BigQueryからCloudSQLに直接クエリが実行できるようになったということですが、サービスの基盤はAWSを利用しているためDBはもちろんRDS。。。
そこでどうにかしてRDSに溜まっているデータに対してBigQueryから直接クエリを実行したいと思いやってみました。
正確には、RDSをCloudSQLでレプリケーションしてCloud SQL federated queryでBigQueryからクエリを実行してみました。
構成
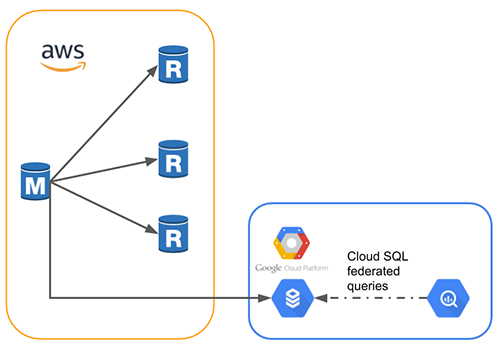
既にソースDBに対して3台のリードレプリカが作成されている状態だったので、こんな感じの構成にしていきたいと思います。
CloudSQLレプリケーション設定
外部サーバーからCloudSQLレプリカに複製する場合いくつか要件があるのでそれを満たしているか確認します。
- GTID が有効にされていて、GTID 整合性が強制されること。
問題はここでした。
AWSのドキュメントを見ると
DB インスタンスまたはリードレプリカで RDS MySQL バージョン 5.7.22 以下を使用している場合は、DB インスタンスまたはリードレプリカをアップグレードします。RDS MySQL バージョン 5.7.23 以降の MySQL 5.7 バージョンにアップグレードします。
![]()
![]()
稼働中DBのバージョンを勝手にあげる訳にはいかないので、一先ずやりたいことが出来るか検証用の環境を作って試してみます。
RDS設定
まずパラメータグループの作成を行います。
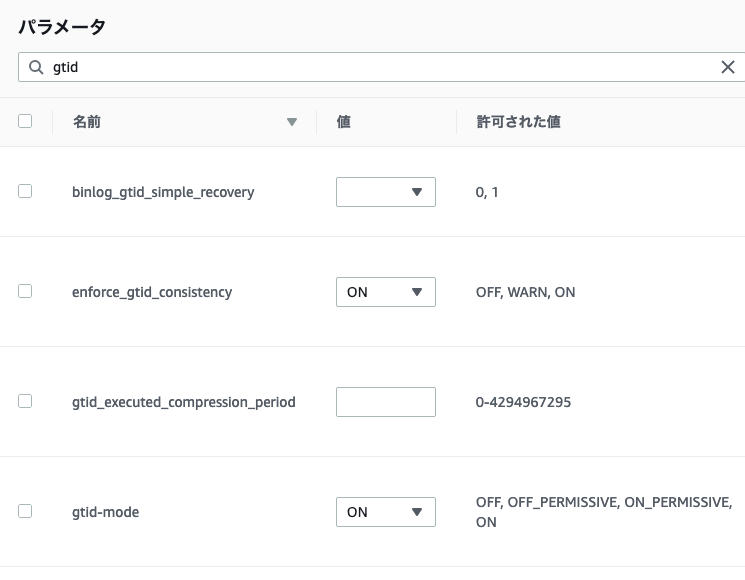
| 名前 | 値 |
|---|---|
| enforce_gtid_consistency | ON |
| gtid-mode | ON |
GTIDを使用したレプリケーションを構成するために、このように変更します。
ついでに、パブリックアクセシビリティを【はい】に変更しCloudSQLから接続できる状態にします。

RDS外部からレプリケーションを行うのでバイナリログ保持時間が適切に設定されているか確認しておきます。
mysql> call mysql.rds_show_configuration;
+------------------------+-------+------------------------------------------------------------------------------------------------------+
| name | value | description |
+------------------------+-------+------------------------------------------------------------------------------------------------------+
| binlog retention hours | NULL | binlog retention hours specifies the duration in hours before binary logs are automatically deleted. |
+------------------------+-------+------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
NULLに設定されているとバイナリログはできる限り早く消去されていくとのことなので、一先ず24時間保存するように変更します。
mysql> call mysql.rds_set_configuration('binlog retention hours', 24);
ソースDBにmysqldumpを実行しても良いのですが、後に本番環境でやることを考えてリードレプリカの一台にmysqldumpを実行したいと思います。
念の為リードレプリカのレプリケーションを停止しておきます。
