本記事では、AIモデルの開発から運用までを支える「MLOps」の基礎を、実際に手を動かして学べるハンズオン形式で解説します。
「MLOpsという言葉は知っているけれど、具体的に何をすればいいかわからない」「モデルを作った後の運用フローを体験してみたい」という方向けにAIエージェントと共同で執筆しました。理論だけでなく、Dockerベースの環境で一通りのパイプラインを構築することを目指します。
MLOpsとは?
機械学習の「運用」を支える仕組み
**MLOps(Machine Learning Operations)**とは、機械学習モデルの開発、デプロイ、運用を持続的かつ安定的に行うための仕組みや文化を指します。ソフトウェア開発における「DevOps」の考え方を、機械学習特有の性質(データへの依存性や継続的な改善の必要性など)に合わせて適用したものです。
なぜMLOpsが必要なのか?
AI開発には、従来のソフトウェア開発とは異なる特有の難しさがあります。
- データへの依存性: 同じコードでも、入力されるデータが変われば結果(モデル)が変わります。
- 継続的な改善: モデルは一度作って終わりではなく、データの変化に合わせて継続的に改善が求められます。
- 再現性と安定性: 「いつ、どのデータと設定で、どのモデルが作られたか」を厳密に管理する必要があります。
これらを仕組みによって自動化・管理することで、開発スピードと品質を両立させることが可能になります。
今回構築するシステム構成
本ハンズオンでは、以下のツールを組み合わせて実践的なパイプラインを構築します。
| カテゴリ | ツール | 役割 |
|---|---|---|
| インフラ | Docker / Docker Compose | 環境の共通化とサービス連携管理 |
| 実験・モデル管理 | MLflow | パラメータ記録とモデルのバージョン管理 |
| 推論API | FastAPI | 学習済みモデルをAPIとして公開 |
| 自動化 | GitHub Actions | 学習・デプロイの自動化(CI/CD) |
| データ管理 | DVC | データセットのバージョン管理 |
全体のロードマップ
以下のステップに沿って、一歩ずつ構築を進めていきます。
- Phase 1: Dockerとuvによる基盤構築 (MLflowサーバーの起動)
- Phase 2: データ管理 (DVCによるデータバージョン管理)
- Phase 3: モデル学習とMLflowによる実験管理
- Phase 4: モデルの登録とバージョン管理 (Model Registry)
- Phase 5: モデルのAPI化と本番運用
- Phase 6: GitHub ActionsによるCI/CDパイプラインの構築
それでは、Phase 1 からスタートしましょう!
Phase 1:Dockerとuvによる基盤構築
MLOps環境の第一歩として、まずは基盤となるインフラをDocker上に構築します。
このフェーズでは、学習記録を保存するための MLflow Tracking Server と、その裏側でデータを管理する データベース(PostgreSQL) を立ち上げます。
Dockerを利用する最大のメリットは、環境の再現性です。「自分のPCでは動くのに、サーバーでは動かない」といったトラブルを防ぎ、チーム全員が全く同じ環境を即座に再現できるようになります。
システムの構成
Phase 1で構築する最小構成のシステム図は以下の通りです。
- MLflow Server: 実験管理の司令塔。ブラウザでUIを表示したり、API経由で学習結果を受け取ります。
- PostgreSQL: パラメータや精度(メトリクス)などの「数値データ」を保存するデータベースです。
- Artifact Storage: モデルのバイナリファイルやグラフ画像など、成果物を保存するストレージです。
事前準備
以下のツールがインストールされていることを確認してください。
- Docker / Docker Compose: コンテナ環境の実行に必要です。公式サイトを参考にDocker Desktopをインストールしてください。なお、Docker Desktopの商用利用は有償ですので、商用で無料利用したい場合はWSL2でDockerをインストールしてください。
- Python (3.10以上): 学習コードの実行に必要です。まだインストールしていない方は、公式サイトを参考にインストールしてください。
- uv: 高速なPythonパッケージ管理ツール。今回はこれを使ってプロジェクトを管理します。公式サイトを参考に導入してください。
- Git: コードのバージョン管理に使用します。まだインストールしていない方は、公式サイトからインストールしてください。
