はじめに
この記事は NSSOL Advent Calendar 2018 の16日目の記事です。
サーバ運用をしていると、「 よくわからないけどとりあえず調べる 」ということが時折発生します。
障害発生時の初動などがその最たる例ですが、それよりももっと漠然と調査をしなければならないことがあるかもしれません。
そうしたときにも、エンジニアたちは 何かしらの着想 を得て、わからない状況から1つ1つ事実を積み上げ、推論とともに調査結果を練り上げていくわけですが、一体どういう考えや調査指針があるのでしょうか。
自身の知識を棚卸しする意味でも、体系化/手順化にチャレンジしてみます。
なお、コマンドの細かいオプションなどは書き始めるとキリがないので、極力既存の記事へリンクしていきます。
ちなみに

Advent Calendarに向けて温めてきたこのネタですが、 闇の魔術に対する防衛術 Advent Calendar 2018 の6日目にある インフラエンジニアと謎のサーバ となんとなくネタかぶりしてしまいました。
実際書いている内容が似通っているところもあるのですが、個人的に 新人に向けた知識体系化 の意図があったので当初路線のまま書いていくことにしましたm(_ _)m
状況設定

タイトルの通り、ノーヒントですので
「 このサーバがなんかおかしいみたい。 」
と言われたところからスタートすることとします。
え?だからといって、そんなささやき戦術から自分が調べる義理もない?
こまけぇこたぁいいんだよ(例のAA)
そんなこと言わずに、当事者意識を持って調査に臨んでいきましょう。
対象環境
いくつかサーバコマンドを扱いますが、調査対象には以下の環境を想定します。
- RHEL系: CentOS 7.6
- 正確には centos/7
- Debian系: Ubuntu 18.04
- 正確には bento/ubuntu-18.04
- その他
- 守備範囲外
- 興味のある方はぜひ ここ から好きなものを選んでみてください
調査のゴール

調査の内容が指定されていればいいのですが、今回はそうでもありません。
善良なるサーバ管理者の気持ちで、以下をゴールと定めてみましょう。
-
サーバの今がわかる
- 「現在サーバがどうなっているか」に答えられるようになる
-
現状調査の方法 理解が必要
- サーバスペック / サーバ構成 / リソース状況 / ...
-
サーバの過去がわかる
- 「過去サーバがどうなっていたか」に答えられるようになる
- 主に ログの読み方 理解が必要
-
サーバの未来がわかる
- 「今後サーバがどうなりそうか」に答えられるようになる
- もちろんここは 推論 が入る
調査の前に

調査の前に、心と体の準備をしましょう。
ツール準備
いくら優れたエンジニアであったとしても、何のツールもなしには調査できません。
調査ツールは個人の好みを含めて色々あるかと思いますが、代表的なパターンを挙げておきます。
Windows端末
業務上、個人端末がWindowsである方は多いかと思います。そうした方向けには以下のようなツールが代表的です。
代表的とか書きながら、あまりそうでもない MobaXterm を入れていますがこれは自分の趣味です。変態ツールにつき個人的おすすめ。
-
コマンドプロンプト
- 昔ながらで、特に追加インストールすることなく標準装備されているもの
- ping / tracert / nslookup / telnet あたりをよく使うと思います
-
Powershell もこの程度なら同様に使えます
- ちゃんと使いこなすにはPowershellバージョンに注意しましょう
-
Windows Subsystem for Linux
- Windows 10から導入された、いわゆる Bash on Windows
- ひと昔前まではこの役割は cygwin が担っていた
- aptを利用して各種Linuxツールを導入することもできる
- ただし業務で安心してみっちり使っていいかと言われるとまだ心もとないかも
- 将来的にこいつが使い物になると調査端末ごとに調査ツールをそこまで変えずに済むので期待している...
- Windows 10から導入された、いわゆる Bash on Windows
- 各種調査ツール
Mac端末
業務端末がMacの場合は標準のターミナル環境があり、様々なツールが容易にインストールできるので多分Windowsより調査向きです。
ちなみに稀だと思いますが、Linux端末の場合も調査端末というレベルでは概ねMacと同じような使用感だと思います。
-
ターミナル
- 標準搭載されているターミナル
- ターミナルとしての機能が気になるなら iTerm2 あたりをどうぞ
- grepやsedなどのUNIXコマンドも装備されているので、調査結果の整形なども一緒に行える
- MacはBSD系なのでGNU系コマンドと一部オプションが異なる点に注意
- brewでいろいろなツールを追加インストールすることもできる
- 標準搭載されているターミナル
- 各種調査ツール
調査の心構え
個人的な心構えは2つです。
-
事実と推論を分けて整理する
- ノーヒントであるがゆえに、当然ファーストステップは推論になるのですが、推論に推論を重ねていくと意味がわからなくなるので、推論のあとは事実確認するようなことが望ましいです
- そういう意味では一人でガリガリ調べ続けるよりは、別の人も巻き込んでワイワイ(?)やるのがいいですね
-
調査事故を起こさない
- たまに障害調査で 二次障害 を引き起こすケースがあります
- 安易なroot作業や、調査作業によるリソース占有など
- 「今自分がなにをやろうとしているか?」についてはいつも 気をつけましょう
- やらかしてしまった場合に備える意味でも ターミナルログ は必ず取りましょう
- 多分どんなターミナルでもログは取れますが、もし取れないものを使っているとしたらそれは窓から投げ捨てましょう(ポイー
- たまに障害調査で 二次障害 を引き起こすケースがあります
調査のはじめに
実際にツールを使って調べ始める前に、まずは現実世界で情報収集してみましょう。
ヒントが与えられなかったとしたら、自分で何か取っ掛かりを見つけにいくことが大事です。
-
報告者へのヒアリング
- ヒアリングしても何も出てこない場合もありますが、「 何をインプットしたらいいかわかっていない 」報告者もいます
- そういう場合を踏まえ、報告者にはちゃんとヒアリングする
- 次回以降の初動がよくなるためにも、教育的なヒアリングが望ましい...
