記事へのリンク
本記事におけるお断り
本記事は筆者が自学自習のためにデータ取得から計算までを行ったものです。特定の団体や個人から許可許諾はとっていないため、もし内容に問題があるとお考えの場合にはご連絡いただければ幸いです。
また、タイトルにもある通り、単純に強い、上手いを判断するのが困難であるポーカーにおけるスキルの『推定』がやりたかったことです。
本記事を通じて少しでもポーカーに興味を持ってアミューズメントやオンラインでポーカーを始めたいと思う人が増えれば何よりです。
実行環境
今回環境はGoogle Colaboratoryにて実装しました。
Google Colaboratory
Googleが公開している無料で使えるハイスペックなJupyterNotebook実行環境です。
Googleアカウントを持っていれば誰でも使えます。
機械学習に使ってほしいっぽい感じで公開されていますが、今回の様に様々な用途で使えると思います。
ただ、連続実行時間に以下の制限が設けられています
- 連続で12時間
- ブラウザを90分操作しないとその時点でセッションが切れる
また、データの読み書きを今回はGoogleDriveで行ったのですが、設定が少々必要である事と、
同一フォルダに数万件のデータを格納すると処理が止まったり不安定になる(GoogleDrive側の問題?)という点にも今回少しつまづきました
実装の流れ
今回はこんな感じで実装を行いました
- 結果データが公開されているサイトにアクセスし、試合結果をスクレイピング
- スクレイピングしたデータを整形、日付順にソート
- ELOレーティングを計算
- TrueSkillを計算
- 結果を分析
スクレイピング
まずは結果を保存するために、GoogleDriveをマウントします。
以下のコードを実行すると、権限付与のためのGoogleログイン画面が表示され、最後に出てくるオーソリコードを入力すると、ドライブが実行環境にマウントされます
from google.colab import drive
drive.mount('/content/drive')
# Go to this URL in a browser: https://accounts.google.com/o/oauth2/auth?client_id=xxx
# Enter your authorization code:
# ··········
# Mounted at /content/drive
必要なライブラリをimport
今回はBeautifulSoupを使いスクレイピングします。
from urllib import request, parse
from bs4 import BeautifulSoup
import json
import pandas as pd
共通で使う関数を定義。
getRankResultの中身は取得先のデータ構造に応じて変更
def getRankResult(soup):
csvHead = []
csvAll = []
for idx,table in enumerate(soup.findAll("table", {"class":"table table-striped"})):
if idx == 0:
continue
rows = table.findAll("tr")
for row in rows:
csvRow = []
for cell in row.findAll(['th','td', 'a']):
if cell.name == 'th':
csvHead.append(cell.get_text())
elif cell.name == 'td':
csvRow.append(cell.get_text())
elif cell.name == 'a':
csvRow.append(cell.get("href").replace('/players/', ''))
csvAll.append(csvRow)
return csvAll
def saveCSV(var, comp_num):
df = pd.DataFrame(var, columns=['rank', 'name', 'uid', 'point'])
# 全行naの行を削除
df = df.dropna(how="all")
# rankを消してindexをrank扱いにする
df = df.drop('rank', axis=1)
df['comp_num'] = comp_num
df.to_csv('drive/My Drive/hogehoge/' + comp_num + '.csv')
メインの処理がこちらです。
今回はとあるURLに対して連番で試合のIDが振られているようなデータでした。
スクレイピングを行う際には処理を並列化するなどすると相手のサーバに負荷が必要以上にかかってしまいます。
for i in range(1,79999):
comp_num = str(i)
target_URL = 'http://hogehogexxxxxxxxxx/' + comp_num
try:
req = request.Request(target_URL)
