はじめに
個人的な備忘として、ADOライブラリを使用してテキストファイル(CSV、TSVなど)をデータベースとして操作する方法をまとめておきます。
1. テキストファイルの種類(CSV、TSVなど)
まずは、対象となるテキストファイルの種類を表にしておきます。
一般的には、カンマ区切りのCSVファイルがほとんどですが、タブ区切り、セミコロン区切りのファイルなども存在します。
| データ形式 | 名称 | 区切り文字 |
|---|---|---|
| CSV | Comma-Separated Values | カンマ (,) |
| TSV | Tab-Separated Values | タブ (\t) |
| SSV | Space-Separated Values | スペース ( ) |
| CSV(EU) | (Comma-Separated Values) | セミコロン (;) |
最後のセミコロン区切りのCSVファイルは、主にヨーロッパで使用されているようです(小数点区切りにカンマを使用しているためその回避策とのこと)。
2. ADOを使用した接続方法
ここでは、Excel VBAを使用しますが、Access VBAやWord VBAでも基本的には同じです。
最初に基本的な例として、CSVファイルを読み込むサンプルコードを挙げておきます。
事前の準備として、以下の内容のCSVファイルを、Excelファイルと同じフォルダに入れておきます。
品名,区分,単価,購入数,購入日
にんじん,野菜,70,3,2020/10/20
りんご,果物,150,2,2020/10/22
みかん,果物,40,10,2020/10/30
キャベツ,野菜,180,1,2020/11/1
じゃがいも,野菜,50,5,2020/11/5
バナナ,果物,300,2,2020/11/6
メロン,果物,1500,1,2020/11/8
2-1. CSVファイルの読み込み(SELECT文)
Excelファイルの標準モジュールに次のコードを記載します。
この例は、参照設定にMicrosoft ActiveX Data Object 6.1 Libraryを追加している場合です。
<ソースコード>
Sub CSVSample_Select()
'ADOを使用してCSVファイルに接続(参照設定にMicrosoft ActiveX Data Object 6.1 Libraryを適用済み)
Dim cn As New ADODB.Connection
cn.Provider = "Microsoft.ACE.OLEDB.12.0"
cn.Properties("Extended Properties") = "Text;HDR=Yes"
cn.Open ThisWorkbook.Path & "\"
'SELECT文の実行
Dim rs As New ADODB.Recordset
rs.Open "SELECT * FROM TestTable.csv WHERE 区分 = '野菜' ORDER BY 単価", cn
'取得した内容(Recordset)の確認
Do While Not rs.EOF
Debug.Print rs("品名") & ", " & rs("区分") & ", " & rs("単価") & ", " & rs("購入数") & ", " & rs("購入日")
rs.MoveNext
Loop
'メモリの解放
rs.Close: Set rs = Nothing
cn.Close: Set cn = Nothing
End Sub
<出力結果>
次のように、WHERE句による絞り込みと、ORDER BY句による並べ替えを実行した結果が出力されます。
じゃがいも, 野菜, 50, 5, 2020/11/05
にんじん, 野菜, 70, 3, 2020/10/20
キャベツ, 野菜, 180, 1, 2020/11/01
以下、拡張プロパティ、Schema.iniファイルについて簡単な説明をしていきます。
その他のADOライブラリの基本事項は、こちらなどを参照してください。
<参考サイト>
エクセルの神髄 - ADOでCSVの読み込み(SQL)
2-2. 拡張プロパティ(Extended Properties)
テキストファイルのADO接続で重要なのは拡張プロパティ(Extended Properties)を記載した次の1行です。
指定文字列として、"Text;HDR=Yes"というようにセミコロンで区切って2つのプロパティを設定しています。
cn.Properties("Extended Properties") = "Text;HDR=Yes"
最初のTextはISAMの指定で、これにより「カンマ区切りのCSVファイルを読み込むこと」が設定されます。
次のHDR=Yesでは、「1行目をカラム名で読み込むこと」を指定しています(指定しなくともデフォルトでYes)。
現在のプロバイダ(Microsoft.ACE.OLEDB.12.0)の拡張プロパティではこの2つしか指定できないようです(おそらく)。
