Webサイトをクロール(スクレイピング)してtitleやdescription、h1タグを収集してExcel(or CSV)にまとめる方法を調べたので記事として残します。
Webサービスのコンテンツやページが増えてくるとページ1つ1つのtitleタグやmetaタグのdescriptionをチェックするのが困難になります。
例えば、バグで、あるページのh1タグが出力されなくなっていても気付くことが難しくなります。
本記事の手順でCSVを出力しバージョン管理しておくことで、SEOテキストに関係する処理を修正した後に差分を確認し、デグレや意図しない変更が発生していないかをチェックできるようになります。
Site Audit SEO を使用します
site-audit-seoというNode製のツールでWebサービスをクロールして各種SEOテキストを収集する事ができます。
インストール方法は上記リポジトリのREADMEをご参照ください。(npmが必要です)
クロールを行います
以下のコマンドでクロールを行います。
ここでは、ipaのページを最大10ページまでクロールしています。
site-audit-seo -m 10 -p parse --xlsx --out-dir . --out-name seo-texts -u https://www.ipa.go.jp/ \
-f 'robots=$("meta[name=robots]").attr("content")' \
-f 'canonical=$("link[rel=canonical]").attr("href")' \
-f 'twitter_title=$("meta[name=\"twitter:title\"]").attr("content")' \
-f 'twitter_description=$("meta[name=\"twitter:description\"]").attr("content")' \
-f 'twitter_image=$("meta[name=\"twitter:image\"]").attr("content")' \
-f 'og_title=$("meta[property=\"og:title\"]").attr("content")' \
-f 'og_description=$("meta[property=\"og:description\"]").attr("content")' \
-f 'og_image=$("meta[property=\"og:image\"]").attr("content")'
