はじめに
今までは、VBAでスクレイピングをしていましたが、Internet Explorerがいつまで使えるか分かりません。
それで、PythonでChromeを対象としたスクレイピングを始めてみました。
環境はWindowsです。
今更な内容ですが、押さえて置いた方がよいであろう基本事項(多分、数か月後には忘れてしまう内容)を、個人的な備忘も兼ねて記しておきます。
<目次>
1. seleniumのインストール
2. WebDriverのダウンロード
3. ソースコードの記述
1. seleniumのインストール
まず、Pythonにseleniumというブラウザを操作するパッケージをインストールします。
次のように、コマンドプロンプトからpy -m pip install seleniumというコマンドを打つことでインストールできます。
>py -m pip install selenium
Collecting selenium
Downloading selenium-3.141.0-py2.py3-none-any.whl (904 kB)
|████████████████████████████████| 904 kB 1.1 MB/s
Collecting urllib3
Downloading urllib3-1.25.11-py2.py3-none-any.whl (127 kB)
|████████████████████████████████| 127 kB 939 kB/s
Installing collected packages: urllib3, selenium
Successfully installed selenium-3.141.0 urllib3-1.25.11
Python自体のインストール方法なども含めて、詳しくは、こちらに書いています。
2. WebDriverのダウンロード
次に、ブラウザの種類に応じたWebDriverが必要になります。
●参考書籍
中嶋英勝『PythonでExcel、メール、Webを自動化する本』SBクリエイティブ
2-1. ダウンロードサイト
次のような、ChromeDriverのダウンロードページを開きます。
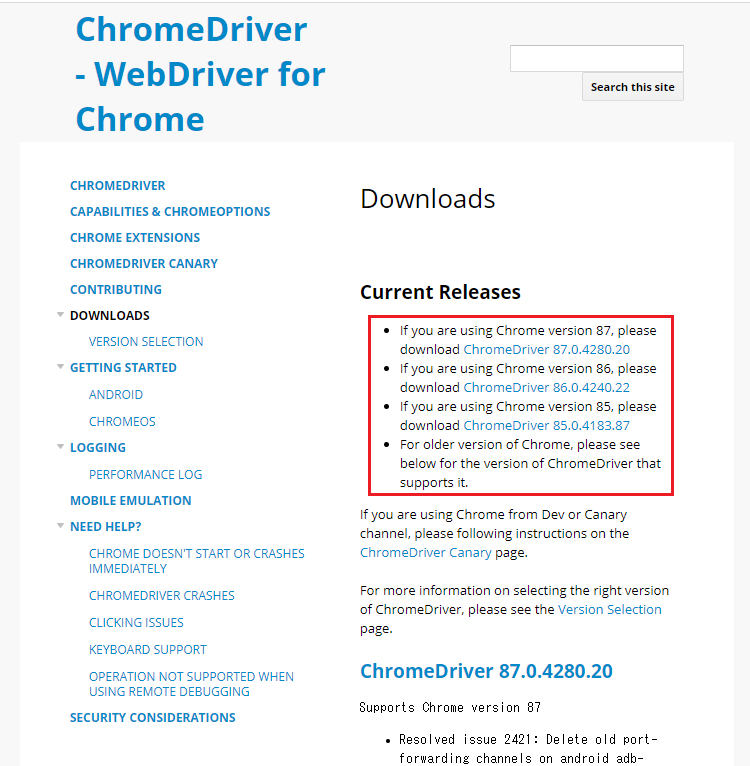
上記の赤枠には、3つのバージョン(87, 86, 85)のChromeDriverがあります。
このうち、現在使用しているChromeのバージョンに一致するものをダウンロードすることになります(次項参照)。
なお、ブラウザごとのWebDriverのリンクは「PyPI / selenium」のDriverの項から確認できます。
2-2. Chromeのバージョン確認
Chromeブラウザメニューの「ヘルプ(H)」から「Google Chrome について(G)」を開くとバージョンが確認できます。

私の環境では、Chromeのバージョンは86なので、先ほどのダウンロードサイトから、これに対応したChromeDriver 86.0.4240.22をクリックします。
2-3. WebDriverの取得
次のような画面が表示されたら、Windows用のChromeDriverをクリックしてインストールします。

