先日 twitter にて SeLU がホットな話題として交わされていたので 関心がわき、シンプルなNN で 見てみました。
結果をここにまとめ公開します。参考になれば幸いです。
背景・経緯
- 深層学習の理解を深めようと、自前で実装を行ってます。
- 先日(2017/6 上旬) にて、twitter の TL で SeLU がホットな話題として交わされてるの見て、関心わきました。
- SeLU と eLU は 似てるらしい。
- SeLU と eLU と ReLU とで見比べます。
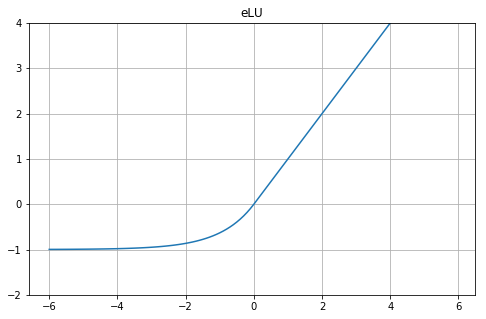
eLU
def eLU(x):
alpha = 1.0
return np.where(x>=0.0, x, alpha*np.exp(x)-alpha)
SeLU
def SeLU(x):
alpha = 1.6732632423543772848170429916717
scale = 1.0507009873554804934193349852946
return scale*np.where(x>=0.0, x, alpha*np.exp(x)-alpha)
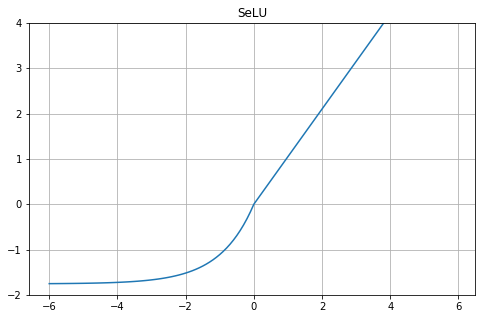
- $X=0$ にエッジがあるんですね。
MNIST 300epoch での比較
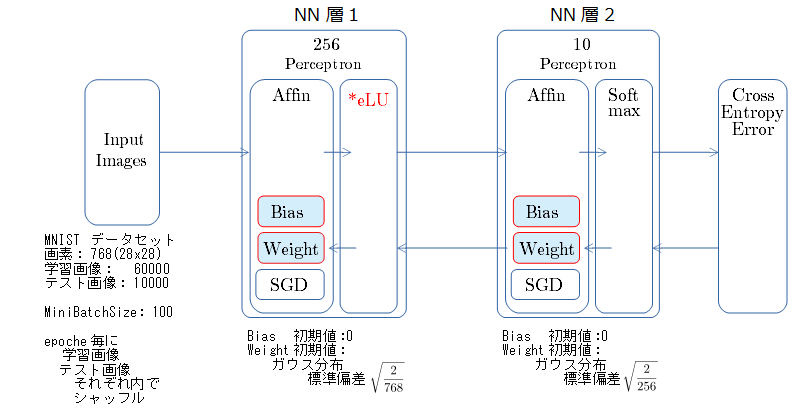
- 300 epoch までのテスト画像での正解率の推移
- 乱数種値は 20170523 で固定
- SGD の学習率は 0.001 で固定
- LeakyReLU の負側の傾きは 0.01
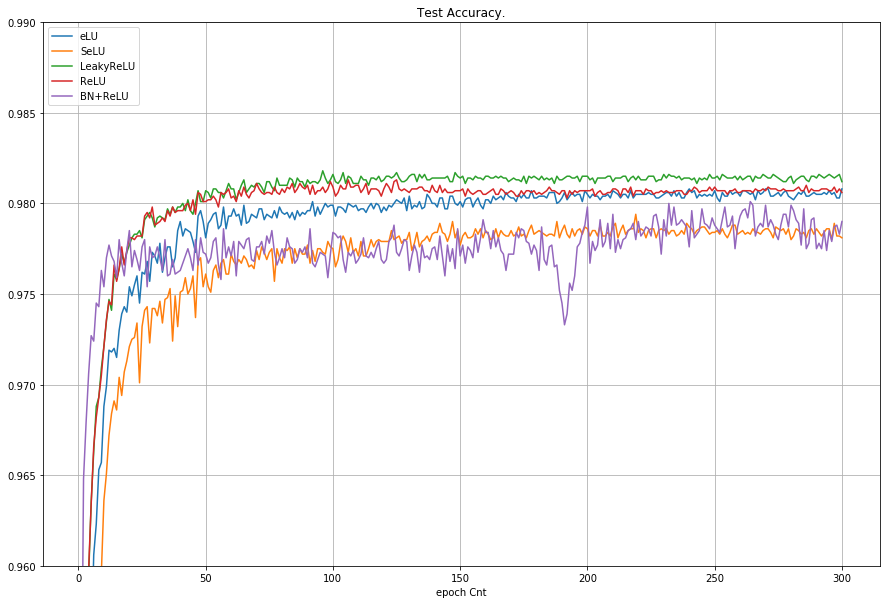
グラフから読み取ったこと
- LeakyReLU が 正解率 98.1% で健闘してます。
- eLU は ReLU と 同等、LeakyReLUから だいたい 0.1% 位下がる。
- 負側の傾きの有無の差が 0.1%位の差と出ている様に見える。
- SeLU と BN+ReLU は 97.9%位 で だいたい同じ。
- (もっと際立った特徴でるかと期待してました...)