今回の例でいけば、少なくとも報告者は「このサーバがなんかおかしいみたい」と言っているので、
-
[Who] 誰がこのサーバがおかしいと言っているのですか?
- そりゃ当然報告者でしょうよ、と思いつつもたまに伝聞のケースがあります
-
[What] このサーバは何用途のサーバですか?
- 「このWebサーバが...」と言ってくれればわかりやすいのですが、そのサーバの役割を聞いてみましょう
-
[Why] なぜこのサーバがおかしいと思ったのですか?
- 「夢にでてきた」とかでなければきっと何かのきっかけがあるはずです
-
[When] いつからこのサーバがおかしいと思ったのですか?
- 聞けるものを1つ選ぶとするなら、個人的にはWhen情報が最強だと思います
-
[How] このサーバがどのようにおかしいのですか?
- 「おかしい」という表現からすれば、動作が遅いとかのケースが多いです
- 場合によっては「○○サーバからアクセスできない」とかもあるでしょう
あたりは聞いておくとよいでしょう。
5W1H的にはあと [Where] がありますが、今回は「このサーバ」という情報がそれにあたるので不要です。
仮に「 システムがなんかおかしい 」というレベルの話からスタートするなら、これヒアリングすべきところですね。
調査本編

それでは実際に調査をはじめていきましょう。
今回はサーバがすでに特定されているので、サーバに入る、入らないという観点で分けてみます。
外部調査
まずサーバに入らずに行う外部調査を考えてみます。
中のことはわからないので、ブラックボックスとして調査をしますが、基本的にはネットワークの観点で調査することになります。
おそらくここの段階では調査対象サーバがLinuxだろうがWindowsだろうが同じことができるでしょう。
ネットワーク上の振る舞い
-
IP / ホスト名
- 「このサーバ」と言われているのでおそらくIPまたはホスト名がわかっているでしょう
- IPならDNSの 逆引き を、ホスト名ならDNSの 正引き を行って情報を補完しましょう
- 基本的にはnslookupを使いますが、最近では dig を使うようにしました
- Windowsでnslookupの代わりにdigコマンドでDNSを調べる(BIND編) - @IT
- Windows/Mac/Linuxともにあります
-
ping
- 念のためそのサーバが生きているか確認してみましょう
- pingではICMPでチェックしますが、特にどのポートがというのがあれば tcpping にトライする手もあります
-
traceroute
- そのサーバに至る経路 を確認してみましょう
- pingが疎通しない場合も、「 どこまでなら行けているのか 」が情報になり得ます
-
ポートスキャン
- 対外的なサーバの振る舞いを見るのであればポートスキャンをかける手があります
- ただちょっと無差別的なのでお行儀は悪いです
- Well-Knownポートを含め、 よく使われるポート は大体決まっているので代表的なものを覚えておくとポートスキャン結果を見てははーん、と思えるかもしれません
- ただそんなガバガバサーバも珍しいので大体22/80くらいしかヒットしなかったりする
- あくまで 調査端末からのポートスキャン結果 なので、そのサーバが活躍するネットワークに存在する端末やサーバからの結果とは異なるであろう点を頭に入れておく
- 個別に気になるポートがあったら telnet で対話的に突っついてみてもいいかもしれない
- 対外的なサーバの振る舞いを見るのであればポートスキャンをかける手があります
OSI参照モデルから
このあたりは全体的に、「この調査はネットワークのどのレイヤを調査しているのか?」ということを OSI参照モデル 整理する必要があります。
「L2は通っているけどL3がダメみたい」とか言えると、かなり調査が具体的になっていると言えます。
-
レイヤ1
- 稀によくありますが、 物理故障 が原因の場合があります
- 実際にサーバを見てみると何かのランプがチカチカしていたりするかもしれません
- データセンター作業に関連して 意図しない抜線 が起こった場合などもここで問題が出ます
- AWSなどのクラウドサービスではほとんど気にしなくてよいですが、自前サーバの場合は可能性として頭の片隅においておいてもいいでしょう
- 稀によくありますが、 物理故障 が原因の場合があります
-
レイヤ2
- おおむねMACアドレスの話です
- 雑に仮想マシンをクローンしたりすると MACアドレス重複 が、なんてことも
- arpコマンドが情報源になります
- おおむねMACアドレスの話です
-
レイヤ3
- ここからIPアドレスやルーティングの話が出てきます
- pingによる死活状態や、tracerouteによる経路診断が情報源です
-
レイヤ4以降
- TCP/UDPのほか、最終的にはHTTPなどのアプリ側の話になります
- ここまでくると外部調査でやれることにも限界がありますね
内部調査

続いて実際に対象サーバの中から調べる内部調査をやってみましょう。
ここまで長々書いていますが、調査というイメージはほとんど全てこちらの内容です。
内部調査にあたって

外部調査に比べ、調査の危険性としては格段に上がりますので気を引き締めましょう。
以下のような点に注意が必要です。
-
ユーザ権限
- 調査に 不要な権限 はもたないようにしましょう
- root権限が必要な場合でも、個別にsudoして実行することが望ましいです
- root権限で調査に一時ファイルを作り、調査後に消すとき
rm -rf /的なことをしたら悲惨です
- root権限で調査に一時ファイルを作り、調査後に消すとき
-
CRUDの意識
- 実行する操作が Create/Read/Update/Delete のどれにあたるか意識しましょう
- 調査では基本的に R の操作になるはずです
- たまにコマンド結果をパイプでファイル化することがあると思いますが、これは C の操作です
