仕組みを学んでいると、すでに世の中に高速なConvolution処理が出回っていても、自前でもConvolution 処理を実装してみたくなりますよね(なりました)。
面白そうな論文「arXiv:1704.04428」の手法を真似て実装しました。
結果は... うん、まぁ... cudnn スゲぇなぁ を体感する事となりました......。
私の実装では、期待してたほどの処理速度には至りませんでしたが、資料をここにてまとめます。
なにかの参考になればと思い公開いたします。
背景
- 深層学習の理解を深めようと、自前で実装を行ってます。
- Convolution 処理についても、理解を深めるため、自前で実装します。
- cudnn 使えば イイじゃん なんですけども ソレはソレ。
- Im2Col方式での実装を考えていましたが、(arXiv:1704.04428) Parallel Multi Channel Convolution using General Matrix Multiplicationの v1 の kn2col-aa方式を面白く感じ、この論文を基に BLAS を用いて実装します。
Convolution 処理について
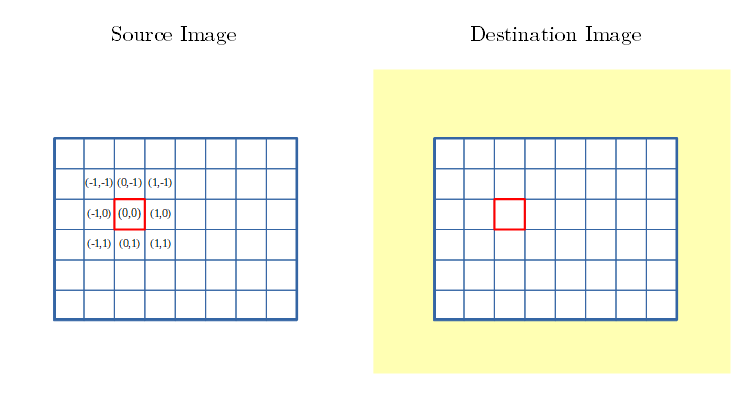
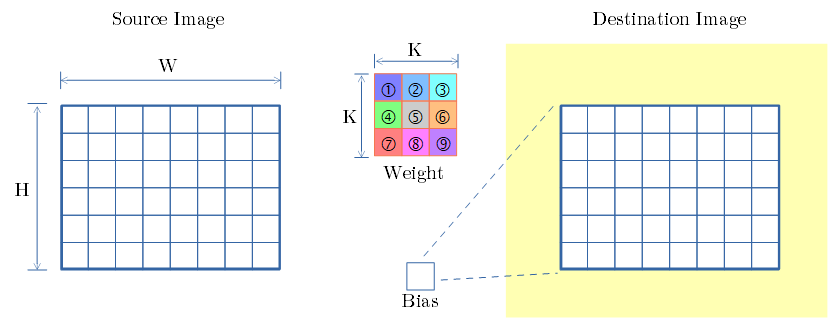
カーネルサイズ3x3での Convolution処理の図解
- 畳み込み処理についてです。
- 一画素一枠の8×6の画像で示します。(下図)
- 注目画素を赤枠に囲ってあります。
- 注目画素と近傍に、相対座標を記してます。
- 以後、本文中では Source Image を src 、Destination Inage を dst と略記します。
- 下図は 3x3 のフィルタを示します。
- 下図は、1画素の畳み込みを示します。