学習率を大きくした場合での比較
先日の記事シンプルなNNで 学習失敗時の挙動と Batch Normalization の効果を見る と同様に、学習率が大きく学習失敗した時と、学習が進む場合で、重みとバイアスの推移を比較しました。
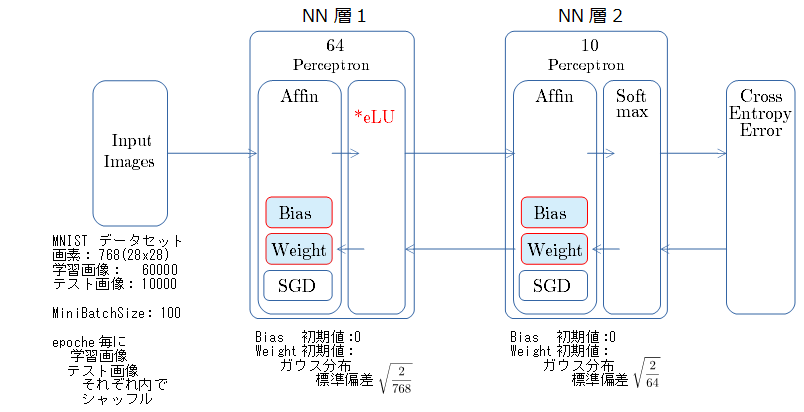
- 乱数種値は 20170523 固定
- 学習率2つで比較。「学習が失敗する場合」と 「順調に進む場合」 で比較する。
- ミニバッチ600回 (1 epoche) 期間での測定。
- 「①学習時正解率」は、学習時の正解率。 横軸はミニバッチ回数、縦軸は正解率。グラフは上に行くほど良く正解率が高い。
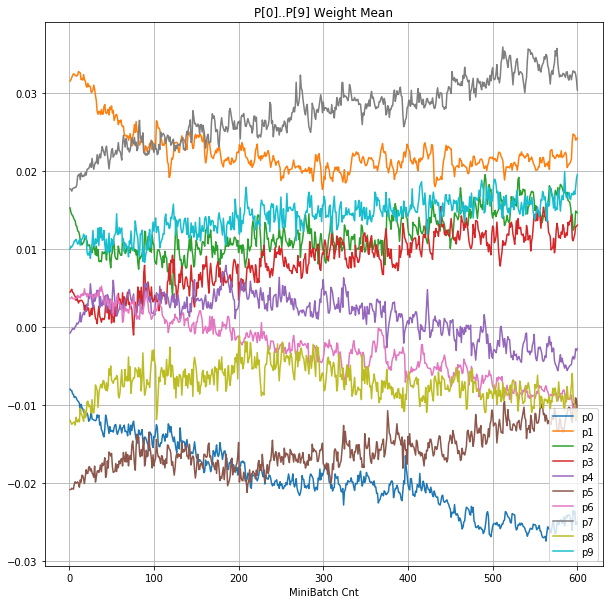
