自然言語処理界隈で、BERTが話題ですね。
私は理論的なことに明るくないので、その辺の説明は他の人に任せて
まずはとにかく動かしてみようと思います。
ぶっちゃけ、GithubのREADME読めば動かし方は分かるんですが、
英語めんどいって人とかはまぁ↓読んでみてください。
やること
実力を確かめたいので、BERT論文中で解いているタスクであるGLUEタスク群のうち、
QQP(Quora Question Pairs)というお題で、実際にスコアを出してみたいと思います。
このQQPというタスク、実は1年くらい前にKaggleのコンペにもなっていました。
(BERT論文の対象タスクであるGLUE benchmarkのタスクと、どっちが先かはよく知らない)
確かに、データの中身を見るとKaggleで使われているtrainと同じようです。
GLUEタスクの方では、trainからvalidateを固定で分割している、くらい。
testセットも、多分使っているデータは同じだけど、GLUEの方が量が少なくて、Kaggleの1/10くらい。
Kaggleは過去のコンペでもSubmitしてスコアを出せる(当然、順位には影響しません)ので
BERTで試したモデルがKaggleでどのくらいスコアが出るのかも見ることができます。
これもやってみます。
準備
-
12GB以上のメモリを搭載したGPU環境、もしくはTPUが使える環境を用意
- メモリ12GB未満のGPU(GTX1080とか)だと、少なくともデフォルト設定(論文の設定)ではOOMで落ちます。私は1080Tiで動かしました。
- 最近はColaboratoryでTPUが無料で使えるらしいので、素直にそれを利用した方が良いと思います。
- OOMについてはissueとしても取り上げられています。今対応を検討中だそうですが、まだ実装できてないとのこと。
-
Python環境を用意して、tensorflow 1.11.0をインストール
-
BERTのソースコードをGoogleのGithubリポジトリからclone
-
同リポジトリのREADMEに記載されている、BERTの事前学習モデルをダウンロード
- 英語モデルに関しては、以下の4つがありますが、とりあえず動かしたいだけなら
BERT-Base Uncasedを使えば良いと思います。- BERT-Base, Uncased: 12-layer, 768-hidden, 12-heads, 110M parameters
- BERT-Large, Uncased: 24-layer, 1024-hidden, 16-heads, 340M parameters
- BERT-Base, Cased: 12-layer, 768-hidden, 12-heads , 110M parameters
- BERT-Large, Cased: 24-layer, 1024-hidden, 16-heads, 340M parameters
-
Uncasedってのは、前処理として英単語をすべて小文字化(lowercased)しているモデルです。 -
Multilingualってモデルもあって、日本語も対応しているのですが、Unicode正規化の影響で濁点が除去されたりしているようです。
この辺を試している方もいるので、BERTの日本語の扱いに関してはそちらを参照ください。
- 英語モデルに関しては、以下の4つがありますが、とりあえず動かしたいだけなら
ソースコードについて
run_*.py となっているスクリプトが、実行用のスクリプトです。
QQPタスクは「2つの質問文が意味的に等価かどうかを判定」する分類問題なので、 run_classifier.py を使います。
使うスクリプトはこれだけ。
他にも事前学習モデルを独自で作成したい場合に run_pretraining.py を使うと思うのですが、
Googleの事前学習モデルを使う場合には不要です。
事前学習モデルを日本語で作っている方もいるので、それはこちらを参照。
(参照ばかりでリンク集みたいになってきた...)
タスクに合わせてスクリプトを修正
QQPをBERTで動かす前には、ちょっと run_classifier.py をいじる必要があります。
READMEの記載から、run_classifier.py の実行方法はすぐに想像がつくのですが
export BERT_BASE_DIR=/path/to/bert/uncased_L-12_H-768_A-12
export GLUE_DIR=/path/to/glue
python run_classifier.py \
--task_name=MRPC \
--do_train=true \
--do_eval=true \
--data_dir=$GLUE_DIR/MRPC \
--vocab_file=$BERT_BASE_DIR/vocab.txt \
--bert_config_file=$BERT_BASE_DIR/bert_config.json \
--init_checkpoint=$BERT_BASE_DIR/bert_model.ckpt \
--max_seq_length=128 \
--train_batch_size=32 \
--learning_rate=2e-5 \
--num_train_epochs=3.0 \
--output_dir=/tmp/mrpc_output/
の、--task_nameにタスク名を指定すれば、なんか動いてくれそうな予感がしますよね。
でも、ソースの中身を見てみると、この --task_name にQQPという選択肢はありません。
この --task_name はどう使われているかというと
task_name = FLAGS.task_name.lower()
if task_name not in processors:
raise ValueError("Task not found: %s" % (task_name))
で読み込まれていて、じゃあ processors はというと
processors = {
"cola": ColaProcessor,
"mnli": MnliProcessor,
"mrpc": MrpcProcessor,
"xnli": XnliProcessor,
}
と定義されています。このdictに "qqp": QqpProcessor という要素を足せば良い、ということです。
もちろん QqpProcessor 自体も定義してあげないといけないのですが、
ほとんどMrpcProcessorをパクって、以下のようにすればOKです。
(余計なifとかtryが入っていますが、これはkaggleデータを読み込む時に出るエラー対処などです。悪しからず...)
