はじめに
完璧なものではありません。gemsim最高っ!です。
動機
以下の記事を読んで、想像以上にシンプルな作りだったので、考えを整理するために自作してみました。完璧に車輪の再発明ですが、車輪の再発明は重要です。
手元にMecab等でトークナイズしたニュース原稿があると仮定して話を進めます。
GitHub
ソースはこちらです。
先程も述べたとおり。手元にMecab等でトークナイズしたニュース原稿がないと動きません
実装手順
- one-hotベクトル用の辞書作成
- ニュース原稿から各単語に連番IDと出現回数を割り当てる
- 連番ID番号からone_hotベクトルを作成する
- ニューラルネットワークの作成
- ニューラルネットワークで学習する
- マルチスレッドで処理
- one-hotベクトルを作成するスレッド
- TFのセッションを走らせるスレッド
- 学習結果の隠れ層への重みwと出力層へのw_を取り出す
- マルチスレッドで処理
- 類似ワードの出力
- 適当な単語(今回はiphone)で類似ワードにwで内積して、更にw_で内積
- 内積して求まったベクトルから上位の単語(類似ワード)を出力
one-hotベクトル用の辞書作成
- ニュース原稿から各単語に連番IDと出現回数を割り当てる
- 連番ID番号からone_hotベクトルを作成する
まずはニュース原稿の各単語にIDを割り振ります。また自作のコードは遅いので出現頻度の低い単語は辞書から削除して少しでも次元を減らしていきます。
class Vocabulary():
def __init__(self):
self.seq_no_id = 0
self.token_to_id = {}
self.id_to_token = {}
self.counter = collections.Counter()
def has(self, data):
if type(data) == str:
return data in self.token_to_id
if type(data) == list:
for t in data:
if t in self.token_to_id:
return True
return False
def add(self, tokens):
self.counter.update(tokens)
def build(self):
for tok, count in self.counter.most_common():
if count <= settings.VOCABULARY_MIN_COUNT:
break
if tok not in self.token_to_id:
self.token_to_id[tok] = self.seq_no_id
self.id_to_token[self.seq_no_id] = tok
self.seq_no_id += 1
def one_hot(self, data):
dim = self.seq_no_id
if type(data) == str:
one_hot = zeros(dim)
one_hot[self.token_to_id[data]] = 1.0
# print('input {}'.format(one_hot))
return [one_hot]
if type(data) == list:
one_hot = zeros(dim)
for t in data:
if self.has(t):
one_hot[self.token_to_id[t]] += 1.0
return [one_hot]
add(tokens)で単語を辞書に登録していきます。引数は単語のリストです。collections.Counterにupdateしていけば出現頻度をカウントしてくれます。
add(tokens)前後を登録したら、最後にbuild()します。このとき頻度の低い単語(デフォルト3単語)には連番を振りません。連番を振ったらtoken_to_id辞書とid_to_token辞書に登録していきます。辞書引きすることで計算量を抑えます。
one-hotベクトルを作成はnumpy.zerosを使って0を並べて、連番ID番目に1足します。if type(data) == list:以下は出力層用です。窓内の単語のone-hotベクトルを総和します。
ニューラルネットワークの作成
隠れ層1層のシンプルなニューラルネットワークをTensorFlowで組みます。
最終的に学習済みの重みが必要なのでself.w1 = w1とself.w0 = w0としてクラス変数に保存しておきましょう。
class NeuralNetwork():
