概要
Power Automate Desktop(以下PAD) の変数についての記事6回目「データテーブル型」です。PADのベース言語Robinのドキュメントを参考に試したものをまとめました。「変数の設定」アクションを中心に簡略化した例を挙げながら整理してみようと思います。コードはPADにコピペで試せます。
目次
注意
- すでに使いこなしているかた向けの記事ではありません。
- Robin言語はあくまでベースであるためPADと異なる部分があります。
- この記事の内容はすべて試していますが公式の見解とは異なる可能性がありますのでご注意ください。
- Power Automateクラウドフローの入出力変数については触れていません。
- 2021年2月の記事です。
- あくまでも個人のまとめです。
- 誤りがありましたらコメントでご指摘いただけると幸いです。
- Robinの公式サイトは2021年4月30日に終了しました。
追記
Power Automate for desktop「最初に知りたかったデータテーブルの扱い方」を書きました。応用編になりますがご興味あればご覧いただけれ幸いです。
データテーブル型変数について
データテーブル型変数は行と列からなる「データテーブル」を持ちます。データテーブルは2次元配列とも呼ばれ、行リスト(配列)が列方向に集合して構成されます。
データテーブル型変数はプロパティに行数、空判定、列名一覧、列数をもっています。

Excelデータやcsvを読み込んだときは最初の行を列名に設定するかしないかでプロパティが変化するので注意が必要です。
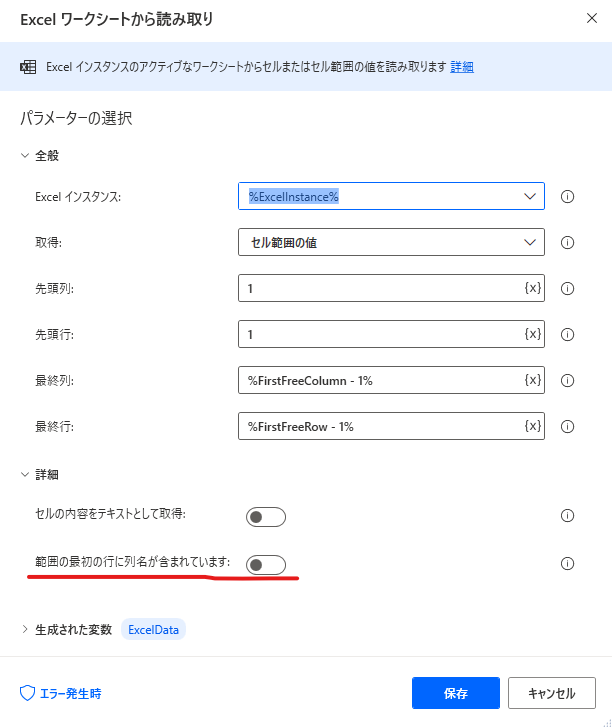
最初の行を列名に設定設定したとき
