以下の記事のメモ。図はオリジナルのサイトから引用。
Streaming Insertのダイアグラム
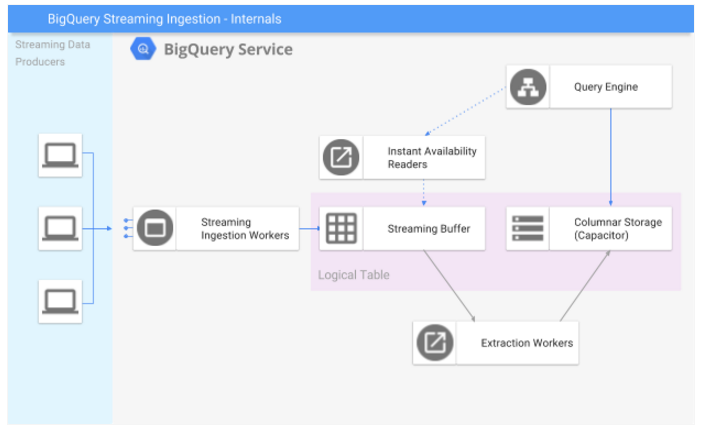
| コンポーネント | 概要 |
|---|---|
| Streaming data producers | BigQueryへストリーミングデータを送るアプリケーション |
| Streaming Ingestion Workers | ストリーミングデータをStreaming Bufferへ入れて、成功・失敗のレポートを行う。 |
| Streaming Buffer | 最近インサートした行を維持するバッファであり、ハイスループットで書き込むために最適化する |
| Instant availability reader | クエリエンジンがストリーミングバッファから直接レコードを読み込むことを可能にする |
| Columnar storage | データはカラムナフォーマットのテーブルに関連付けられる。 |
| Extraction worker | バッファされたレコードのグループを集めて、カラムナフォーマットへ変換し、データをBigQueryの管理するストレージへコミットする処理 |
| Query Engine | Dremel |
クエリのライフサイクルは以下の3ステージからなる。
Stage1 データソースからの挿入
- ユーザはtabledata.insertAllメソッドでBigQueryにストリーミングインサートを送信。このインサートは認可情報などをヘッダに加えてJSONフォーマットで送られる。
- 1つのinsertAll呼び出しは1つもしくは複数のレコードが含まれている。
- batch factorとして、いくつの行が1つのinsertAll呼び出しに含まれているか参照することができる。
- インサートは、Streaming Workerによって受信し、処理され、insertAllペイロードの各レコードをストリーミングバッファに保存するために必要な呼び出しを行う。
- workerはinsertAllリクエストの成功/失敗のレポートを行い、ペイロードはより詳細な個々のレコードのステータスを含む。
- insert workerがそれを確認すると、データはstreaming bufferにコミットされる。
- stream buffer storageはカラムナストレージよりもハイスループットでの書き込みが行われるように最適化される。このときのデータは堅牢だが、管理されたストレージより可用性の面で多くの制限がある。
Stage2 クエリ
- Streaming bufferに届いたレコードは数分間そこに滞在し、この期間レコードはバッファされる。この段階でテーブルにクエリを発行することは可能。
- Instant Availability Readerはワーカーがquery engineからバッファされたレコードを読み取ることを可能としている。
※instant availability経由でデータを読むのは管理されたストレージから読むよりも遅くなる。これはデータのロケーション(streaming bufferはquery treeよりも遠いところにある)とストレージフォーマット、並列性が要因である。
Stage3
- extraction workerはバッファからレコードを集め、カラムナフォーマットへ書き込む。
- extraction workerはカラムナストレージへ効率的なバッチを作成しようとするので、テーブルに到着するレコードやストリーミングレコードのボリュームは、これらの抽出が行われる頻度に影響される。
- レコードは抽出されると、garbageとマークされ、streaming bufferから削除される。
- 管理されたストレージへコミットされたレコードのグループとして、それらは複数のデータセンターにレプリカされ、アーカイブされる。