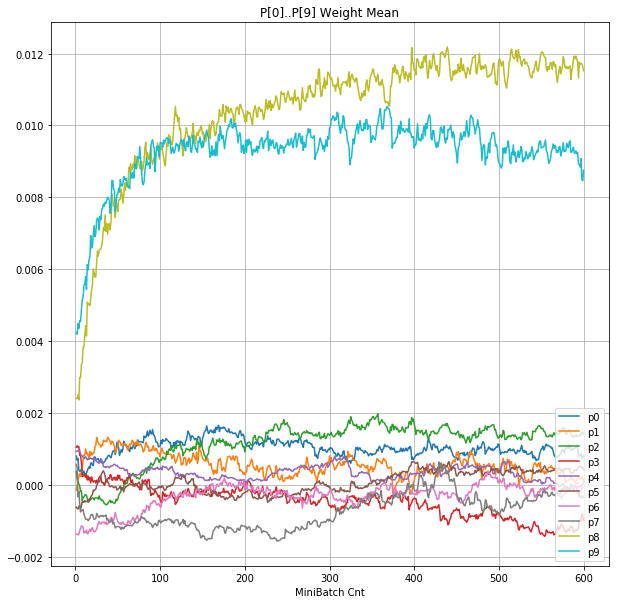
- 「②層2 Weight」は、層2の10個のパーセプトロンへのweight(10個) の平均値の推移のグラフ。横軸はミニバッチ回数、縦軸はWeight値。振動していれば学習の進行中で、横線(振動がない)状態はdying 状態。
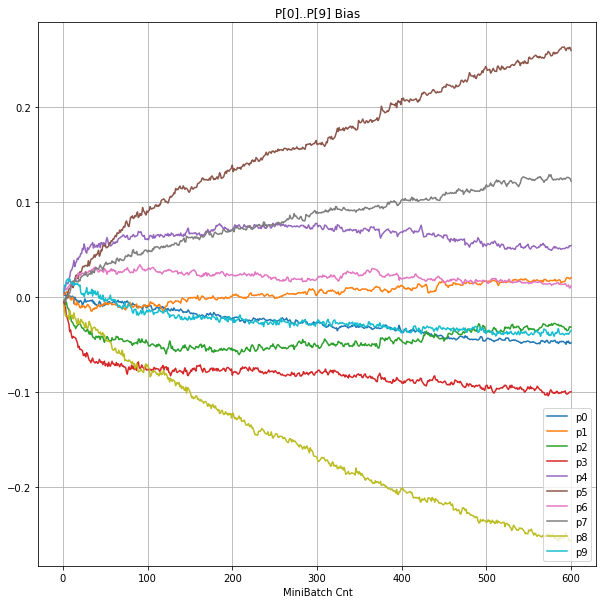
- 「③層2 Bias」は、層2の10個のパーセプトロンへの Bias 値の推移のグラフ。横軸はミニバッチ回数、縦軸はBiasの値。
- 「④層1 Weight]は、層1の64個のパーセプトロン中の10個に注目し、各注目パーセプトロンへのWeight(768個)の平均値の推移のグラフ。