mysql> CALL mysql.rds_stop_replication;
GCPのドキュメントにコマンドが記載されているのですが、そのままだとエラーになるので--master-data=1は省きます。
一つのコマンドでGCSにアップロードをしても良いのですが、今回は一度サーバー上に保存します。
$ mysqldump \
-h [MASTER_IP] -P [MASTER_PORT] -u [USERNAME] -p \
--databases [DBS] \
--hex-blob --skip-triggers \
--order-by-primary --no-autocommit \
--ignore-table [VIEW] \
--single-transaction --set-gtid-purged=on > ./dump.sql
mysqldumpが終了したらGCSにアップロードします。
$ gsutil cp ./dump.sql gs://[BUCKET]/[PATH_TO_DUMP]
CloudSQL設定
ここからやっとGCPをいじり始めます。

CloudSQLからデータ移行を選択します。
移行を開始を選択して入力が必要な部分を埋めていきます。
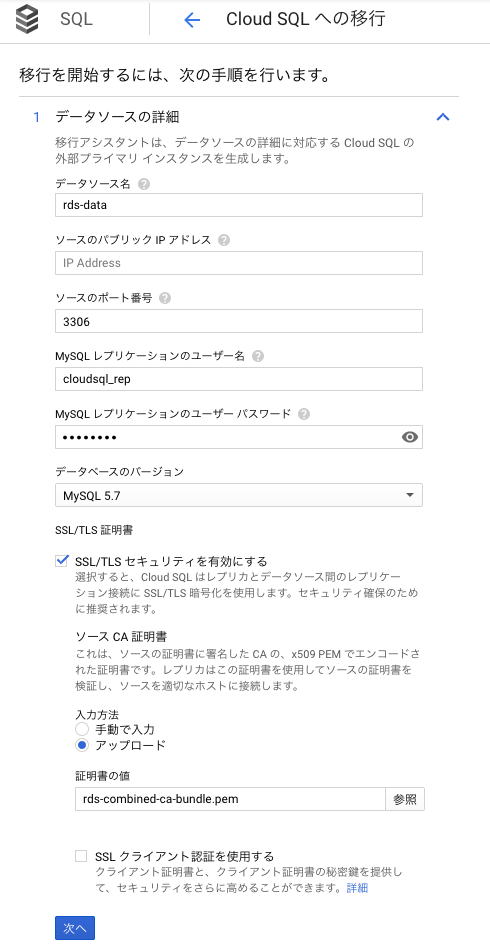
ソースのパブリックIPアドレスについては、nslookupでホストを指定して調べました。
レプリケーションユーザーですが、今回はCloudSQLのIPからのみ接続を許可したいのでRDS側には後ほどユーザーを作成したいと思います。
証明証ですが、こちらにダウンロードリンクが記載されているので入手します。
ダウンロードした証明書を指定し、【次へ】を選択。
そして__BigQueryのデータロケーションと同じゾーン__・任意のマシンタイプを選択、先ほどGCSにアップロードしたダンプファイルを指定しリードレプリカの作成をします。
CloudSQLからRDSへの接続設定
GCPドキュメントにもある通り、この作業はCloudSQLでリードレプリカの作成をしてから30分以内に行わないとリードレプリカの作成が停止します。
ということで、CloudSQLのリードレプリカ作成オペレーションの終了を待たずに並行して作業を進めていきます。
まずCloudSQLリードレプリカのIPアドレスを調べます。
$ gcloud sql instances describe [REPLICA_NAME] --format="default(ipAddresses)"
ipAddresses:
- ipAddress: xxx.xxx.xxx.xxx
type: PRIMARY
- ipAddress: xxx.xxx.xxx.xxx
type: OUTGOING
IPアドレスを取得できるようになるまで数分かかります。
CloudSQL(OUTGOINGのIP)からソースデータベースに接続できるようにRDS側でセキュリティグループ等を設定します。
次にレプリケーションユーザーを作成します。
既に作成している場合は飛ばしてください。
mysql> CREATE USER 'cloudsql_rep'@'OUTGOINGのIP' IDENTIFIED BY 'パスワード';
mysql> GRANT REPLICATION CLIENT, REPLICATION SLAVE ON *.* TO 'cloudsql_rep'@'OUTGOINGのIP';
ここまで設定したらCloudSQLにダンプファイルが復元されるまで待ちます。
CloudSQLでリードレプリカの作成が終了したら一応確認します。
mysql> SHOW SLAVE STATUS ¥G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: xxx.xxx.xxx.xxx
Master_User: cloudsql_rep
Master_Port: 3306
Connect_Retry: 60
...