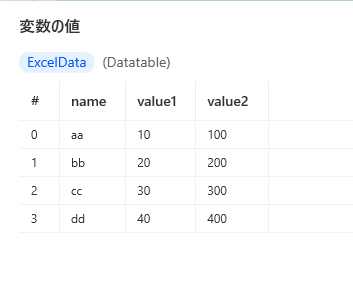
.RowCount = 4
.IsEmpty = False
.columns = ['name','value1','value2']
.columnCount = 3
最初の行を列名に設定しないとき
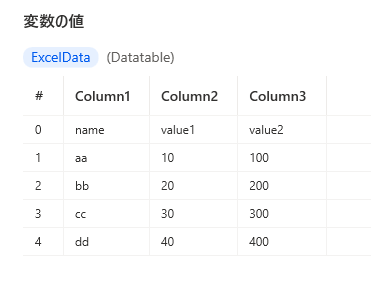
.RowCount = 5
.IsEmpty = False
.columns = ['Colmn1','Colmn2','Colmn3']
.columnCount = 3
またデータテーブルは0ベースのインデックス番号を持っています。
値は%テーブル名[行インデックス][列インデックス]%または%テーブル名[行インデックス][列名]%でアクセスできます。
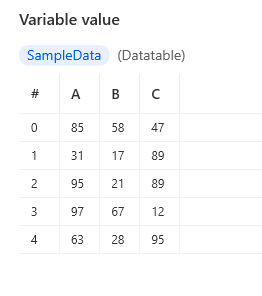
SampleData[1][0] =31
SampleData[1]['B'] = 17
データテーブルを「変数の設定」アクションから作成する
ここではExcelデータを使わずに「変数の設定」アクションからデータテーブルを作成します。
-
列名のリストをつくります
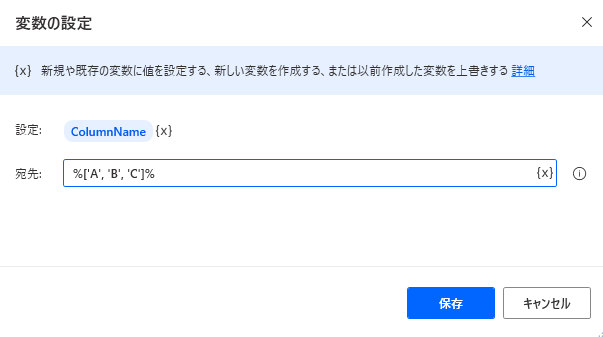
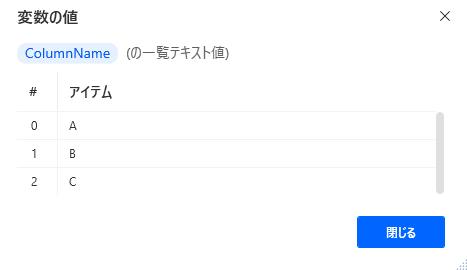
-
リストを2つ作成します。
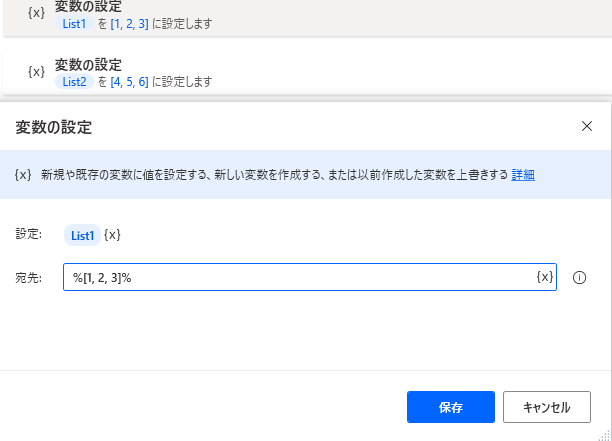
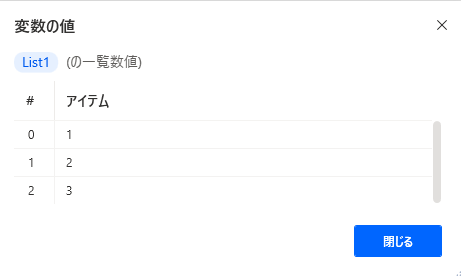
-
列名のリストを列名に変換します。