- 注目画素と近傍画素に、フィルタの各重みを掛け、足し合わせ、変換後の画素の値となります。
dstの注目画素=
画素(-1,-1)×① + 画素(0,-1)×② + 画素(1,-1)×③
+ 画素(-1, 0)×④ + 画素(0, 0)×⑤ + 画素(1, 0)×⑥
+ 画素(-1, 1)×⑦ + 画素(0, 1)×⑧ + 画素(1, 1)×⑨
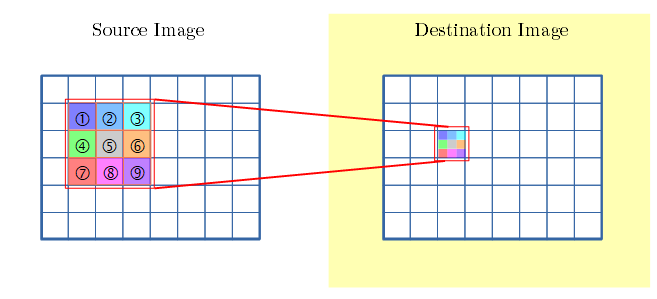
- 上図では、色で、変換後の画素が、近傍のどの要素から足し合わされたかを示しています。
SCSK (Single Channel Single Kernel)
- src側のチャンネル数:1 & dst側のチャンネル数:1 の単純な例で 畳み込み処理 の流れを示します。
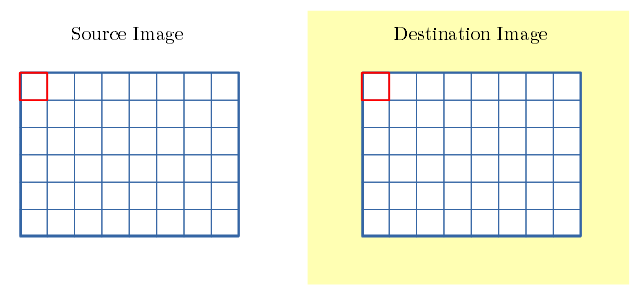
- 構成要素は、src画像、dst画像、3x3フィルタ、Bias値。
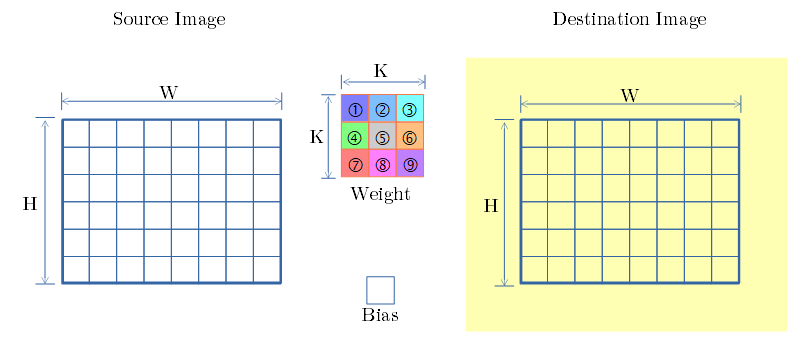
- Bias値で dst画像を ブロードキャスト。
- 画像の左上を 始点 と呼称します。(下図の赤枠)
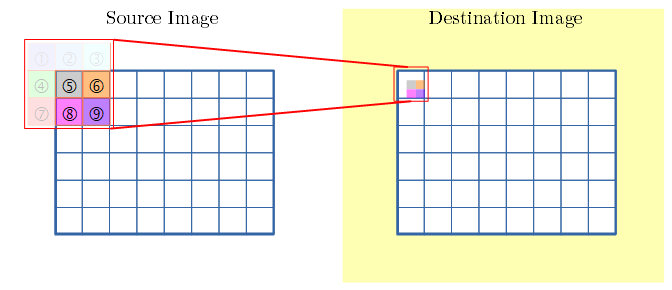
- 始点の 畳み込みを行います。
- 近傍で画像外になる所は 対象外とします。
- 下図で dst側 には、畳み込みに用いた箇所(⑤⑥⑧⑨)を色で示してます。
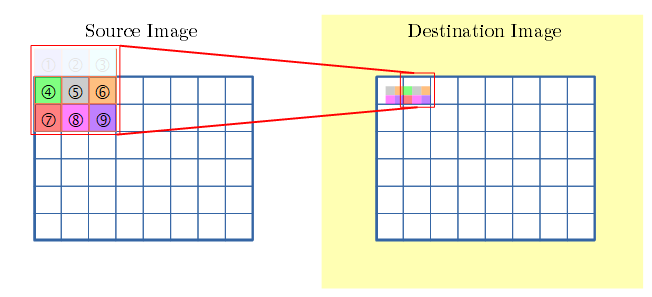
- 注目点を右に移動。
- 有効な画素(④⑤⑥⑦⑧⑨)とで畳み込みを行います。
- 同様に右端まで行い...
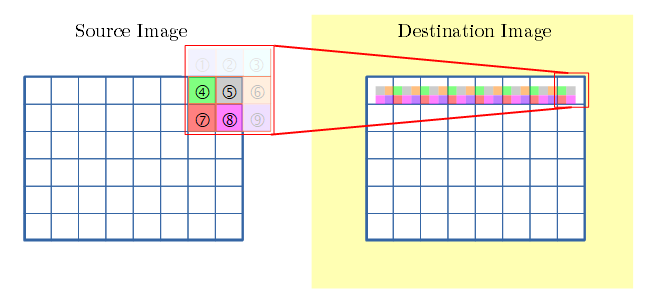
- 同様に各行の各画素を順に、畳み込みを行います。
- 画像の右下を 終点 と呼称します。(下図の注目画素)
