この記事は、TensorFlow Advent Calendar 2016の18日目の記事です。
もともとはPredNetを実装しようと思ってConvLSTMを実装していたのですが、これ単体でも動画のフレーム予測ができるのでせっかくなので試してみようと思ってこの記事を書きました。
この前のTensorFlow UserGroupのイベント「NN論文を肴に飲む会」でも発表させていただきましたので、元となる論文の概要などが気になる方はこちらのスライドをご覧ください。
Convolutional LSTM(畳み込みLSTM)
名前からしてどんなものなのかという想像は簡単につくと思います。従来のLSTMでは時間遷移する状態は(バッチサイズ, 中間層のユニット数)の2階テンソルでしたが、それが(バッチサイズ,縦,横,チャンネル数)の4階テンソルになったものです。その際、扱う状態が画像情報なので、従来でしたら層間の結合は総結合だったものを畳み込みに変更したというものです。
従来のLSTMが↓
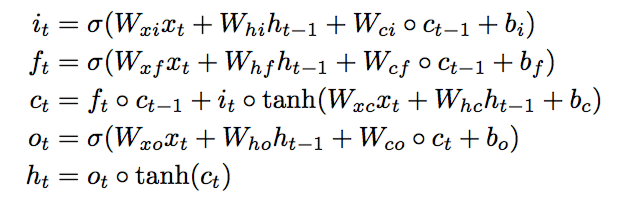
畳み込みLSTMが↓
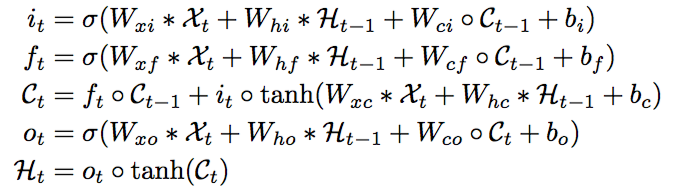
見た目はさほど違いませんが、単なる行列の掛け算の部分が全て畳み込みになっています。ただしピープホールが寄与するアダマール積の部分はそのままアダマール積のままなので注意が必要です。(いつも思うのですが、そもそも何でピープホールの部分は行列の掛け算でなくアダマール積なんでしょうか・・・?)
TensorFlowにおける実装
当然ながら畳み込みLSTMなんてものはデフォルトの機能では存在しませんので実装する必要があります。tf.nn.rnn_cell.RNNCellを継承してConvLSTMCellを実装していきましょう。ソースコードはこちらにあげています。データセット加工とかDLのスクリプトも作ったけどごちゃごちゃなったり、元データセットが凄まじい大きさなので、使った分だけ加工してそのままリポジトリにあげています。
参考にしたコードはこちらです。
今回作ったもの
今回作成したものはKITTIのデータセットを用いた運転風景の予測です。本来でしたら過去数フレームから未来何フレームかを予測するべきなのですが、コードが多くなるのと、学習に時間がかかるので過去4フレームから未来1フレームを予測するネットワークを構築します。
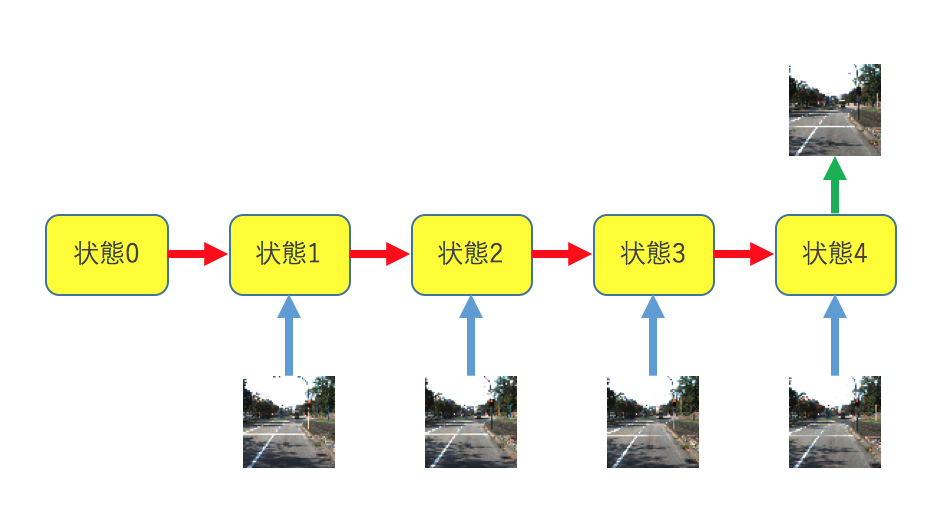
画像サイズは色々試しましたがGFORCE GTX1070で動かしてみて128×128ぐらいが限界かなと感じました。なので64×64で検証しました。論文ではLSTMの層は多層にしてありましたが、ラッパーまで改造するのがめんどくさかったので単層で組んでいます。誤差関数は論文では何故かクロスエントロピーをつかっていましたが、気持ち悪かったので絶対誤差を用います。
tf.nn.RNNCellについて
元となるtf.nn.RNNCellで最低限継承しなければいけないメソッドはstate_size, output_size, __call__の3つです。残る一つのzero_stateですが、これは今回は内部状態の初期値を全部0で作成するものなので、本来は実装しなくてもいいのですが、今回は内部状態のshapeが4階テンソルを取るため、変更してあげる必要があります。それぞれの役割としては、output_sizeですがこれは出力(内部状態ではない)のユニット数になります。RNNの性質上、内部状態になる中間層のユニット数の数と一致します。計算量を削減するために出力を射影する場合にはそれに合わせて変更します。