プロジェクトの初期化
まずは作業ディレクトリを作成し、uv を使ってプロジェクトを初期化します。
# プロジェクトディレクトリの作成と移動
mkdir mlops-hands-on
cd mlops-hands-on
# プロジェクトの初期化
uv init
# 必要なライブラリの追加
uv add mlflow fastapi uvicorn pandas scikit-learn lightgbm matplotlib psycopg2-binary
Docker設定ファイルの作成
① MLflow用 Dockerfile の作成
ファイル名を Dockerfile.mlflow として作成します。
FROM python:3.12-slim
# LightGBMの動作に必要なlibgomp1と、PostgreSQL接続に必要なライブラリをインストール
RUN apt-get update && apt-get install -y \
libgomp1 \
libpq-dev \
gcc \
&& rm -rf /var/lib/apt/lists/*
# 学習とMLflowサーバーに必要なライブラリをインストール
RUN pip install mlflow psycopg2-binary pandas lightgbm scikit-learn matplotlib
EXPOSE 5000
CMD ["mlflow", "server", \
"--host", "0.0.0.0", \
"--port", "5000", \
"--backend-store-uri", "postgresql://mlflow:mlflow@db:5432/mlflow", \
"--default-artifact-root", "mlflow-artifacts:/", \
"--artifacts-destination", "/mlruns", \
"--serve-artifacts", \
"--allowed-hosts", "*"]
-
apt-get install libgomp1: LightGBM を動作させるために必要なライブラリです。 -
--default-artifact-root: アーティファクトをサーバー経由で安全に扱うための設定です。 -
--serve-artifacts: これを有効にすることで、モデルの送受信をMLflowサーバー経由で行えるようになります。
② Docker Compose 設定の作成
複数のコンテナを一括管理するための docker-compose.yml を作成します。
version: '3.9'
services:
db:
image: postgres:15
container_name: mlflow-db
environment:
POSTGRES_USER: mlflow
POSTGRES_PASSWORD: mlflow
POSTGRES_DB: mlflow
ports:
- "5432:5432"
volumes:
- postgres_data:/var/lib/postgresql/data
mlflow:
build:
context: .
dockerfile: Dockerfile.mlflow
container_name: mlflow-server
ports:
- "5000:5000"
depends_on:
- db
volumes:
- ./mlruns:/mlruns
- .:/app
working_dir: /app
volumes:
postgres_data:
起動と確認
準備が整ったら、コンテナを起動します。
docker compose up -d --build
起動後、ブラウザで http://localhost:5000 にアクセスし、以下のようなMLflowの管理画面が表示されれば成功です!
最後に、ここまでの設定を Git に記録しておきましょう。
git add .
git commit -m "Initial commit: Setup with Docker and uv"
次は Phase 2:データ管理 (DVC) に進みます!
Phase 2:データ管理 (DVC)
Phase 1でインフラが整いました。次に着手するのは、MLOpsにおいて非常に重要な 「データのバージョン管理」 です。
機械学習では、「どのコード」で学習したかだけでなく、「どのデータ」 で学習したかが結果に直結します。本フェーズでは、データ管理ツール DVC (Data Version Control) を導入します。
データ管理のイメージ
Phase 2で構築するデータ管理の流れは以下の通りです。
なぜ DVC が必要なのか?