- 終点まで 畳み込みを行います。
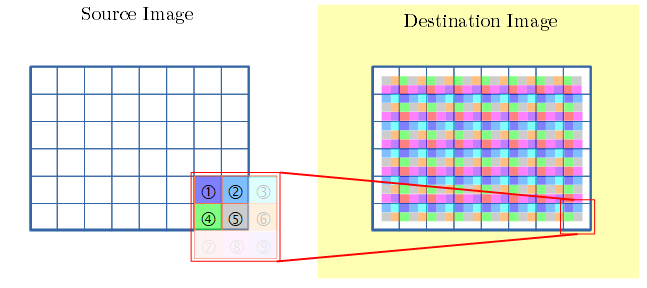
- 上図では、dst側は、各画素が近傍のどこから畳み込みを行ったかを示す図になっています。(後の説明で使います)
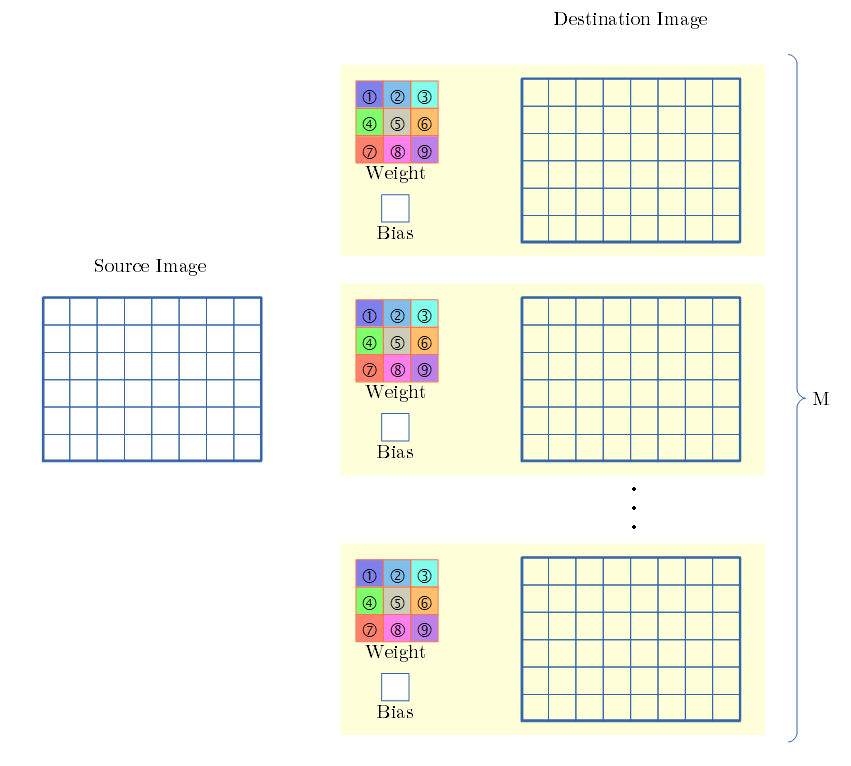
SCMK (Single Chanel Multi Kernel)
- src側のチャンネル数は1、dst側のチャンネル数は複数、での例です。
- dst側のチャンネル毎に、フィルタとBias値 があります。
- 1つのsrc から 各dstの用のフィルタとBias値 を用いて 畳み込み変換を行います。
- 各dstでの畳み込み変換は SCSKと同じです。
MCSK (Multi Channel Single Kernel)
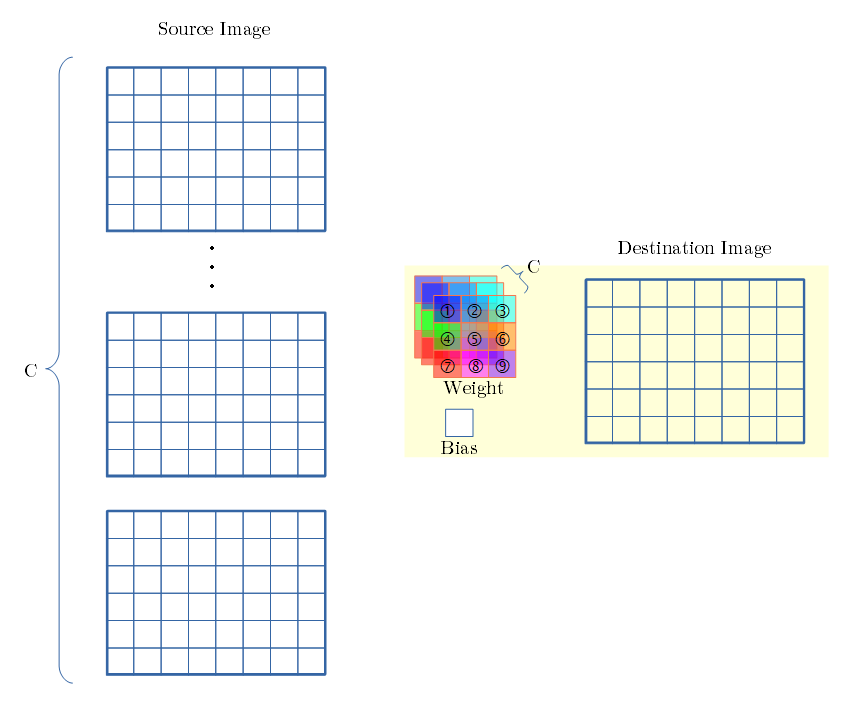
- src側のチャンネル数が複数、dst側はチャンネル数が1、での例です。
- dst側に、フィルタはsrc側のチャンネル数分あります。ですが、Bias値は1個です。
- 各src側チャンネル からの 畳み込み変換は SCSKと同じです。
- dst側では、各srcからの畳み込み変換値を 足し合わせます。
MCMK (Multi Channel Multi Kernel)
- src側のチャンネル数は複数、dst側のチャンネル数も複数、での例です。
- dst側のチャンネル毎に、src側のチャンネル数分のフィルタと、Bias値があります。
- 各dstでの畳み込み変換は、MCSKと同じです。
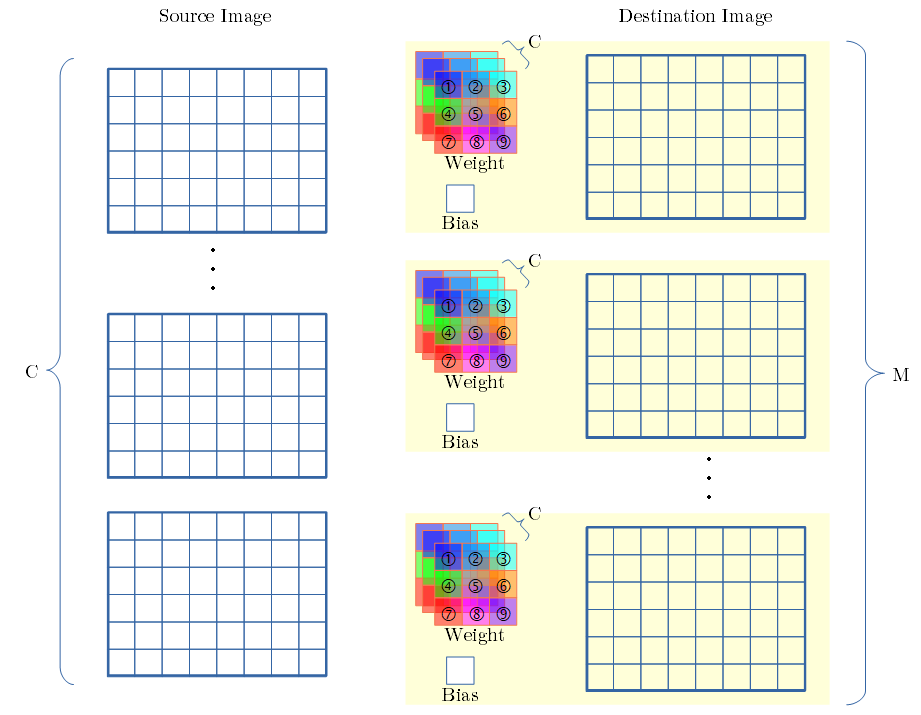
Kn2Image 方式
- (arXiv:1704.04428) Parallel Multi Channel Convolution using General Matrix Multiplication の Kn2raw-aa 方式を基にしています。