ダウンロードしたファイルを解凍すると、次のようにchromedriver.exeというWebDriverを得ることができます。

このDriverを、Pythonのソースコードファイルと同じフォルダに置いて使用することになります(違うフォルダに置いて、ソースコードでパスの指定をしても良い。)。
3. ソースコードの記述
yahooのサイトを開いて検索を実行するコードを書くと次のようになります。
import time
from selenium import webdriver
driver = webdriver.Chrome() # WebDriverのインスタンスを作成
driver.get('https://www.yahoo.co.jp/') # URLを指定してブラウザを開く
time.sleep(2) # 2秒待機
search_box = driver.find_element_by_name('p') # name属性で検索ボックスを特定
search_box.send_keys('スクレイピング') # 検索ボックスにテキストを入力
search_box.submit() # 検索文言の送信(検索ボタンを押すのと同じ)
time.sleep(2) # 2秒待機
driver.quit() # ブラウザを閉じる
これは、ChromeDriverのサイトにあるコードを若干修正したものです。
実行すれば、ブラウザ(Chrome)が立ち上がり、yahooのサイトから「スクレイピング」の文言の検索を実行します。
以下、簡単に解説を残しておきます。
3-1. ライブラリのインポート
import time
from selenium import webdriver
基本はimport [ライブラリ名]の振合いで記述します。
1行目は、標準ライブラリのtimeをインポートしています。
2行目は、先ほどインストールしたパッケージseleniumからwebdriverというライブラリをインポートしています。
3-2. WebDriverのインスタンスの作成
3-2-1. ソースコードと同じフォルダにドライバを保存している場合
ソースコードと同じフォルダにChromeDriverを保存している場合は次のように記述すれば、WebDriverのインスタンス作成ができます。
driver = webdriver.Chrome()
3-2-2. ソースコードと異なるフォルダにドライバを保存している場合
一つ下のディレクトリ(フォルダ)にドライバーを保存している場合は、次のように記述します。
driver = webdriver.Chrome('Driver/chromedriver')
上記のDriverはディレクトリ名(フォルダ名)です。
3-2-3. インスタンスの変数名について
なお、(当然ですが)変数のdriverは何でも構いません。
次のように、変数をdにしても大丈夫です・
d = webdriver.Chrome()
3-3. URLを指定してブラウザを開く
次のように、[インスタンス名].get([URL名])の記述で、指定したサイトを開くことができます。
driver.get('https://www.yahoo.co.jp/')
3-4. ノードの取得
3-4-1. HTMLの確認
検索を実行するために、次のような検索文言を入力するテキストボックスの場所を読み取る必要があります。

これは、WEBページのHTMLを見て取得することになります。
テキストボックスのHTMLを確認するには、その場所を右クリックして「検証(I)」を選択します。
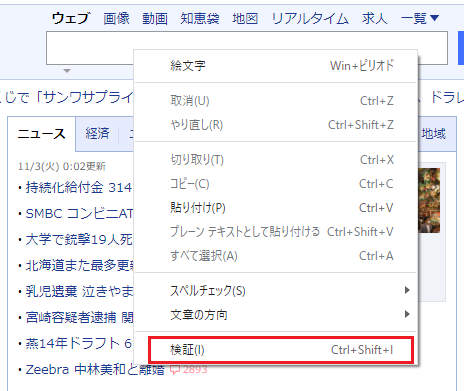
すると右側に、サイトのHTMLが表示されます。
そのうち、青くなっているところが該当箇所のHTMLとなります。