横軸はミニバッチ回数、縦軸はWeight値。振動していれば学習の進行中で、横線(振動がない)状態はdying 状態。
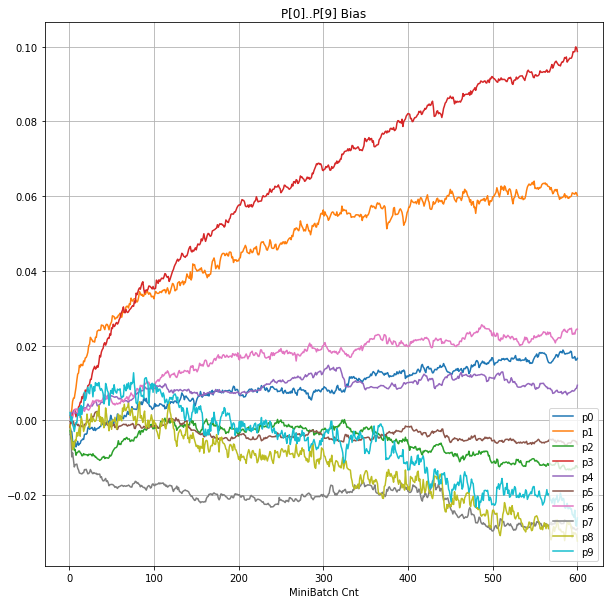
- 「⑤層1 Bias」は、④で注目したパーセプトロンへの Bias 値の推移のグラフ。横軸はミニバッチ回数、縦軸はBiasの値。
eLU
| 学習率 | 0.01 | 0.001 |
|---|---|---|
| 備考 | 学習失敗 | 順調 |
| ①学習時正解率 | 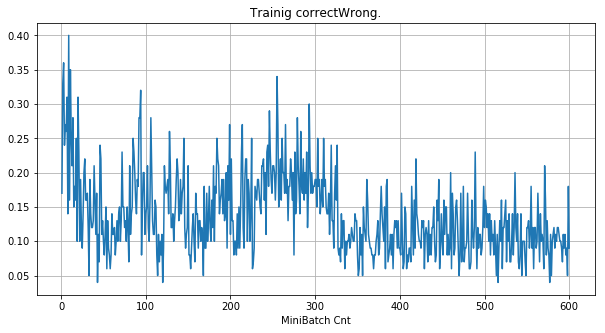 |
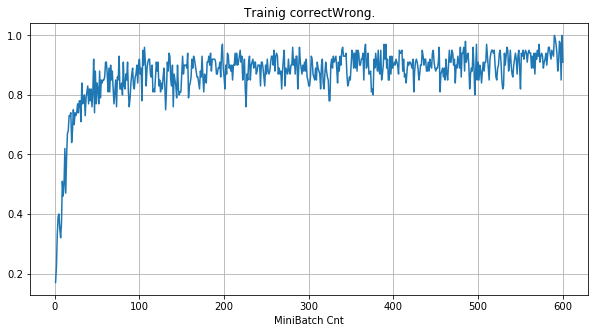 |