- 論文からの追加内容は、paddingの配置と、MiniBatch 対応です。
- この方式の特徴は、フィルタの重み毎に、行列演算を行う事です。
- 3×3のフィルタ(9個の重み)では、9回、画像(チャンネル数×MiniBatch)の行列演算を行い、足し合わせます。
- 以下、順を追って図解します。
SCSK での例
- src 画像を、下図で示す様に、パディングを入れてシリアライズ化します。
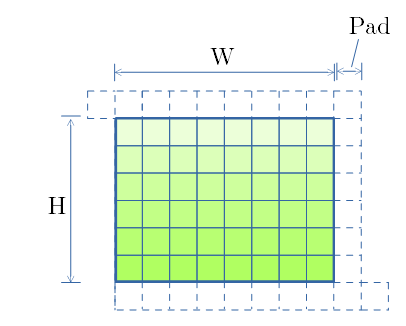


- TailPad は SCSKでは紹介のみです。 後述の MCMK × miniBatch にて用いるパディング領域です。
- 順伝播での流れを示します。 フィルタの色にも注目して下さい。
- 下図の①〜⑨は、フィルタの①〜⑨の処理に対応します。
- ①の、ずらした2行は、上行はsrc側(In)、下行はdst側(Out)を示します。
- ①の上行は、Inの各画素に ①の重みを掛けた値を示します。①の色で示してます。
- ①の上行の値を、下行に足し込みます。
- ズレ量の Line+1 は、注目画素と①の相対位置です。
- ②は、上行と下行のズレ量を Line にします。 これは、注目画素と②の相対位置です。
- 以下③〜⑨を、相対位置分ずらして、足し込んで行きます。
- (⑤は相対位置のズレがないため、上行と下行にズレはないです)
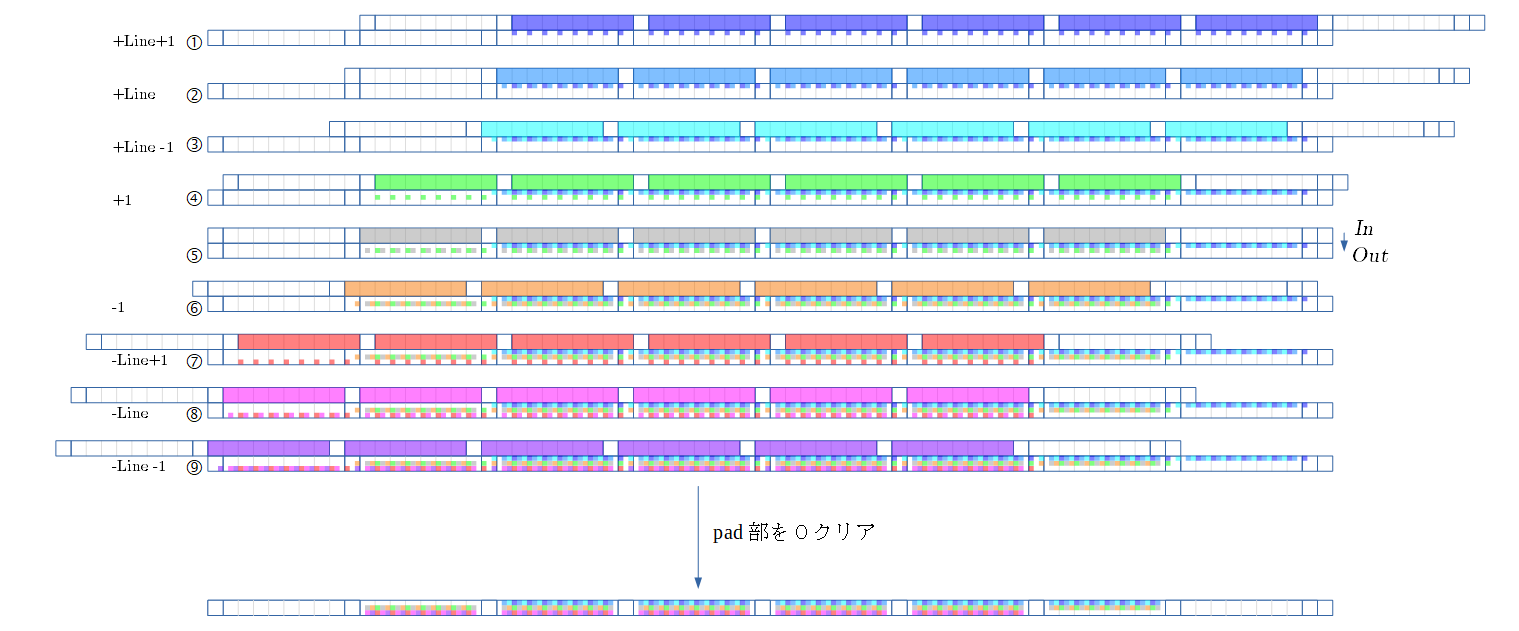
- 無効な部分はPad部に書かれ、Pad部を0クリアすると、有効値のみ残るのがミソです。(面白いと感じた所です)
- ⑨まで足しこんだ下行から、Pad部を0クリアし、シリアライズを解いたのが下図です。
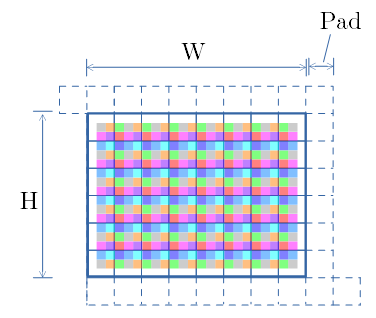