なお、Office2003以前のプロバイダ(Microsoft.Jet.OLEDB.4.0)であれば次のように細かく指定することができました。
cn.Properties("Extended Properties") = "Text;HDR=Yes;FMT=CSVDelimited;TypeGuessRows=12"
FMT(Formatの略)では区切り文字(カンマやタブなど)を指定して、TypeGuessRowsではデータ形式の判定を行う行数を指定しています。
一覧で比較すると次のようになります。
| 指定文字列 | Microsoft.Jet. OLEDB.4.0 | Microsoft.ACE. OLEDB.12.0 | 指定内容 |
|---|---|---|---|
| Text | ○ 要指定 | ○ 要指定 | 接続対象をテキストファイルとすることを指定 |
| HDR=Yes HDR=No |
○ 指定可能 (デフォルトはYes) |
○ 指定可能 (デフォルトはYes) |
1行目をヘッダーとするか否かを指定 |
| FMT=CSVDelimited FMT=TabDelimited FMT=Delimited(x) |
○ 要指定 | × 指定できない (カンマ区切り固定) |
区切り文字を指定 |
| TypeGuessRows=[数字] | ○ 指定可能 | × 指定できない (8行固定) |
データ形式の推測を行う行数を指定 |
現在のMicrosoft.ACE.OLEDB.12.0の拡張プロパティでは、区切り文字の指定(FMT)やデータ形式の読取り行数の指定(TypeGuessRows)はできません。
これらの指定が必要な場合は、次に説明するSchema.iniファイルにて行うことになります。
<参考サイト>
ADO.NET text file ConnectionString Extended Properties
2-3. Schema.iniファイル
テキストファイルの種類(CSV、TSVなど)や読取り方法などの設定は、対象となるテキストファイルと同じフォルダに、次のようなSchema.iniファイルを作成して行います。
<2つのテキストファイルを指定する場合のSchema.iniファイルの例>
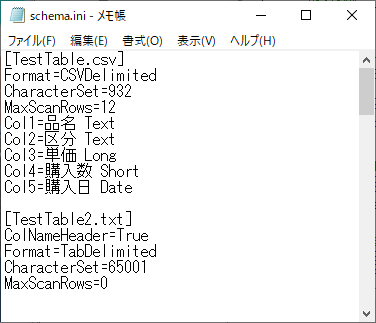
<作成方法>
・テキストエディタ(メモ帳でOK)でファイル名「Schema.ini」のファイルを作成します。
・対象となるテキストファイル名は角括弧で括って記載します。
・ファイル名に続いてキーワードと設定内容を=で結びます。
・同フォルダ内の複数のテキストファイルの設定をする場合は、上記のように2つ並べて記載します。
・記載内容に大文字小文字の区別はないようです(Formatでもformatでも構わない)。
<記載内容>
1つ目のTestTable.csvファイルの指定内容は以下のようになっています。
[TestTable.csv]
Format=CSVDelimited
CharacterSet=932
MaxScanRows=12
Col1=品名 Text
Col2=区分 Text
Col3=単価 Long
Col4=購入数 Text
Col5=購入日 Date
簡単に言うと、Formatは区切り文字の指定(FMTと同じ)、CharacterSetは文字コードの指定、MaxScanRowsはデータ形式の推測を行う行数を指定(TypeGuessRowsと同じ)を行っています。
続くCol1からCol5は、各カラムのデータを読み込む際の「カラム名の指定」、「データ型の指定」を行っています(1~5の数字はカラムの順番です)。
詳細は、次のとおりです。
2-3-1. 指定できる項目の一覧
Schema.iniファイルで指定できる項目は主に次のとおりです。
| 項目 | 指定内容 | 指定例 |
|---|---|---|
| [ファイル名] | テキストファイル名を指定 | [Sample.txt] |
| Format | 区切り文字を指定 | Format=CSVDelimited |
| CharacterSet | テキストファイルの文字コードを指定 | CharacterSet=65001 |
| MaxScanRows | データ形式の推測を行う行数を指定 | MaxScanRows=12 |
| ColNameHeader | 1行目をヘッダーとするか否かを指定 | ColNameHeader=TRUE |
| Coln | カラム名とデータ型を指定(固定長の場合はフィールド幅も指定) | Col1=ID Long |
以下、個別に見ていきます。
<参考URL>
Understanding Schema.ini Files
2-3-2. ファイル名の指定
次のようにファイル名と拡張子を指定します。
[Sample.txt]
拡張子は.txtと.csvは指定できますが、.tsvは指定できませんでした(拡張子を.txtに変えれば読み取れます)。
2-3-3. Formatの指定
キーワードFormatでは、読み込むテキストファイルの区切り文字を指定します。