if num_proj:
self._state_size = (
LSTMStateTuple(num_units, num_proj)
if state_is_tuple else num_units + num_proj)
self._output_size = num_proj
else:
self._state_size = (
LSTMStateTuple(num_units, num_units)
if state_is_tuple else 2 * num_units)
self._output_size = num_units
@property
def state_size(self):
return self._state_size
@property
def output_size(self):
return self._output_size
次にstate_sizeですが、これは内部状態のユニット数になります。一般的なRNNやGRUだった場合は当然のことながら内部状態になる中間層の数と一致するのですが、LSTMは内部状態と出力の両方が次の状態に作用するために、上記のrnn_cell.pyのようにサイズは2倍になります。
zero_stateはこのstate_sizeに合わせて0でパディングした初期状態を返します。
最後にオブジェクトの関数呼び出しの__call__ですが、ここでの処理が実際に重みと入力を掛けたりなどして、各タイムステップでの処理を記述した部分になります。
TensorFlowのRNN関係のオペレーションは行数も少ないので、興味があれば是非読んでみてください。
tf.nn.ConvLSTMCell
さて、本題のConvLSTMCellの実装です。ポイントは2つあります。
- 一般的なLSTMで行われる、前の時間での出力と新規の入力のConcat(結合)を画像のチャンネルレベルで行う。
- 内部状態も入出力も全て同じサイズ(チャンネルは除く)にするために畳み込みの際には0パディングを行い、ストライドは縦横共に1ピクセルで固定する。
一つ目のポイントなのですが、入力ゲートや忘却ゲートの生成時に入力と前の時間の出力を結合する必要があります。(下図の下段での処理)
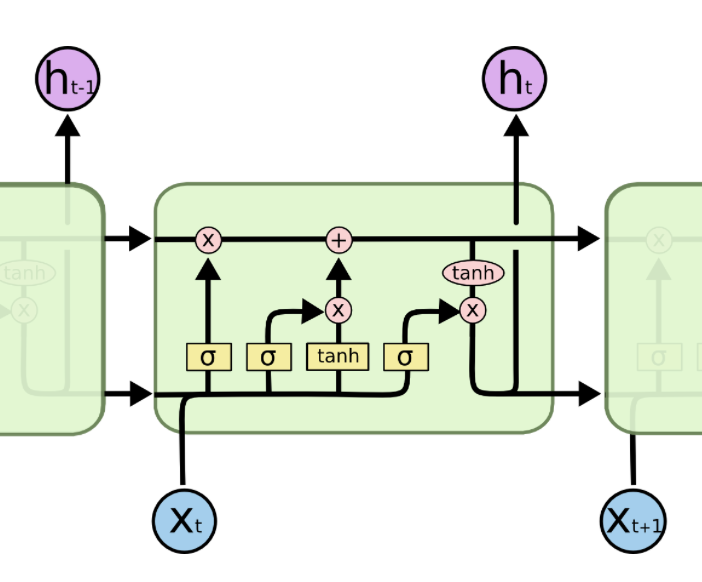
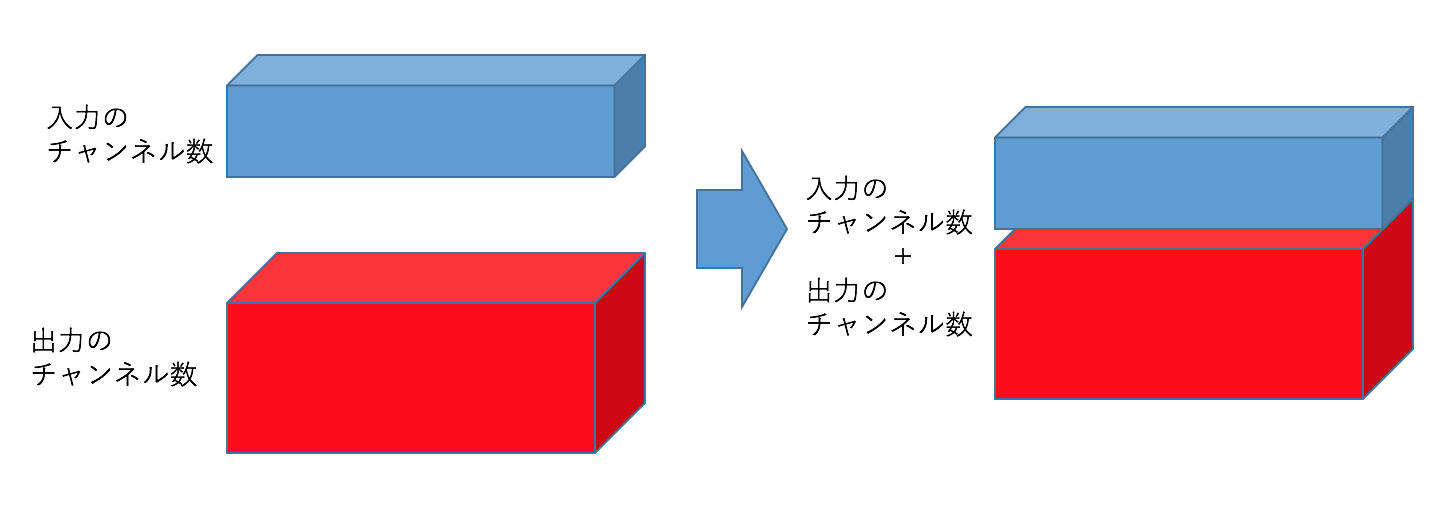
その際に従来のLSTMでは前の時間の出力と入力でサイズが違う場合があるので単純に足し算などができません。そのため、入力長・出力長方向にテンソルを結合します。PPAPを想像していただければと思います。(下図)

しかし、今回入力になるものも出力になるものも状態も4階テンソルを持つためにそのまま結合することもできません。それを解決するほうほうとして、二つ目のポイントにも被るのですが、入力も出力も画像の縦横のサイズだけを統一してチャンネル方向に結合します。イメージとしては下図の通り。
if len(args) == 1:
res = math_ops.matmul(args[0], weights)
else:
res = math_ops.matmul(array_ops.concat(1, args), weights)
# 共有重みになるので必ずpadding='SAME'で畳み込み
if len(args) == 1:
res = tf.nn.conv2d(args[0],kernel, stride, padding='SAME')