ハット^をつけて波括弧{}で囲います。リストを波括弧で囲うとデータテーブルに変換されます。ハット^をつけると列名に変換されます。
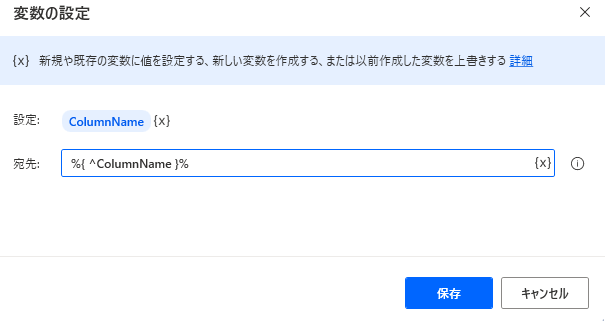
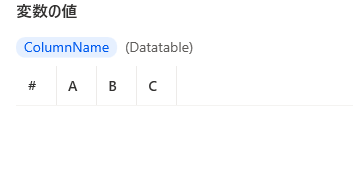
4. 結合します。データテーブルへリストの結合は同じ項目数でないとできません。
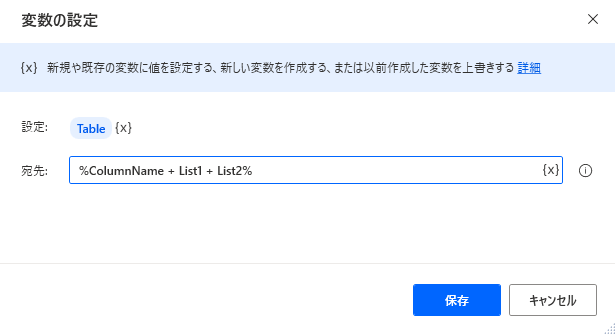
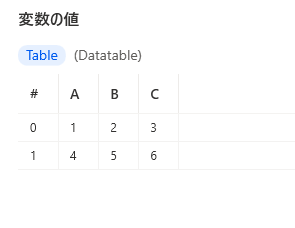
結合で作成されたデータテーブル型変数はプロパティを持たないので注意が必要です。
1アクションで書く場合は次のようになります。
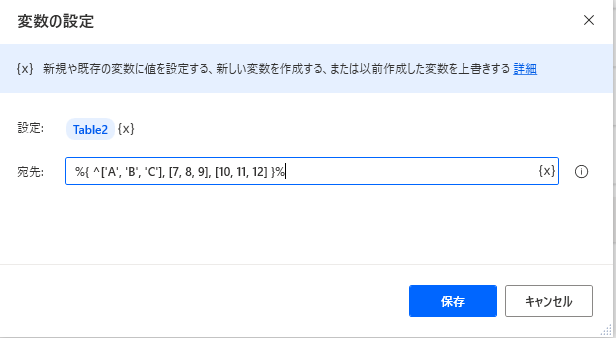
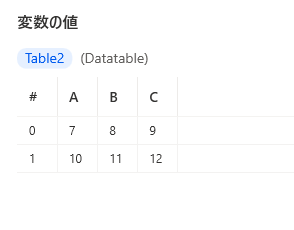
1アクションで作成されたデータテーブル型変数はプロパティを持っています。
DataRow
テーブルデータから行をインデックス番号で指定してするとDataRow型として変数に代入できます。
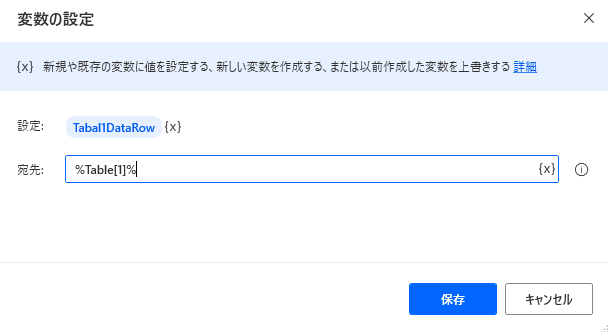
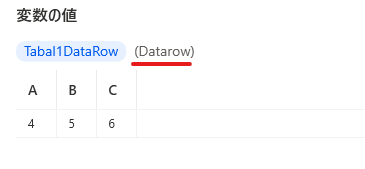
DataRowは列数が同じテーブルに結合できます。
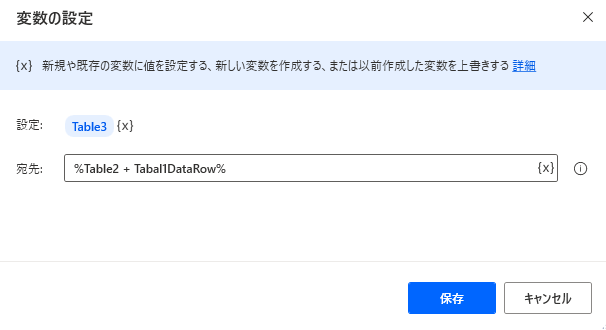
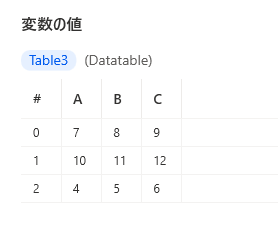
データテーブルの値を置換
変数名にインデックスを指定して値を置き換えることができます。
ただし今のところサポートされている方法ではないためご注意ください。
