Athenaを利用する際、文字コードを意識する機会があったのでまとめてみました。
Athenaとは?
S3上のデータに対して、SQLによるクエリを投げてデータの分析を行うことができるサービスです。
Presto 0.172およびHive DDLに基づくクエリエンジンとなっております(Presto、Hiveが何なのかは正直よくわからん)。
特徴をまとめると以下になります。
- サーバレスでインフラ管理の必要なし
- 大規模データに対しても高速なクエリ
- 事前のデータロードなしにS3に直接クエリ
-
ただし、事前にデータベースとテーブルを作成しておく必要あり
- DDLクエリによる作成のほか、管理コンソールから数クリックで作成することも可能
-
ただし、事前にデータベースとテーブルを作成しておく必要あり
- スキャンしたデータに対しての従量課金
- S3のデータスキャンに対して、$5 / 1TB料金
- 10MB未満のクエリは10MBに切り上げ
- そのほか、リージョンをまたぐ場合はデータ転送料金がかかる
- Ex) 東京リージョンのS3上のデータに対して、オハイオリージョンのAthenaでクエリを投げるなど
- S3のデータスキャンに対して、$5 / 1TB料金
- JDBC経由でBIツールから直接クエリ
ほかにも、パフォーマンスやコストを意識した使い方(パーティション、列指向フォーマット)、Athenaの制約など色々あるんですが、話が大きく脱線しますので割愛します。
詳しく知りたい方は以下をご確認ください。
AWS Black Belt Online Seminar 2017 Amazon Athena
遭遇した事象
前提
- スキャン対象のデータ
- CSV
- 文字コードはSJIS
- データには日本語文字を含む
- 定義したテーブル情報
- SerDe(シリアライザー/デシリアライザー)にLazySimpleSerDeを指定
- その他の設定は以下のDDLを確認
CREATE EXTERNAL TABLE IF NOT EXISTS testdb.testtable (
name string,
mailaddress string,
sex string,
age int
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = ',',
'field.delim' = ','
)
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.IgnoreKeyTextOutputFormat'
LOCATION 's3://<スキャン対象のデータがあるS3の場所>/'
TBLPROPERTIES (
'has_encrypted_data'='false',
'skip.header.line.count'='1' ←スキャンデータにヘッダーが含まれている場合は必要
)
クエリ実行結果
クエリ(SELECT * FROM testdb.testtable limit 10;)を実行すると、結果が文字化けしてしまいました。南無三。
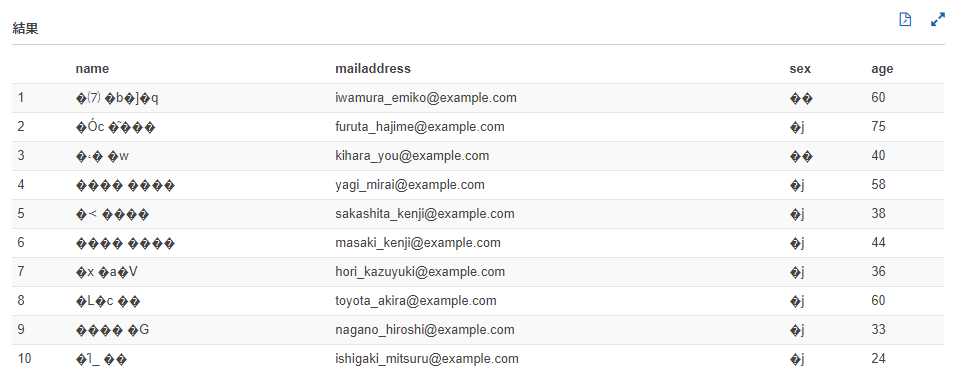
対応したこと
原因はスキャンデータの文字コードなのでは?と思いました。
以下のいずれかの対応を行うことで、このように文字化けを回避することができました。
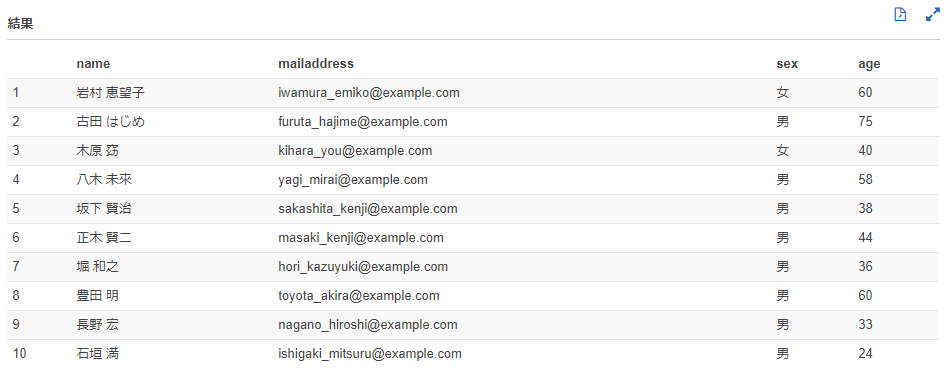
対応その1:スキャンデータの文字コードを変更する
スキャン対象のデータはSJISだったので、UTF-8に変更しました。
※こういうときは、「ええい!とりあえずUTF-8や!」というタイプの人間です
すると、文字化けすることなくレコードが返ってきました。
対応その2:serialization.encodingプロパティを指定する
詳細は後述しますが、実はAthenaでは、テーブル定義時にserialization.encodingプロパティというものを指定できます。
以下のように定義したテーブルに対してクエリを実行すると、こちらも文字化けすることなくレコードが返ってきました。
CREATE EXTERNAL TABLE IF NOT EXISTS testdb.testtable (
name string,
mailaddress string,
sex string,
age int
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = ',',
'field.delim' = ','
)
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.IgnoreKeyTextOutputFormat'
LOCATION 's3://<スキャン対象のデータがあるS3の場所>/'
TBLPROPERTIES (
'has_encrypted_data'='false',
'skip.header.line.count'='1',
'serialization.encoding'='SJIS' ←ここを追加した
)
どっちがいいの?
スキャンデータが数ファイルだけで構成されているようであれば、ファイルを1つずつUTF-8に変換でもいいかもしれません。
が、serialization.encodingを設定しちゃったほうがはるかに楽ですね。
Athenaに文字コードの制約はあるのか?
Athenaとしては、文字コードに関する明示的な制約はなく、AWSの公式ドキュメントでも言及されてません。
ただし、データの解釈においては各SerDeごとの仕様に依存します。
今回使用したSerDe「LazySimpleSerDe」の場合、デフォルトではUTF-8を使用してデータの解釈を行うため、SJISを含んだCSVファイルへのクエリ結果が文字化けしたと考えられます。
AthenaにおけるSerDeについては、以下をご確認ください。
まとめ
- Athenaでは、文字コードに関する明示的な制約はない(AWSのドキュメントにも言及されていない)
- 使用するSerDeの種別およびserialization.encodingプロパティの指定次第では、文字化けの回避が可能