| ②層2Weight | 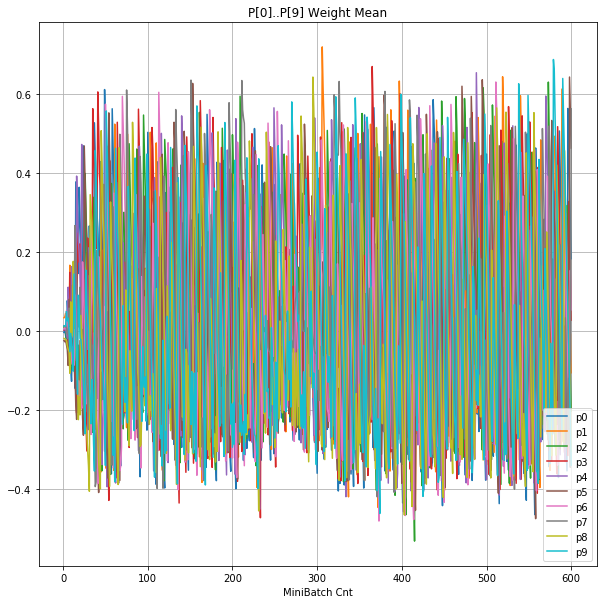 |
 |
| ③層2Bias |  |
 |
| ④層1Weight | 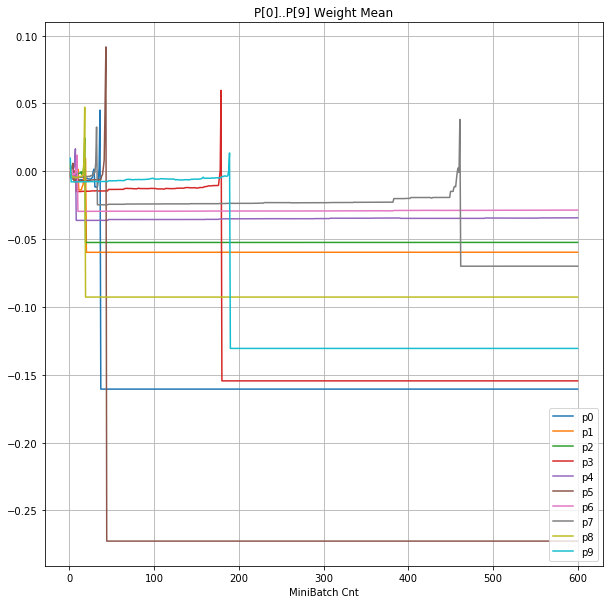 |
 |
| ⑤層1Bias | 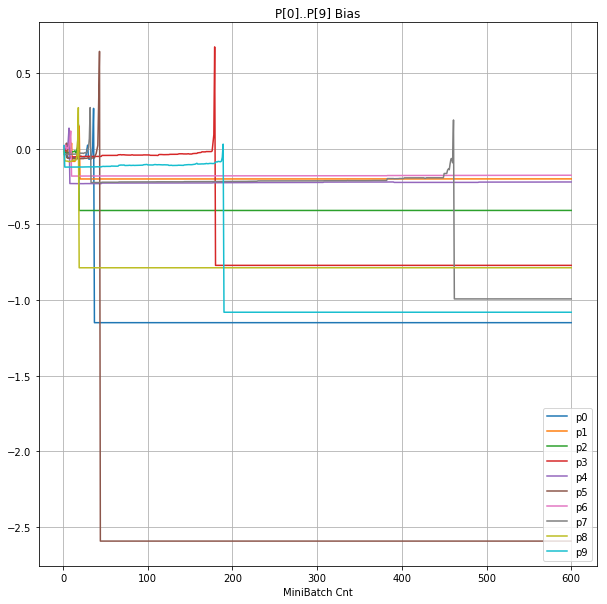 |
 |
SeLU
| 学習率 | 0.01 | 0.001 |
|---|---|---|
| 備考 | 学習失敗 | 順調 |
| ①学習時正解率 | 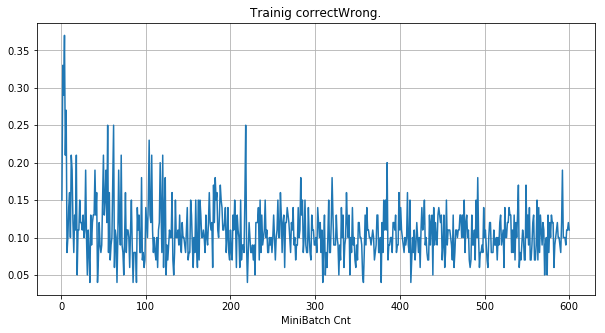 |
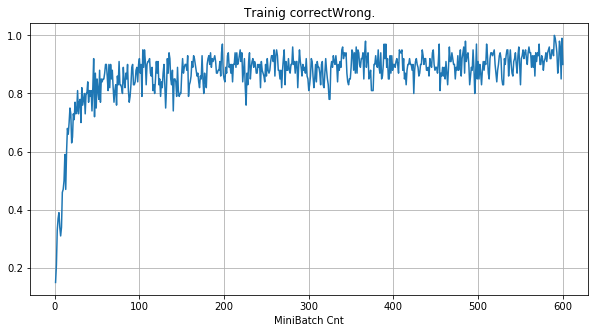 |
