はじめに
動画配信サイト(こちら)を作成することになり、AWSの利用を開始しました。
私自身AWS初学者でありますが、自分の躓いた箇所などを投稿し、共有できればと思っております。
本記事では、S3にアップロードした動画ファイルをストリーミング配信用動画ファイル(HLS形式)へ自動変換するフローの作成手順を説明します。AWSのサービスの連携概念図は以下の通りです。
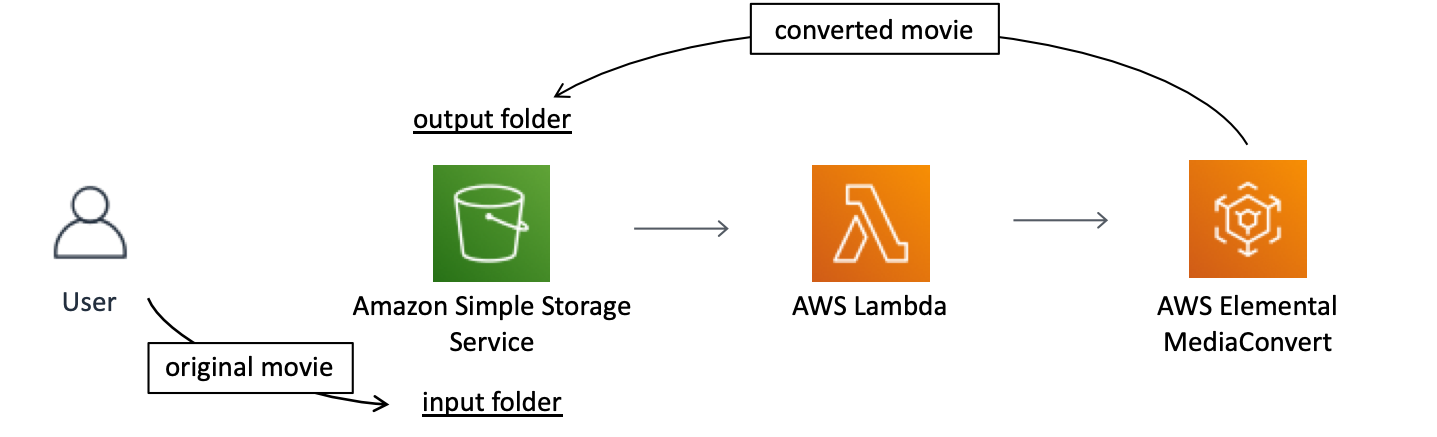
今回は同一S3バケット内に元動画アップロード用フォルダ(input folder)と変換後動画用フォルダ(output folder)を作成します。そして、input folderへのアップロードをトリガーとしてLambda、MediaConvertと連携します。
S3バケットの作成
作業概要
- S3バケットの作成
- folderの作成

特別な設定をする必要はありません。好きな名前をつけてサクッと作っていきます。説明上
input folder名:original_movie
output folder名:converted_movie
とします。
MediaConvertの設定
作業概要
- MediaConvert用のIAMロールの設定
- ジョブテンプレートの作成
1. MediaConvert用のIAMロールの設定
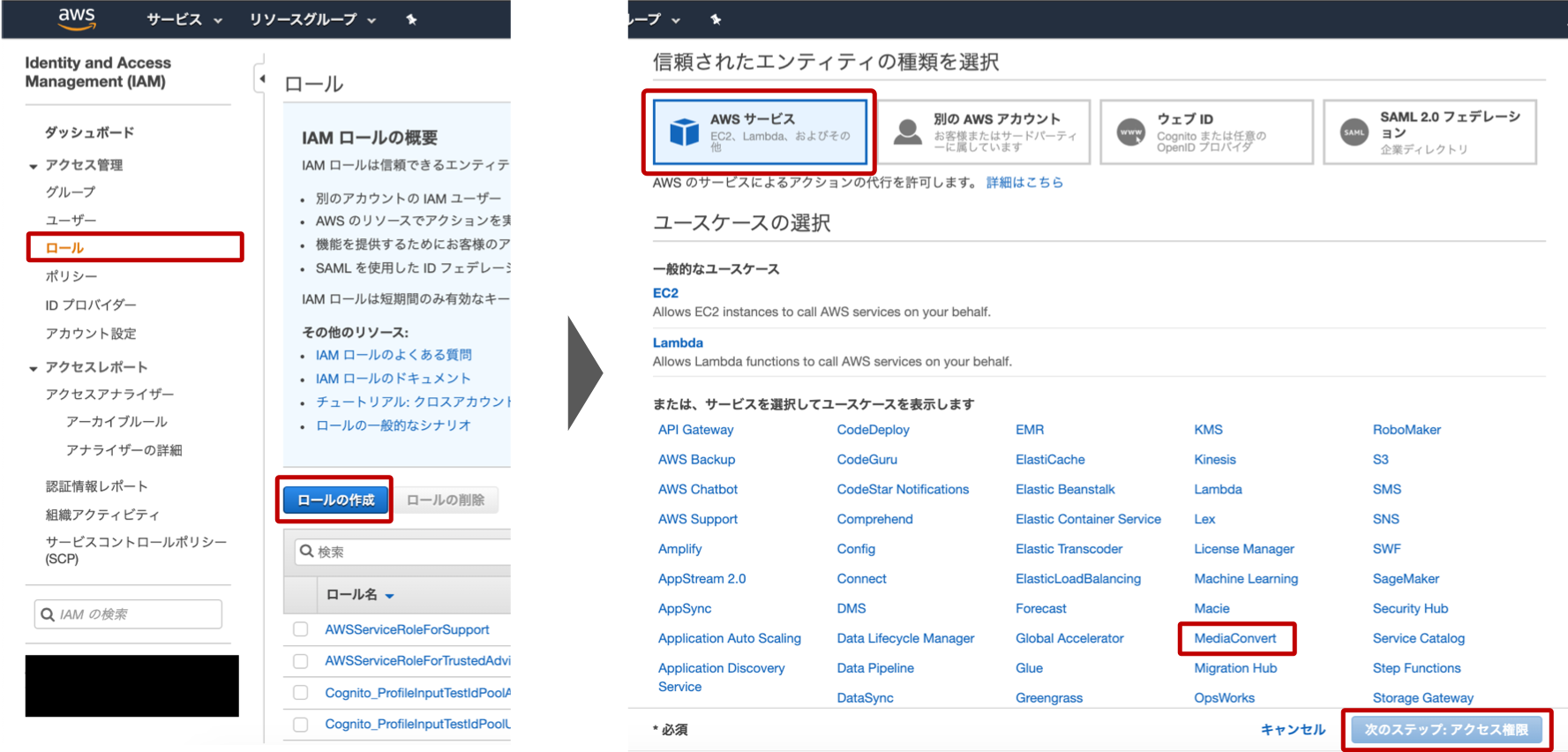
そのままMediaConvertを利用しようとしたらジョブテンプレートの作成ボタンを押すと「権限がどうのこうの〜」というエラーが返されてしまいました。はじめにMediaConvert用のIAMの設定をする必要があるようです。
サービスから「IAM」を選択し、「ロール」、「ロールの作成」の順に進んでいきます。
次に、付与するロールを選択します。「AWSサービス」→「MediaConvert」→「次のステップ:アクセス権限」→「次のステップ:タグ」→「次のステップ:確認」の順にサクサク選択していきます。最後に任意のロール名をつけます。困ったらMediaConvertDefaultRoleのようにつけてしまいましょう。