- そしてパイプ先を間違えて大事な設定を消してしまう...なんてことも
-
U や D は露骨に影響が出るので特に注意しましょう
- 調査終わったぁ~!と思って調査ファイルを D するときは要注意です
-
負荷の配慮
- 調査コマンドであっても、割とリソースを食うものがあったりします
- プロセス調査のtopコマンドで、障害時に 5人くらいが別々にtop してて結構重かったなんてことも
- ログを見る際、 なんとなーく vi してしまって 数GBのメモリを持っていった人もいました
- 調査では基本的に less を使うのがいいでしょう
- 閲覧結果をターミナルに残しておきたければ more
- vi や cat は 対象ファイルのサイズが把握できているとき に使う
- 負荷に対して特に気を使う場合は ionice あたりと一緒に使うといいでしょう
- 調査コマンドであっても、割とリソースを食うものがあったりします
ハードウェアを調べる
まずはサーバのハードウェアを調べてみましょう。
これは多分ディストリビューション色があまりないです。
マシンスペックなど
/proc 配下からはマシンスペックが確認できます。
### CPU
$ cat /proc/cpuinfo
processor : 0
vendor_id : GenuineIntel
cpu family : 6
model : 60
model name : Intel(R) Core(TM) i7-4771 CPU @ 3.50GHz
stepping : 3
cpu MHz : 3500.002
cache size : 8192 KB
physical id : 0
(略)
### メモリ
$ cat /proc/meminfo
MemTotal: 500396 kB
MemFree: 9620 kB
MemAvailable: 376020 kB
Buffers: 1812 kB
Cached: 340260 kB
SwapCached: 200 kB
(略)
$ free -h
total used free shared buff/cache available
Mem: 488M 77M 9.3M 3.4M 401M 367M
Swap: 1.5G 1.0M 1.5G
### ストレージ
$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/VolGroup00-LogVol00 38G 1.4G 37G 4% /
devtmpfs 233M 0 233M 0% /dev
tmpfs 245M 0 245M 0% /dev/shm
tmpfs 245M 4.4M 240M 2% /run
tmpfs 245M 0 245M 0% /sys/fs/cgroup
/dev/sda2 1014M 86M 929M 9% /boot
tmpfs 49M 0 49M 0% /run/user/1000
こういった数値出力系のコマンドには単位を適当に揃える -h オプションがあります。
Human readable なオプションとして覚えておきましょう。
あとそもそも、「メモリとはなんぞや?」という場合には以下の記事が役に立ちます。
あとはネットワークインターフェイス。昔は ifconfig でしたが今は ip コマンドですね。
### NIC
$ ip addr
(略)
3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 08:00:27:be:7c:53 brd ff:ff:ff:ff:ff:ff
inet 192.168.100.10/24 brd 192.168.100.255 scope global eth1
valid_lft forever preferred_lft forever
inet6 fe80::a00:27ff:febe:7c53/64 scope link
valid_lft forever preferred_lft forever
その他デバイス
その他デバイスを見る場合は /dev から辿ります。
$ ls -l /dev
total 0
crw-------. 1 root root 10, 235 Dec 15 10:25 autofs
drwxr-xr-x. 2 root root 180 Dec 15 10:28 block
drwxr-xr-x. 2 root root 60 Dec 15 10:25 bsg
crw-------. 1 root root 10, 234 Dec 15 10:25 btrfs-control
drwxr-xr-x. 2 root root 2700 Dec 15 10:30 char
crw-------. 1 root root 5, 1 Dec 15 10:25 console
lrwxrwxrwx. 1 root root 11 Dec 15 10:25 core -> /proc/kcore
drwxr-xr-x. 3 root root 80 Dec 15 10:25 cpu
crw-------. 1 root root 10, 61 Dec 15 10:25 cpu_dma_latency
crw-------. 1 root root 10, 62 Dec 15 10:25 crash
drwxr-xr-x. 5 root root 100 Dec 15 10:30 disk
brw-rw----. 1 root disk 253, 0 Dec 15 10:25 dm-0
brw-rw----. 1 root disk 253, 1 Dec 15 10:25 dm-1
(略)
b(block) / c(character) / d(directory) / l(link) など、ファイルタイプが豊かなのが特徴です。
ソフトウェアを調べる
