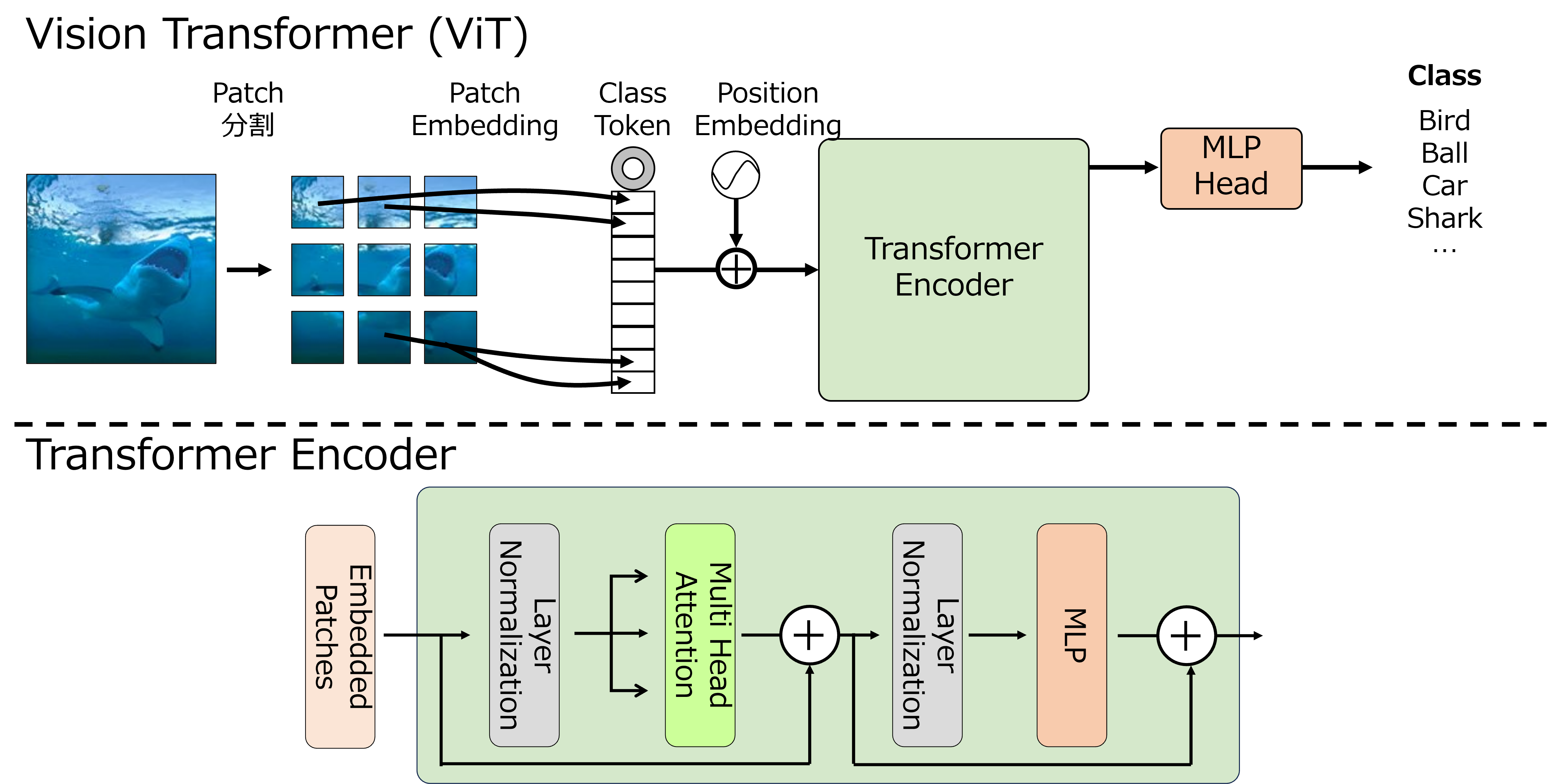
画像認識の分野においては,Convolutional Neural Network(CNN)が用いられてきた.しかし,近年では自然言語処理の分野で注目されているTransformerを画像認識に応用したVision Transformer(ViT)に基づく手法が優れた性能を発揮することが報告されている.
この記事ではViTの構造や特徴などをまとめる.
モデル構造
ViTの主な構造は以下の3つに分かれている.
- Input Layer:画像をトークンに変換
- Transformer Encoder:トークンからアテンションを計算し特徴を抽出
- MLP Head:Transformer Encoderで抽出した特徴を元に画像を分類
Input Layer
Input Layerでは,Patch分割,Patch Embedding,Position Embedding(Position Encoding)の3つの処理で構成される.