else:
res = tf.nn.conv2d(array_ops.concat(3, args), kernel, stride, padding='SAME')
if分で分岐しているのは、一般的なrnnの場合とlstmの場合で分けているだけです。
elseのネストの部分の違いの通り、畳み込む前にconcatをかけています。従来手法の場合はランク1方向に結合していますが、conv_lstmではランク3(チャンネル)方向に結合しているのがわかると思われます。
二つ目のポイントですが、上記の結合の問題もですし、何よりRNNの特性上、共有重みを用いて時間伝播していく特性上、常に内部状態のテンソルは同じshapeをしている必要があります。
そのため、畳み込みのpaddingはもちろんSAMEになります。また、当然のことですが畳み込みのpaddingはフィルタサイズ分の補正しかしてくれないため、strideを1以上にすると画像が小さくなってしまいます。そのため、strideのサイズは必ず[1,1,1,1]に固定します。このせいで非常に計算コストは高くなり、ある程度小さい画像で行わないと全くもって学習が進みません・・・。
時間展開
Convlstmcellで各時間の挙動が実装できたところで、これをRNNの時間展開していきます。セルを時間展開する方法は大きく分けて二つあり、reuse_variables()を用いながらfor文でまわす方法とtf.nn.rnn()やtf.nn.dynamic_rnn()を用いる方法です。今回はせっかくなのでTensorFlowの関数を使っていきます。その際に今回はtf.nn.rnn()の方を使います。個人的には入力データ作成がめんどくさくないdynamic_rnn()を使いたかったのですが、time_majorオプションなどで時間軸がテンソルの2階部分に固定されているためにその部分を改造するのがめんどくさかったのでrnn()を採用します。そのため、入力データは(バッチサイズ, 横, 縦, チャンネル)の4階テンソルのリストになります。
#入力データ(batch, width, height, channel)の4階テンソルの時系列リスト
images = []
for i in xrange(4):
input_ph = tf.placeholder(tf.float32,[None, IMG_SIZE[0], IMG_SIZE[1], 3])
tf.add_to_collection("input_ph", input_ph)
images.append(input_ph)
#正解データ(batch, width, height, channel)の4階テンソル
y = tf.placeholder(tf.float32,[None, IMG_SIZE[0], IMG_SIZE[1], 3])
むぅ、かなり不格好な形でfeed_dictする羽目になりましたが、もっとうまい方法はなかったものか・・・。
feed_dict = {}
# 訓練に使用する画像の最初のフレームをバッチサイズ分取得
target = []
for i in xrange(FLAGS.batch_size):
target.append(random.randint(0,104))
#入力画像のplaceholder用のfeed_dictを埋める
for i in xrange(4):
inputs = []
for j in target:
file = FLAGS.data_dir+str(i+j)+'.png'
