The day of CosineSimilarity!!?
2025年1月21日 強力なアイテム「コサイン類似度」をゲット
もしかしてLLMのRAG界隈では常識のアイテムなのかもしれませんが第3回金融データ活用チャレンジ|【初学者向け】LLMを活用したRAG(Retrieval-Augmented Generation)ハンズオンで自分は「コサイン類似度」をゲットしました.
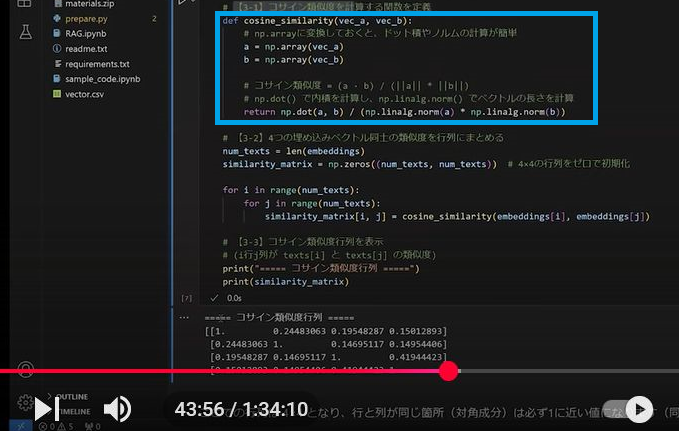
動画にも映ってます(青枠)がソースはこれ.
def cosine_similarity(vec_a, vec_b):
"""
コサイン類似度を計算する関数。
例: cosine_similarity([1,0,0], [0.7,0.7,0])
ベクトルaとベクトルbの内積を、両ベクトルのノルムの積で割ることで求める。
"""
a = np.array(vec_a) # listをnp.arrayに変換
b = np.array(vec_b)
# dot()で内積を計算し、linalg.norm()でベクトルの長さ(ノルム)を計算
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
これがどういうものかGemini-2.0-flushの説明によると

Gemini-2.0-flushに数学的に説明してもらうと
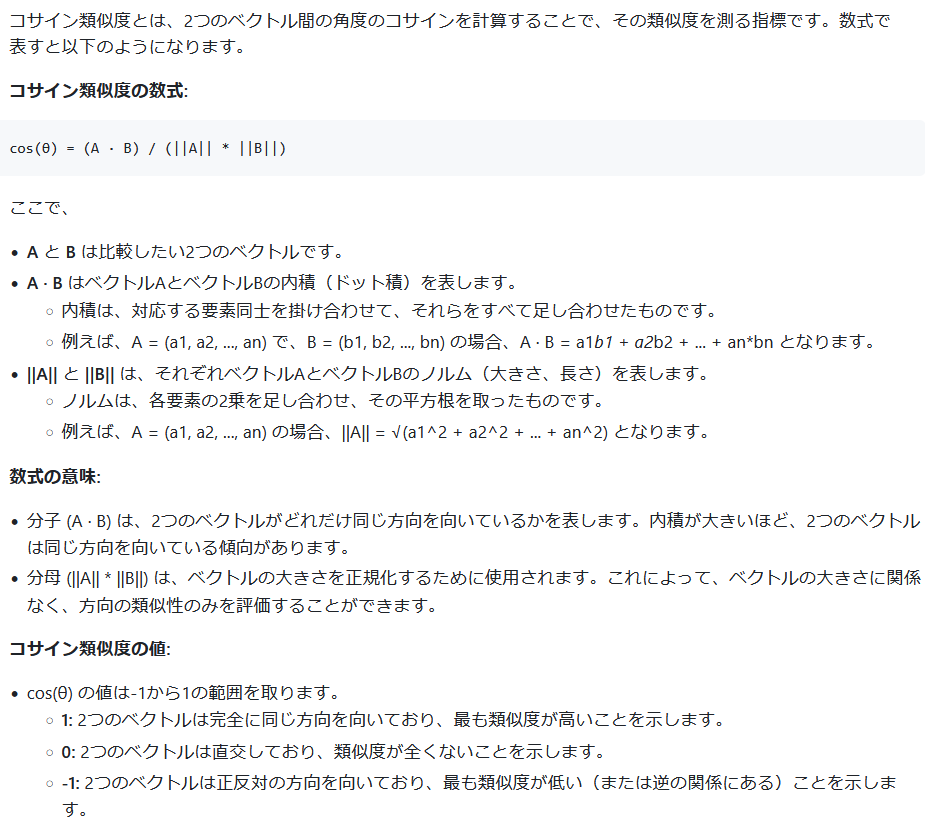
内積という数学用語を理解するポイントは
- ベクトルa,bの対応する要素同志を掛け合わせてそれらをすべて足し合わせたもの
- np.dot(a, b)
- ① aの長さ||a||, ② bの長さ||b||, ③ aとbの間の角度θのcos(θ) この3つを掛けた値
- np.linalg.norm(a) * np.linalg.norm(b) * np.cos(θ)
- この2つの値は直観的に理解しがたいが数学で計算すると同じ値になりこれが aとbの内積として定義される
マイクロソフト様のcosine_similarity関数は
np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
を返却していますがこれはaとbの間の角度θのcos(θ) と同値になります.
