はじめに
こんにちは,ワークス徳島人工知能NLP研究所の山村です.
先週のアドベントカレンダーの記事では,chiTra の事前学習用コーパスの前処理の一つであるクリーニングについて紹介しました.
本記事では,前処理の中でも 文分割(複数の文を1文ごとに分割する) について紹介したいと思います.
文分割は, BERT のような言語モデルを学習するためには必要な前処理となっています.
また最後に,いくつかの文分割ライブラリについても軽く紹介します.
これから,0から事前学習モデルを作成する方(文分割の前処理が必要な方)など,興味がある方は参考にしてみてください.
本記事を読む前に,chiTra についてざっくりと知りたい方やコードを書いて使ってみたい方は,過去の記事を参考にしてみてください.
【非専門家向け】BERT - chiVe / chiTra 利活用に向けて Part3. - Qiita
BERT と文分割
BERT を事前学習 (Pre-training) タスクとして,以下の2つの教師なしタスクを使用しています.
- Masked LM
- Next Sentence Prediction (NSP)
本記事で着目するのは,2 の Next Sentence Prediction (NSP) タスクです.
Next Sentence Prediction (NSP) タスクとは,文間の関係を学習するために導入された事前学習タスクであり,入力された 2 文がコーパス上での連続した 2 文か否かを予測するタスクになります.
BERT の学習を実装したコードはいくつかありますが,NSP タスクを学習するためには学習対象の入力コーパスに対してあらかじめ文分割を適用して,文区切りなどフォーマットに変換しておく必要があります.
例えば,Tensorflow Model Garden にある事前学習用のデータを作成するスクリプト (create_pretraining_data.py) では,1文ごとに改行区切りにして,文書の区切りに改行をはさんだようなフォーマットで入力コーパスを準備しておく必要があります.
もちろん,既に文分割済みのデータセットをコーパスとして利用する場合は問題ありませんが,自前で用意したテキストや文分割されていないデータセットを利用する場合には,文分割処理が必要となってきます.
余談:NSP の派生タスク
上記で紹介したように,BERT では Masked LM と Next Sentence Prediction (NSP) の 2 タスクによる事前学習を行っています.
BERT以降に提案された言語モデルである ALBERT では,NSP タスクの代わりに Sentence Order Prediction (SOP) という改良タスクを提案しています.
ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
この SOP タスクでは,NSP タスクの隣接する文かどうかではなく,文の順序を予測するようなより難しい事前学習タスクになっており,下流タスクの精度が向上すると報告されています.
chiTra と文分割
chiTra では,言語処理学会第28回年次大会(NLP2022) に 論文 を発表しており,この論文では Wiki-40B と文分割器 Bunkai を利用して事前学習用のコーパスを作成しています.
Bunkai は,pure Python の文分割ライブラリであり,改行記号に対しても文境界の判定ができげるのが特徴になっています.
また,現在でもこまめにメンテナンスやリリースがされており,使いやすいライブラリになっています.
ただし, 単純に Bunkai を適用しただけでは,文の区切りとは考えられないような箇所に対しても文境界の判定がされるような過分割される事例もいくつかありました.
そこで,先週紹介したコーパスのクリーニング処理の一つに,このような過分割に対する文分割エラーを修正する処理を加えることで,この問題を回避しています.
この文分割エラーを修正する具体的なコードは,こちらです.
https://github.com/WorksApplications/SudachiTra/blob/main/pretraining/bert/corpus_preprocessing/normalizer/document_normalizer/document_normalizer.py#L62
おまけ:大規模コーパスと文分割器
一般に,言語モデルの学習には大規模なコーパスが必要となります.
このような大規模なコーパスを処理するには,ある程度高速に実行できる文分割器が必要となります.
もちろん,文境界の判定の精度を向上させるためには,文分割に辞書などのリソースや複雑な処理が必要になってくるので,実行速度とのトレードオフになることもあります.
ある程度高速で日本語にも対応している python の文分割器として,pySBD などがあります.
pySBD は,spaCy のパイプラインとして組み込むことができる文分割器となっており,spaCy を使うユーザにとっても扱いやすいライブラリとなっています.
pySBD は Pragmatic Segmenter というRuby のコードを python に移植したもので,日本語の場合は以下のようなルールによって文境界の判定が行われます.
https://github.com/diasks2/pragmatic_segmenter#golden-rules-japanese
注意:文分割器にとても長いテキストを入力すると実行速度が低下する
pySBD などの文分割器の多くは,正規表現による文分割処理を行っています.
しかし,正規表現器によっては(実装しているアルゴリズムによっては),入力長 N に対して爆発的に計算量が増加するものがあります.
そのため,大規模コーパスのようなさまざまなテキストが混在しているものを解析する場合は,このような異常な入力を与えていないか気をつける必要があります.
以下は, pySBD に対して入力長を変化させた際の実行速度を調べるコードと実行結果です.
このコードでは,入力長に対して1回の試行しか行っていません.