このHTMLでは、inputというタグの中に、type、class、nameなどの属性値が指定されています。
これらのタグ名、属性値を手がかりにして、必要な部分(ノード)を指定することになります。
タグ名や属性値は、同じものが重複する場合もあるので、まずは一意となる(ページ中でそれ一つしか無い)ものを探し出します。
確認すると次のclassとnameがページ中で1つしかないことが判明しました。
class="_1wsoZ5fswvzAoNYvIJgrU4"
name="p"
3-4-2. ノードを取得するソースコード
ここでは、よりシンプルなnameの属性値を用いて、次のようなコードで必要な部分(ノード)を取得します。
search_boxは変数なので、別名でも構いません。
search_box = driver.find_element_by_name('p')
nameの属性値でノードを取得する場合は、[インスタンス名].find_element_by_name([属性値])の振り合いで記述します。
なお、classの属性値で取得する場合は、次のように書きます。
search_box = driver.find_element_by_class_name('_1wsoZ5fswvzAoNYvIJgrU4')
3-4-3. ノード取得のためのメソッド
ノードを取得するためのメソッドは、name、class以外にもいくつか用意されています(このサイトを参照)。
3-4-3-1. ノードを単数で取得する場合
| メソッド | 取得対象 |
|---|---|
| find_element_by_id | id名(属性値) |
| find_element_by_name | name名(属性値) |
| find_element_by_xpath | XPathで取得 |
| find_element_by_link_text | リンクテキストで取得 |
| find_element_by_partial_link_text | リンクテキストの一部で取得 |
| find_element_by_tag_name | タグ名(要素) |
| find_element_by_class_name | class名(属性値) |
| find_element_by_css_selector | セレクタで取得 |
単数で取得する場合は、同名のものがあっても、最初に見つかったノードのみが取得されます。
なお、私のようにXPathをよく知らない方は、こちらの記事「クローラ作成に必須!XPATHの記法まとめ」を参照してください。使いこなせたらかなり便利だと思います。
3-4-3-2. ノードを複数(リスト)で取得する場合
| メソッド | 取得対象 |
|---|---|
| find_elements_by_name | id名(属性値) |
| find_elements_by_xpath | name名(属性値) |
| find_elements_by_link_text | リンクテキストで取得 |
| find_elements_by_partial_link_text | リンクテキストの一部で取得 |
| find_elements_by_tag_name | タグ名(要素) |
| find_elements_by_class_name | class名(属性値) |
| find_elements_by_css_selector | セレクタで取得 |
単数で取得する場合は、同名の全てのノードが、リスト形式で取得されます。
本来のHTMLの記述には、id名は一つのページの中に1つ、class名、name名は複数でも構わないなどのルールがありますが、id名が複数あるサイトもあるため、find_elements_by_nameなどの複数(リスト)取得のメソッドが用意されています。
複数取得の場合はリスト形式でノードを取得していることから、次のように要素番号までを指定する必要があります。
search_box = driver.find_elements_by_name('p')[0]
3-4-4. 【参考】ノードのノード(子要素以下)を取得する
ノードを取得する際に、一意のid名などがあれば簡単にコードが書けますが、そう都合良くいかない場合もあります。
そのような場合には、絞り込み検索をするような具合で、一旦、大きめの範囲のノードを指定して、その子要素(孫要素)のノードを指定するという方法をとることが多く発生します。
ノードのノードを取得する方法は、次のように単純にメソッドを連結することで実現できます。
search_box = driver.find_element_by_tag_name('fieldset').find_element_by_tag_name('input')
なお、変数を分けて書くことも可能です(下記)。
search_box1 = driver.find_element_by_tag_name('fieldset')
search_box = search_box1.find_element_by_tag_name('input')
2回目の絞り込みでは、子要素以下のノードが対象となります。
3-5. 検索ボックスにテキストを入力する
検索ボックスにテキストを入力するには、send_keysメソッドを使って次のように記載します。
ここでは「スクレイピング」という文言をテキストボックスに入力しています。
search_box.send_keys('スクレイピング')
3-6. 検索の実行
次のようにsubmitメソッドを使用することで、検索フォームに入力したテキストをWEBサイトのサーバに送信する(つまり検索を実行する)ことができます。
search_box.submit()
これは、HTMLのフォームデータをサーバに送信する操作をしていることになります。
なお、次のように、単純に「検索ボタンをクリックする」という命令を実行しても同じ結果を得ることができます。
search_box = driver.find_element_by_class_name('PHOgFibMkQJ6zcDBLbga8').click()
これは検索ボタンについてクラス名でノードを取得して、clickメソッドにより検索ボタンのクリック操作を行っていることになります。
3-7. ブラウザを閉じる
次のコードで、開いたブラウザを閉じることができます。
driver.quit()
さいごに
以上のところが基本の基本というところでしょうか。
これを書きながら、innerTextとかouterHTMLとかはどうやって取得するのだろうかと考えましたが、この辺も普通にメソッドが用意されていました。
Pythonのスクレイピングは、多くの方が利用されているので、結構使いやすくなっているように思われます。