通常、コードは Git で管理しますが、数GBを超えるようなデータセットを Git に含めると、リポジトリが極端に重くなります。
-
DVC の役割: 実データは外部ストレージ(S3, ローカルHDD等)に保存し、Git にはデータの指紋が書かれた軽量なファイル(
.dvc)のみを保存します。 -
再現性の確保: Git のコミットと
.dvcファイルを紐付けることで、「特定のコードに対応する正確なデータ」をいつでも復元できます。
DVC の初期化とデータ準備
まず DVC を導入し、ダミーのセンサーデータを生成します。
# DVCインストール
uv add dvc
# DVCの初期化
uv run dvc init
# データを格納するフォルダ
mkdir data
次に、学習に使うデータを準備します。とはいえ実際のデータは持ち合わせていないため、代わりにデータを生成するスクリプト generate_data.py を作成し、実行します。
import pandas as pd
import numpy as np
np.random.seed(42)
n_samples = 1000
# 特徴量の生成(温度、振動、圧力、稼働時間)
data = {
"temperature": np.random.normal(50, 5, n_samples),
"vibration": np.random.normal(100, 20, n_samples),
"pressure": np.random.normal(10, 2, n_samples),
"operating_hours": np.random.uniform(0, 5000, n_samples),
}
df = pd.DataFrame(data)
# 異常ラベルの生成(温度や振動が一定値を超えると故障しやすいという簡易ルール)
logit = (df["temperature"] - 50) * 0.2 + (df["vibration"] - 100) * 0.05 + (df["pressure"] - 10) * 0.5
prob = 1 / (1 + np.exp(-logit))
df["label"] = (prob > np.random.uniform(0, 1, n_samples)).astype(int)
df.to_csv("data/data.csv", index=False)
print("Data generated: data/data.csv")
このデータには、温度や振動などの連続値が含まれており、単なる「0か1か」の単純なルールよりも複雑な関係性が含まれています。
uv run python generate_data.py
データの管理(DVC と Git の使い分け)
生成したデータを DVC の管理下に置きます。
# データをDVCの管理下に追加
uv run dvc add data/data.csv
# 生成されたメタファイルをGitで管理
git add data/data.csv.dvc data/.gitignore
git commit -m "Add data.csv via DVC"
これで、生データ data.csv は Git の管理対象から外れ、代わりに軽量な .dvc ファイルが Git で管理されるようになりました。
ローカルディレクトリを「疑似リモート」として設定
今回は手軽に試すため、ローカルの別ディレクトリをリモートストレージとして設定します。
# 疑似的なリモートストレージ用ディレクトリを作成
mkdir -p /tmp/dvc-storage
# DVCリモートとして登録
uv run dvc remote add -d myremote /tmp/dvc-storage
# データのアップロード(プッシュ)
uv run dvc push
これで、もし手元のデータを消してしまっても uv run dvc pull でいつでも復元できるようになりました。
次は Phase 3:モデル学習とMLflowによる実験管理 です!
Phase 3:モデル学習とMLflowによる実験管理
Phase 2で準備したセンサーデータを使って、実際にモデルを学習させます。このフェーズの目的は、実験の履歴を自動で記録し、後から比較できるようにすることです。
実験管理のイメージ
学習コードの実装
プロジェクト直下に main.py を作成します。モデルには数値データに強い LightGBM を使用します。
import pandas as pd
import lightgbm as lgb
import matplotlib.pyplot as plt
import mlflow
import mlflow.lightgbm
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, f1_score, roc_auc_score
# MLflowサーバーへの接続設定
mlflow.set_tracking_uri("http://localhost:5000")
mlflow.set_experiment("sensor-anomaly-detection")
# 1. データの読み込み
df = pd.read_csv("data/data.csv")
X = df.drop("label", axis=1)
y = df["label"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 2. MLflowの実行開始
with mlflow.start_run():
params = {
"objective": "binary",
"metric": "binary_logloss",
"learning_rate": 0.1,
"num_leaves": 31,
"seed": 42,
