスのリスト
self.transform = transform # 前処理クラスのインスタンス
self.phase = phase # train or validの指定
def __len__(self):
'''画像の枚数を返す'''
return len(self.file_list)
def __getitem__(self, index):
'''
前処理をした画像のTensor形式のデータとラベルを取得
'''
# index番目の画像をロード
img_path = self.file_list[index]
img = Image.open(img_path) # [高さ][幅][色RGB]
# 画像の前処理を実施
img_transformed = self.transform(
img, self.phase) # torch.Size([3, 224, 224])
label = int(img_path.split("/")[-2])
return img_transformed, label
モデルを学習させる関数を作成します。
def train_model(net, dataloaders_dict, criterion, optimizer, num_epochs):
# 初期設定
# GPUが使えるかを確認
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("使用デバイス:", device)
# ネットワークをGPUへ
net.to(device)
# ネットワークがある程度固定であれば、高速化させる
torch.backends.cudnn.benchmark = True
# epochのループ
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch+1, num_epochs))
print('-------------')
# epochごとの訓練と検証のループ
for phase in ['train', 'valid']:
if phase == 'train':
net.train() # モデルを訓練モードに
else:
net.eval() # モデルを検証モードに
epoch_loss = 0.0 # epochの損失和
epoch_corrects = 0 # epochの正解数
# 未学習時の検証性能を確かめるため、epoch=0の訓練は省略
if (epoch == 0) and (phase == 'train'):
continue
# データローダーからミニバッチを取り出すループ
for inputs, labels in tqdm(dataloaders_dict[phase]):
# GPUが使えるならGPUにデータを送る
inputs = inputs.to(device)
labels = labels.to(device)
# optimizerを初期化
optimizer.zero_grad()
# 順伝搬(forward)計算
with torch.set_grad_enabled(phase == 'train'):
outputs = net(inputs)
loss = criterion(outputs, labels) # 損失を計算
_, preds = torch.max(outputs, 1) # ラベルを予測
# 訓練時はバックプロパゲーション
if phase == 'train':
loss.backward()
optimizer.step()
# 結果の計算
epoch_loss += loss.item() * inputs.size(0) # lossの合計を更新
# 正解数の合計を更新
epoch_corrects += torch.sum(preds == labels.data)
# epochごとのlossと正解率を表示
epoch_loss = epoch_loss / len(dataloaders_dict[phase].dataset)
epoch_acc = epoch_corrects.double(
) / len(dataloaders_dict[phase].dataset)
print('{} Loss: {:.4f} Acc: {:.4f}'.format(
phase, epoch_loss, epoch_acc))
4.2 ネットワークモデルの作成
次にVGG-16を例にネットワークモデルを作成します。
学習済みモデルのダウンロードをして、ファインチューニングのために最後の出力層を今回のクラス数である256に付け替えます。