- 畳み込み処理の結果となります。
MCMK × MiniBatch での例
- パラメータと、画素のシリアライズ図を示します。

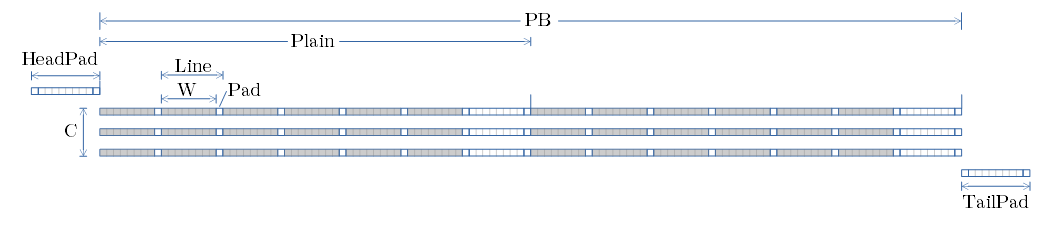
- 各行が、各チャンネル となります。
- 行内に、MiniBatch分の画素が並びます。
- 上図では、チャンネル数3、MiniBatchサイズ2の例です。
-
演算の流れを示します。
-
要素を下図に示します。
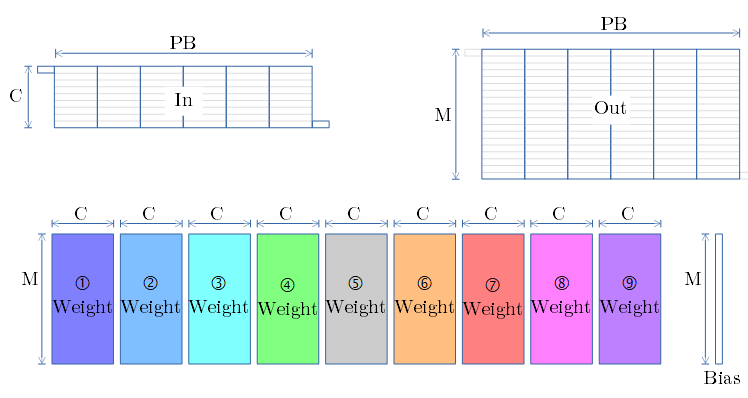
-
Bias値を Out にブロードキャストします。
-
SCSK の例で示した様に、In と Out をずらしながら、①〜⑨の重み で行列演算を行います(下図)
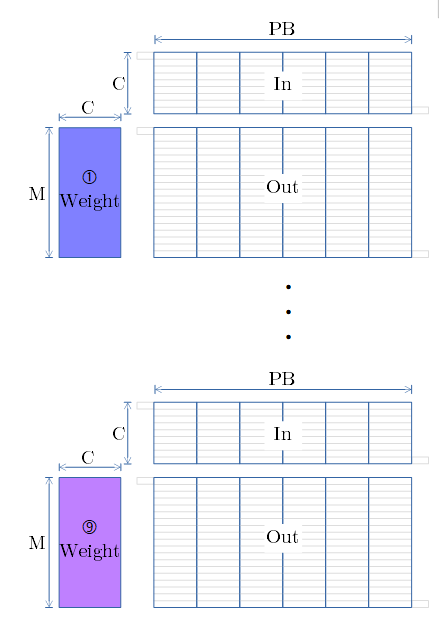
- ⑨の行列演算まで 足しこんだOut は 畳み込み処理の結果となります。
- 行列演算は BLAS の GEMM 関数がお勧めです。
逆伝播
- 逆伝播での流れを示します。
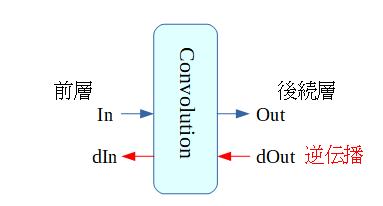
- 画素の傾きdIn , Weightの傾きdW , Biasの傾き dB を順に図解します。
逆伝播 dIn
- $dIn = Weight^T × dOut$
SCSK での例
- 順伝播の畳み込みとの違いは、上行がdOut(逆伝播での入力値)、下側がdIn(逆伝播での出力値) であることです。
- 他に違いはなく、順伝播と同様にズラしながら ①〜⑨ を足し合わせます。
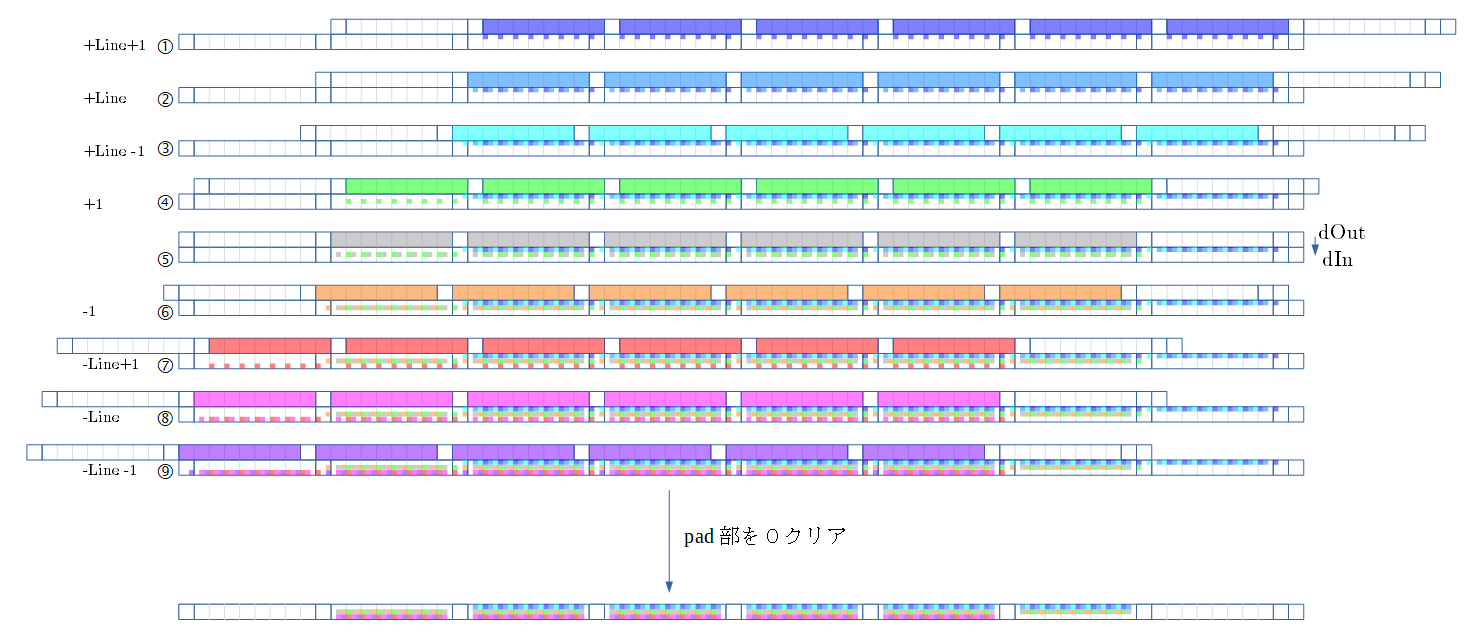
- ①〜⑨ を足し合わせた結果は、dIn となります。
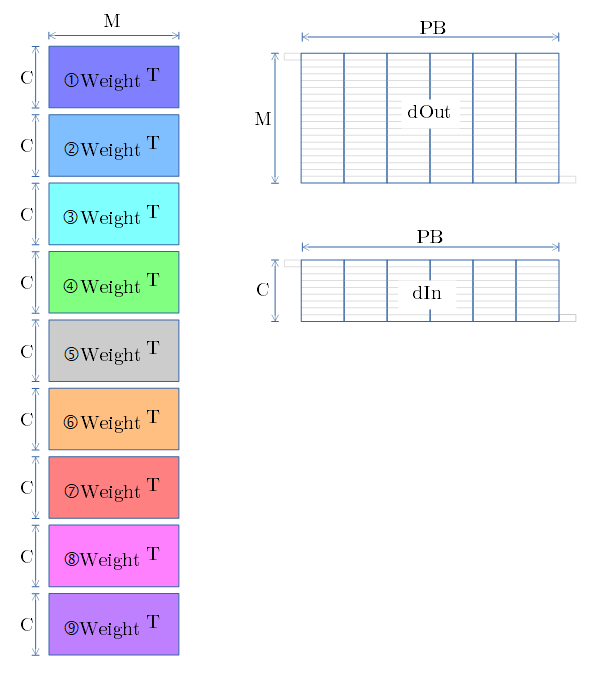
MCMK + MiniBatch での例