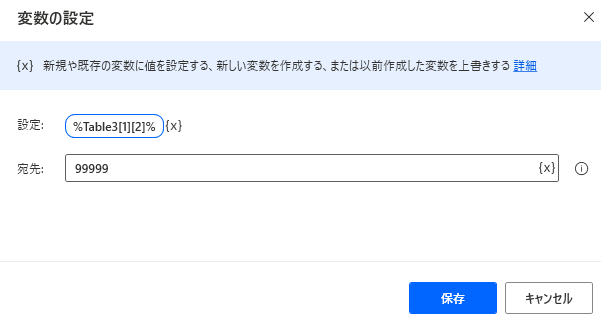
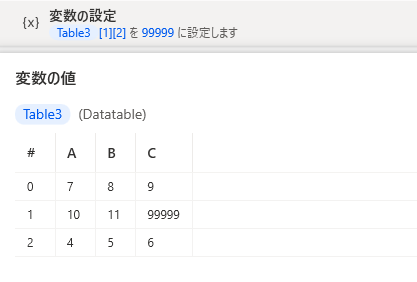
PAD内でデータテーブルを作成
乱数の生成アクションを利用してサンプルデータテーブルを作成します。
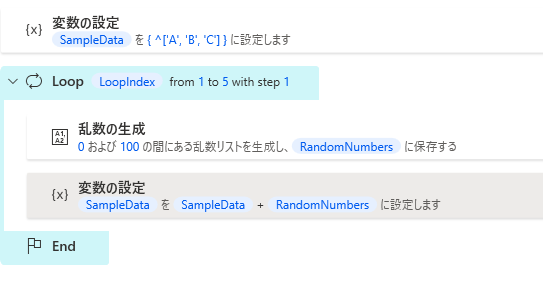
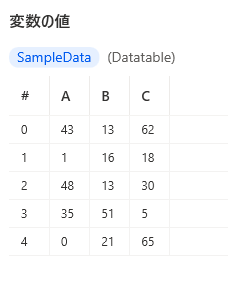
-
列名のみのデータテーブルを作成
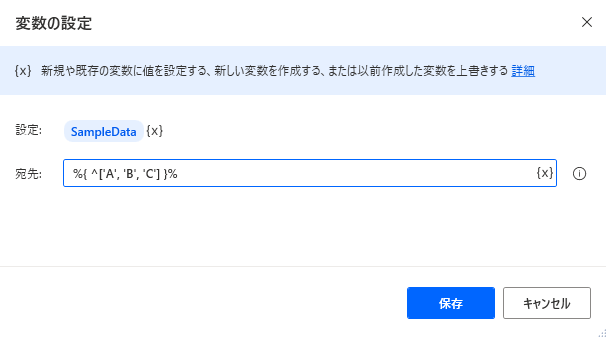
-
乱数の生成アクションで列数に合わせたリストを作成
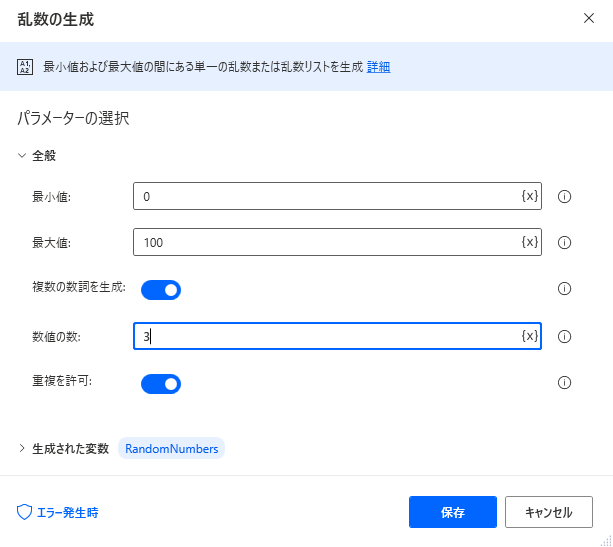
-
列名のみのデータテーブルに結合
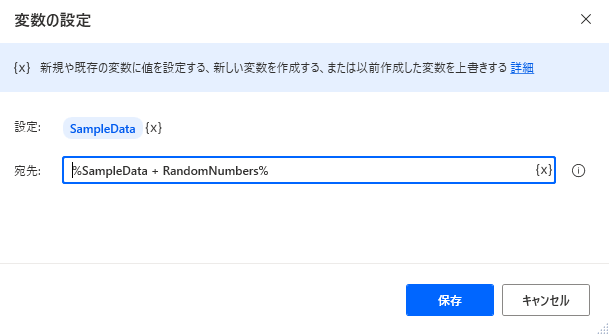
-
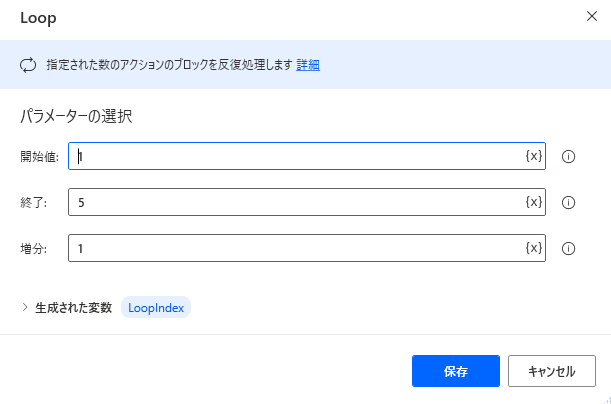
2,3を必要なで行数に合わせてループ
ExcelからPAD用データテーブルに変換
Excelファイルの列行データをPADにハードコードできるように変換するpythonスクリプトです。
起動してExcelファイルを選択するとクリップボードにPADの「変数の設定」アクション用コードとして格納されます。
「変数の設定」アクションにペーストするとデータテーブルとして扱うことができます。
手で書くのは面倒なので作成しました。
「変数の設定」アクションに格納できる最大文字数は半角65536文字です。
python3.8.7
Pandas
openpyxl
xlrd
pyperclip
import os
import pandas as pd
import pyperclip