class QqpProcessor(DataProcessor):
"""Processor for the QQP data set (GLUE version)."""
def get_train_examples(self, data_dir):
"""See base class."""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "train.tsv")), "train")
def get_dev_examples(self, data_dir):
"""See base class."""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "dev.tsv")), "dev")
def get_test_examples(self, data_dir):
"""See base class."""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "test.tsv")), "test")
def get_labels(self):
"""See base class."""
return ["0", "1"]
def _create_examples(self, lines, set_type):
"""Creates examples for the training and dev sets."""
examples = []
for (i, line) in enumerate(lines):
if i == 0:
continue
guid = "%s-%s" % (set_type, i)
try:
if set_type == "test":
text_a = tokenization.convert_to_unicode(line[1])
text_b = tokenization.convert_to_unicode(line[2])
label = "0"
else:
text_a = tokenization.convert_to_unicode(line[3])
text_b = tokenization.convert_to_unicode(line[4])
label = tokenization.convert_to_unicode(line[5])
except IndexError as e:
sys.stderr.write('Index Error: {} {}\n'.format(i, line))
if set_type == 'test':
text_a = tokenization.convert_to_unicode('Why does qqp include invalid data?')
text_b = tokenization.convert_to_unicode('Why does qqp include invalid data?')
label = '0'
else:
examples.append(
InputExample(guid=guid, text_a=text_a, text_b=text_b, label=label))
return examples
これだけ修正してあげれば、とりあえず事前学習モデルでBERTを動かせます。
GLUEにSubmit
まずはfine tuning
論文中のGLUEデータは、別リポジトリにあるdownload_glue_data.pyを使って落とせます。
これを実行すると、実行ディレクトリ配下の glue_data/QQP ディレクトリにデータが格納されます。
glue_data/QQP/
├── dev.tsv
├── original