"verbose": -1 # ログをスッキリさせる
}
model = lgb.train(
params,
lgb.Dataset(X_train, label=y_train),
num_boost_round=100
)
y_pred_prob = model.predict(X_test)
y_pred = (y_pred_prob > 0.5).astype(int)
acc = accuracy_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)
auc = roc_auc_score(y_test, y_pred_prob)
# 3. パラメータとメトリクスの記録
mlflow.log_params(params)
mlflow.log_metric("accuracy", acc)
mlflow.log_metric("f1_score", f1)
mlflow.log_metric("auc", auc)
# 4. モデルと可視化結果の記録
mlflow.lightgbm.log_model(model, name="model")
lgb.plot_importance(model)
plt.title("Feature Importance")
plt.savefig("feature_importance.png")
mlflow.log_artifact("feature_importance.png")
print(f"Accuracy: {acc:.4f}, AUC: {auc:.4f}")
学習コードのポイント解説:
-
set_tracking_uri&set_experiment: 記録先のサーバー(Phase 1で立てたコンテナ)と、実験の名前(プロジェクトの単位)を指定します。 -
with mlflow.start_run(): このブロック内で行われた一連の記録が一つの「Run(実行結果)」としてグループ化されます。 -
log_params&log_metric: 学習時のパラメータ(設定)と、算出されたメトリクス(精度やF1スコアなどの評価指標)を数値データとして保存します。 -
log_model: 学習済みのモデル本体を保存します。これにより、後に紹介する「Model Registry」や「API化」でモデルを呼び出せるようになります。 -
log_artifact: 特徴量の重要度グラフなどの画像ファイルやテキストファイルを「成果物」として保存します。
学習の実行
以下のコマンドで学習を実行します。
uv run main.py
実行後、コンソールに精度(Accuracyなど)が表示されます。パラメータを書き換えて何度か実行してみると、MLflow の真価がわかります。
MLflow UI での結果確認
ブラウザで http://localhost:5000 を開くと、下図のようにこれまでの実行履歴がリストで表示されます。
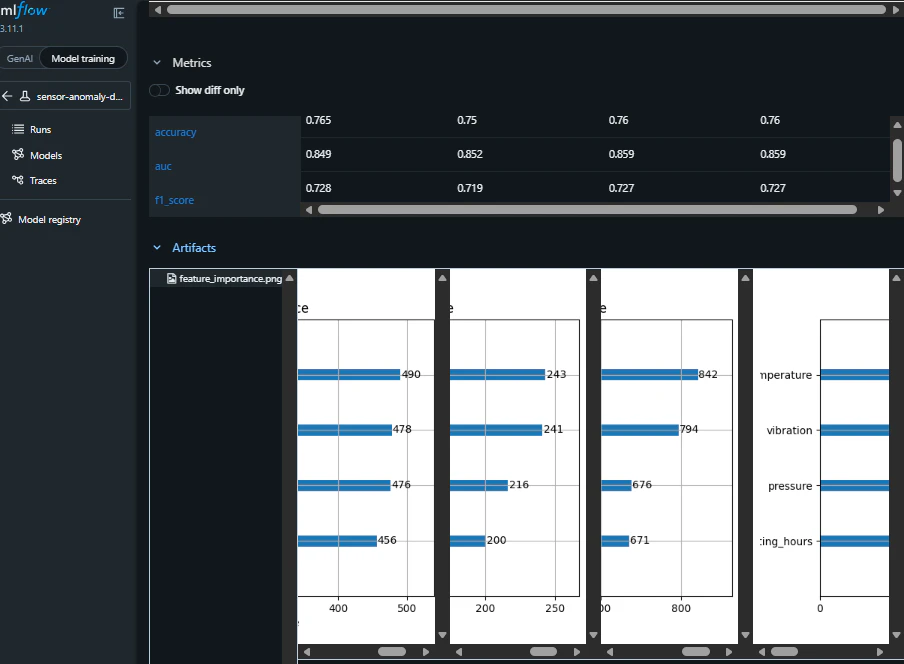
評価指標と成果物の見方
- Accuracy(正解率): 正しく予測できた割合。直感的ですが、データの偏りに注意。
- AUC: 分類能力の高さ。1.0に近いほど優秀。
- F1 Score: 「見逃し」と「誤検知」のバランス。実務で非常に重要。
- Feature Importance: どの特徴量(温度など)を重視したか。現場の知見と照らし合わせるのに役立ちます。
これで、実験の記録と管理ができるようになりました。
次は Phase 4:モデルの登録とバージョン管理 (Model Registry) です!
Phase 4:モデルの登録とバージョン管理 (Model Registry)
Phase 3では学習のたびに「履歴」が残るようになりました。しかし、実務では「たくさんある履歴の中から、どれが本番用か?」を明確に管理する必要があります。ここで登場するのが Model Registry です。
モデル管理のイメージ
モデルを「実験記録」としてだけでなく、名前を付けて 「共有可能な資産」 として管理します。
-
名前での管理: 複雑なIDではなく
sensor-anomaly-modelといった名前で呼び出せます。 - バージョン管理: 同じ名前で登録するたびに v1, v2 と自動で更新されます。
-
Alias (エイリアス): 特定のバージョンに
@production(本番用)といったラベルを貼れます。
プログラムからのモデル登録
Phase 3 の main.py を少し改良して、学習が終わった瞬間に Registry へ登録するようにします。
# 4. モデルの記録と登録 (registered_model_name を指定)
mlflow.lightgbm.log_model(
model,
name="model",
registered_model_name="sensor-anomaly-model"
)
このコードを実行すると、sensor-anomaly-model という名前でモデルが登録(初回は新規作成)されます。
本番用モデルの指定 (Alias 設定)
ここが MLOps の醍醐味です。一番良いモデルに「本番用」の印を付けます。
- MLflow UI の Model Registry 画面で
sensor-anomaly-modelを選択。 -
Aliases セクションで
productionという名前のエイリアスを最新のバージョンに追加します。
Alias を使うことで、推論サーバー(API)側は「常に
@productionとラベルされたモデルをロードする」と書いておくだけでよくなります。新しいモデルに Alias を付け替えるだけで、API側のコードを一切変えずにモデルを更新できます。
次は Phase 5:モデルのAPI化と本番運用 に進み、このモデルを外部から呼び出せるようにしましょう!