- 順伝播と同様に、画素配置(各行がチャンネル、行内にminiBatch分の画素を内包)へ 変換します。
- 要素を下図に示します。
- Tは転置を示します。
- SCSK の例で示した様に、dOut と dIn をずらしながら、①〜⑨の重み で行列演算を行います(下図)。
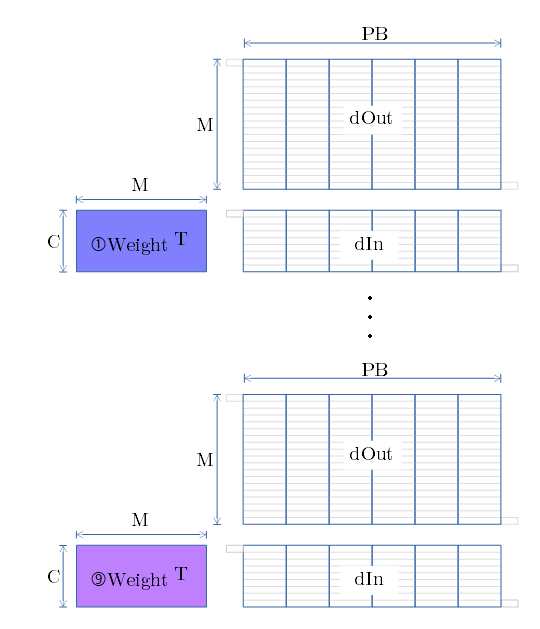
- ⑨の行列演算まで 足しこんだ結果が dIn になります。
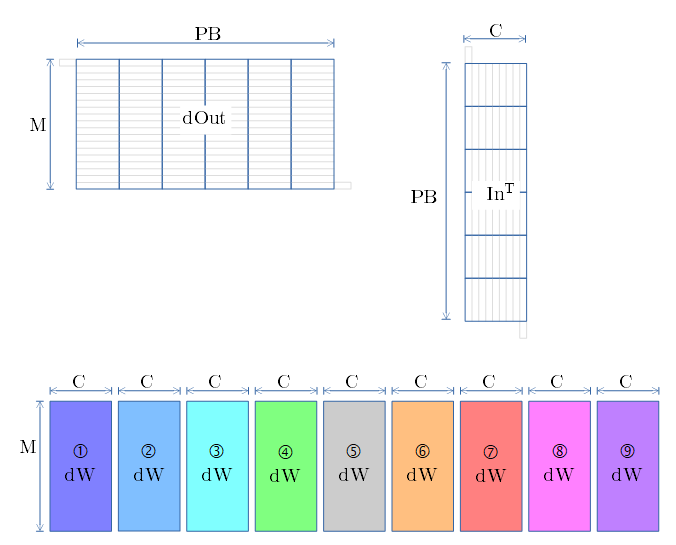
逆伝播 dW
- $dW = In^T × dOut$
SCSK での例
- 下図の①〜⑨は、フィルタの①〜⑨の傾き(dW) を求める処理に対応します。
- ①の、ずらした3行は、上行は In、中行は dOut 、下行は dW の算出過程値 を示します。
- 上行(In) と 中行(dOut) を掛けた値を、下行に格納します。
- pad部は0。padと掛けわせる所は0に。 → 順伝播で有効だった箇所のみ下行で有効値に。
- ①では、上行と中行のズレ量は Line+1 です。
- 下行①の総和が、 ①のdW になります。
- ②は、上行と中行のズレ量を Line にします。
以下③〜⑨を、ズレ量を変えながら、dwを算出していきます。

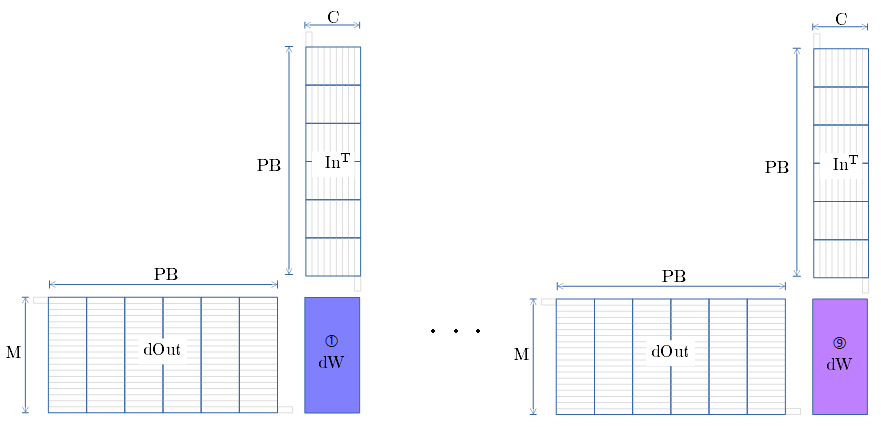
MCMK + MiniBatch での例
-
要素を下図に示します。
-
SCSKの例で示したように、①~⑨を、Inと dOut をズラしながら 行列積で dW を算出します。
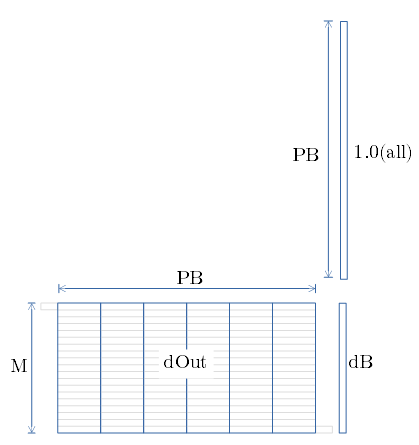
逆伝播 dB
- dB は Channel 毎の dOut の総和です。
- BLASの gemv 関数を用いて、行毎の総和を算出します。
Im2Col 方式と比べての特徴