無事レプリケーションができているようです。
mysqldumpを実行するためにレプリケーションを停止したリードレプリカも忘れずに再開しておきます。
mysql> CALL mysql.rds_start_replicartion;
BigQuery 接続を作成
いよいよ大詰めです。
BigQueryのコンソールから接続の作成を選択し、
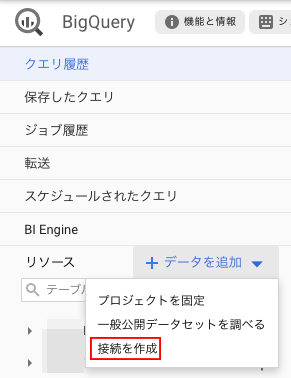
必要な情報を入力していきます。
接続を作成を選択すると・・・
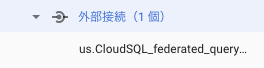
外部接続が現れました!
取り敢えずクエリを実行してみます。
SELECT * FROM EXTERNAL_QUERY("プロジェクトID.ゾーン.CloudSQL_federated_query_RDS", "SELECT * FROM INFORMATION_SCHEMA.TABLES;");
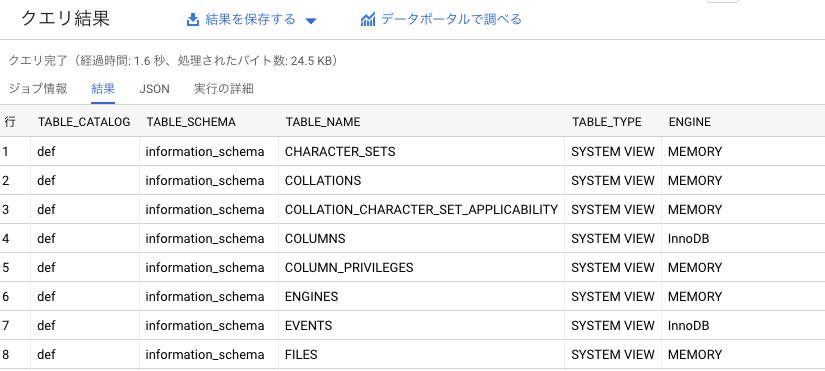
結果が返ってきました!
さいごに
残念なことに本番環境のRDSはMySQLのバージョンが要件を満たせていなかったため検証用に環境を作って試してみましたが、やりたいことはできそうなので気づかれないように本番環境のバージョンを上げておきたいと思います。
Cloud SQL federated queryについてですが、CloudSQLに対してクエリを実行しているのでBigQueryほどのスピードにはなりません。
また、クエリ結果もキャッシュされないようなのであまり調子に乗りすぎると気づかぬうちにスキャン量が積み重なってしまうかもしれません。。。
ただ、いろいろな可能性を感じられるのでいじり倒してみたいと思います。