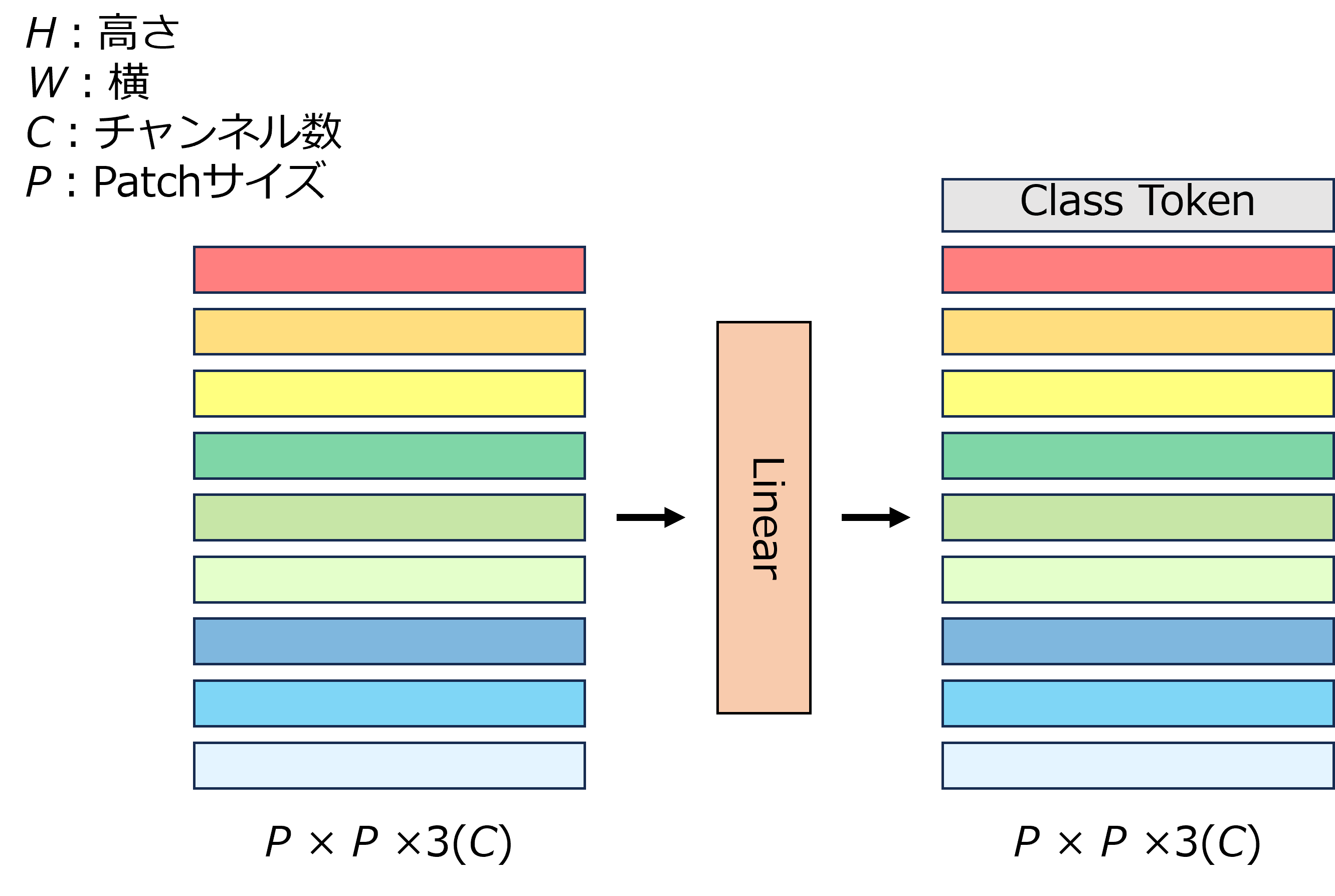
Patch分割
ViTは自然言語処理モデルであるTransformerを画像認識に応用した手法であるため,画像をそのまま入力することができない.そこで,ViTでは画像を$\mathbf{x}\in\mathbb{R}^{H\times W\times C}$だとすると画像をパッチに分割し,トークンとして扱う.そして,分割した各パッチを平坦化(Flatten)し$\mathbf{x}_p\in\mathbb{R}^{N\times (P^2\cdot C)}$という1次元のベクトルに変換する.
ここで$N$はパッチ数で,$P$はパッチサイズ(パッチは正方形であるため,$N$は$N=HW/P^2$)である.

Patch Embedding
変換したベクトルをLinear(全結合層)により埋め込みを行う.埋め込んだベクトルにClass Tokenである$\mathbf{x}_\text{class}$を結合する.Class Tokenは後述するTransformer Encoderで抽出した特徴量を集約しクラス分類を行うために利用される.