res = request.urlopen(req)
body = res.read().decode('utf-8')
res.close()
soup = BeautifulSoup(body)
csvAll = getRankResult(soup)
saveCSV(csvAll, comp_num)
except:
# 飛び番があるため処理が止まらないようエスケープ
print(i)
continue
と、、、ここまで読んでお気づきの方もいらっしゃるかと思いますが、
このプログラムを実行すると1試合1ファイルとして保存されることになります。
そして、GoogleDriveで1フォルダに約8万件もデータを突っ込むとどうなるか、
超不安定になり、最悪処理が止まることや、対象のフォルダが開けなくなったり、ローカル同期とかしていた日には・・・
とろくな目にあいません。1回で実行する処理を分ける、フォルダを数千件で分ける、等色々考えられる回避策がありました
スクレイピングしたデータを整形、日付順にソート
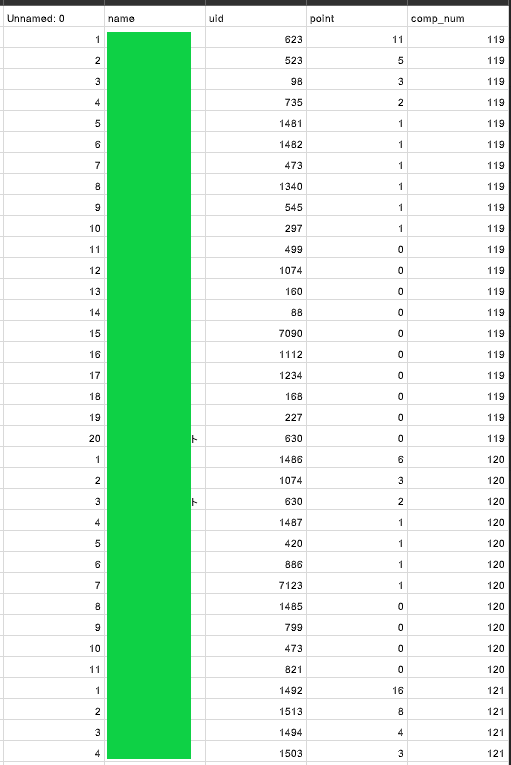
データを以下の様な形に整形します。
※少し長くなるためコードは一旦割愛
- indexとなる一番左の列が順位です(列名は付け忘れ。。。)
- nameはプレイヤーの名前です。実名ではなくポーカーネームというハンドルネームのようなものです。
- uidはプレイヤーを一意に特定するためのidです。
- pointはオリジナルデータに含まれる月間ランキング等の集計用の数値です。今回は使いません(複数店舗で運用ルールが異なったりするため)
- comp_numは試合を一意に特定するためのidです
このような形式で約8000試合分を1ファイルにまとめ、それを8ファイル作成しました
日付のデータは別で持っており、それに従ってcomp_numがソートされます
ELOレーティングを計算
一気に全データを計算しようとすると、前述の90分制限や12時間制限に引っかかりそう(前者はブラウザ自動リフレッシュとかでどうにかなるのかもしれないですが)
だったので、1000試合ごとに計算結果を出力し、途中から計算しなおせるようにしました。
uidをキーとしてELOレーティングの最新値を持つハッシュテーブルを作成しGoogleDriveに出力する事で実現しました。
from google.colab import drive
drive.mount('/content/drive')
import pandas as pd
import numpy as np
from tqdm import tqdm_notebook as tqdm
import datetime
import csv
import pickle
# 勝率計算
def calcOddsAvsB(A:int, B:int):
N = 400
odds = 1 / ((10 ** ((B - A) / N)) + 1)
return odds
# ELOレーティングの計算
def calcELO(A:int, B:int, isAwin:bool):
K = 8
odds = calcOddsAvsB(A, B)
if isAwin:
return K * (1 - odds)
else:
return K * odds * -1
# calcELO(1500,1700,True)
# 6.077975413183664
# 計算結果の格納
def saveDict(fpath:str, dic:dict):
with open(fpath,'wb') as f:
pickle.dump(dic, f)
def readDict(fpath:str):
with open(fpath, 'rb') as f:
dic = pickle.load(f)
return dic
df_all = pd.DataFrame()
for i in range(1,9):
df = pd.read_csv('drive/My Drive/compdata/allresult/' + str(i) + '.csv')
df_all = df_all.append(df)
# ここら辺は動けばよい、でちょっと雑なやり方
df_all = df_all.rename(columns={'Unnamed: 0': 'deltarget'})
df_all = df_all.rename(columns={'Unnamed: 0.1': 'rank'})
del df_all['deltarget']
# 途中から再開する場合
resumeNum = 34000
uidELOdic = readDict('drive/My Drive/compdata/calc/' + str(resumeNum) + '_dic.bin')
# comp_numの一覧を取得
df_target = pd.read_csv('drive/My Drive/compdata/all_sorted_by_date.csv')
# 一度に処理する数
execnum = 1000