次にソフトウェアを調べます。こちらはディストリビューションで違ってきます。
OS情報
いずれも、 /etc/os-release というファイルからOSバージョンなどが確認できます。
$ cat /etc/os-release
NAME="CentOS Linux"
VERSION="7 (Core)"
ID="centos"
ID_LIKE="rhel fedora"
VERSION_ID="7"
PRETTY_NAME="CentOS Linux 7 (Core)"
ANSI_COLOR="0;31"
CPE_NAME="cpe:/o:centos:centos:7"
HOME_URL="https://www.centos.org/"
BUG_REPORT_URL="https://bugs.centos.org/"
CENTOS_MANTISBT_PROJECT="CentOS-7"
CENTOS_MANTISBT_PROJECT_VERSION="7"
REDHAT_SUPPORT_PRODUCT="centos"
REDHAT_SUPPORT_PRODUCT_VERSION="7"
$ cat /etc/os-release
NAME="Ubuntu"
VERSION="18.04.1 LTS (Bionic Beaver)"
ID=ubuntu
ID_LIKE=debian
PRETTY_NAME="Ubuntu 18.04.1 LTS"
VERSION_ID="18.04"
HOME_URL="https://www.ubuntu.com/"
SUPPORT_URL="https://help.ubuntu.com/"
BUG_REPORT_URL="https://bugs.launchpad.net/ubuntu/"
PRIVACY_POLICY_URL="https://www.ubuntu.com/legal/terms-and-policies/privacy-policy"
VERSION_CODENAME=bionic
UBUNTU_CODENAME=bionic
ほかにも /etc/***-release ってファイルがいくつかあるので気になる方は見てみてください。
### CentOS
$ ls -l /etc/*-release
-rw-r--r--. 1 root root 38 Nov 23 13:16 /etc/centos-release
-rw-r--r--. 1 root root 393 Nov 23 13:16 /etc/os-release
lrwxrwxrwx. 1 root root 14 Dec 15 10:26 /etc/redhat-release -> centos-release
lrwxrwxrwx. 1 root root 14 Dec 15 10:26 /etc/system-release -> centos-release
### Ubuntu
$ ls -l /etc/*-release
-rw-r--r-- 1 root root 105 Jul 23 19:40 /etc/lsb-release
lrwxrwxrwx 1 root root 21 Aug 20 13:44 /etc/os-release -> ../usr/lib/os-release
ホスト名とか
uname -a するといろいろ見えます。
$ uname -a
Linux centos7 3.10.0-514.10.2.el7.x86_64 #1 SMP Fri Mar 3 00:04:05 UTC 2017 x86_64 x86_64 x86_64 GNU/Linux
$ uname -a
Linux ubuntu18 4.15.0-29-generic #31-Ubuntu SMP Tue Jul 17 15:39:52 UTC 2018 x86_64 x86_64 x86_64 GNU/Linux
基本的には カーネルバージョンを確認 するために使う気がします。
CentOS7はカーネル3.10、Ubuntu18はカーネル4.15ですね。ちなみに現在パブリックベータ中のRHEL8は4.18らしい。
ちょっと前までは32bit or 64bitを確認するためってのもありましたが、最近は32bitサーバを見なくなったのであまり意識することもなくなりました。
各種パッケージ
ディストリビューション間の違いとして最も有名なのは パッケージ管理システム でしょう。
CentOSなどのRedHat系は古くはrpm、現在はyumです。ただ、yumはPython2系ツールなので、RHEL8からは dnf に変わるようです。
UbuntuなどのDebian系は古くはdeb、現在ではaptですね。
ちょっとそれぞれでPythonのバージョンを調べてみましょう。
$ yum list installed python
Loaded plugins: fastestmirror
Loading mirror speeds from cached hostfile
* base: ftp-srv2.kddilabs.jp
* extras: ftp-srv2.kddilabs.jp
* updates: ftp-srv2.kddilabs.jp
Installed Packages
python.x86_64 2.7.5-48.el7 @anaconda
$ apt list installed python
Listing... Done
python/bionic,now 2.7.15~rc1-1 amd64 [installed,automatic]
それぞれ似たようなコマンドがあるので、必要に応じて調べてみてください。
稼働状況を調べる

ハードウェアやソフトウェアの状態はある程度管理台帳的なものでも管理できるかもしれませんが、稼働状況はそうもいきません。
自分の目で確かめてみましょう。
起動時間