\mathbf{x}_p^N\mathbf{E} = [\mathbf{x}_{\text{class}};\ \mathbf{x}_p^1\mathbf{E};\ \mathbf{x}_p^2\mathbf{E};\ \cdots;\ \mathbf{x}_p^N\mathbf{E}]
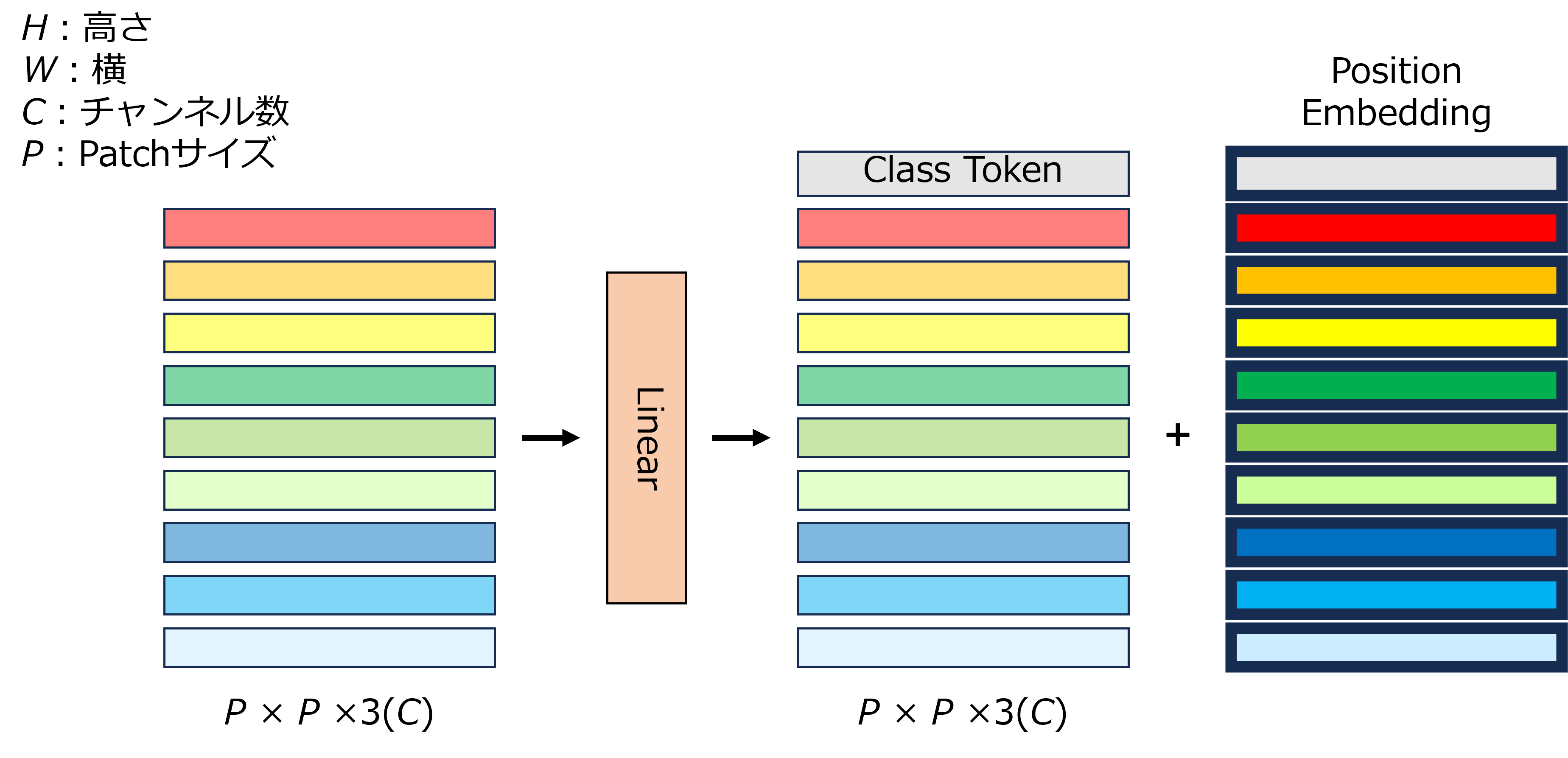
Position Embedding(Position Encoding)
Transformer EncoderのSelf-Attentionでは,位置情報を考慮せずに計算している.このままでは性能低下を引き起こすため,各トークンに位置情報である$\mathbf{E}_{pos}$を埋め込んでいる.
\mathbf{z}_0 = [\mathbf{x}_{\text{class}};\ \mathbf{x}_p^1\mathbf{E};\ \mathbf{x}_p^2\mathbf{E};\ \cdots;\ \mathbf{x}_p^N\mathbf{E}] + \mathbf{E}_{pos}
Transformer Encoder
Transformer EncoderはLayer Normlization,Multi-Head Self-Attention,MLPで構成される.ViTはTransformer Encoderを複数繰り返し特徴を抽出する.Transformer Encoderの数はViTのモデルサイズによって異なる.