| ②層2Weight | 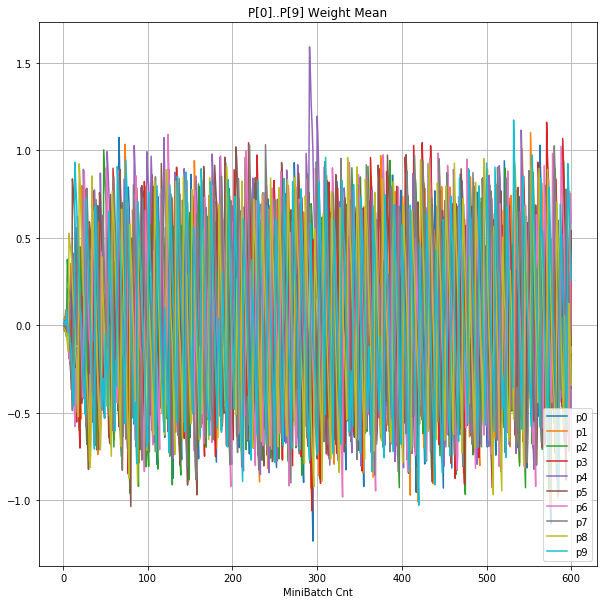 |
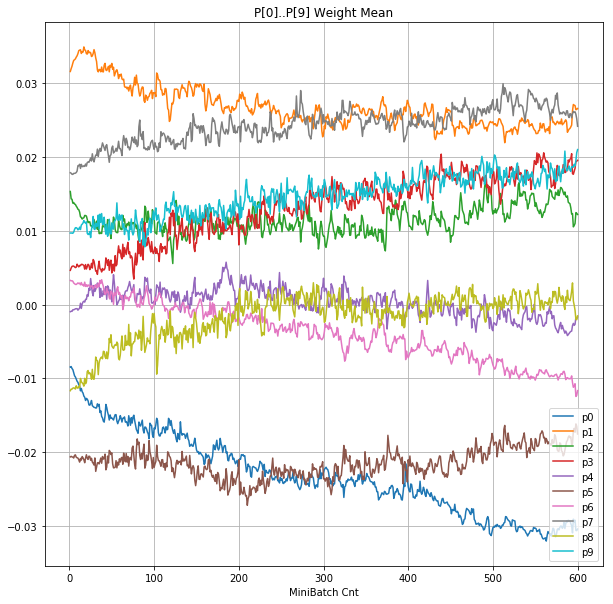 |
| ③層2Bias | 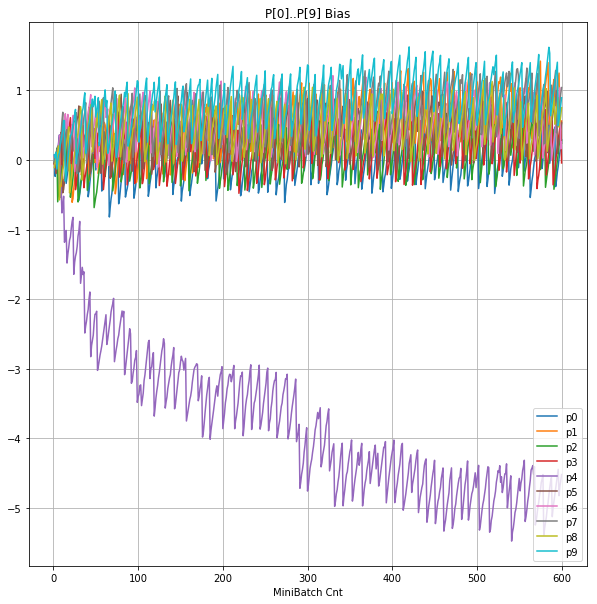 |
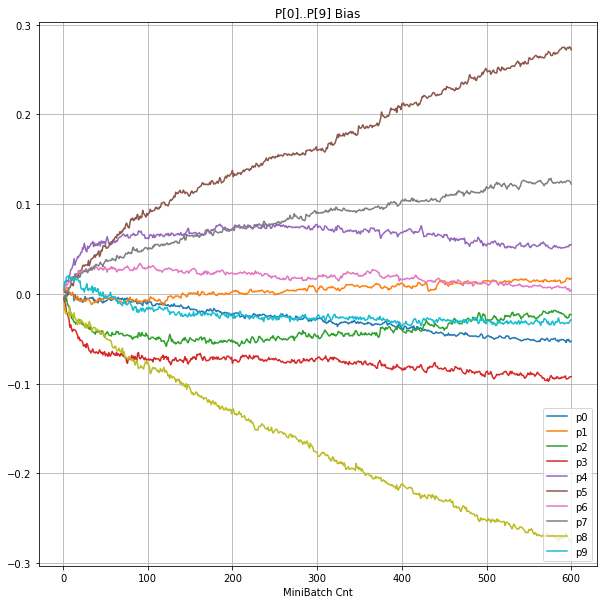 |
| ④層1Weight | 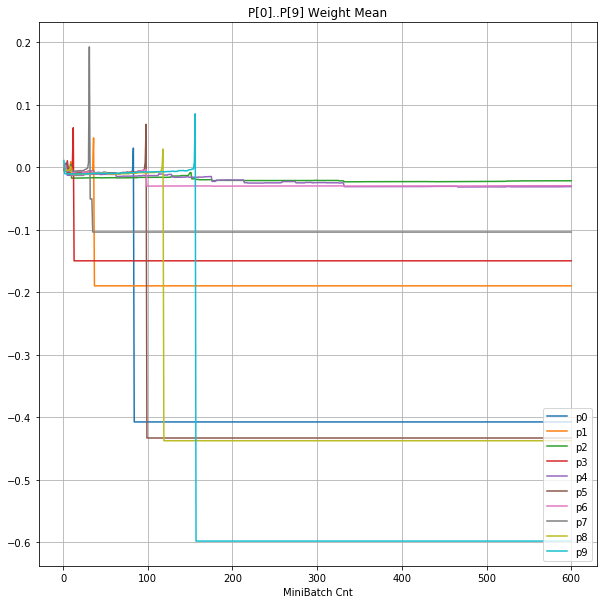 |
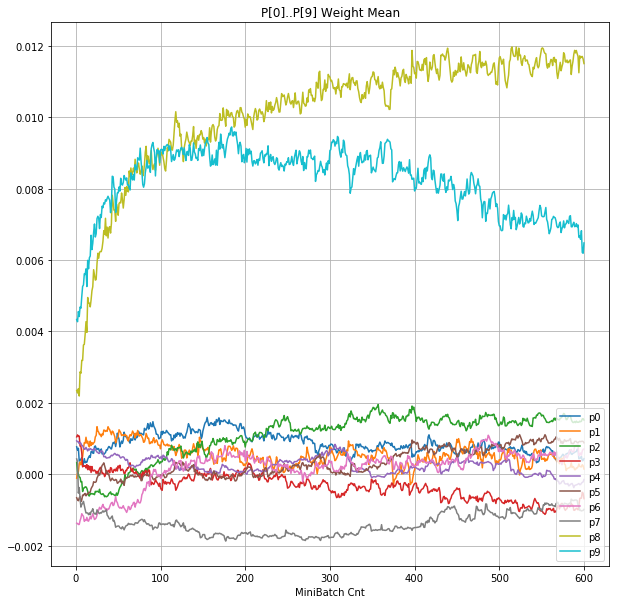 |
| ⑤層1Bias | 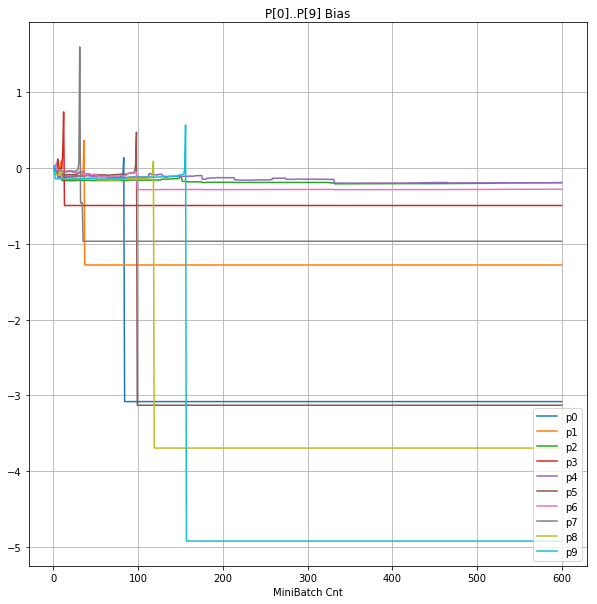 |