# カンマ区切り(CSVファイル)
Format=CSVDelimited
# タブ区切り(TSVファイル)
Format=TabDelimited
# スペース区切り(SSVファイル)
Format=Delimited( )
# セミコロン区切り(CSV(EU))
Format=Delimited(;)
# 固定長
Format=FixedLength
用意されてる値を表にすると次のとおりです
| 指定値 | 区切り文字 | 説明 |
|---|---|---|
| CSVDelimited | カンマ (,) | カンマ区切りのファイル(CSVファイル)の場合に使用 |
| TabDelimited | タブ (\t) | タブ区切りのファイル(TSVファイル)の場合に使用 |
| Delimited(指定文字) | カスタム | 任意の区切り文字を指定できる(二重引用符(")を除く) |
| FixedLength | なし(固定長) | 区切り位置は固定長のフィールド幅で判定 |
<参考URL>
Specifying the File Format
もはや不要だとは思いますが、TSVファイル、SSVファイル、固定長のファイルのサンプルコードを以下書いておきます。
2-3-3-1. タブ区切りファイル(TSV)のサンプルコード
タブ区切りファイル(TSVファイル)を読み取る場合のサンプルコードです。
TSVファイルですが、拡張子は.txtとしています(.tsvが読み込めないため)。
<VBAのコード>
Sub TSVSample_Select()
'ADOを使用してテキストファイルに接続(参照設定にMicrosoft ActiveX Data Object 6.1 Libraryを適用済み)
Dim cn As New ADODB.Connection
cn.Provider = "Microsoft.ACE.OLEDB.12.0"
cn.Properties("Extended Properties") = "Text;HDR=Yes"
cn.Open ThisWorkbook.Path & "\"
'SELECT文の実行
Dim rs As New ADODB.Recordset
rs.Open "SELECT * FROM TestTableTsv.txt WHERE 区分 = '野菜' ORDER BY 単価", cn
'取得した内容(Recordset)の確認
Do While Not rs.EOF
Debug.Print rs("品名") & ", " & rs("区分") & ", " & rs("単価") & ", " & rs("購入数") & ", " & rs("購入日")
rs.MoveNext
Loop
'メモリの解放
rs.Close: Set rs = Nothing
cn.Close: Set cn = Nothing
End Sub
<Schema.iniファイルの記載>
[TestTableTsv.txt]
Format=TabDelimited
2-3-3-2. スペース区切りファイル(SSV)のサンプルコード
スペース区切りファイル(SSVファイル)を読み取る場合のサンプルコードです。
SSVファイルですが、拡張子は.txtとしているのは前例と同様です。
<VBAのコード>
Sub SSVSample_Select()
'ADOを使用してテキストファイルに接続(参照設定にMicrosoft ActiveX Data Object 6.1 Libraryを適用済み)
Dim cn As New ADODB.Connection
cn.Provider = "Microsoft.ACE.OLEDB.12.0"
cn.Properties("Extended Properties") = "Text;HDR=Yes"
cn.Open ThisWorkbook.Path & "\"
'SELECT文の実行
Dim rs As New ADODB.Recordset
rs.Open "SELECT * FROM TestTableSsv.txt WHERE 区分 = '野菜' ORDER BY 単価", cn
'取得した内容(Recordset)の確認
Do While Not rs.EOF
Debug.Print rs("品名") & ", " & rs("区分") & ", " & rs("単価") & ", " & rs("購入数") & ", " & rs("購入日")
rs.MoveNext
Loop
'メモリの解放
rs.Close: Set rs = Nothing
cn.Close: Set cn = Nothing
End Sub
<Schema.iniファイルの記載>
[TestTableSsv.txt]
Format=Delimited( )
2-3-3-3. 固定長ファイルのサンプルコード
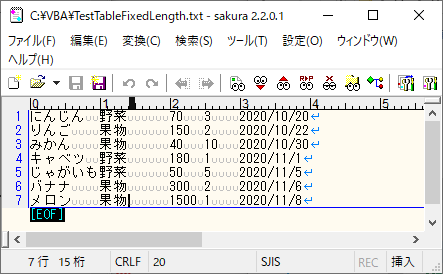
最後に、データの区分を区切り文字ではなく、フィールドの長さで判定する場合のサンプルコードです。