- Im2Col方式については Convolution処理の手法 Im2Col方式の図解 に記載しました。
メリット
- Im2Col 方式では、Workメモリに、画像の9倍(3x3フィルターの場合)のメモリを要します。
- それに比べると、本方式は使用メモリは少なく済みます。
デメリット
- 1以外のストライドの時の所要時間。
- 本方式だと、計算後に間引く方法しか思い浮かんでないです...。
評価
処理速度評価。cudnn との比較
測定モデル
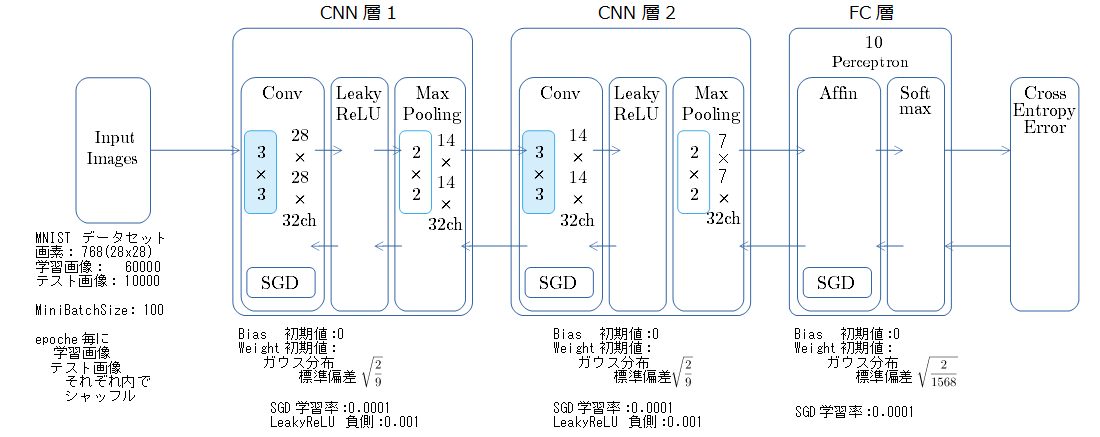
比較対象
| 識別名 | 補足 |
|---|---|
| OpenBLAS | K2Image 方式をopenBLAS ライブラリを用いて実装での測定結果。openBLASはCPU上にてマルチスレッドで行列演算を行う。 |
| cuBLAS | K2Image 方式をcuBLAS ライブラリを用いて実装での測定結果。cuBLASはGPUを用いて行列演算を行う。 |
| cudnn | cudnn で提供される convolution向け関数を用いての測定結果。 |
- convolution 処理以外は、全てCPUで演算させている。
測定環境
| 項目 | 内容 |
|---|---|
| CPU | Intel(R) Core(TM) i7 CPU 920 @ 2.67GHz |
| M/B | GIGABYTE EX58-DS4 |
| メモリ | 12GB |
| グラフィックカード | 玄人志向 GF-GTX1050Ti-4GB/OC/SF |
| OS | Ubuntu 16.04 |
| グラフィックドライバ | nvidia-375 |
| CUDA | 8.0.61-1 |
| openBLAS | 0.2.18-1ubuntu1 |
| コンパイラ | gcc Ubuntu 5.4.0-6ubuntu1~16.04.4 |