Phase 5:モデルのAPI化と本番運用
Phase 4で「本番用(@production)」としてラベル付けされたモデルができました。いよいよ、このモデルを使って外部からの予測リクエストに応答する 推論API を構築します。
推論APIのイメージ
FastAPI による推論サーバーの実装
Python の高速な Web フレームワークである FastAPI を使用します。プロジェクト直下に app.py を作成します。
import mlflow
import pandas as pd
from fastapi import FastAPI
from pydantic import BaseModel
# MLflowサーバーの設定 (コンテナ間通信のためサービス名 'mlflow' を指定)
mlflow.set_tracking_uri("http://mlflow:5000")
app = FastAPI(title="Sensor Anomaly Detection API")
class SensorData(BaseModel):
temperature: float
vibration: float
pressure: float
operating_hours: float
# Alias '@production' を指定してロード
model_uri = "models:/sensor-anomaly-model@production"
model = mlflow.pyfunc.load_model(model_uri)
@app.get("/")
def read_root():
return {"message": "Sensor Anomaly Detection API is running"}
@app.post("/predict")
def predict(data: SensorData):
input_df = pd.DataFrame([data.dict()])
prediction = model.predict(input_df)
return {
"prediction": int(prediction[0]),
"model_version": model_uri
}
API 用の Dockerfile 作成
APIをコンテナ化するため、Dockerfile.api を作成します。
FROM python:3.12-slim
# LightGBM 動作に必要な libgomp1 をインストール
RUN apt-get update && apt-get install -y \
libgomp1 \
&& rm -rf /var/lib/apt/lists/*
WORKDIR /app
COPY . .
RUN pip install mlflow fastapi uvicorn pandas lightgbm scikit-learn
# APIサーバー(Port 8000)の起動
CMD ["uvicorn", "app:app", "--host", "0.0.0.0", "--port", "8000"]
Docker Compose への統合
docker-compose.yml の services セクションに以下を追記します。
api:
build:
context: .
dockerfile: Dockerfile.api
container_name: mlflow-api
ports:
- "8000:8000"
depends_on:
- mlflow
起動と動作確認
コンテナを起動(再ビルド)します。
docker compose up -d --build
ブラウザで http://localhost:8000/docs を開くと、下図のようなSwagger UI から API をテストできます。@production ラベルを付け替えるだけで、API を再起動せずに中身のモデルを更新できる MLOps の運用フローをぜひ体感してください。
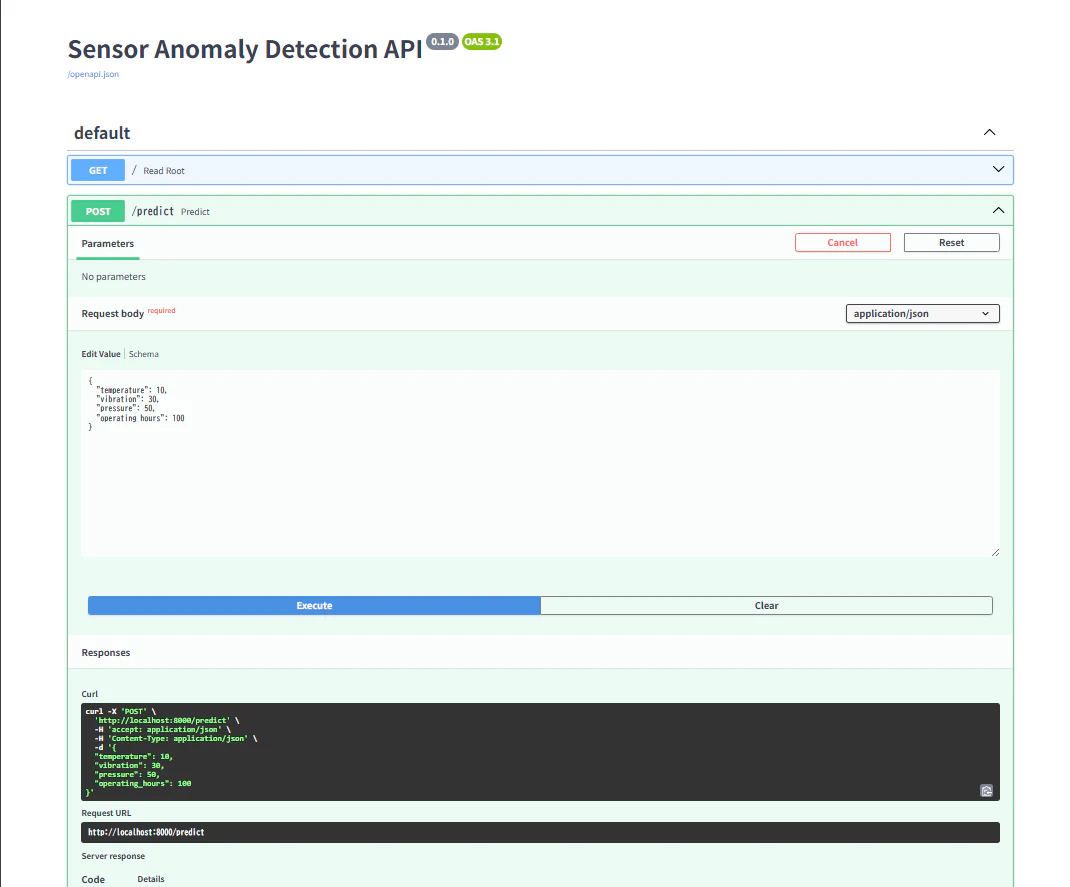
次は、これら全ての工程を自動化する Phase 6:GitHub Actions による CI/CD パイプラインの構築 です!
Phase 6:GitHub Actions による CI/CD パイプラインの構築