for num in range(resumeNum + execnum, len(df_target), execnum):
if num + execnum <= len(df_target):
comps = df_target.compid[num:num+execnum]
else:
comps = df_target.compid[num:]
df_result = pd.DataFrame()
pbar = tqdm(total=len(comps))
for i in comps:
pbar.update(1)
df_comp = df_all[df_all.comp_num == i]
try:
# 初期値の設定
for idx, row in df_comp.iterrows():
if int(row.uid) in uidELOdic:
befELO = uidELOdic[int(row.uid)]
else:
befELO = 1500
uidELOdic[int(row.uid)] = befELO
df_comp.at[idx, 'befELO'] = befELO
df_comp.at[idx, 'diffELO'] = 0
df_comp.at[idx, 'aftELO'] = 0
# 全パターンの計算、itertool等使えばもっと楽に組み合わせ列挙出来る
for idx, row in df_comp.iterrows():
for idx_in, row_in in df_comp.iterrows():
if idx == idx_in:
continue
winflg = False
if idx_in > idx:
winflg = True
diffELO = calcELO(row.befELO, row_in.befELO, winflg)
df_comp.at[idx, 'diffELO'] += diffELO
# 最後に全部の計算結果を合算
df_comp.aftELO = df_comp.befELO + df_comp.diffELO
# 計算結果を保存
for idx, row in df_comp.iterrows():
uidELOdic[int(row.uid)] = row.aftELO
df_result = df_result.append(df_comp)
except:
import traceback
with open('drive/My Drive/compdata/calc/' + 'error' + str(i) + '.log', 'a') as f:
traceback.print_tb(traceback.format_exc(), file=f)
df_result.to_csv('drive/My Drive/compdata/calc/' + 'error' + str(i) + '.csv')
pbar.close()
pbar.close()
df_result.to_csv('drive/My Drive/compdata/calc/' + str(num) + '.csv')
saveDict('drive/My Drive/compdata/calc/' + str(num) + '_dic.bin', uidELOdic)
TrueSkillを計算
TrueSkillを一から自分で実装する事は激しくおすすめしません。
先人により各種言語のライブラリが公開されているのでおとなしくそちらを使いましょう。
まずはGoogleColaboratoryの実行環境にTrueSkillのライブラリをインストールします
!pip install trueskill
import trueskill
また、TrueSkillを利用する際には以下の流れで処理を行います
- 計算用のインスタンスを作成(パラメータを設定)
- プレイヤーを生成
- チームを組成 ←1vs1だろうが、チーム戦ではなかろうが絶対に組成が必要です
- (省略)重みづけの設定
- 変動後のレーティングを計算
計算用のインスタンスを生成
パラメータを設定し、計算用のインスタンスを生成します。
例によって理解しやすさ(と私の理解)優先で数学的にあっていない説明があるかもしれません。
- mu:正規分布のグラフの左右の位置の初期値。
- sigma:分散。データがどの程度散らばっているかの横幅の初期値。
- beta:上手い人から見た勝率75%であるプレイヤーがどの程度下のmuにまで存在するか。運の要素が強い競技はここを大きな値にする必要がある。
- tau:sigmaが収束に向かう様に補助される役割?がある値。正直ここはちゃんと理解してないまま計算しました。。。誰か教えてください
- draw_probability:引き分けになる確率
今回、パラメータはbetaを5倍に、drawを0にしました。
betaの5倍という数値は、約20名の試合があった時にトップとビリが約10%程度muが左右に変動する程度だったため採択しました。
ここの値をいくつにするのがポーカーにおいては妥当なのか?という問題に答えるためには何回か計算する必要があります。
mu = 25.