│ └── quora_duplicate_questions.tsv
├── test.tsv
└── train.tsv
あとは以下のようにしてBERTのfine tuningを走らせます。
export BERT_BASE_DIR=/path/to/bert/uncased_L-12_H-768_A-12
export GLUE_DIR=/path/to/glue_data
python run_classifier.py \
--task_name=QQP \
--do_train=true \
--do_eval=true \
--data_dir=$GLUE_DIR/QQP \
--vocab_file=$BERT_BASE_DIR/vocab.txt \
--bert_config_file=$BERT_BASE_DIR/bert_config.json \
--init_checkpoint=$BERT_BASE_DIR/bert_model.ckpt \
--max_seq_length=128 \
--train_batch_size=32 \
--learning_rate=2e-5 \
--num_train_epochs=3.0 \
--output_dir=/tmp/qqp_output/
GTX1080Tiで、大体3時間くらいでした。
次にtestデータのpredict
testデータのpredictは以下のように実行できます。
export BERT_BASE_DIR=/path/to/bert/uncased_L-12_H-768_A-12
export GLUE_DIR=/path/to/glue
export TRAINED_CLASSIFIER=/tmp/qqp_output/ # fine tuning時に--output-dirで指定したディレクトリでOK。中にモデルができている。
python run_classifier.py \
--task_name=QQP \
--do_predict=true \
--data_dir=$GLUE_DIR/QQP \
--vocab_file=$BERT_BASE_DIR/vocab.txt \
--bert_config_file=$BERT_BASE_DIR/bert_config.json \
--init_checkpoint=$TRAINED_CLASSIFIER \
--max_seq_length=128 \
--output_dir=/tmp/qqp_output/
実行が終われば、ここで--output_dirに指定したディレクトリに test_results.tsv ができるはずです。
GLUE benchmarkにSubmit
test_results.tsv をGLUE benchmarkのサイトでSubmitしてみます。
Googleアカウントでログインして https://gluebenchmark.com/submit からSubmitできます。
が、GLUEっていうのは11個のタスクの集合体です。
他タスクの結果も格納したzipファイルをアップロードする必要があります。
せっかくなら、それらもBERTで作成したかったのですが、時間がなかったのでQQP.tsvだけ作って
あとはサンプルSubmitファイル(ここからダウンロードできる)をそのまま使ってアップロードしました。
結果は以下。(QQP以外は、サンプルSubmitのスコアになっています)
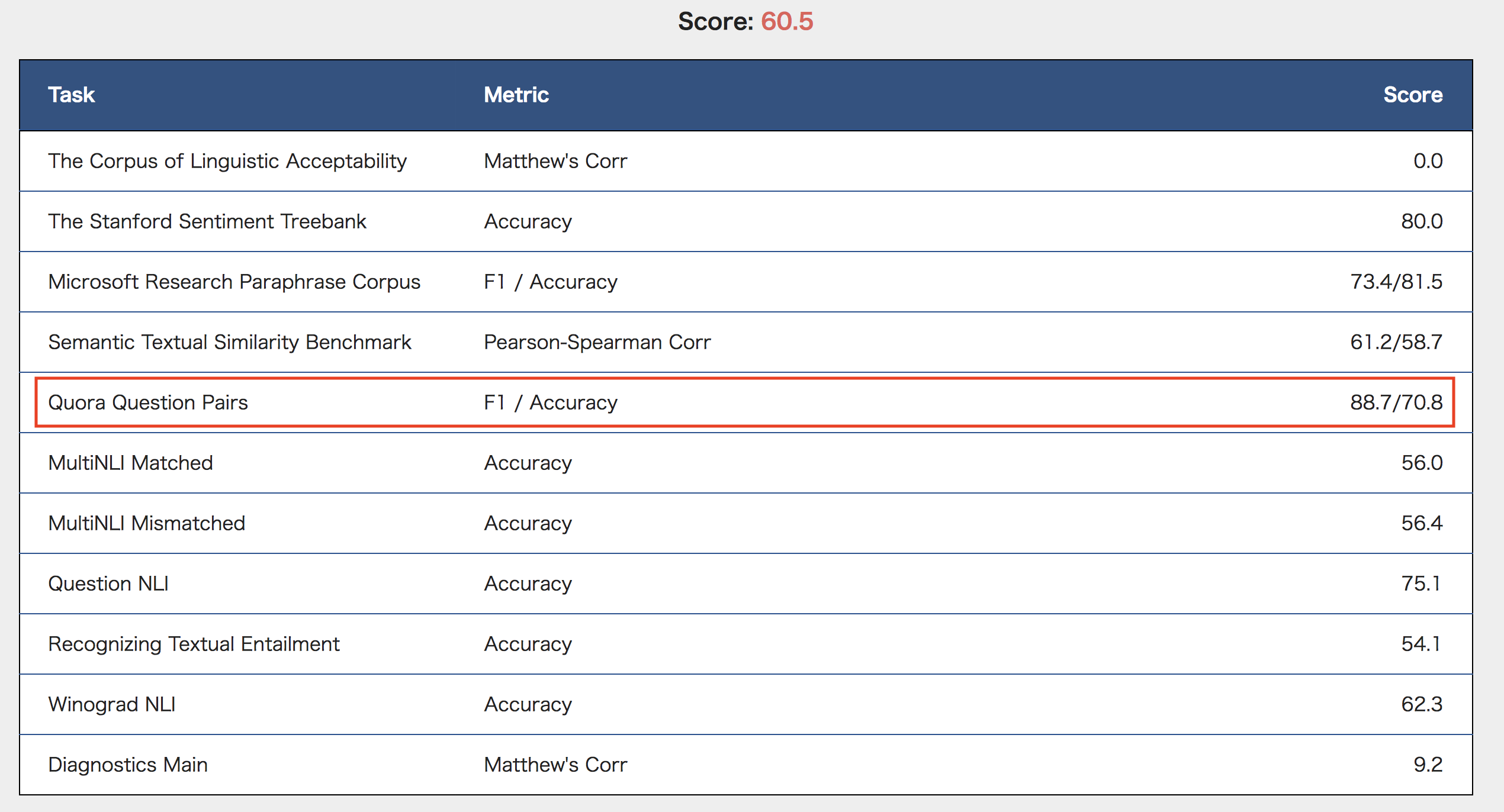
Googleの結果では、71.2/89.2(F1/Accuracy)なので、近い値が出ています。(バグなのかGLUE benchmarkのサイトでの表示はF1とAccuracyが逆になってますが...)
