Athenaでは事前にデータベースおよびテーブルを定義しておく必要がありますが、その際に指定する名前に日本語が使えるのか気になったので、試してみました。
Athenaについては、以下のページにて簡単にまとめましたので、ご確認ください。
Amazon Athenaにおける文字コードの考え方 -Athenaとは?-
Athenaの仕様
Athenaにおける各要素の命名について、公式ドキュメントを確認したところ、以下の記載がありました。
Athena のテーブル名とテーブルの列名は小文字にする必要があります。
Apache Spark を使用する場合は、テーブル名とテーブルの列名を小文字にする必要があります。
Athena では大文字と小文字を区別せず、テーブル名と列名を小文字に変換しますが、Spark には最初から小文字のテーブル名と列名が必要です。
大小文字が混在する列名 (profileURI) や大文字の列名が含まれているクエリは無効です。
Athena のテーブル、データベース、および列の名前に使用できる特殊文字はアンダースコアのみです。
Athena のテーブル、データベース、および列の名前にアンダースコア (_) 以外の特殊文字を含めることはできません。
ふむ、つまりはこういうことだと理解しました。
- テーブル、データベース、および列名には以下の制約がある
- 小文字はOK
- 大文字は小文字に変換される
- 特殊文字はアンダースコア( _ )のみOK
- 言い換えると、日本語は使用できない
日本語を指定する方法
上記のとおり、公式では日本語は使えないと読める記述がありましたが、ちょっとした工夫で日本語を指定することができました。
データベース、テーブル作成DDL
結論から言えば、データベース、テーブル、列名をバッククォート( ` )で囲んだDDLであれば日本語で作成できちゃいます。
※日本語のほか、アンダースコア( _ )以外の特殊文字も指定できることを一部確認しました
※ダブルクォートやシングルクォートで囲んだり、囲み無しの場合はエラーとなりました
CREATE DATABASE `テストデータベース`;
CREATE EXTERNAL TABLE IF NOT EXISTS `テストデータベース`.`テストテーブル` (
`名前` string,
`メールアドレス` string,
`性別` string,
`年齢` int
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = ',',
'field.delim' = ','
)
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.IgnoreKeyTextOutputFormat'
LOCATION 's3://<スキャン対象のデータがあるS3の場所>/'
TBLPROPERTIES (
'has_encrypted_data'='false',
'skip.header.line.count'='1' ←スキャンデータにヘッダーが含まれている場合は必要
)
上記のクエリを実行した結果がこちら。
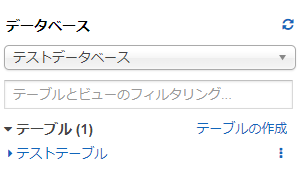
ご覧の通り、ちゃんと日本語名のデータベース、テーブルが作成されています。
日本語名テーブルへのクエリ
上記で作成したテーブルへクエリを投げる際も、少しだけ工夫が必要です。
SELECT * FROM テストデータベース.テストテーブル;だとエラーになります。
かと言ってSELECT * FROM `テストデータベース`.`テストテーブル`;とすると、エラーにはなりませんが、レコードがうまく返ってきません。
結論としては、SELECT * FROM "テストデータベース"."テストテーブル";のように、データベース、テーブル名をダブルクォート( " )で囲んであげると、以下のようにレコードが返ってきます。
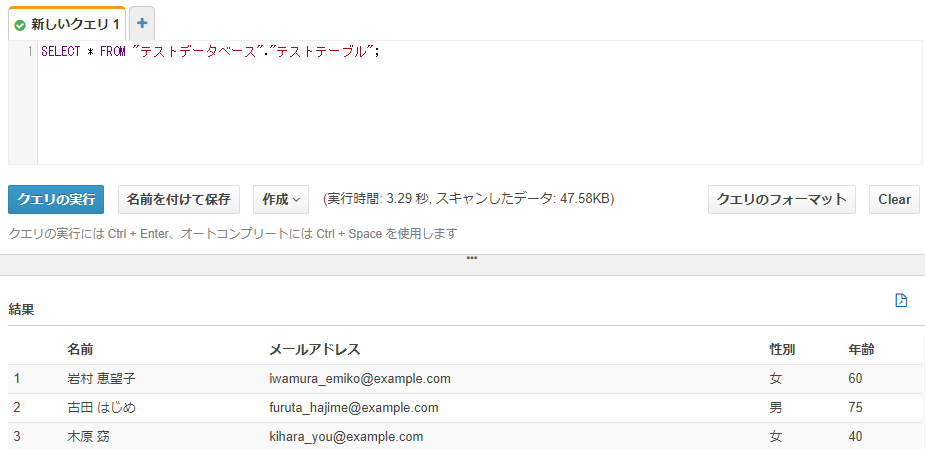
※そういえば、列名もちゃんと日本語になってますね
日本語名のテーブルを使うことによる不都合
テーブル名を指定する以下のDDLでエラーが発生しました。
DESCRIBE `<日本語テーブル名>`ALTER TABLE `<日本語テーブル名>` ADD PARTITION (<パーティション句>)
DROP TABLE `<日本語テーブル名>`は使えたので、日本語名のテーブルを作成できるけど削除できない、なんてカオスな事態にはならないようで安心しました。
が、パーティション切れないのは正直イタいですね。。。
まとめ
- Athenaでは、テーブル、データベース、および列名に日本語やアンダースコア( _ )以外の特殊文字を使用することはサポートされていない
- 定義時にデータベース、テーブル、列名をバッククォート( ` )で囲むことで、日本語や特殊文字の指定が可能
- 日本語名のテーブルに対して、ADD PARTITIONは使えない
所詮はサポートされていない非公式な定義方法なので、
「どうしても日本語で定義したい、かつパーティション切るほどでもない」
といったニーズがある場合(そんなニーズあるのかは置いといて)は、今回お伝えした方法を試してもらえればと思います。