sigma = mu / 3.
beta = sigma / 2.
tau = sigma / 100.
draw_probability = 0.1
backend = None
# パラメータの調整
beta *= 5
draw_probability = 0
env = trueskill.TrueSkill(
mu=mu, sigma=sigma, beta=beta, tau=tau,
draw_probability=draw_probability, backend=backend)
試しに適当に計算すると以下のような結果となりました。
uid_trueskill_dict = {}
# 適当な試合を抽出
df_test = df_all[df_all.comp_num==119]
# レーティングの計算
players_comp = []
for idx, row in df_test.iterrows():
if int(row.uid) in uid_trueskill_dict:
# 必ずチームを組成する必要がある。チームはタプルかリストでプレイヤーをまとめたもの。今回は当然1人
players_comp.append((env.create_rating(uid_trueskill_dict[int(row.uid)][0], uid_trueskill_dict[int(row.uid)][1]),))
else:
uid_trueskill_dict[int(row.uid)] = [env.mu, env.sigma]
players_comp.append((env.create_rating(),))
players_comp = env.rate(players_comp)
# 計算結果の保存
i = 0
for idx, row in df_test.iterrows():
uid_trueskill_dict[int(row.uid)] = [players_comp[i][0].mu, players_comp[i][0].sigma]
i += 1
display(players_comp)
plt.figure(figsize=(10,5))
x = np.arange(-10., 50., 0.1)
for i in uid_trueskill_dict.values():
y = (1 / np.sqrt(2 * np.pi * i[1] ) ) * np.exp(-(x - i[0]) ** 2 / (2 * i[1]) )
plt.plot(x, y)
plt.grid() #グリット線
plt.show()
# 全チームの計算結果。muが25より増減、sigmaは一律現象している
[(trueskill.Rating(mu=30.781, sigma=7.905),),
(trueskill.Rating(mu=29.358, sigma=7.835),),
(trueskill.Rating(mu=28.501, sigma=7.813),),
(trueskill.Rating(mu=27.851, sigma=7.802),),
(trueskill.Rating(mu=27.307, sigma=7.795),),
(trueskill.Rating(mu=26.827, sigma=7.791),),
(trueskill.Rating(mu=26.388, sigma=7.788),),
(trueskill.Rating(mu=25.975, sigma=7.786),),
(trueskill.Rating(mu=25.579, sigma=7.785),),
(trueskill.Rating(mu=25.192, sigma=7.785),),
(trueskill.Rating(mu=24.808, sigma=7.785),),
(trueskill.Rating(mu=24.421, sigma=7.785),),
(trueskill.Rating(mu=24.025, sigma=7.786),),
(trueskill.Rating(mu=23.612, sigma=7.788),),
(trueskill.Rating(mu=23.173, sigma=7.791),),
(trueskill.Rating(mu=22.693, sigma=7.795),),
(trueskill.Rating(mu=22.149, sigma=7.802),),
(trueskill.Rating(mu=21.499, sigma=7.813),),
(trueskill.Rating(mu=20.642, sigma=7.835),),
(trueskill.Rating(mu=19.219, sigma=7.905),)]
全データの計算
# 記述済みの箇所等は省略
# 途中計算結果の読み込み
base_fpath = 'drive/My Drive/compdata/'
result_dir_name = 'calc_trueskill/'
resume_num = 0
if resume_num > 0:
uid_trueskill_dict = readDict(base_fpath + result_dir_name + str(resume_num) + '_dic.bin')