サーバの起動時間です。
「サーバ再起動が発生したか?」を確かめる簡単な方法としてこのuptimeの値を見るという方法があります。
あと、その昔 208.5日問題 というおそろしい問題があったのを思い出しました。
$ uptime
16:45:28 up 6:20, 1 user, load average: 0.00, 0.01, 0.05
ロードアベレージも見えるので、まずこのコマンドを最初に打つことでサーバの状況に対して身構えることができます。
プロセス状況
ps コマンドを使います。
単体でどうこう、というものではないので典型的なオプション例を紹介します。
### プロセス名のほか、リソース使用量についても併記
$ ps -aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 1.2 127896 6372 ? Ss 10:25 0:02 /usr/lib/systemd/systemd --system --deserialize 23
root 2 0.0 0.0 0 0 ? S 10:25 0:00 [kthreadd]
root 3 0.0 0.0 0 0 ? S 10:25 0:00 [ksoftirqd/0]
root 6 0.0 0.0 0 0 ? S 10:25 0:00 [kworker/u2:0]
root 7 0.0 0.0 0 0 ? S 10:25 0:00 [migration/0]
(略)
### プロセス名のほか、親プロセスID(PPID)についても併記
$ ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 10:25 ? 00:00:02 /usr/lib/systemd/systemd --system --deserialize 23
root 2 0 0 10:25 ? 00:00:00 [kthreadd]
root 3 2 0 10:25 ? 00:00:00 [ksoftirqd/0]
root 6 2 0 10:25 ? 00:00:00 [kworker/u2:0]
root 7 2 0 10:25 ? 00:00:00 [migration/0]
(略)
他のオプションも知りたい方は以下をどうぞ。
「あのプロセスが動いているか知りたい」なんて時にはpsとgrepを組み合わせますが、マヌケなことに自分も引っかかってしまうので自分を除外してあげましょう。
### grep で指定した ssh にも引っかかる
$ ps -ef | grep ssh
root 931 1 0 10:25 ? 00:00:00 /usr/sbin/sshd -u0
root 25157 931 0 15:15 ? 00:00:00 sshd: vagrant [priv]
vagrant 25160 25157 0 15:15 ? 00:00:00 sshd: vagrant@pts/0
vagrant 25433 25161 0 17:04 pts/0 00:00:00 grep --color=auto ssh ★こいつが余計
### 除外してやる
$ ps -ef | grep ssh | grep -v grep
root 931 1 0 10:25 ? 00:00:00 /usr/sbin/sshd -u0
root 25157 931 0 15:15 ? 00:00:00 sshd: vagrant [priv]
vagrant 25160 25157 0 15:15 ? 00:00:00 sshd: vagrant@pts/0
具体的に怪しいプロセスが特定できたなら strace でより深く見てみるのもありかもしれません。
リソース状況
top が一番メジャーです。 -d(Delay) でリフレッシュ感覚を指定します。デフォルトは3秒。
### 5秒間隔でtop
$ top -d 5
top - 16:42:17 up 6:17, 1 user, load average: 0.00, 0.01, 0.05
Tasks: 86 total, 2 running, 84 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.4 us, 0.2 sy, 0.0 ni, 99.4 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 500396 total, 73888 free, 80068 used, 346440 buff/cache
KiB Swap: 1572860 total, 1571632 free, 1228 used. 376084 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
25397 vagrant 20 0 157760 2216 1552 R 0.4 0.4 0:00.03 top
1 root 20 0 127896 6372 3896 S 0.0 1.3 0:02.77 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:00.01 kthreadd
3 root 20 0 0 0 0 S 0.0 0.0 0:00.26 ksoftirqd/0
6 root 20 0 0 0 0 S 0.0 0.0 0:00.95 kworker/u2:0
7 root rt 0 0 0 0 S 0.0 0.0 0:00.00 migration/0
8 root 20 0 0 0 0 S 0.0 0.0 0:00.00 rcu_bh
9 root 20 0 0 0 0 R 0.0 0.0 0:00.89 rcu_sched
(略)
topコマンドは1画面にこれでもかというほど情報を詰め込んでくれているので、読めるようになるまでは少し慣れが必要です。