最後の仕上げとして、これまでの工程(データ生成、学習、モデル登録、API公開)を自動で繋ぐ CI/CD パイプライン を構築します。
自動化のイメージ
ソフトウェア開発の CI/CD に加え、機械学習では以下の概念が重要になります。
- CT (Continuous Training): 新しいコードやデータが push された際に、自動的に再学習を実行する。
- CD (Continuous Deployment): 再学習されたモデルを自動的にレジストリに登録し、推論 API に反映させる。
これらを自動化することで、人的ミスを防ぎ、常に最新かつ高品質なモデルをユーザーに提供し続けることができます。
GitHub Actions で動かした API はテストが終わると自動的に消去されるため、ブラウザからアクセスすることはできません。ここでの目的は「コードの変更がシステムを壊さないか自動で検証すること」にあります。実際にユーザーが使えるようにするには、ここからさらにクラウドサーバー等へデプロイする工程が必要になります。ですので厳密には本ハンズオンではCIのみを実装しています。
ワークフローファイルの作成
GitHub Actions の設定ファイル .github/workflows/mlops.yml を作成します。
name: MLOps Hands-on Pipeline
on:
push:
branches: [ main ]
pull_request:
branches: [ main ]
jobs:
train-and-deploy:
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v4
- name: Set up Docker Buildx
uses: docker/setup-buildx-action@v3
- name: Build and start containers
run: docker compose up -d --build
- name: Wait for MLflow to be ready
run: sleep 20
- name: Run training (Continuous Training)
run: |
# 1. 学習データの生成 (DVC管理下のデータはGitにないためCI内で生成)
docker compose exec -T mlflow python generate_data.py
# 2. モデル学習とレジストリ登録
docker compose exec -T mlflow python main.py
- name: Set Model Alias (Continuous Deployment)
run: |
# 3. 学習された最新モデルに @production エイリアスを付与
docker compose exec -T mlflow python -c "import mlflow; mlflow.set_tracking_uri('http://localhost:5000'); from mlflow import MlflowClient; MlflowClient().set_registered_model_alias('sensor-anomaly-model', 'production', '1')"
- name: Restart API to load new model
run: |
# 4. 推論APIを再起動して最新モデルをロードさせる
docker compose restart api
sleep 10
- name: Verify API
run: |
# 5. API が正常に応答するか確認
curl -s http://localhost:8000/ | grep "Sensor Anomaly Detection API is running"
ポイント解説:
-
docker compose up -d: GitHub Actions のランナー環境内で、Phase 1 で作成したインフラを一瞬で立ち上げます。 -
docker compose exec: 立ち上がったコンテナ内でmain.pyを実行し、自動で学習とモデル登録(Phase 3, 4 の工程)を行います。 - --alias production --version 1: 最新モデル(version1)をaliasでproductionとするように設定しています。