# 学習済みのVGG-16モデルをロード
# VGG-16モデルのインスタンスを生成
use_pretrained = True # 学習済みのパラメータを使用
net = models.vgg16(pretrained=use_pretrained)
# VGG16の最後の出力層の出力ユニットを料理画像のクラス数の256に付け替える
net.classifier[6] = nn.Linear(in_features=4096, out_features=256)
# 訓練モードに設定
net.train()
print('ネットワーク設定完了:学習済みの重みをロードし、訓練モードに設定しました')
損失関数の設定をします。
criterion = nn.CrossEntropyLoss()
5 学習
準備が整ったので、学習を行います。
まずはDatasetを作成します。
# 料理画像へのファイルパスのリストを作成する
train_list = make_datapath_list(phase="train")
val_list = make_datapath_list(phase="valid")
# Datasetを作成する
size = 224
mean = (0.485, 0.456, 0.406)
std = (0.229, 0.224, 0.225)
train_dataset = FoodDataset(
file_list=train_list, transform=ImageTransform(size, mean, std), phase='train')
val_dataset = FoodDataset(
file_list=val_list, transform=ImageTransform(size, mean, std), phase='val')
次にDataLoaderを作成します。今回はどの事前学習済みモデルに対しても共通でバッチサイズには64を設定しました。
batch_size = 64
train_dataloader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size, shuffle=True)
val_dataloader = torch.utils.data.DataLoader(
val_dataset, batch_size=batch_size, shuffle=False)
# 辞書オブジェクトにまとめる
dataloaders_dict = {"train": train_dataloader, "valid": val_dataloader}
5.1 VGG16
まずはVGG16で学習を行います。
ファインチューニングで学習させるパラメータを設定します。
ネットワークの後ろの方ほど学習率が高くなるようにします。
# ファインチューニングで学習させるパラメータを、変数params_to_updateの1~3に格納する
params_to_update_1 = []
params_to_update_2 = []
params_to_update_3 = []
# 学習させる層のパラメータ名を指定
update_param_names_1 = ["features"]
update_param_names_2 = ["classifier.0.weight",
"classifier.0.bias", "classifier.3.weight", "classifier.3.bias"]
update_param_names_3 = ["classifier.6.weight", "classifier.6.bias"]
# パラメータごとに各リストに格納する
for name, param in net.named_parameters():
if update_param_names_1[0] in name:
param.requires_grad = True
params_to_update_1.append(param)
print("params_to_update_1に格納:", name)
elif name in update_param_names_2:
param.requires_grad = True
params_to_update_2.append(param)
print("params_to_update_2に格納:", name)
elif name in update_param_names_3:
param.requires_grad = True
params_to_update_3.append(param)
print("params_to_update_3に格納:", name)
else:
param.requires_grad = False
print("勾配計算なし。学習しない:", name)
# 最適化手法の設定
optimizer = optim.SGD([
{'params': params_to_update_1, 'lr': 1e-4},
{'params': params_to_update_2, 'lr': 5e-4},
{'params': params_to_update_3, 'lr': 1e-3}
], momentum=0.9)
それでは学習を実行します。
今回はエポック数はいずれも50を用いました。
# 学習・検証を実行する
num_epochs=50
train_model(net, dataloaders_dict, criterion, optimizer, num_epochs=num_epochs)
※実際に学習する際はこれらのファイルをpythonファイルにまとめてSagemakerの学習ジョブを起動して学習を行っています。
学習結果は以下のようになりました。
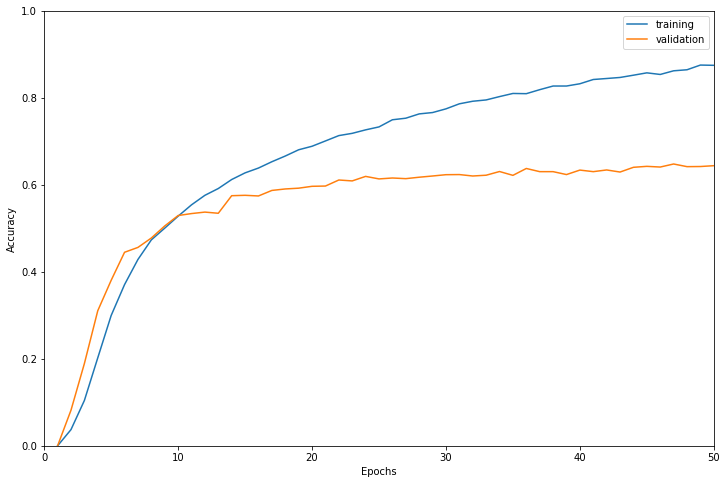
検証データに対する正解率で最も高かったのは47エポック目で正解率0.6480でした。
だいたい20エポック半ばで検証データに対する精度が頭打ちになっています。
学習に使用したインスタンスはml.g4dn.16xlargeで学習時間は27025秒でした。
5.2 AlexNet
次にAlexNetで学習を行います。
とはいえ変える部分は事前学習済みモデルのダウンロードとネットワークの付替え部分および学習率の設定箇所のみです。
net = models.alexnet(pretrained=use_pretrained)
# AlexNetの最後の出力層の出力ユニットを料理画像のクラス数の256に付け替える
net.classifier[-1] = nn.Linear(in_features=4096, out_features=256)
params_to_update_1 = []
params_to_update_2 = []
params_to_update_3 = []
# 学習させる層のパラメータ名を指定
update_param_names_1 = ["classifier.4.bias", "classifier.4.weight", "classifier.1.bias", "classifier.1.weight"]
update_param_names_2 = ["classifier.6.bias", "classifier.6.weight"]
# パラメータごとに各リストに格納する
for name, param in net.named_parameters():
if name in update_param_names_1:
param.requires_grad = True
params_to_update_2.append(param)
print("params_to_update_2に格納:", name)
elif name in update_param_names_2:
param.requires_grad = True
params_to_update_3.append(param)
print("params_to_update_3に格納:", name)
else:
param.requires_grad = True
params_to_update_1.append(param)
print("params_to_update_1に格納:", name)
# 最適化手法の設定
optimizer = optim.SGD([
{'params': params_to_update_1, 'lr': 1e-4},
{'params': params_to_update_2, 'lr': 5e-4},
{'params': params_to_update_3, 'lr': 1e-3}
], momentum=0.9)
学習結果は以下のようになりました。
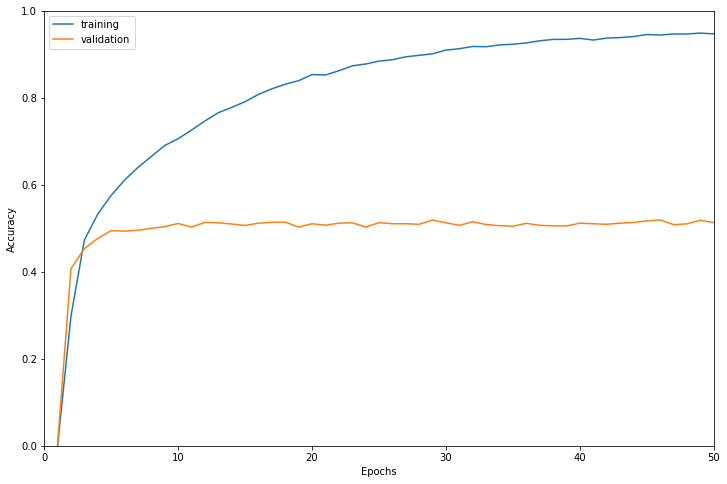
検証データに対する正解率で最も高かったのは46エポック目で正解率0.5195でした。
だいたい10エポックくらいで検証データに対する精度が頭打ちになっています。