あとtop中に表示を切り替え(toggle)たりもできます。
ネットワーク状況
netstat と言いたいところなのですが、もうないので ss を使います。
ifconfig もそうでしたが、 netstat とともに net-tools 一族は滅んでいきますので、 ip ss たちの iproute2 一族のことを知っていきましょう。
ネットワーク状況、といったときにまず気になるのは「ポートの待受状況」でしょうか。
$ ss -antup
Netid State Recv-Q Send-Q Local Address:Port Peer Address:Port
udp UNCONN 0 0 *:21233 *:*
udp UNCONN 0 0 127.0.0.1:323 *:*
udp UNCONN 0 0 *:68 *:*
udp UNCONN 0 0 ::1:323 :::*
udp UNCONN 0 0 :::43640 :::*
tcp LISTEN 0 128 *:111 *:*
tcp LISTEN 0 128 *:22 *:*
tcp LISTEN 0 100 127.0.0.1:25 *:*
tcp ESTAB 0 0 10.0.2.15:22 10.0.2.2:65148
tcp LISTEN 0 128 :::111 :::*
tcp LISTEN 0 128 :::22 :::*
tcp LISTEN 0 100 ::1:25 :::*
いくつかLISTENしてますね。
これはrootで実行するとさらに便利です。
# ss -antup | grep ssh
tcp LISTEN 0 128 *:22 *:* users:(("sshd",pid=931,fd=3))
tcp ESTAB 0 0 10.0.2.15:22 10.0.2.2:65148 users:(("sshd",pid=25160,fd=3),("sshd",pid=25157,fd=3))
tcp LISTEN 0 128 :::22 :::* users:(("sshd",pid=931,fd=4))
このように、そのポートを待ち受けている元のプロセスもわかります。
次にパケットの処理状況をみてみます。
$ ip -s link
(略)
4: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP mode DEFAULT group default qlen 1000
link/ether 08:00:27:ba:9b:02 brd ff:ff:ff:ff:ff:ff
RX: bytes packets errors dropped overrun mcast
320700 2361 0 0 0 25
TX: bytes packets errors dropped carrier collsns
1566 21 0 0 0 0
RXが受信、TXが送信です。
転送量が確認できるほか、「通信が安定しない」場合にはまずerrorsやdroppedがあるかなんかも見ることがあります。
これ以上に具体的なパケット処理を見たいということであれば、着目するNICに tcpdump を仕掛けることになります。
あと調べたいとすれば「外部への疎通状況」あたりかと思いますが、これは外部調査でも使った ping / traceroute のほか、 curl や nc を使って自分でがんばってみましょう。
この nc もなんでもできる変態ツールで割と好きなのですが、その強力さからセキュリティの人に「ncは 変態すぎるので 極力サーバに入れないでほしい」と言われたことがあります。まぁ、こいつですぐ バックドア 作れますしね...。
ファイル状況
ファイルに関しては、ディレクトリごとのデータ量やファイルの更新日時などをチェックします。
まずデータ量に関しては du コマンドが使えます。
/usr 配下のディレクトリごとでどれくらいのデータがあるか見てみます。
du コマンドは必ずしもroot権限で実行する必要はないのですが、このへんはrootじゃないと引っかかるケースが多いですね。
# du -sh /usr/*
60M /usr/bin
0 /usr/etc
0 /usr/games
8.8M /usr/include
386M /usr/lib
127M /usr/lib64
40M /usr/libexec
0 /usr/local
41M /usr/sbin
260M /usr/share
55M /usr/src
0 /usr/tmp
-s は summerize オプションで結果のみを表示、 -h はおなじみ human readable オプションです。
次にファイルの更新日時です。
ベーシックなところでは ls -lt なんてのがあります。
$ ls -lt
total 220
-rw-------. 1 root root 11773 Dec 15 20:25 secure
-rw-------. 1 root root 123204 Dec 15 20:01 messages
-rw-------. 1 root root 4790 Dec 15 20:01 cron
-rw-r--r--. 1 root root 292292 Dec 15 15:15 lastlog
-rw-rw-r--. 1 root utmp 1920 Dec 15 15:15 wtmp
(略)
-t オプションをつけると更新日時順に並んでくれます。
さらに find コマンドで「最後の修正から○○以内」なんてファイルを探すことができます。
1時間以内に更新されたログを探してみましょう。
# date
Sat Dec 15 20:42:09 UTC 2018
# find /var/log -mmin -60 -printf "%TY-%Tm-%Td %TH:%TM:%TS %p\n"
2018-12-15 20:01:01.7112369400 /var/log/messages