Layer Normlization
Layer Normlizationは正規化手法の1つであり,そのデータ自身の平均と標準偏差で正規化を行う手法である.
一方で,Batch Normlizationはミニバッチ内のデータ全体の平均と標準偏差で正規化を行うため,バッチサイズが小さい場合や時系列データのように各データの長さが異なると精度が低下してしまう.
Multi-Head Self-Attention
Multi-Head Self-Attentionは,複数のヘッドでSelf-Attentionを計算し,各パッチ間のAttention(関連度)を求めることで特徴を抽出する機構である.
Self-Attention
Attentionは3つの異なる重みを持つLinear(全結合層)によって変換したベクトル$\textbf{Q}$(Query),$\textbf{K}$(Key),$\textbf{V}$(Value)を用いて計算する.
まず,$\textbf{Q}$(Query)と$\textbf{K}$(Key)の積にSoftmax関数を適用し,Attentionの重み(Attention Weight)を算出する.次に,Attention Weightに$\textbf{V}$(Value)を乗算することでAttentionを計算する.
つまり,画像の空間方向に特徴量を混ぜ合わせる処理が行われる.
\text {Attention}(\mathbf{Q},\mathbf{K},\mathbf{V}) = \mathrm{Softmax}\bigg(\frac{\mathbf{Q}\mathbf{K}^\mathrm{T}}{\sqrt{{d}_{k}}}\bigg)\mathbf{V}
ここで,$\sqrt{{d}_{k}}$は$\textbf{Q}$,$\textbf{K}$,$\textbf{V}$の次元数であり,$\textbf{Q}$と$\textbf{K}$の積が大きくなりすぎないようにするスケーリングや外れ値の影響を緩和する役割を担っている.

$\textbf{Q}$は,画像の各パッチが他のパッチとどの程度関連しているかを評価するための指標である.つまり,$\textbf{Q}$は,現在の要素が他の要素とどの程度関連しているかを示している.
$\textbf{K}$は,画像の各パッチが他のパッチからどの程度注目されるかを評価するための指標である.つまり,$\textbf{K}$は,他の要素がこの要素をどの程度重要視しているかを示している.
最後に,$\textbf{V}$は,実際の情報を持っているベクトルであり,最終的な出力を生成するために使用される.Attentionの重み付け計算によって決定された重要度に基づいて,これらの$\textbf{V}$が集約される.
Multi-Head Self-Attention
Multi-Head Self-Attentionは後述するSelf-Attentionを$h$個並列に行う.この時,並列に計算する数をヘッドと言い,ヘッドの数はViTのモデルサイズによって異なる.
Multi-Head Self-Attentionは下記のように計算される.
\mathrm{MultiHead}(z) = \mathrm{Concat}({head}_{1},{head}_{2},...,{head}_{h})W^{o}
{head}_{i} = \mathrm{Attention}(z{W}^{Q}_{i},z{W}^{K}_{i},z{W}^{V}_{i})
ここで,${}z$は入力,${}head_i$は${}h$個のAttention,${}W^o$はすべての${}head$に乗算する重み,
${}W^Q$,${}W^K$,${}W^V$はそれぞれ入力を$\textbf{Q}$,$\textbf{K}$,$\textbf{V}$に変換する重み行列である.
また,Concatは,各${}head$の値を1つに連結する操作を指す.
MLP
MLPはMulti Layer Perceptronの略称であり,Linear(全結合層),活性化関数,Dropoutで構成される.活性化関数には,GELUが用いられている.
MLPでは,Multi-Head Self-Attentionと異なり,トークンごとでチャンネル方向に混ぜ合わせる処理が行われる.
MLP Head
MLP HeadはLayer NormlizationとLinear(全結合層)で構成される分類器である.CNNの場合には全結合層や分類器と呼ばれる.MLP HeadではTransformer Encoderで抽出した特徴量を集約したClass Tokenを入力し,クラス分類を行う.Linear(全結合層)の出力次元数はクラス数に対応する.
まとめ
画像認識において近年スタンダードなモデルになったViTについて解説した.近年ではViTは知っている前提で話が進むことも多いので,知っておくといいかもしれません.
参考文献
論文:An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
LINK:https://arxiv.org/abs/2010.11929
timmのリポジトリ:https://github.com/huggingface/pytorch-image-models/tree/main
備考
timmというライブラリを使用することで簡単に学習済みのViTのFine-tuning可能です.
ここで実際にtimmを使用してViTでCIFAR-10 / 100を分類するコードを公開しています.