学習に使用したインスタンスはml.g4dn.12xlargeで学習時間は7343秒でした。
5.3 GoogLeNet
GoogLeNetでのとネットワークの付替え部分および学習率の設定は以下です。
net = models.googlenet(pretrained=use_pretrained)
# GoogLeNetの最後の出力層の出力ユニットを料理画像のクラス数の256に付け替える
net.fc = nn.Linear(in_features=1024, out_features=256)
# ファインチューニングで学習させるパラメータを、変数params_to_updateの1~3に格納する
params_to_update_1 = []
params_to_update_2 = []
params_to_update_3 = []
# 学習させる層のパラメータ名を指定
update_param_names_1 = ["inception5"]
update_param_names_2 = ["fc.bias", "fc.weight"]
# パラメータごとに各リストに格納する
for name, param in net.named_parameters():
if update_param_names_1[0] in name:
param.requires_grad = True
params_to_update_2.append(param)
print("params_to_update_2に格納:", name)
elif name in update_param_names_2:
param.requires_grad = True
params_to_update_3.append(param)
print("params_to_update_3に格納:", name)
else:
param.requires_grad = True
params_to_update_1.append(param)
print("params_to_update_1に格納:", name)
# 最適化手法の設定
optimizer = optim.SGD([
{'params': params_to_update_1, 'lr': 1e-4},
{'params': params_to_update_2, 'lr': 5e-4},
{'params': params_to_update_3, 'lr': 1e-3}
], momentum=0.9)
学習結果は以下のようになりました。
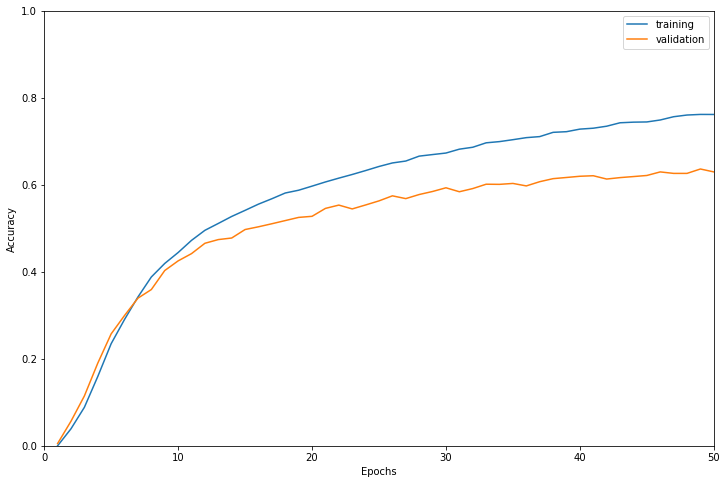
検証データに対する正解率で最も高かったのは49エポック目で正解率0.6365でした。
緩やかですがまだ検証データに対する正解率が上昇しているので、もう少しエポック数を増やしたら精度が上ったかもしれません。
学習に使用したインスタンスはml.g4dn.12xlargeで学習時間は11705秒でした。
5.4 DenseNet-201
DenseNet-201でのとネットワークの付替え部分および学習率の設定配下です。
net = models.densenet201(pretrained=use_pretrained)
# DenseNet-201の最後の出力層の出力ユニットを料理画像のクラス数の256に付け替える
net.classifier = nn.Linear(in_features=1920, out_features=256)
# update_param_names_1 = ["layer3", "layer2"]
update_param_names_2 = ["features.denseblock4"]
update_param_names_3 = ["classifier.bias", "classifier.weight", "features.norm5.bias", "features.norm5.weight"]
# パラメータごとに各リストに格納する
for name, param in net.named_parameters():
# if name in update_param_names_1:
# param.requires_grad = True
# params_to_update_1.append(param)
# print("params_to_update_1に格納:", name)
if update_param_names_2[0] in name:
param.requires_grad = True
