まずはWebUIクイックスタートのマニュアルのとおり進めて、実際に利用してみる。
https://cloud.google.com/bigquery/web-ui-quickstart
検索の実行やデータのロード、データのエクスポートする際に、可視化インタフェースとしてWebUIを使用することができる。
このクイックスタートではパブリックデータに対する問い合わせと、サンプルデータをBQへ登録する方法について示す。
1.準備
データをロードするのにコストがかかるので、ビリングの設定をしておく必要がある。
2.パブリックなデータセットを検索
BigQuery web UIはテーブルに問い合わせするためのインタフェースを提供する。
COMPOSE QUERYをクリック。

次のクエリをテキストエリアに入力する。
SELECT
weight_pounds, state, year, gestation_weeks
FROM
publicdata:samples.natality
ORDER BY weight_pounds DESC LIMIT 10;

クエリが妥当かどうかは緑か赤で判断できる。妥当であれば、1回のクエリで処理されるデータ容量が表示される。これは実行するとどれくらいのコストが発生するか分かるので役に立つ。
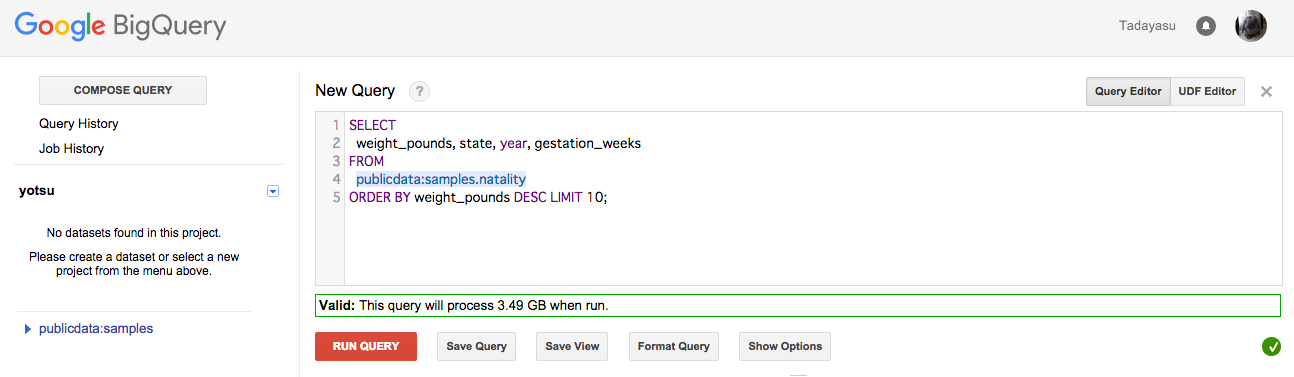
RUN QUERYボタンをクリックすると、クエリの結果は下に表示される。

上記のクエリはパブリックデータセットのテーブル(publicdata:samples.natality:)にアクセスしている。
publicdataはプロジェクト名、samplesはデータセット名、natalityはテーブル名。
何個のデータを扱ってたのか確認してみる。約1億3700万のデータに対してクエリをかけていた。

3.データをロードしテーブルに格納
カスタムデータをテーブルにロードし、クエリをかける。
3.1.データのダウンロード
US Social Security Administrationが提供しているzipファイルをダウンロード。
3.2.データセットの作成
プロジェクト名の横にある下向きの矢印をクリックし、Create new datasetをクリックする。
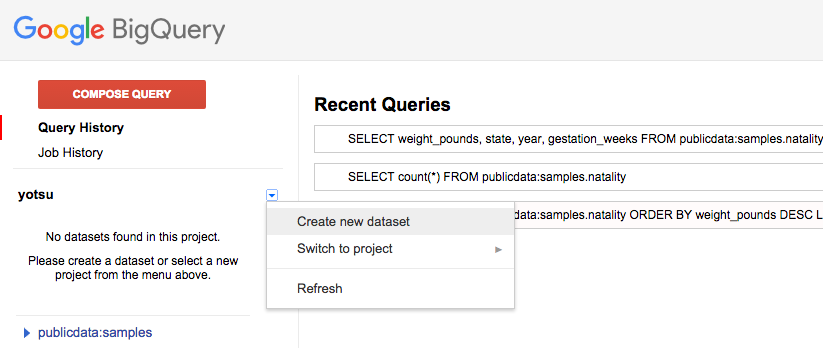
dataset IDを入力
Dataset IDはプロジェクト毎にユニークである必要がある。