より厳密に調査したいなどの理由で複数回試行する場合などは, pytest-benchmark などが便利です.
from time import time
import japanize_matplotlib
import pandas as pd
import pysbd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_theme(style='ticks')
%config InlineBackend.figure_formats = {'png', 'retina'}
japanize_matplotlib.japanize()
def elapsedtime(func):
def wrapper(*args, **kwargs):
s = time()
result = func(*args, **kwargs)
e = time()
elapsed_time = e - s
return (elapsed_time, result)
return wrapper
@elapsedtime
def sbd_segmenter(text: str):
for j in seg.segment(text):
_ = j
return None
seg = pysbd.Segmenter(language="ja", clean=False, char_span=True)
TIMEOUT = 10
sentence = "これは10文字です。"
elapsed_time_items = []
elapsed_time = 0
while elapsed_time < TIMEOUT:
len_sentence = len(sentence)
elapsed_time, _ = sbd_segmenter(sentence)
elapsed_time_item = {
"len_sentence": len_sentence,
"elapsed_time": elapsed_time
}
print(elapsed_time_item, flush=True)
elapsed_time_items.append(elapsed_time_item)
sentence *= 2
sbd_elapsed_time_df = pd.DataFrame(elapsed_time_items)
f, ax = plt.subplots(figsize=(7, 7))
ax.set(xscale="log", yscale="log")
sns.scatterplot(data=sbd_elapsed_time_df, x='len_sentence', y='elapsed_time')
ax.set_title("文分割器(pySBD)の実行速度(sec)")
ax.set_xlabel('文字長 N')
ax.set_ylabel('実行時間(sec)')
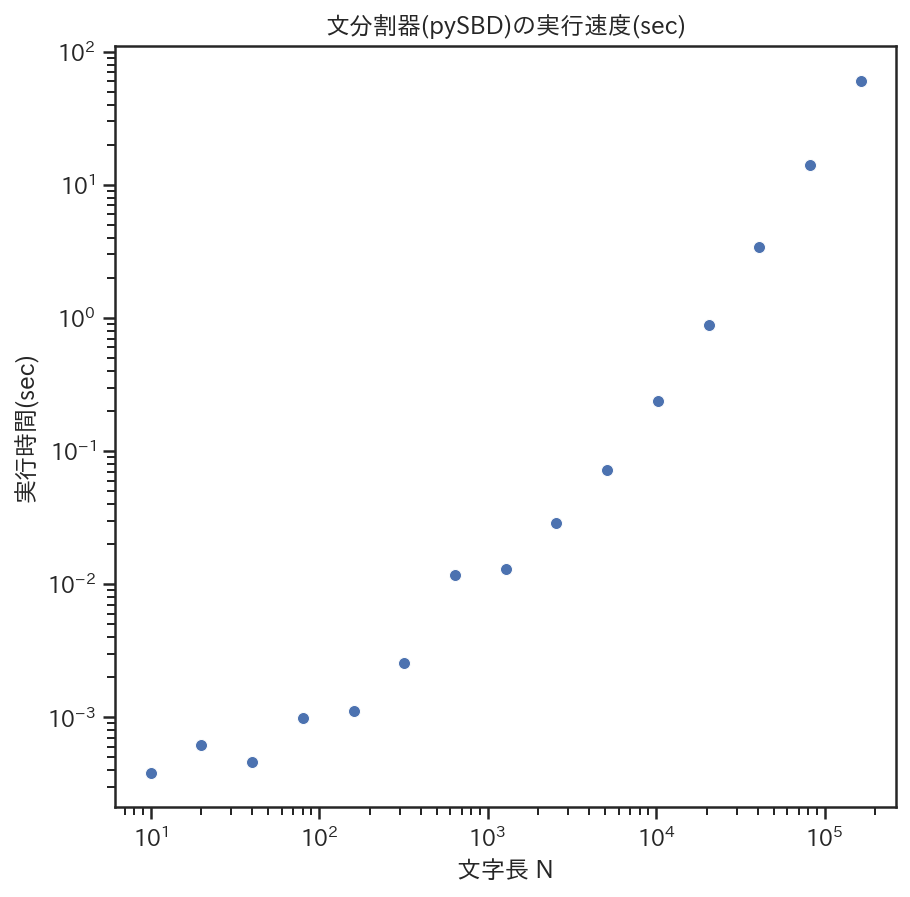
上記のコードでは,
入力長 N を,10文字,20文字,40文字,...と変化させていった場合の実行速度をプロット(注:対数グラフ)しています.
入力長 N が 163,840 文字のときは約60秒ほどかかっていました.
解析対象のコーパスの中に,このような長い文字列がないか(文分割器などへそのまま処理させていないか)などは事前にチェックしておいた方が良さそうです.
おわりに
本記事では,事前学習モデル (chiTra) の前処理に焦点を当てて文分割器の紹介をしました.
もちろん,本記事で扱えなかった文分割器などもあります.
(コメント等で,いろんな文分割器の情報を共有していただけると助かります)
chiTra は Works Applications が開発・公開しています.
何か困ったことや気になることがありましたら,質問や相談ができる Slack のワークスペースがありますので,ぜひお気軽にご連絡ください.
https://github.com/WorksApplications/SudachiTra#%E9%80%A3%E7%B5%A1%E5%85%88--contact-us