params_to_update_2.append(param)
print("params_to_update_2に格納:", name)
elif name in update_param_names_3:
param.requires_grad = True
params_to_update_3.append(param)
print("params_to_update_3に格納:", name)
else:
param.requires_grad = True
params_to_update_1.append(param)
print("params_to_update_1に格納:", name)
# 最適化手法の設定
optimizer = optim.SGD([
{'params': params_to_update_1, 'lr': 1e-4},
{'params': params_to_update_2, 'lr': 5e-4},
{'params': params_to_update_3, 'lr': 1e-3}
], momentum=0.9)
学習結果は以下のようになりました。
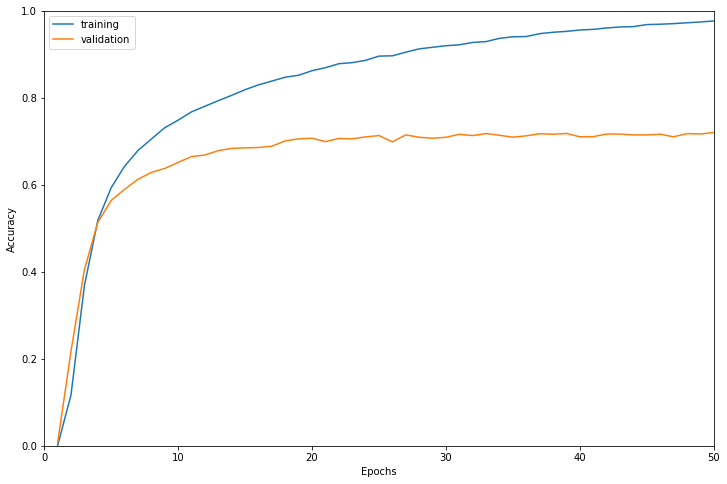
検証データに対する正解率で最も高かったのは50エポック目で正解率0.7204でした。
だいたい20エポックくらいで検証データに対する精度が頭打ちになっています。
学習に使用したインスタンスはml.g4dn.12xlargeで学習時間は30445秒でした。
5.5 ResNet-152
ResNet-152でのとネットワークの付替え部分および学習率の設定は以下です。
net = models.resnet152(pretrained=use_pretrained)
# ResNet-152の最後の出力層の出力ユニットを料理画像のクラス数の256に付け替える
net.fc = nn.Linear(in_features=2048, out_features=256)
# ファインチューニングで学習させるパラメータを、変数params_to_updateの1~3に格納する
params_to_update_1 = []
params_to_update_2 = []
params_to_update_3 = []
# 学習させる層のパラメータ名を指定
# update_param_names_1 = ["layer3", "layer2"]
update_param_names_2 = ["layer4"]
update_param_names_3 = ["fc.weight", "fc.bias"]
# パラメータごとに各リストに格納する
for name, param in net.named_parameters():
# if name in update_param_names_1:
# param.requires_grad = True
# params_to_update_1.append(param)
# print("params_to_update_1に格納:", name)
if update_param_names_2[0] in name:
param.requires_grad = True
params_to_update_2.append(param)
print("params_to_update_2に格納:", name)
elif name in update_param_names_3:
param.requires_grad = True
params_to_update_3.append(param)
print("params_to_update_3に格納:", name)
else:
param.requires_grad = True
params_to_update_1.append(param)
print("params_to_update_1に格納:", name)
# 最適化手法の設定
optimizer = optim.SGD([
{'params': params_to_update_1, 'lr': 1e-4},
{'params': params_to_update_2, 'lr': 5e-4},
{'params': params_to_update_3, 'lr': 1e-3}
], momentum=0.9)
学習結果は以下のようになりました。
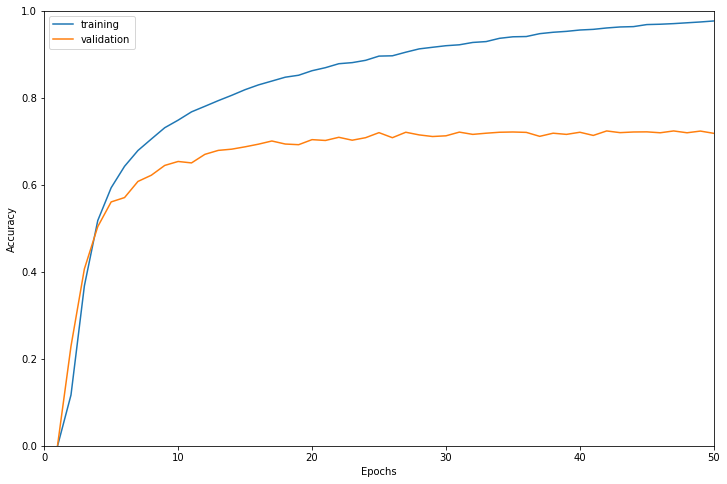
検証データに対する正解率で最も高かったのは42エポック目で正解率0.7240でした。