2. ジョブテンプレートの作成
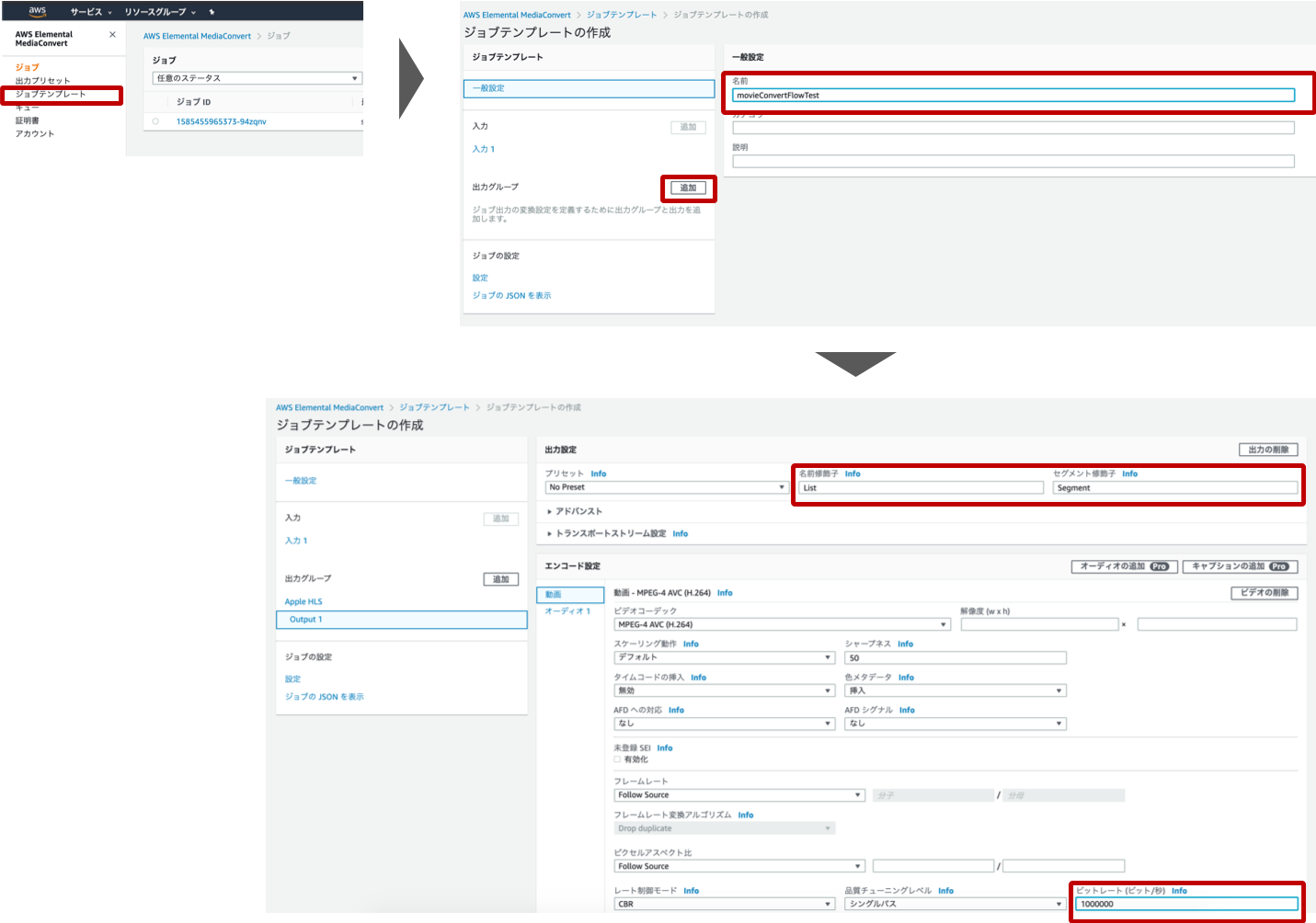
サービスから「MediaConvert」を選択します。
- 左側のナビゲーションバーからジョブテンプレートを選択
- 一般設定でジョブテンプレートの名前を入力(適当)
- 出力グループの追加
- Apple HLSを選択
- 名前修飾子、セグメント修飾子の入力(適当)
- ビットレートの入力
の順で進めていきます。文字が小さくて見えづらいかも知れませんが、おおよそこの赤枠内に対する入力を行えば大丈夫です。
名前修飾子、セグメント修飾子は変換後動画ファイル名に付されるものになります。適当に設定していきます。ここではビットレートは1000000[bit/s]としています。
最後に「作成」ボタンを押してジョブテンプレート作成完了です。
Lambdaの設定
- 関数の作成(Python3.7)
- 関数コードの編集
1. 関数の作成(Python3.7)
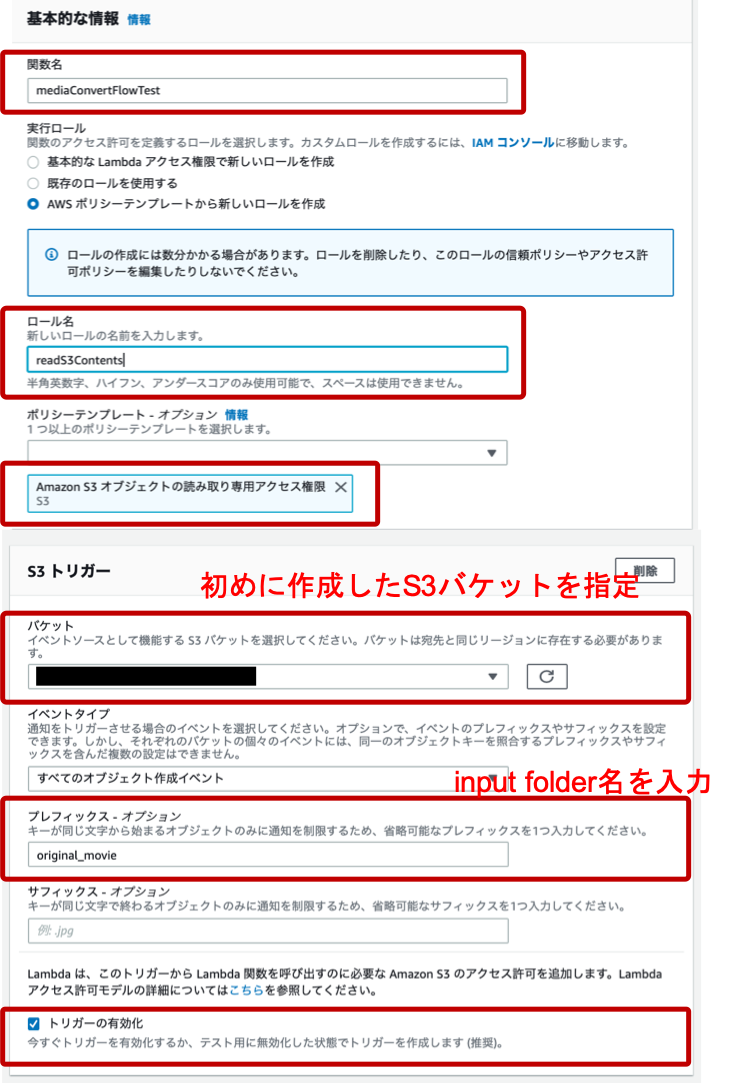
サービスから「Lambda」を選択し、「関数の作成」→「設計図の使用」→「s3-get-object-python」の順に進んでいきます。
基本的な設定、S3トリガーの設定を行います。
- Lambda関数に名前の入力(適当)
- ロール名の入力(適当)
- ポリシーテンプレートに「Amazon S3オブジェクトの読み取り専用アクセス権限」が存在することの確認
- S3バケットの指定
- プレフィックス名の指定(オプション)
※この点に関してはオプションですが、あらかじめ入力フォルダを作成していたので、original_movieを入力 - 「トリガーの有効化」にチェックを入れる
- 「関数の作成」ボタンを押す
この流れで関数の作成が完了します。