else:
uid_trueskill_dict = {}
df_target = pd.read_csv(base_fpath + 'all_sorted_by_date.csv')
exec_num = 1000
if resume_num == 0:
init_num = 0
else:
init_num = resume_num + exec_num
for num in range(init_num, len(df_target), exec_num):
if num + exec_num <= len(df_target):
comps = df_target.compid[num:num+exec_num]
else:
comps = df_target.compid[num:]
df_result = pd.DataFrame()
pbar = tqdm(total=len(comps))
for i in comps:
pbar.update(1)
df_comp = df_all[df_all.comp_num == i]
try:
# チームの組成
players_comp = []
for idx, row in df_comp.iterrows():
if int(row.uid) in uid_trueskill_dict:
mu_player_bef = uid_trueskill_dict[int(row.uid)][0]
sigma_player_bef = uid_trueskill_dict[int(row.uid)][1]
else:
mu_player_bef = env.mu
sigma_player_bef = env.sigma
uid_trueskill_dict[int(row.uid)] = [env.mu, env.sigma]
players_comp.append((env.create_rating(mu_player_bef, sigma_player_bef),))
df_comp.at[idx, 'bef_mu'] = mu_player_bef
df_comp.at[idx, 'bef_sigma'] = sigma_player_bef
# レーティングの計算
players_comp = env.rate(players_comp)
# 計算結果の保存
i = 0
for idx, row in df_comp.iterrows():
if int(row.uid) != 999999999:
mu_player_aft = players_comp[i][0].mu
sigma_player_aft = players_comp[i][0].sigma
else:
mu_player_aft = env.mu
sigma_player_aft = env.sigma
uid_trueskill_dict[int(row.uid)] = [mu_player_aft, sigma_player_aft]
i += 1
df_comp.at[idx, 'aft_mu'] = mu_player_aft
df_comp.at[idx, 'aft_sigma'] = sigma_player_aft
# 計算結果の格納
df_result = df_result.append(df_comp)
except:
import traceback
with open(base_fpath + result_dir_name + 'error' + str(i) + '.log', 'a') as f:
traceback.print_tb(traceback.format_exc(), file=f)
df_result.to_csv(base_fpath + result_dir_name + 'error' + str(i) + '.csv')
pbar.close()
pbar.close()
df_result.to_csv(base_fpath + result_dir_name + str(num) + '.csv')
saveDict(base_fpath + result_dir_name + str(num) + '_dic.bin', uid_trueskill_dict)
という感じで計算ができました。
速度はちゃんと測っていなかったのですが、組み合わせ列挙が不要であるTrueSkillの方が体感で数倍高速でした。
(TrueSkillは1000試合を約10分で計算)
結果を分析
次の記事で計算結果と、ランキングのデータも公開します!
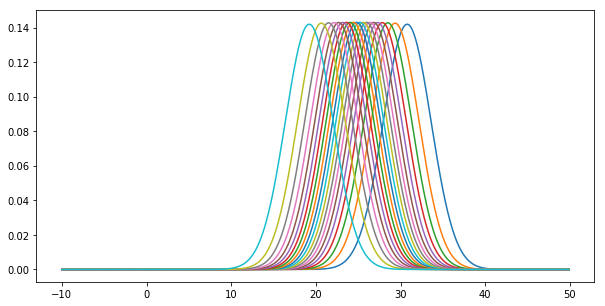
ちなみにTrueSkillの10000試合程度回したユーザごとのスキルです。
重なりがあってめちゃくちゃ見づらいですが、
山の高さ→その人のスキルがどの程度絞り込めているか?高いほど絞りこめている
左右の位置→その人のスキルの基本的な高さ。右に行けば行くほど強いひと
という風に良い感じに分布してそうです。

次の記事
次の記事では、計算結果からわかること、ELOレーティングとTrueSkillの違いを中心に記載したいと思います。