だいたい30エポック手前で検証データに対する精度が頭打ちになっています。
学習に使用したインスタンスはml.g4dn.16xlargeで学習時間は35905秒でした。
5.6 Wide ResNet-101-2
Wide ResNet-101-2でのとネットワークの付替え部分および学習率の設定は以下です。
net = models.wide_resnet101_2(pretrained=use_pretrained)
# Wide ResNet-101-2の最後の出力層の出力ユニットを料理画像のクラス数の256に付け替える
net.fc = nn.Linear(in_features=2048, out_features=256)
params_to_update_1 = []
params_to_update_2 = []
params_to_update_3 = []
# 学習させる層のパラメータ名を指定
update_param_names_1 = ["layer4"]
update_param_names_2 = ["fc.bias", "fc.weight"]
# パラメータごとに各リストに格納する
for name, param in net.named_parameters():
if update_param_names_1[0] in name:
param.requires_grad = True
params_to_update_2.append(param)
print("params_to_update_2に格納:", name)
elif name in update_param_names_2:
param.requires_grad = True
params_to_update_3.append(param)
print("params_to_update_3に格納:", name)
else:
param.requires_grad = True
params_to_update_1.append(param)
print("params_to_update_1に格納:", name)
# 最適化手法の設定
optimizer = optim.SGD([
{'params': params_to_update_1, 'lr': 1e-4},
{'params': params_to_update_2, 'lr': 5e-4},
{'params': params_to_update_3, 'lr': 1e-3}
], momentum=0.9)
学習結果は以下のようになりました。
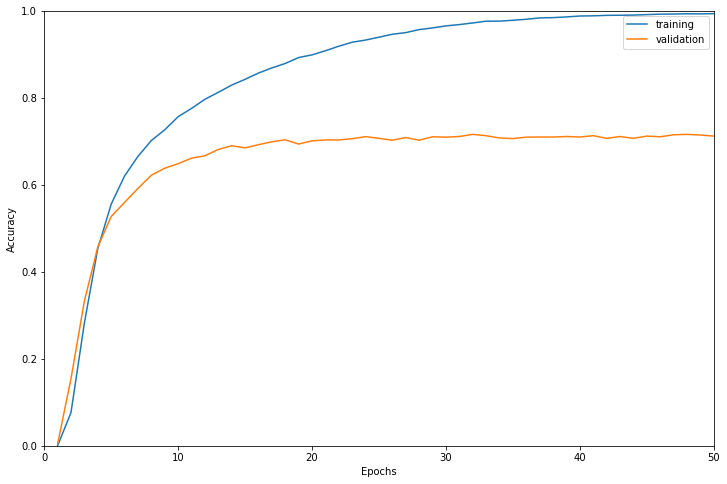
検証データに対する正解率で最も高かったのは32エポック目で正解率0.7161でした。
だいたい20エポックで検証データに対する精度が頭打ちになっています。
学習に使用したインスタンスはml.g4dn.16xlargeで学習時間は48949秒でした。
6. まとめ
結果をまとめると次のようになります。
精度はDenseNet-201、Wide ResNet-101-2とほぼ横並びですが、ResNet-152が最もよくなりました。
学習時間はWide ResNet-101-2、ResNet-152が長く、高いスペックのインスタンスでもかなりの時間を要しました。Wide ResNet-101-2とAlexNetでは実に7倍近くの学習時間の差が出ました。
一方でDenseNet-201は学習時間はResNet-152、Wide ResNet-101-2ほど長くなく必要なマシンのスペックも控えめなのでトータルで見ると最も優秀な学習済みモデルかもしれません。(あくまで今回の結果で、ですが)
| VGG-16 | AlexNet | GoogleNet | DenseNet-201 | ResNet-152 | Wide ResNet-101-2 | |
|---|---|---|---|---|---|---|
| 学習用インスタンス | ml.g4dn.16xlarge | ml.g4dn.12xlarge | ml.g4dn.12xlarge | ml.g4dn.12xlarge | ml.g4dn.16xlarge | ml.g4dn.16xlarge |
| 学習時間(秒) | 27025 | 7343 | 11705 | 30445 | 35905 | 48949 |
| 検証データに対する精度 | 0.6480 | 0.5195 | 0.6365 | 0.7204 | 0.7240 | 0.7161 |