次のようなテキストファイルを準備します。
なお、半角文字の長さは1、全角文字の長さは2でカウントされるようです(SHIFT_JISファイル及びUTF-8ファイルで確認)。
<VBAのコード>
Sub FixedLengthSample_Select()
'ADOを使用してテキストファイルに接続(参照設定にMicrosoft ActiveX Data Object 6.1 Libraryを適用済み)
Dim cn As New ADODB.Connection
cn.Provider = "Microsoft.ACE.OLEDB.12.0"
cn.Properties("Extended Properties") = "Text;HDR=Yes"
cn.Open ThisWorkbook.Path & "\"
'SELECT文の実行
Dim rs As New ADODB.Recordset
rs.Open "SELECT * FROM TestTableFixedLength.txt WHERE 区分 = '野菜' ORDER BY 単価", cn
'取得した内容(Recordset)の確認
Do While Not rs.EOF
Debug.Print rs("品名") & ", " & rs("区分") & ", " & rs("単価") & ", " & rs("購入数") & ", " & rs("購入日")
rs.MoveNext
Loop
'メモリの解放
rs.Close: Set rs = Nothing
cn.Close: Set cn = Nothing
End Sub
<Schema.iniファイルの記載>
[TestTableFixedLength.txt]
ColNameHeader=False
Format=FixedLength
Col1=品名 Text Width 10
Col2=区分 Text Width 10
Col3=単価 Long Width 5
Col4=購入数 Text Width 5
Col5=購入日 Date Width 10
2-3-4. CharacterSetの指定
キーワードCharacterSetでは、テキストファイルの文字コードを指定します。
何も指定しないとSHIFT_JISで読み込まれます(現時点の環境では)。
# SHIFT_JIS(デフォルト)
CharacterSet=932
# UTF-8
CharacterSet=65001
# Unicode(UTF-16)
CharacterSet=1200
# EUC-JP
CharacterSet=51932
文字コードはMicrosoftの定めるコードページ(数字)で指定します。
日本語に関係するコードページの主なところは、次のとおりです。
| コードページ | 文字コード | サクラエディタの指定 |
|---|---|---|
| 932 | SHIFT_JIS | SJIS |
| 1200 | UTF-16(Unicode) | Unicode |
| 1201 | UTF-16BE(Unicode) | UnicodeBE |
| 12000 | UTF-32(Unicode) | - |
| 12001 | UTF-32BE(Unicode) | - |
| 20932 | EUC-JP(JIS 0208-1990 and 0212-1990) | EUC-JP |
| 50220 | JIS(ISO-2022-JP) | JIS |
| 51932 | EUC-JP | EUC-JP |
| 65000 | UTF-7(Unicode) | UTF-7 |
| 65001 | UTF-8(Unicode) | UTF-8, CESU-8 |
最後のカラムはサクラエディタ(テキストエディタ)で指定できる文字コードとの対応を示しています。
<参考サイト>
ADODBでUTF-8のCSVを取り込む
コードページ識別子
CESU-8(通信用語の基礎知識)
2-3-5. MaxScanRowsの指定
キーワードMaxScanRowsでは、データ形式の推測を行う行数を指定を指定します。
何も指定しない場合のデフォルト値は8行です。
# 12行分読み取って判定する場合
MaxScanRows=12
# 全ての行を読み取って判定する場合
MaxScanRows=0
基本的には、指定した数値だけレコードを読み取ってデータ型を判定します。
ただし、MaxScanRows=0と指定すると、全てのレコードを読み取ります。
判定されたデータ型に変換できないデータはNullとなりますので注意が必要です。
なお、カラムごとのデータ型を指定すると(Colnの指定)、MaxScanRowsの指定は反映されません。
2-3-6. ColNameHeaderの指定
キーワードColNameHeaderでは、1行目をカラム名として読み込むか否かを指定します。
# 1行目をヘッダーと指定する
ColNameHeader=True
# 1行目をヘッダーと指定しない(全てレコードとして読み取る)
ColNameHeader=False