5.のプレフィックスに関してですが、ここではフォルダ名を指定しています。「プレフィックスなのにフォルダ名?」とハテナになってしまいました。S3ではkey-valueデータストア型の技術が用いられているようで、S3にはフォルダという概念がないためだそうです(参考)。
遷移後の画面で、「実行ロール」内の「既存のロール」が service-role/readS3Contents になっていることを確認してください。readS3Contentsは関数作成画面で記入したロール名になります。私の場合MediaConvertと連携するために、デフォルトのポリシーに加え、IAMFullAccess, AWSElementalMediaConvertFullAccess をアタッチしています(最善策かどうかは分かりません)。
2. 関数コードの編集
デフォルトの関数コードを編集します。
以下はサンプルコードになります。このコードの作成にあたりこちらの記事を参考にさせていただきました。
import os
import urllib.parse
import boto3
def lambda_handler(event, context):
bucket = event['Records'][0]['s3']['bucket']['name']
key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8')
settings = make_settings(bucket, key)
user_metadata = {
'JobCreatedBy': 'videoConvertSample',
}
client = boto3.client('mediaconvert', endpoint_url = <MediaConvertのAPIエンドポイント>)
result = client.create_job(
Role = <ロールのARN>,
JobTemplate = <ジョブテンプレート名>,
Settings=settings,
UserMetadata=user_metadata,
)
def make_settings(bucket, key):