2018-12-15 20:42:10.9179728350 /var/log/secure
2018-12-15 20:42:10.9179728350 /var/log/audit/audit.log
2018-12-15 20:01:01.6992369860 /var/log/cron
出力整形の部分でごちゃごちゃしていますが、大事なのは find /var/log -mmin -60 のところです。
時間指定のところは c(create) / a(access) / m(modify) があります。
特定ファイルの情報は stat コマンドで確認できます。
stat /var/log/messages
File: ‘/var/log/messages’
Size: 123204 Blocks: 248 IO Block: 4096 regular file
Device: fd00h/64768d Inode: 100860334 Links: 1
Access: (0600/-rw-------) Uid: ( 0/ root) Gid: ( 0/ root)
Context: system_u:object_r:var_log_t:s0
Access: 2017-04-06 12:27:20.109730159 +0000
Modify: 2018-12-15 20:01:01.711236940 +0000
Change: 2018-12-15 20:01:01.711236940 +0000
Birth: -
できることならファイルの変更者も知りたいところですが、多分標準だとデータは残っていなさそうです。
標準でもついてる auditd などを動かすことで、細かな情報も残るようになります。
サービス稼働状況
古くは service や chkconfig コマンドでしたが、いまは systemd 系列ですね。
$ systemctl list-units --type=service
UNIT LOAD ACTIVE SUB DESCRIPTION
auditd.service loaded active running Security Auditing Service
chronyd.service loaded active running NTP client/server
crond.service loaded active running Command Scheduler
dbus.service loaded active running D-Bus System Message Bus
getty@tty1.service loaded active running Getty on tty1
gssproxy.service loaded active running GSSAPI Proxy Daemon
(略)
第2引数が list-units だと稼働中サービスを、 list-unit-files だと可動していないものを含めて全サービスが表示されます。
参考: Linux Performance Analysis in 60,000 Milliseconds
いろいろな状況調査ですが、つまるところこの画像の理解に尽きます。
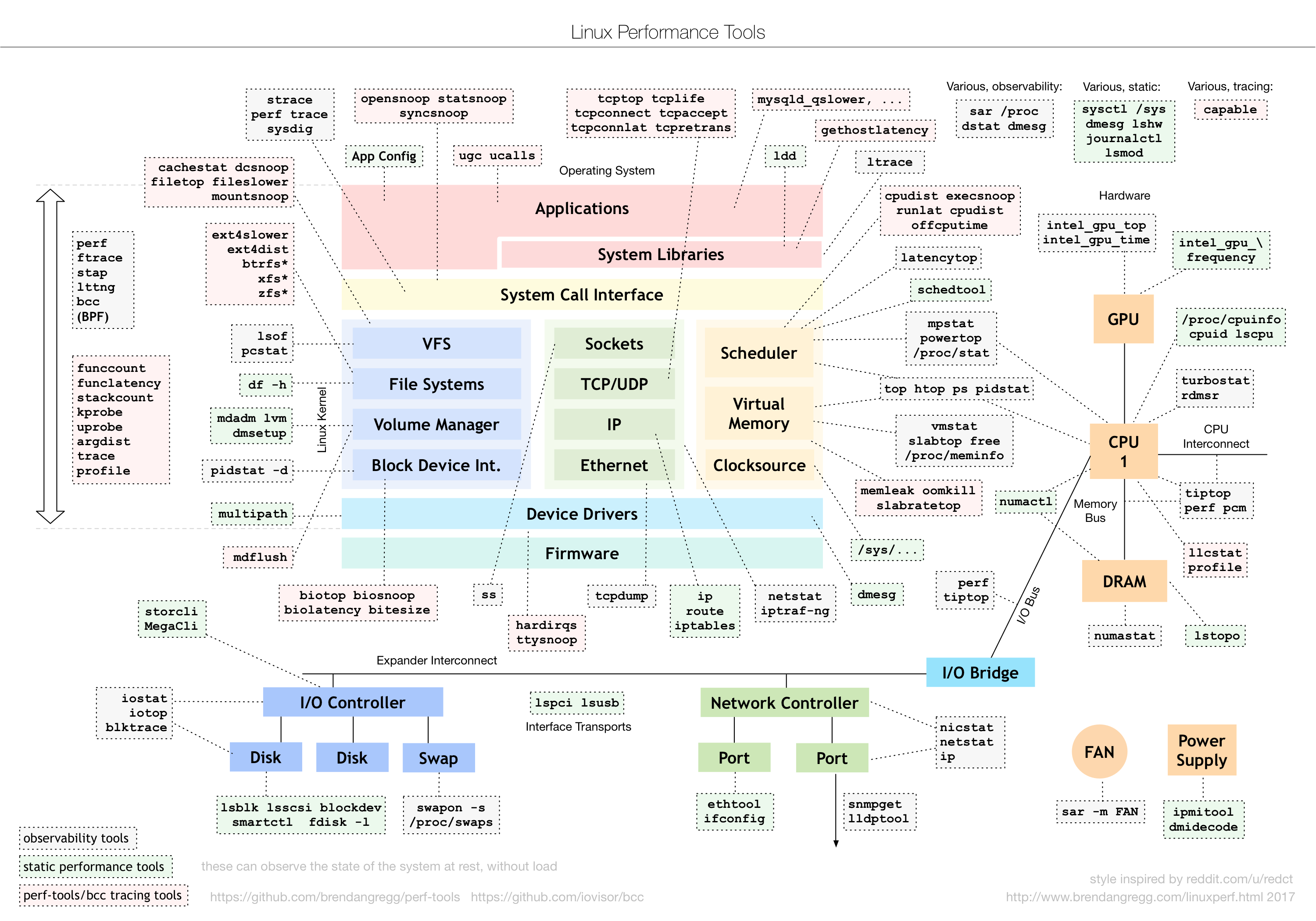 (引用: [Linux Performance](http://www.brendangregg.com/linuxperf.html))
(引用: [Linux Performance](http://www.brendangregg.com/linuxperf.html))
サーバのアーキテクチャをベースに、どの部分の情報をとっているのかをまとめた素晴らしい画像。
この画像を作ったNetflixエンジニアのBrendan Gregg氏は、「パフォーマンス分析最初の1分」についての記事も書いています。
さながら「ノーヒント 1分間 サーバ調査(Linux編)」のよう。
各種設定を調べる
システム設定
基本的にシステム設定は /etc 配下に入ります。
細かいので触れませんが、見る機会が多そうなものを挙げておきます。
-
ユーザ設定
- /etc/passwd
- ユーザ設定一覧
- /etc/group
- グループ一覧
- /etc/passwd
-
ネットワーク設定
- /etc/hosts
- ローカルの名前解決設定
- /etc/nsswitch.conf
- 名前解決順序の設定
- resolve.conf
- DNSサーバの設定
- NIC設定
- ディストリビューションで差がある
- RedHat系: /etc/sysconfig/network-scripts/ifcfg-***
- NICごとに1ファイル
- Debian系: /etc/network/interfaces
- 全NICで1ファイル
- /etc/hosts
-
その他
- /etc/fstab
- ストレージマウント設定
- /etc/sysctl.conf
- カーネルパラメータ設定
- 現在読み込まれているパラメータは
sysctl -aで確認できる
- /etc/fstab
ジョブ設定
OS内で定期的実行される処理はcronがメインなので、 crontab -l で確認しましょう。
### デフォルトは実行ユーザにおけるcronジョブを表示
$ crontab -l
no crontab for vagrant
### root権限なら任意のユーザのcronジョブを表示可能
# crontab -l -u mail
no crontab for mail
ちなみに有名な話ですが、 crontab -r という凶悪なオプションがあります。
### すでにcronエントリがある
$ crontab -l
0 12 * * * echo "cron test1"