-
curl: API が正しく起動しているかを確認します。
自動化の体験(リポジトリの作成とPR)
このワークフローを動かすには、コードを GitHub に Push する必要があります。
- GitHub で新しいリポジトリを作成します。
- ローカルリポジトリを紐付け、
mainブランチへ Push します。 - GitHub 上の「Actions」タブで、自動的に学習とデプロイ(API確認)が走り出すのを確認してください。
今回の自動化では「最新モデルを即座に本番用」としていますが、実務では精度を比較するロジックを入れたり、Phase 4 のように人間が UI 上で最終確認(Human-in-the-loop)を行う運用が一般的です。まずはこの「自動で全てが繋がる感覚」を掴むことが第一歩です。
おわりに
お疲れ様でした!これで本ハンズオンの全ての工程が完了しました。
本記事で扱ったもの
- Docker: インフラのコード化(IaC)
- DVC: データのバージョン管理
- MLflow: 実験管理とモデルレジストリ
- FastAPI: 推論エンジンの API 化
- GitHub Actions: ワークフローの自動化
今後の展望
今回はローカル環境(および GitHub Actions 内)での完結でしたが、次のステップとしては以下のような内容が考えられます。
- クラウドストレージ(Amazon S3等)との連携
- Kubernetes 等を用いた大規模なデプロイ
- ドリフト検知(データの性質変化の監視)
MLOps は奥が深い分野です。プロジェクトによって利用するフレームワーク、インフラおよびパイプラインの構成も異なりますが、本記事で構築した「最小構成」のイメージがあれば、より大規模なシステムにも応用が効くはずです。ぜひ今回の環境をベースにハンズオンを実施いただき、ご自身のプロジェクトにも MLOps 導入を検討してみてはいかがでしょうか。
付録:各Phaseで利用する全コード
本ハンズオンで作成した全てのコードをこちらにまとめています。各ファイルをプロジェクトのルートディレクトリに配置することで、一連の MLOps 環境を再現できます。
1. インフラ構成 (Docker)
Dockerfile.mlflow
FROM python:3.12-slim
# LightGBMの動作に必要なlibgomp1と、PostgreSQL接続に必要なライブラリをインストール
RUN apt-get update && apt-get install -y \
libgomp1 \
libpq-dev \
gcc \
&& rm -rf /var/lib/apt/lists/*
# 学習とMLflowサーバーに必要なライブラリをインストール
RUN pip install mlflow psycopg2-binary pandas lightgbm scikit-learn matplotlib
EXPOSE 5000
CMD ["mlflow", "server", \
"--host", "0.0.0.0", \
"--port", "5000", \
"--backend-store-uri", "postgresql://mlflow:mlflow@db:5432/mlflow", \
"--default-artifact-root", "mlflow-artifacts:/", \
"--artifacts-destination", "/mlruns", \
"--serve-artifacts", \
"--allowed-hosts", "*"]
docker-compose.yml
version: '3.9'
services:
db:
image: postgres:15
container_name: mlflow-db
environment:
POSTGRES_USER: mlflow
POSTGRES_PASSWORD: mlflow
POSTGRES_DB: mlflow
ports:
- "5432:5432"
volumes:
- postgres_data:/var/lib/postgresql/data
mlflow:
build:
context: .