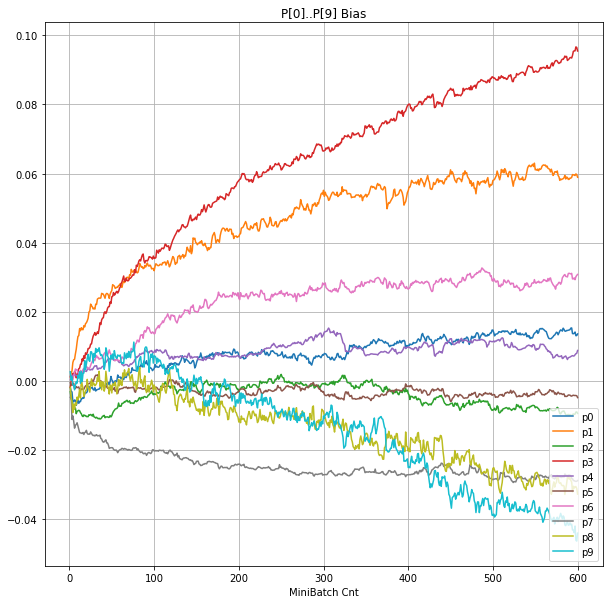 |
グラフから読み取ったこと
- 学習率 0.01 では、eLU と SeLU ともに学習失敗している。
- ReLU と LeakyReLU も 0.01 の学習率にて、一応学習は進んでいた。 →先日の記事
- 層1のWeightとBiasをみるに、負側に大きく振れた場合に、横線で反応がなくなる状態(dying)が目立つ。
- 発散よりも、負側の傾きがなくなるところで無反応な状態になりやすそう。
まとめ
- eLU SeLU の良さは シンプルはNNでは目立たず、もっと多層や、複雑なデータを扱うときに発揮されるのでしょうか......