### cronを編集(edit)したい...
### しかしキーが隣なので -e と -r を間違えてしまった!
$ crontab -r
### -r は remove オプション...
$ crontab -l
no crontab for vagrant
大抵こういうコマンドには対話的な削除確認があるのですが、crontabさんは硬派なので 黙って抹殺 してくれます。
この流れであれば、直前の crontab -l の出力をもとに復元が可能ですが、いきなり編集しようとして間違えると悲惨ですね。
本質的には crontab -r をエイリアスか何かで禁止しておくのが望ましい(消すにしても crontab -e を使う)でしょう。
ログを調べる
最後に、各種ログをみてみましょう。
ログを見る
ログも設定と同様に、概ね /var/log の下に入っています。
見る機会が多そうなものは以下です。
-
システムログ
- /var/log/messages
- メインの システムログ
- とりあえずここを見る、くらいでもよい
- /var/log/dmesg
- デバイス関連 のログ
- /var/log/messages
-
ログインログ
- /var/log/wtmp
- 最近の ログイン情報 を見ることができる
- /var/log/secureやlastコマンドでも似たような情報が見れる
- バイナリファイルなのでwhoコマンド経由で読める
- 仮に不届き者がまだログインしているとしたら、wallコマンドとかwriteコマンドで メッセージを叩き込む こともできる
- rootユーザならptsデバイスにパイプしてメッセージを送ることもできる
- 最近の ログイン情報 を見ることができる
- lastlogコマンド
- ユーザごとの最終ログイン情報 を見ることができる
- /var/log/wtmp
-
その他
- /var/log/cron
- 要root権限
- cronの稼働状況や、cron設定の操作を見ることができる
- /var/log/cron
ログ設定の確認
後追いには欠かせないログですが、無限に残るわけでもないので注意しましょう。
$ cat /etc/logrotate.conf
(略)
/var/log/wtmp {
monthly
create 0664 root utmp
minsize 1M
rotate 1
}
(略)
### アプリごとのログローテート設定が入っている
$ ls /etc/logrotate.d/
chrony ppp syslog wpa_supplicant yum
### システムログのローテート設定
$ cat /etc/logrotate.d/syslog
/var/log/cron
/var/log/maillog
/var/log/messages
/var/log/secure
/var/log/spooler
{
missingok
sharedscripts
postrotate
/bin/kill -HUP `cat /var/run/syslogd.pid 2> /dev/null` 2> /dev/null || true
endscript
}
もし調査の中で、ログが不十分だと感じたらこのあたりを変更することになります。
書き方等はこちらをどうぞ。
調査の振り返り
一通りの調査を終えたら、改めてゴールを考えてみましょう。
-
サーバの今がわかる
- 「現在サーバがどうなっているか」に答えられるようになる
-
外部調査
- ネットワーク上の振る舞い
-
内部調査
- ハードウェアを調べる
- ソフトウェアを調べる
- 稼働状況を調べる
-
外部調査
- 「現在サーバがどうなっているか」に答えられるようになる
-
サーバの過去がわかる
- 「過去サーバがどうなっていたか」に答えられるようになる
-
内部調査
- ログを調べる
-
内部調査
- 「過去サーバがどうなっていたか」に答えられるようになる
-
サーバの未来がわかる
- 「今後サーバがどうなりそうか」に答えられるようになる
- 主に 稼働状況 で得た情報をもとに推論します
- リソース枯渇、再発予測、...
- 主に 稼働状況 で得た情報をもとに推論します
- 「今後サーバがどうなりそうか」に答えられるようになる
いかがでしょうか?サーバのことがわかるようになったでしょうか?
欲しい情報がなかったら?

サーバのことを改めて考えたとき、「 あの情報があれば... 」というようなことがあります。
そうした欲しい情報があり、再発が見込まれる場合は、「 その情報が残るように仕込んでおく 」という方法があります。
リソース情報を残したい
リソースに関しては「モニタソフトを仕込む」か「スクリプトを仕込む」かの2通りです。
モニタソフトを仕込む
OSSであれば Zabbix、お金がかかってもいいなら Datadog などがあります。
これらは収集、蓄積と可視化をいっぺんに行えるので、あとから分析するのも楽ですね。
問題として、モニタ用に専用エージェントを入れる必要があるため、障害の恐怖に怯えながら新しいソフトを仕込むというのが現実的に難しい場合があります。
スクリプトを仕込む
専用エージェントといかずとも、簡単なスクリプトをcronか何かで動かして情報を残す方法もあります。
この観点で最も有名なのは sar でしょうか。System Admin Reporterの略だとか。
sarで情報収集した場合、グラフとして時系列で見るのがちょっとつらいのが難点ですね。
GnuPlotあたりで自前でグラフ化するなどの一工夫が必要でしょう。
ログを残したい
ログを残す場合、「ログが消えてしまっている」のか「ログがそもそも出ていない」かで対応が異なります。
ログを保護する
こちらは「ログが消えてしまっている」場合の対処です。
すでに説明したように logrotate でログが消えないように配慮するほか、 Fluentd のようなログコレクタで逃してやる方法があります。
ロギング箇所を増やす
続いて「ログがそもそも出ていない」場合の対処です。
設定変更で対応できるものとしてはログレベルの変更があります。バグを報告したりすると「ログレベルをDEBUGに変えて待っててください」とか言われるアレです。いずれにせよ、DEBUGにすれば事象を記録できるのであれば、まだマシといえます。
そもそもプログラムなどの作りがいまいちで、問題の事象をそもそも記録できない場合は例外処理の追加などを含め、何かしらのロギング処理を増やす必要があります。こちらはちょっとヘビーですね。
操作情報を残したい
シンプルといえばシンプルですが、「 全操作履歴を残す 」のは非常に強力な仕込みです。
場合によっては結構なストレージを食いそうな気がしますが、すぐ手を出せるものを含めいくつか方法はあるようです。
さいごに

長々と書いてしまいましたが、新人エンジニアを中心に「調査といっても一体何を...」と思うような人に何か少しでも取っ掛かりを与えられれば幸いです。
もし、「 こんなアプローチもあっていいのでは? 」などあればコメント等いただければと思います!