読み込んだデータが指定したデータ型と合わない場合はNullとなります。
この指定はExtended PropertiesにおけるHDRの指定と重複しますがどちらでも指定できます。
2-3-7. Colnの指定
キーワード**Coln**では、各カラムのデータを読み込む際の「カラム名の指定」、「データ型の指定」のほか、オプションとして「フィールド長」の指定を行います
# 各データのフィールド長を指定しない場合(区切り文字でデータを区分する場合)
Col1=品名 Text
Col2=区分 Text
Col3=単価 Long
Col4=購入数 Short
Col5=購入日 Date
# 各データのフィールド長を指定する場合(固定長字でデータを区分する場合などで使用)
Col1=品名 Text Width 10
Col2=区分 Text Width 10
Col3=単価 Long Width 5
Col4=購入数 Text Width 5
Col5=購入日 Date Width 10
各データのフィールド長を指定する場合の例は2-3-3-3. 固定長ファイルのサンプルコードを参照してください。
指定できるデータ型は次の表のとおりです。
| データ型 | 種類 | サイズ | 扱える範囲 |
|---|---|---|---|
| Bit | 真偽型 | 1bit | True(1) / False(0) |
| Byte | (整数型) | 1byte | 0 ~ 255 |
| Short (Integer) | 短整数型 | 2byte | -32,768 ~ 32,767 |
| Long | 長整数型 | 4byte | -2,147,483,648 ~ 2,147,483,647 |
| Currency | 通貨型 | 8byte | -922337203685477.5808 ~ 922337203685477.5807 |
| Single | 単精度浮動小数点数型 | 4byte | 有効桁数7桁の実数(おおよそ) |
| Double (Float) | 倍精度浮動小数点数型 | 8byte | 有効桁数15桁の実数(おおよそ) |
| DateTime (Date) | 日付時刻型 | 8byte | 100-01-01 00:00:00 ~ 9999-12-31 23:59:59 |
| Text (Char) | 文字列型 | - | 最大255文字 |
| Memo (LongChar) | 文字列型 | - | (最大65,536文字?) |
データ型の括弧内はODBCデータ型です(このデータ型を記載しても同様に挙動します)。
値の範囲は、解説が見つからなかったので、実際に値を入れて調べました。
Memo型の最大文字数は確認していません(Accessと同様であれば最大65,536文字あたりでしょうか)。
3. 各種SQL構文のサンプルコード
以上では、SELECT文でテキストファイルを読み込みましたが、その他のSQL構文も使用できるものがあります。
なお、テキストファイルを更新したり、一部削除する操作はできない仕様のようです。
主なSQL構文の使用の可否をまとめると次のとおりです。
| SQL構文 | 使用可否 | 補足 |
|---|---|---|
| CREATE TABLE文 | ○ | 新しいテキストファイルが作成される |
| INSERT文 | ○ | テキストファイルの末尾にレコードが追加される |
| UPDATE文 | × | ファイルの書き換えはできない |
| DELETE文 | × | ファイルの内容の一部削除はできない |
| DROP TABLE文 | ○ | テキストファイルが削除される |
3-1. CREATE TABLE文
以下のサンプルコードを実行すると、新しいテキストファイルが作成されます。
'CREATE TABLE文(テーブル作成)
Sub CSVSample_CreateTable()
'ADOを使用してCSVファイルに接続
Dim cn As New ADODB.Connection
cn.Provider = "Microsoft.ACE.OLEDB.12.0"
cn.Properties("Extended Properties") = "Text"
cn.Open ThisWorkbook.Path & "\"
'CREATE TABLE文の実行
Dim cm As New ADODB.Command
cm.ActiveConnection = cn
cm.CommandText = "CREATE TABLE CreateTestTable.csv(" & _
"品名 TEXT(20)," & _
"区分 TEXT(10)," & _
"単価 LONG," & _
"購入数 INTEGER," & _
"購入日 DATE)"
cm.Execute
'メモリの解放
Set cm = Nothing
cn.Close: Set cn = Nothing
End Sub
3-2. INSERT文
以下のサンプルコードを実行すると、テキストファイルの末尾にレコードが追加されます。