3.4.データをロードし、新しいテーブルに格納
新しいテーブルにデータを入れる。
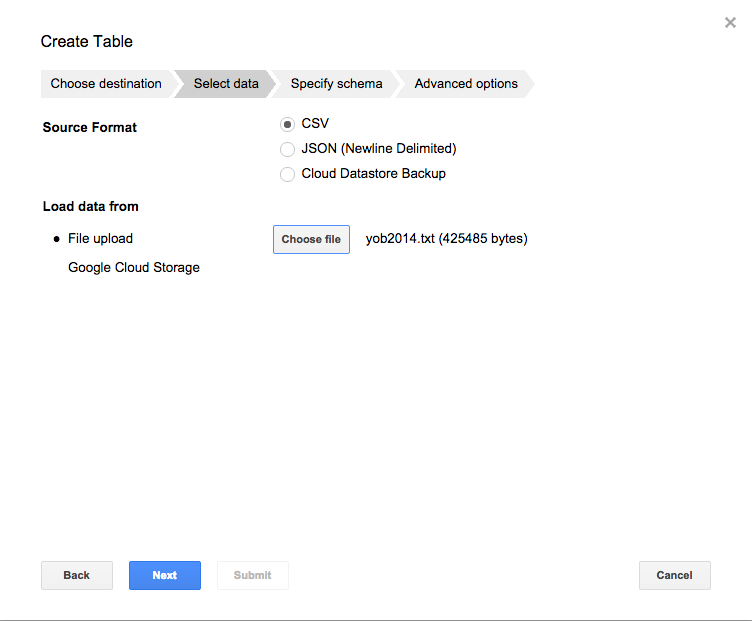
下向き矢印をクリックし、 Create new tableをクリックする。

table IDを入力。

Click the Choose fileボタンをクリックし、yob2014.txtファイルを選択。
Click Edit as textをクリックし、以下の文字を入力する。
name:string,gender:string,count:integer
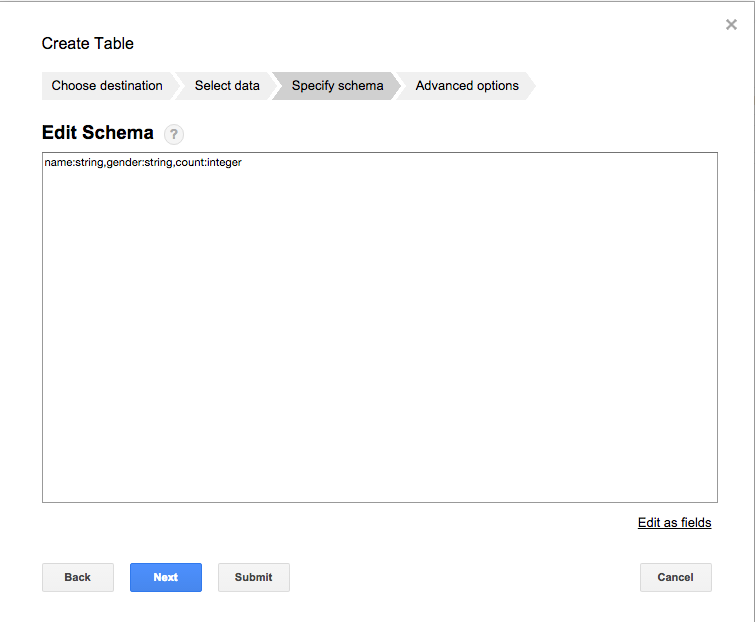
Submitボタンをクリック

上記のステップで、BigQueryはテーブルを作成し、そこにデータをロードすることができた。
しばらく(1分程度)するとテーブルが作成されていることを確認できる。

3.5.テーブルを検索
カスタムデータをテーブルに入れたので、パブリックデータを処理した時と同様に、クエリをかけることができる。
COMPOSE QUERYボタンをクリック
次のクエリをテキストエリアに記載。 datasetIdとtableIdはさっき作った自分のものを指定する。
SELECT
name, count
FROM
datasetId.tableId
WHERE
gender = 'M'
ORDER BY count DESC LIMIT 5;