def prepare_model(self, learning_rate, num_units, vec_dim):
with tf.name_scope('input'):
x = tf.placeholder(tf.float32, [None, vec_dim])
with tf.name_scope('hidden1'):
w1 = tf.Variable(tf.truncated_normal([vec_dim, num_units]))
b1 = tf.Variable(tf.zeros(num_units))
hidden1 = tf.nn.relu(tf.matmul(x, w1) + b1)
with tf.name_scope('output'):
w0 = tf.Variable(tf.zeros([num_units, vec_dim]))
b0 = tf.Variable(tf.zeros([vec_dim]))
p = tf.nn.softmax(tf.matmul(hidden1, w0) + b0)
with tf.name_scope('optimizer'):
t = tf.placeholder(tf.float32, [None, vec_dim])
loss = -1 * tf.reduce_sum(t * tf.log(p))
train_step = tf.train.AdamOptimizer(
learning_rate=learning_rate).minimize(loss)
self.w1 = w1
self.w0 = w0
self.b1 = b1
self.x = x
self.t = t
self.p = p
self.train_step = train_step
self.loss = loss
def prepare_session(self):
sess = tf.Session()
sess.run(tf.global_variables_initializer())
self.sess = sess
ニューラルネットワークで学習する
- マルチスレッドで処理
- one-hotベクトルを作成するスレッド
- TFのセッションを走らせるスレッド
- 学習結果の隠れ層への重みwと出力層へのw_を取り出す
- 定期等な単語で類似ワードにwで内積して、更にw_で内積
TensorFlowの処理はC/C++で処理されていると思うでGILが解除されているはず。というわけで学習最中にone-hotベクトルの作成してしまいましょう。one-hotベクトルはQueueで受け渡します。
class Word2Vec():
# Skip Gram Model
def __init__(self, window, alpha, size):
self.window_size = window
self.nn = neuralnet.NeuralNetwork()
self.alpha = alpha
self.size = size
self.w = None
self.w_ = None
self.vocab = None
def make_model(self, data):
self.vocab = Vocabulary()
for tokens in data:
self.vocab.add(tokens)
self.vocab.build()
voca_dim = self.vocab.seq_no_id
self.nn.prepare_model(self.alpha, self.size, voca_dim)
self.nn.prepare_session()
def slice_window(self, tokens):
ws = self.window_size
for pos in range(len(tokens)):
w_begin = pos - ws
w_end = pos + ws
if w_begin < 0:
if pos == 0:
w_begin = 1
else:
w_begin = 0
input_token = tokens[pos]
output_token = tokens[w_begin:pos] + tokens[pos + 1:w_end]
yield input_token, output_token
def train(self, data):
nn = self.nn
q = queue.Queue(2)
th = SessionRunner(nn, q)
th.start()
in_vecs = []
out_vecs = []
for tokens in data:
for in_token, out_tokens in self.slice_window(tokens):
if self.vocab.has(in_token) and self.vocab.has(out_tokens):
in_vecs.extend(self.vocab.one_hot(in_token))
out_vecs.extend(self.vocab.one_hot(out_tokens))
q.put((in_vecs, out_vecs))
in_vecs = []
out_vecs = []
q.put((None, None))
th.join()
return th.w, th.w_
class SessionRunner(threading.Thread):
def __init__(self, nn, q):
super(SessionRunner, self).__init__()
self.nn = nn
self.q = q
def run(self):
while True:
input_vecs, output_vecs = self.q.get()
if input_vecs is None and output_vecs is None:
break
# 学習済みの重みw0とw1の結果を受け取ります
w, w_, _ = self.nn.sess.run([self.nn.w1, self.nn.w0,
self.nn.train_step],
feed_dict={
self.nn.x: input_vecs,
self.nn.t: output_vecs,
})
self.w = w
self.w_ = w_
これで主要な部分は完成です。簡単ですね。
類似ワードの出力
- 適当な単語(今回はiphone)で類似ワードにwで内積して、更にw_で内積
- 内積して求まったベクトルから上位の単語(類似ワード)を出力
def main():
token_gen = utils.find_and_load_token_files()
token_gen = [line for _, line in token_gen]
token_gen = sorted(token_gen)[:500]
w2v = word2vec.Word2Vec(window=15, alpha=0.0005, size=200)
w2v.make_model(token_gen)
word = 'iphone'
rank = 10
onehot = w2v.vocab.one_hot(word)[0]
for i in range(100):
random.shuffle(token_gen)
w, w_ = w2v.train(token_gen)
r = np.dot(onehot, w)
predict = np.dot(r, w_)
sort = predict.argsort()[::-1]
most_similar = [w2v.vocab.id_to_token[i] for i in sort[:rank]]
if i == 0 or (i + 1) % 5 == 0:
print("epoch = {} -----------".format(i + 1))
print('{} =====> {}'.format(word, most_similar))
if __name__ == '__main__':
main()
全ニュース原稿で学習しようと思いましたが、原稿が増えるほど次元が増加していきます。5000次元くらいでないと遅すぎるので、IT関連ニュースを500記事ほど使って学習します。
類似ワードは上位10件を表示します。
結果
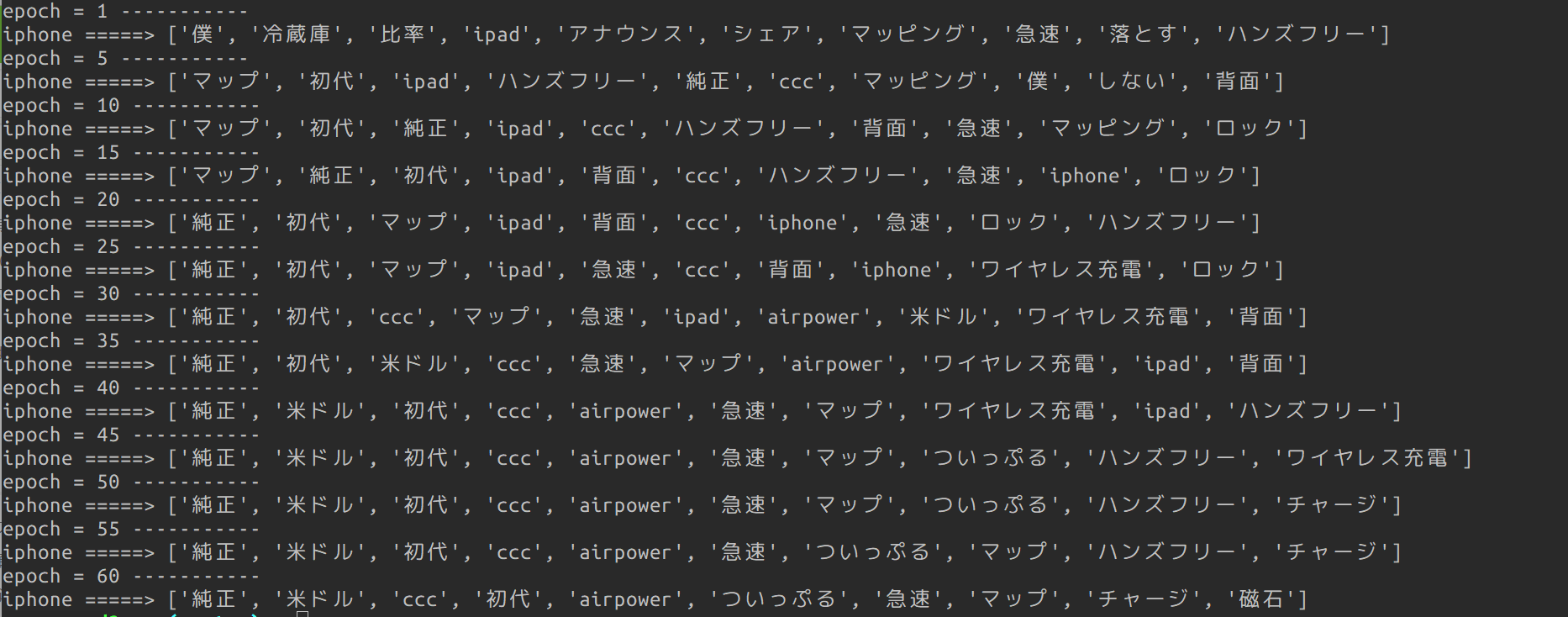
それっぽいワードがでてきいますね。おそらく成功でしょう。おそらく!!
途中でiphoneの類似ワードにiphoneが来ているのは、出力層の値が高確率で0なので、それが特長になってしまっているのでしょう。
感想
- 思った以上に簡単だった。やはりシンプルなものは強い。
- 遅い!遅すぎる!! たぶん何かが間違っている。
- gensimすごい!!!! どうなってるの?
- シンプルにしようとしたけど、遅すぎて色々複雑になってしまった
- Thread化
- 低頻度の単語を辞書から削除
- 割とそれっぽい結果になった
- やはりパラメータチューニングがキモ
というわけでQiitaとブログと私の浅い知識でササッと作ってみました。色々と不備があると思いますが、それっぽい結果がでたので成功したということにします。
(高速化方法などアドバイスお待ちしております…)