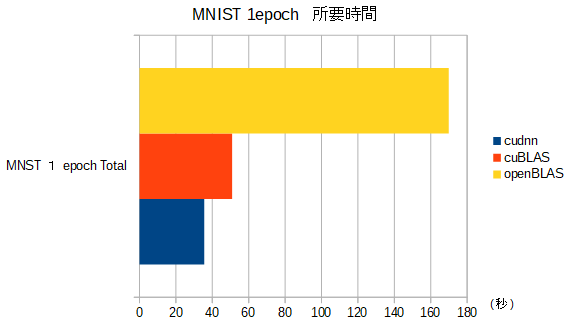
MNIST 1 Epoch の所要時間での比較
- convolution 以外の処理も含めての、モデルとしての処理時間比較です。
- グラフは左側(短い)方が 速く 良い。 伸びるほど遅く、好ましくない。

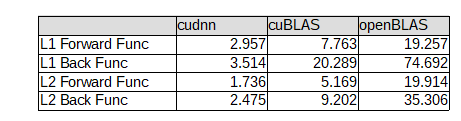
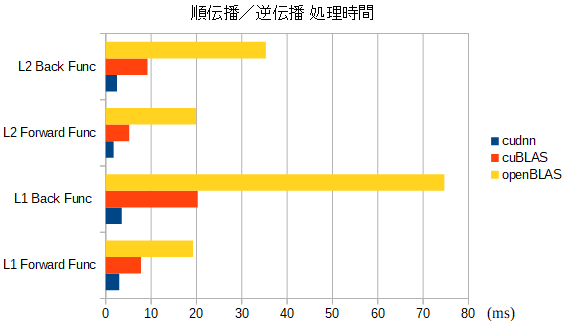
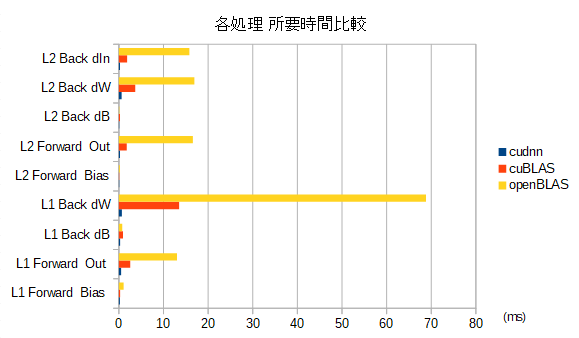
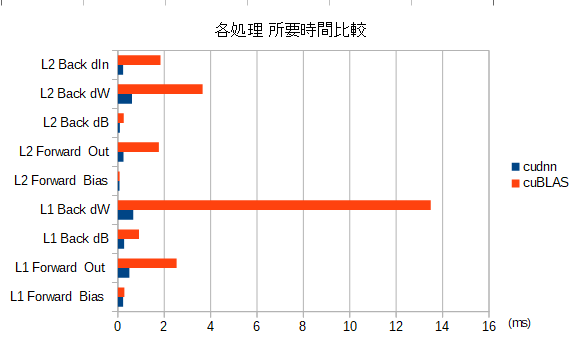
Convolution 処理 順伝播/逆伝播の 所要時間 の比較
- convolution 処理として必要な処理(画素配置変換、メモリコピー、等)を含めての比較
- cuBLAS と cuDNN での 比較グラフ
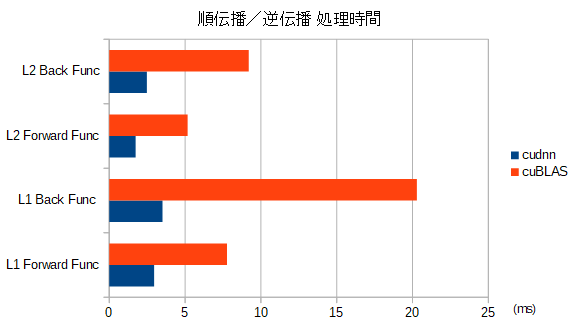
行列演算関数 の 所要時間 の比較
BLAS または cudnn 関数での 所要時間の比較
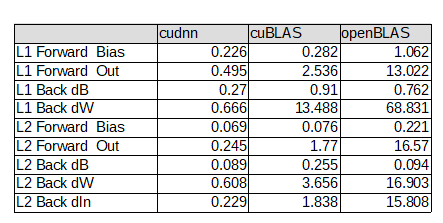
- dW の差が目立ちますね...。
- $In^T$ と $dOut$ の 9回分の行列積の 所要時間として要してるのは分かるのですが...
- cudnnが速すぎ...。
- cuBLAS の dw の演算では、gemmbatch()を用いて、1関数呼び出しで 9回分の行列演算を行ってます。
- gemm()関数を 9回呼ぶよりは、gemmbatch()を用いる方が 3倍以上速かったです。
感想
- Convolution 処理の沼は深い...。好きだけど無限に時間を吸われる...。
- cudnn すげぇ...。
ここまで読んで頂き ありがとうございました。