背景
- とある測定データを読み込む⇒グラフ化する一連の流れをメソッドで実装しようと考えた。
- 実務で扱うデータ元が多岐に渡るため、将来も含め整合性のあるコードを書き続けられるか不安である。
目的
- ポリモルフィズム(polymorphism)と抽象クラス(abstract class)を学んだので用例を提示してみる。
- 抽象メソッドを用いることで、データ元毎にクラスが異なっても読み込み⇒グラフ化を同じメソッド名で実装できるようにする。
⇒将来記憶が消えかけた時に同様のコードを書いても同じ実装ができるようにする
感想
-
もし記憶が消えかかったころに新規の測定器で採ったデータを扱うことになるとしても、同じメソッド名で操作するコードを書くことを自分に強制できそうだ。
-
測定データを元にどのサブクラスを用いるか振り分けられれば、色々なデータをforループ一発で処理できそう。次のテーマにしたい。
-
この方法で一通り必要なものを自作モジュールで作成しておけば、実行部コードがかなり簡略化しそう。
コード
from abc import ABCでモージュールを読み込み、ABCを継承したクラスを作成することで抽象クラス(abstract class)の定義を行った。
abstract class:これを継承したサブクラスは必ず抽象メソッドをオーバーライトしなければならない
抽象クラス内にデータ読み込みメソッドと、グラフプロットメソッドを作成し、from abc import abstractclassmethodで読み込んだ@abstractclassmethodでデコレートした。
これにより、それぞれのメソッドは抽象化され、サブクラス作成時にオーバーライトが要求されるようになった。
import numpy as np
import pandas as pd
from abc import ABC, abstractclassmethod
# abstract classの定義
# abstract classの意義⇒これを継承したサブクラスは必ず抽象メソッドをオーバーライドしなければならない
class MeasurementData(ABC):
def __init__(self, data_path):
self.data_path = data_path
# データ読み込み抽象メソッド
@abstractclassmethod
def read_data(self):
return pd.read_csv(self.data_path, encoding='sjis')
# グラフプロット抽象メソッド
@abstractclassmethod
def plot(self):
return pd.plot.scatter(self.read_data)
# 一つ目のサブクラスの定義
class A_inst(MeasurementData):
def __init__(self, data_path, name):
super().__init__(data_path)
self.name = name
#オーバーライトしている
def read_data(self):
return pd.read_csv(self.data_path, engine='python', header=None)
#オーバーライトしている
def plot(self, ax):
return self.read_data().plot(ax=ax, x=0, y=1)
# 二つ目のサブクラスの定義
class B_inst(MeasurementData):
def __init__(self, data_path, name):
super().__init__(data_path)
self.name = name
#A_instとは異なる内容でオーバーライトしているが、メソッド名は同じである
def read_data(self):
return pd.read_csv(self.data_path,usecols=[0, 1, 3], engine='python', header=None)
#A_instとは異なる内容でオーバーライトしているが、メソッド名は同じである
def plot(self, ax):
return self.read_data().plot(ax=ax, x=0, y=3)
下記の測定データを用意した
data_list_inst_A = [
'sample_data_for_polymorphism1-1.csv',
'sample_data_for_polymorphism1-2.csv'
]
data_list_inst_B = [
'sample_data_for_polymorphism2-1.csv',
'sample_data_for_polymorphism2-2.csv'
]
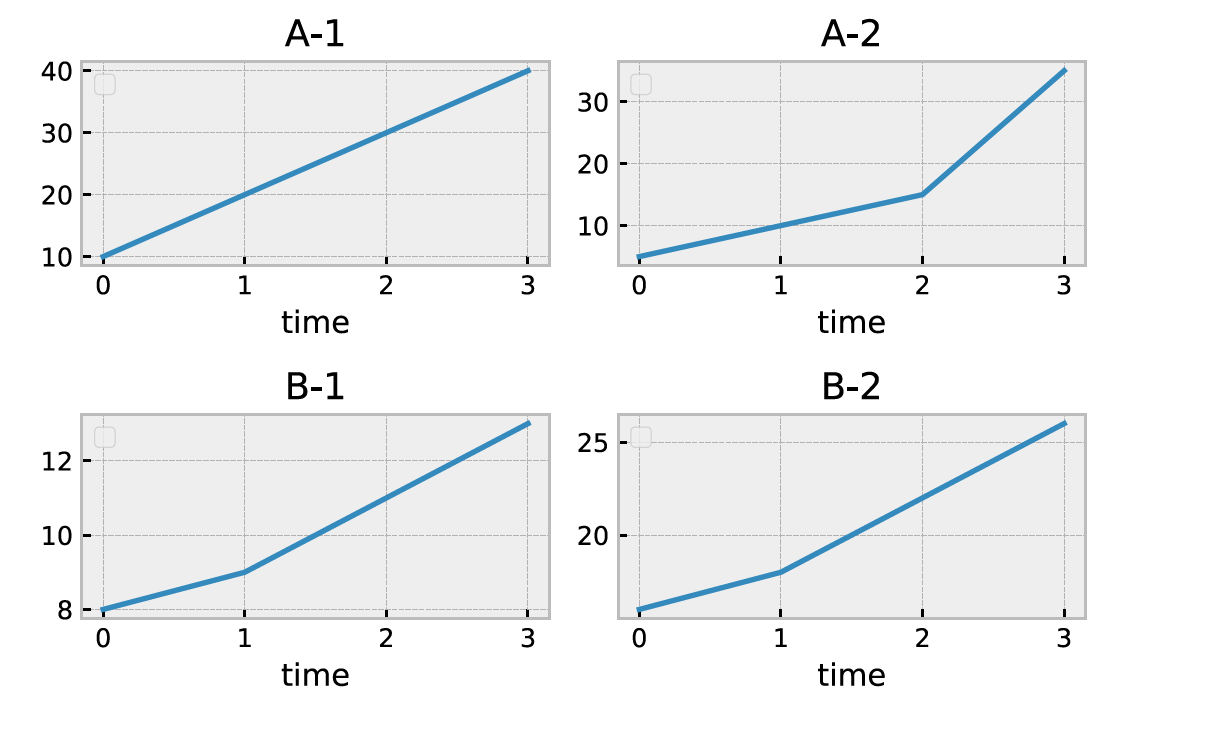
データの中身
A-1
0 1
0 0 10
1 1 20
2 2 30
3 3 40
A-2
0 1
0 0 5
1 1 10
2 2 15
3 3 35
B-1
0 1 3
0 0 1 8
1 1 2 9
2 2 3 11
3 3 4 13
B-2
0 1 3
0 0 2 16
1 1 4 18
2 2 8 22
3 3 12 26
main.py
import matplotlib.pyplot as plt
plt.style.use('bmh')
fig, ax = plt.subplots(len(data_list_inst_A), 2)
ax=ax.flatten()
for i, data in enumerate(data_list_inst_A):
temp_data_ins = A_inst(data, f'A-{i+1}')
temp_data_ins.read_data()
temp_data_ins.plot(ax=ax[i])
ax[i].set(title=temp_data_ins.name,xlabel='time')
ax[i].legend([])
off_set = len(data_list_inst_A)
for i, data in enumerate(data_list_inst_B):
temp_data_ins = B_inst(data, f'B-{i+1}')
temp_data_ins.read_data()
temp_data_ins.plot(ax=ax[i+off_set])
ax[i+off_set].set(title=temp_data_ins.name, xlabel='time')
ax[i+off_set].legend([])
plt.tight_layout()
plt.show()
実行結果