basename = os.path.basename(key).split('.')[0]
return \
{
"Inputs": [
{
"FileInput": f"s3://{bucket}/{key}",
}
],
"OutputGroups": [
{
"Name": "Apple HLS",
"OutputGroupSettings": {
"Type": "HLS_GROUP_SETTINGS",
"HlsGroupSettings": {
"Destination": f"s3://{bucket}/<output folder名>/{basename}/",
},
},
"Outputs": [
{
"VideoDescription": {
"Width": 640,
"Height": 360,
},
},
],
},
],
}
4箇所の<>部分を置き換えてください。
<MediaConvertのAPIエンドポイント>
「MediaConvert」→「アカウント」の順に進むとMediaConvertのAPIエンドポイントを取得できます。
<ロールのARN>
Lambda関数の画面の実行ロールの部分からロールを表示し、遷移先でロールのARNが確認できます。
<ジョブテンプレート名>
ジョブテンプレート名に置き換えてください。
<output folder名>
output folder名(converted_movie)に置き換えてください。
動作確認
S3のoriginal_movieフォルダに動画をアップロードします。しばらくしてconverted_movieフォルダの中身を確認し、入力した動画ファイル名のファイルが作成されていて、その配下に.m3u8, .tsファイルが存在していれば成功です。
最後に
インターン先で出会った仲間で動画配信サイトを作ろう!という話になり、3ヶ月ほど前からAWSを学習し始めました。今後は自身の備忘録も兼ねて、QiitaにAWS関連の情報を投稿していこうと思います。
よろしくお願いします。