「コサイン類似度」はどう使って何がすごかった?
第3回金融データ活用チャレンジ では19個のPDF(企業のESGレポートや統合報告書)が与えられ「???グループの2024年3月期の非常勤監査役は何人?」という質問に対して回答を作成する必要があります.
19個のPDFに格納される全量データのなかでこの質問の回答に必要な情報はかなり限られておりほとんどが不要な情報です.
不要な情報はノイズになり回答精度に悪影響を与えるのでそれらは取り除き回答に必要な情報のみを絞り込んでLLMのインプットとして提供する必要があります.
回答の答えを知ってそうなPDFの該当ページを検索するためにどうすればよいか?
2025年1月21日 ハンズオンでゲットしたソリューションは以下の内容です.
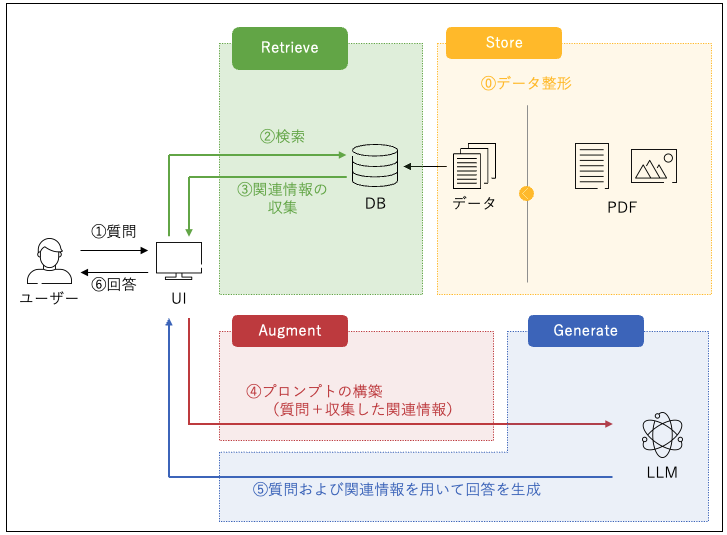
Store
LLM埋め込み(Embedded)モデルを使って各PDFの各ページのテキストをベクトル変換してストレージ(ディスクやメモリ)に格納します.
このベクトルは質問ベクトルの突合に使うために必要なものです.
PDFのページのテキストが長すぎる場合はLLM埋め込み(Embedded)モデルによっては分割する必要があります.
個人的直観的見解ではありますが,あまりにも長い文章を2,048個の浮動小数点に圧縮するみたいなことは精度上の懸念があるのでベクトル変換する文章は適切なサイズの分割(この適切なサイズが自分にはわかりませんが)が必要かもしれないです.
| LLM埋め込み(Embedded)モデル | インプット(MAX) | 出力次元数(MAX) |
|---|---|---|
| text-embedding-3-large | 8,192 tokens | 3,072 |
| voyage-3-large | 32,000 tokens | 2,048 |
| text-embedding-004 | 2,048 tokens | 768 |
文章のベクトル化はAzure OpenAIだとこんな感じになります.
client = AzureOpenAI(
api_key=AZURE_OPENAI_API_KEY,
azure_endpoint=AZURE_OPENAI_ENDPOINT,
api_version=API_VERSION
)
response = client.embeddings.create(
input=text,
model=DEPLOYMENT_ID_FOR_EMBEDDING
)
text_vector = response.data[0].embedding
Retrieve
質問文をLLM埋め込みモデルでベクトル化してStoreに格納された各PDFの各ページのテキスト(ベクトル)と片っ端から突き合わせてコサイン類似度を計算します.
そのあとでコサイン類似度の大きい順に並び変えて上位10テキスト(これはベクトルではなくもとになる文章)をLLMのchatモデルに与えて質問の回答を依頼します.
このハンズオンの手法で今回のコンペでは上位に着地できたようです.