無事実行できていた、ということだと思います。
KaggleにSubmit
無事にBERTモデルができたということで、KaggleにもSubmitしてみます。
KaggleとGLUEとでは、testデータのフォーマットが異なるので、
- BERTスクリプトで動くように整形
- BERTスクリプトでpredict
- できた
test_result.tsvを再度Kaggleのフォーマットに整形
をしなければなりませんが割愛。
あと、Kaggleのtestデータ量はGLUEの10倍くらいあるので、predictにめっちゃ時間かかります。
QQPのKaggle Leaderboardはこんな感じになっています。

スコアはLoglossです。0.11〜で、ひしめき合っていますね。
では今回の結果はどうだったか...

0.38154 ... !!!
全然ダメやん。
※BERTがダメというわけではありません。私のタスクのあて方がダメなのです。(後述)
Kaggleでダメだった理由
なんでダメなんだろ。ダメにしても、もう少し良い結果なのかな、と思っていた。
一応、スクリプトの処理など見直してみたけど特に引っかかるものはなし。
そこで、今度はKaggleのkernelから適当なものを引っ張ってきてモデル作って
逆にそれをGLUEに投稿してみた。
使ったkernelは[ LB 0.18+ ] LSTM with GloVe and magic featuresというもの。(まるコピーです。ありがとうございました。)
このモデルではLogloss 0.18くらいだったようです。
共起している単語の頻度とったり、GloVeというEmbeddingを使ったり、らしい。
すると、こちらの結果は...

なるほど、Google本家のも含めてBERTより良いスコア出てますね。
QQP「だけ」なら、Kagglerの方が強かったわけです。
GLUEって
...さて、唐突かつ今更なのですが、GLUEって
The General Language Understanding Evaluation
なんですね。
あぁ...Generalって...そういうこと?
あらかじめ知っておけ、というか気づけ、という話なのですが
GLUEって11タスクを 汎用的に 解くことができるモデルを目指すもの、なんですね。きっと。
GLUEのpaperがあるのですが、Abstractに思いっきり書いていました。
it must be general: it must be able to process language in a way that is not exclusively
tailored to any one specific task or dataset.
つまり特定のタスクに特化したモデルを目指すものじゃないよ、と。
BERTは、それら様々なタスクで、より汎用的な言語モデルを獲得できたことで話題になったのでした。
だからKaggleで世界の猛者データサイエンティストたちが、コンペタスクのみに特化したモデルや前処理、試行錯誤しまくったものに
理論も分かってないタダのおっさんがちょっとGithubのスクリプトそのまま叩いたくらいで勝てるわけないだろ、と。
(いや、勝てるとは思ってなかったですよ、一応...)
Kagglerナメんなよ、と。
BERTもうちょい調べてから来いよ、と。
BERT試して感じたこと
最後はちょっと自分の無知ゆえ、打ちのめされた感じになってしまいましたが、とりあえず簡単に動かすことはできます、BERT。
今回はGLUEでやってみましたが、もちろんオリジナルのタスクに適用することもできると思います。
fine tuning自体はGPUでも数時間で出来るものもあるので、例えば自身で保有しているコーパスで事前学習モデル作成しておいて
タスクごとに短い時間、かつ少量のドメイン特化コーパスで良いモデルが得られるのであれば、それだけでもありがたいです。
また、有効な前処理とかも全然調べられていないので、その辺もまだまだ余地があると思います。
今回私がやったようにそのまま適用しただけでは、Kaggleで負けてしまいましたが
きっとアプローチを変えれば、もっと良いモデルができるのでしょう。
業務でNLPの分類を扱っているものもいくつかあるので、そちらでも試してみる価値はありそうです。
蛇足1
これを書いているときに気づいたのですが、GLUEの1位が、BERTを抜いてMicrosoftのモデルに変わったようです。
https://gluebenchmark.com/leaderboard

日進月歩ですねぇ(他人事)
蛇足2
これを書いているときに気づいたのですが、Kaggle Advent Calendar 2018の明日のネタが
@namakemono さんの「BERT出たので,過去問(Quora)で性能を調べてみます」のようで、まる被りしてしまいました。。
わざとじゃないです、本当。でも、なんかすみません。
私の内容は間違っていたり不足があったりするかもなので、明日拝見して勉強させていただきます!