dockerfile: Dockerfile.mlflow
container_name: mlflow-server
ports:
- "5000:5000"
depends_on:
- db
volumes:
- ./mlruns:/mlruns
- .:/app
working_dir: /app
api:
build:
context: .
dockerfile: Dockerfile.api
container_name: mlflow-api
ports:
- "8000:8000"
depends_on:
- mlflow
volumes:
postgres_data:
2. データ生成・学習 (Python)
generate_data.py
import pandas as pd
import numpy as np
import os
os.makedirs("data", exist_ok=True)
np.random.seed(42)
n_samples = 1000
data = {
"temperature": np.random.normal(50, 5, n_samples),
"vibration": np.random.normal(100, 20, n_samples),
"pressure": np.random.normal(10, 2, n_samples),
"operating_hours": np.random.uniform(0, 5000, n_samples),
}
df = pd.DataFrame(data)
logit = (df["temperature"] - 50) * 0.2 + (df["vibration"] - 100) * 0.05 + (df["pressure"] - 10) * 0.5
prob = 1 / (1 + np.exp(-logit))
df["label"] = (prob > np.random.uniform(0, 1, n_samples)).astype(int)
df.to_csv("data/data.csv", index=False)
print("Data generated: data/data.csv")
main.py
import pandas as pd
import lightgbm as lgb
import matplotlib.pyplot as plt
import mlflow
import mlflow.lightgbm
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, f1_score, roc_auc_score
mlflow.set_tracking_uri("http://localhost:5000")
mlflow.set_experiment("sensor-anomaly-detection")
df = pd.read_csv("data/data.csv")
X = df.drop("label", axis=1)
y = df["label"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
with mlflow.start_run():
params = {"objective": "binary", "metric": "binary_logloss", "learning_rate": 0.1, "verbose": -1}
model = lgb.train(params, lgb.Dataset(X_train, label=y_train), num_boost_round=100)
y_pred_prob = model.predict(X_test)
y_pred = (y_pred_prob > 0.5).astype(int)
mlflow.log_params(params)
mlflow.log_metric("accuracy", accuracy_score(y_test, y_pred))
mlflow.log_metric("auc", roc_auc_score(y_test, y_pred_prob))
mlflow.lightgbm.log_model(model, name="model", registered_model_name="sensor-anomaly-model")
lgb.plot_importance(model)
plt.savefig("feature_importance.png")
mlflow.log_artifact("feature_importance.png")
3. 推論 API (FastAPI)
app.py
import mlflow
import pandas as pd
from fastapi import FastAPI
from pydantic import BaseModel
mlflow.set_tracking_uri("http://mlflow:5000")
app = FastAPI(title="Sensor Anomaly Detection API")
class SensorData(BaseModel):
temperature: float
vibration: float
pressure: float
operating_hours: float
model_uri = "models:/sensor-anomaly-model@production"
model = mlflow.pyfunc.load_model(model_uri)
@app.post("/predict")
def predict(data: SensorData):
input_df = pd.DataFrame([data.dict()])
prediction = model.predict(input_df)
return {"prediction": int(prediction[0]), "model_version": model_uri}
Dockerfile.api
FROM python:3.12-slim
RUN apt-get update && apt-get install -y libgomp1 && rm -rf /var/lib/apt/lists/*
WORKDIR /app
COPY . .
RUN pip install mlflow fastapi uvicorn pandas lightgbm scikit-learn
CMD ["uvicorn", "app:app", "--host", "0.0.0.0", "--port", "8000"]
4. 自動化 (CI/CD)
.github/workflows/mlops.yml
name: MLOps Hands-on Pipeline
on: [push, pull_request]
jobs:
train-and-deploy:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Build and start
run: docker compose up -d --build
- name: Wait
run: sleep 20
- name: Training
run: |
docker compose exec -T mlflow python generate_data.py
docker compose exec -T mlflow python main.py
- name: Set Alias
run: docker compose exec -T mlflow python -c "import mlflow; mlflow.set_tracking_uri('http://localhost:5000'); from mlflow import MlflowClient; MlflowClient().set_registered_model_alias('sensor-anomaly-model', 'production', '1')"
- name: Restart and Verify
run: |
docker compose restart api
sleep 10
curl -s http://localhost:8000/