各オプションについて
| オプション | 説明 |
|---|---|
| -m 10 | max-requestsの略で、ページをスキャンする回数を最大10回に制限しています |
| -p parse | presetの略で、収集するフィールドのセットを指定できます。parseの場合はurl, title, h1, description, keywordを収集します。 |
| --xlsx | 処理結果をxlsxで出力します |
| --out-dir . | 処理結果を出力するフォルダを指定します。今回はカレントディレクトリを指定しています |
| --out-name seo-texts | 出力結果のファイル名を指定します。今回はseo-texts.xlsxになります |
| -u <URL> | クロールの始点となるURLを指定します |
| -f '列名=処理' | 追加で収集するフィールドを指定します。左辺に列名を指定し、右辺に値を収集する処理を指定します。処理はjQuery(?)が使えるようです |
その他のオプションについてはsite-audit-seo --helpで確認してください。
処理結果を確認する
処理が終了するとコマンドを実行したディレクトリにseo-texts.xlsxというファイルが出力されています。
この中に、収集したテキストが記載されています。
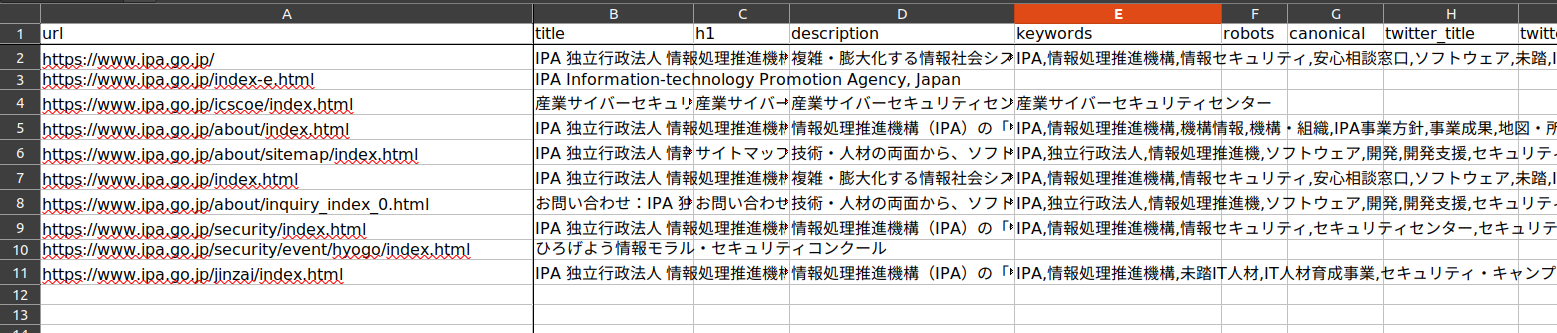
Web Viewで結果を確認する
本記事では使用しませんが、処理結果をブラウザで確認する仕組みも用意されています。
クロールが完了すると、以下のようにコマンドが終了せず、待機状態になると思います。
これは内部的にサーバーが立ち上がっている状態です。
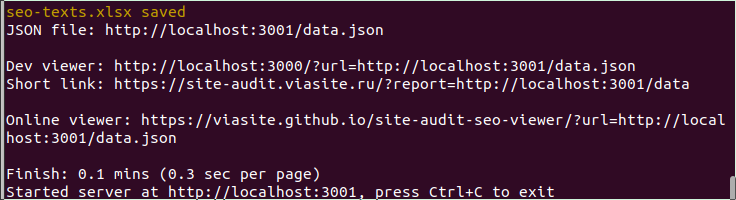
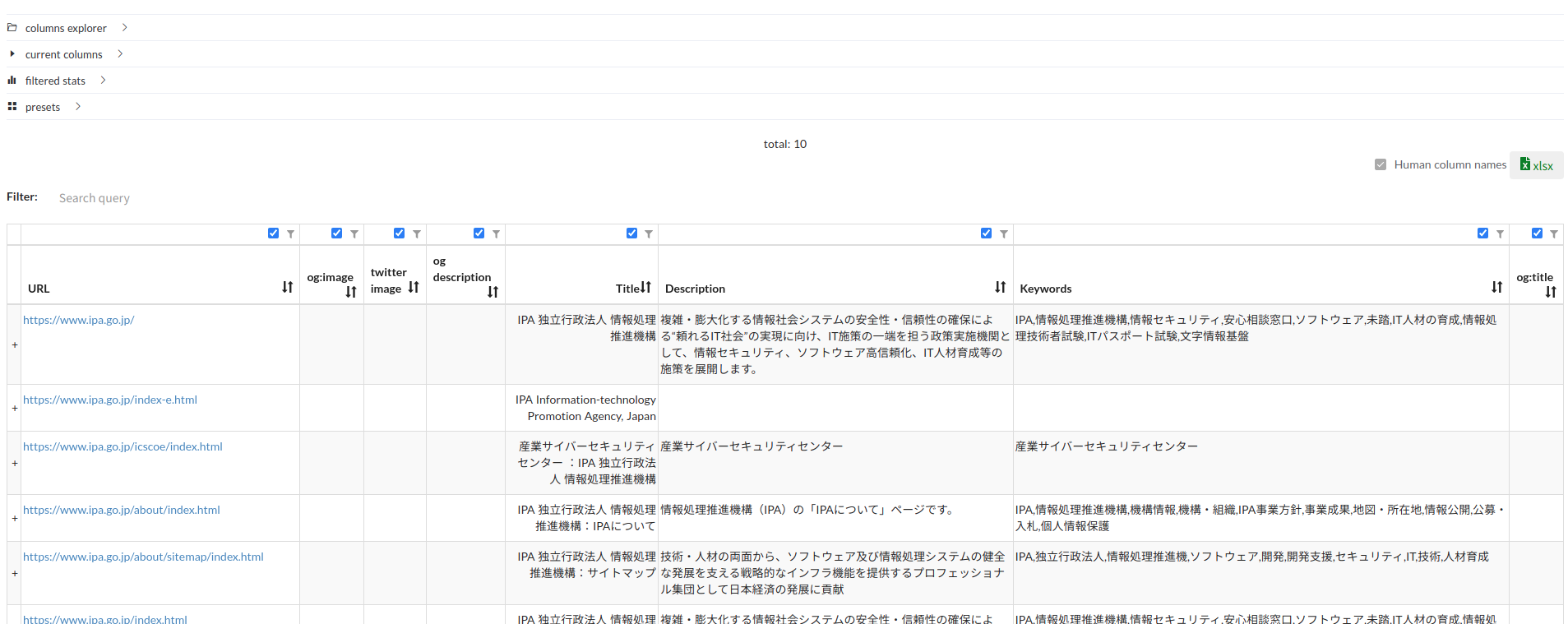
Online viewerの右のURLをクリックするとViewerが立ち上がり、ローカルサーバからデータを読み込んで可視化してくれます。
ローカルサーバを停止するにはCtrl+Cを押下します。
差分を把握する
上記のxlsxファイルをURL列の昇順でソートし、CSVにエクスポートしてgitで管理しておけば差分が閲覧でき、便利かと思います。
本記事は以上です。
余談
SEO関連のツールについて調べようとすると、検索結果にSEO業者の有料サービスへ誘導する記事ばかり表示されるのが辛い所ですね