img = cv2.imread(file)/255.0
inputs.append(img)
feed_dict[tf.get_collection("input_ph")[i]] = inputs
ただ、とりあえず時間展開部分のモデル構築は非常にシンプルに書くことができます。
cell = conv_lstm_cell.ConvLSTMCell(FLAGS.conv_channel, img_size=IMG_SIZE, kernel_size=KERNEL_SIZE,
stride= STRIDE, use_peepholes=FLAGS.use_peepholes, cell_clip=FLAGS.cell_clip, initializer=initializer,
forget_bias=FLAGS.forget_bias, state_is_tuple=False, activation=activation)
outputs, state = tf.nn.rnn(cell=cell, inputs=images, dtype=tf.float32)
画像生成
畳み込みLSTMの最後の時間の出力を元に画像を生成していきます。必要な情報はtf.nn.rnn()で帰ってくるリストoutputsの最後のテンソルなのでoutputs[-1]で取得して、その(バッチサイズ, 横, 縦, チャンネル数)の4階テンソルを畳み込んで画像生成を行います。畳み込みLSTMのポイントでお話ししましたが、ネットワーク内で出てくる画像データはすべて同じ大きさをしています。それを利用して1×1で畳み込みをかけることにより予想フレームの画像を出力します。
#最終時間での出力を取得
last_output=outputs[-1]
#結果を1×1で畳み込んで元画像と同じサイズに加工
kernel = tf.Variable(tf.truncated_normal([1,1 ,FLAGS.conv_channel, 3],stddev=0.1))
result = tf.nn.conv2d(last_output, kernel,[1,1,1,1], padding='SAME')
result = tf.nn.sigmoid(result)
出力画像の画素値は0〜255にする必要があるので発火関数はシグモイド関数にして結果を255倍します。無事に画像を出力することができます。
結果
まあ、TensorBoardでログを取ったりチェックポイントファイルなどを生成とかするわけでもなく適当に垂れ流した結果を貼ります。

確かに学習はして行っていて最後の方は道路の白線とかが意外といい感じに出てきているけど、パラメータは適当なんでまあこんなもんかという感想。後半の方は絶対誤差平均で0.1程度をさまよっていました。
ちなみに画像サイズを大きくして学習させたらすごく時間はかかりましたけど絶対誤差はさらに小さくなって、結構鮮明になってました。
考察と今後
パラメータチューニングとかやってないので結果はうーんという感じですね。たまに結構うまくいったケースとはありましたが、道路上の木がなくなったりしていてまだまだ突っ込みどころ満載でした。
畳み込みLSTMを最小限に実装しただけなので、実際に色々試したい場合はセルのラッパーやtf.nn系のメソッドおよびseq2seqもいじる必要があります。仕事で使うことがあったらがっつり実装、チューニングしていこうかなと思います。何はともあれ、がっつりとRNN周りのコード読めたのが一番の成果でした。
みなさん良いお年を〜。