なお、RecordsetオブジェクトのAddNewメソッドを使用しても、同様にレコードの追加が可能です。
'INSERT文(データの追加)
Sub CSVSample_Insert()
'ADOを使用してCSVファイルに接続
Dim cn As New ADODB.Connection
cn.Provider = "Microsoft.ACE.OLEDB.12.0"
cn.Properties("Extended Properties") = "Text"
cn.Open ThisWorkbook.Path & "\"
'INSERT文の実行
Dim cm As New ADODB.Command
cm.ActiveConnection = cn
cm.CommandText = "INSERT INTO CreateTestTable.csv VALUES ('ほうれんそう', '野菜', 150, 2, '2021-2-25')"
cm.Execute
'メモリの解放
Set cm = Nothing
cn.Close: Set cn = Nothing
End Sub
3-3. DROP TABLE文
以下のサンプルコードを実行すると、テキストファイルが削除されます。
'DROP TABLE文(テーブル削除)
Sub CSVSample_DropTable()
'ADOを使用してCSVファイルに接続
Dim cn As New ADODB.Connection
cn.Provider = "Microsoft.ACE.OLEDB.12.0"
cn.Properties("Extended Properties") = "Text"
cn.Open ThisWorkbook.Path & "\"
'DROP TABLE文の実行
Dim cm As New ADODB.Command
cm.ActiveConnection = cn
cm.CommandText = "DROP TABLE CreateTestTable.csv"
cm.Execute
'メモリの解放
Set cm = Nothing
cn.Close: Set cn = Nothing
End Sub
3-4. テーブルが存在するか否かを確認する
テーブル(テキストファイル)が存在するか否かの確認を行うこともできます。
以下の例では、データベースのテーブル一覧を取得するためにADOXオブジェクトを使用するために、事前にMicrosoft ADO Ext. 6.0 for DDL and Securityというライブラリの参照設定をしています。
なお、このライブラリのTablesコレクションで取得されたファイル名は、ピリオドがシャープに変換されていたため(理由は不明です)、その点の補正もしています。
'テーブルが存在するかの確認を実行
Sub IsExistCSVTableTest()
Debug.Print IsExistCSVTable("TestTable_コピー.csv")
End Sub
'テーブルが存在するか否かを確認する関数(戻り値:True=存在する, False=存在しない)
Function IsExistCSVTable(tblName As String) As Boolean
tblName = Replace(tblName, ".", "#") 'Tablesコレクションでピリオドがシャープに変換されるため
'ADOを使用してCSVファイルに接続
Dim cn As New ADODB.Connection
cn.Provider = "Microsoft.ACE.OLEDB.12.0"
cn.Properties("Extended Properties") = "Text"
cn.Open ThisWorkbook.Path & "\"
Dim ct As New ADOX.Catalog: ct.ActiveConnection = cn 'Catalogオブジェクトを現在のDBに関連付け
Dim tbl As Table 'テーブルオブジェクトを格納する変数
IsExistCSVTable = False '初期値を明示(書かなくともFalse)
For Each tbl In ct.Tables 'CatalogオブジェクトのTablesコレクションを1つずつ取得
If tbl.Type = "TABLE" And StrComp(tbl.Name, tblName, vbTextCompare) = 0 Then 'TableオブジェクトのTypeプロパティとNameプロパティで一致するかを確認
IsExistCSVTable = True
Exit For
End If
Next
Set ct = Nothing 'Catalogオブジェクトの解放
cn.Close: Set cn = Nothing 'Connectionオブジェクトの解放
End Function
さいごに
ADOファイルでテキストファイルを読み込む場合、読み込むデータ型の指定が詳細にできるのが便利です。
Excelファイルでも同様の指定ができると良いのですが。