import tkinter.filedialog
desktop_path = os.path.expanduser('~/Desktop')
filetype = [("excel", "*.xlsx")]
file_path = tkinter.filedialog.askopenfilename(
filetypes=filetype, initialdir=desktop_path)
df = pd.read_excel(file_path)
for name in df.columns:
if df[name].dtype == "datetime64[ns]":
df[name] = df[name].astype(str)
df2 = df.reset_index().T.reset_index()
d = df2.drop(df2.index[0]).T.values.tolist()
e = ",".join(map(str, d))
f = "%{^"+e+"}%"
pyperclip.copy(f)
今回のコード
SET ColumnName TO ['A', 'B', 'C']
SET List1 TO [1, 2, 3]
SET List2 TO [4, 5, 6]
SET ColumnName TO { ^ColumnName }
SET Table TO ColumnName + List1 + List2
SET Table2 TO { ^['A', 'B', 'C'], [7, 8, 9], [10, 11, 12] }
SET Tabal1DataRow TO Table[1]
SET Table3 TO Table2 + Tabal1DataRow
# デモ1
SET SampleData TO { ^['A', 'B', 'C'] }
LOOP LoopIndex FROM 1 TO 5 STEP 1
Variables.GenerateRandomNumber.ListOfRandomNumbers MinimumValue: 0 MaximumValue: 100 NumbersCount: 3 AllowDuplicates: True RandomNumbers=> RandomNumbers
SET SampleData TO SampleData + RandomNumbers
END
# デモ2
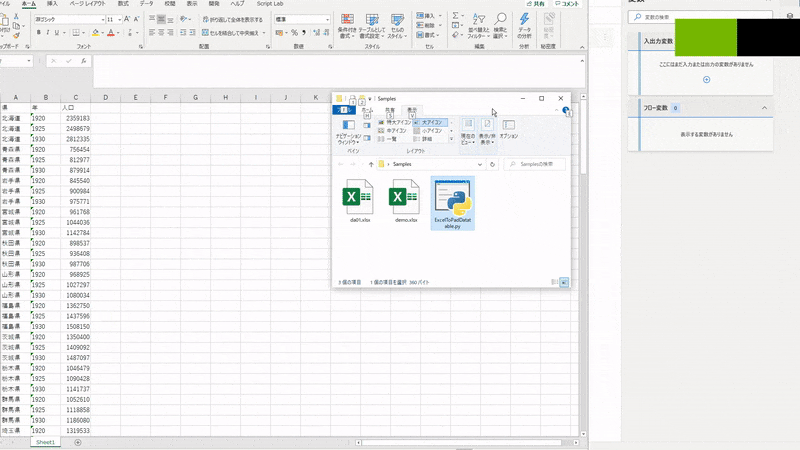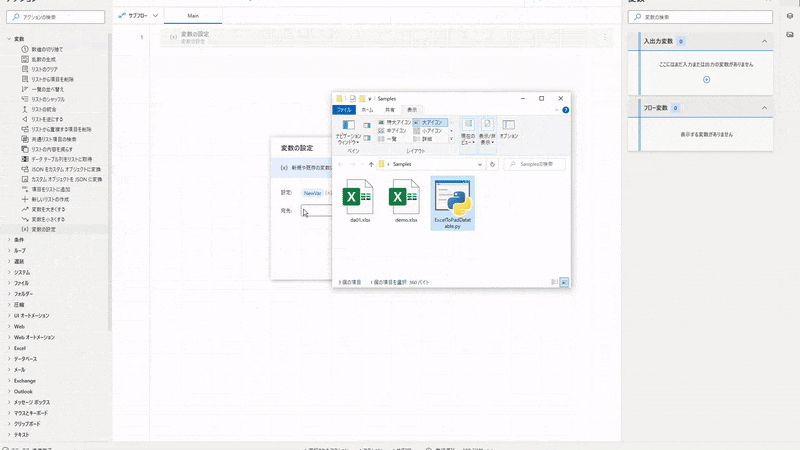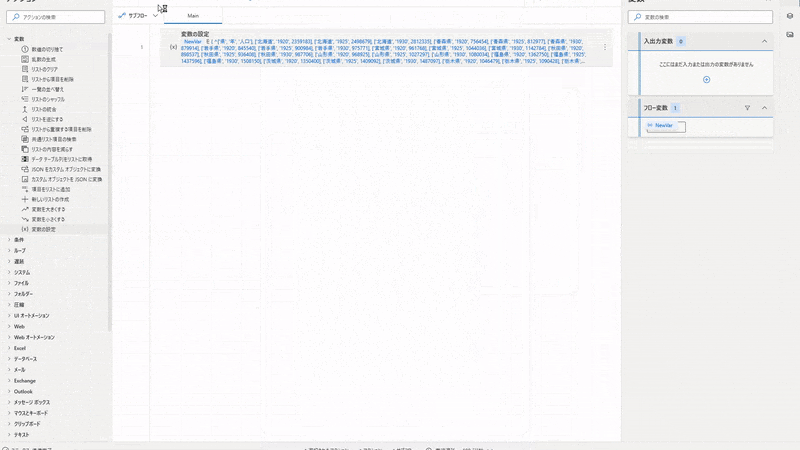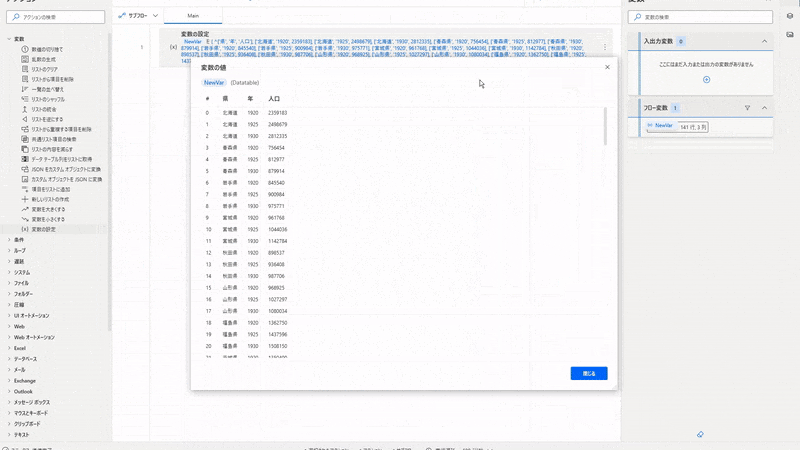
SET NewVar TO { ^['県', '年', '人口'], ['北海道', '1920', 2359183], ['北海道', '1925', 2498679], ['北海道', '1930', 2812335], ['青森県', '1920', 756454], ['青森県', '1925', 812977], ['青森県', '1930', 879914], ['岩手県', '1920', 845540], ['岩手県', '1925', 900984], ['岩手県', '1930', 975771], ['宮城県', '1920', 961768], ['宮城県', '1925', 1044036], ['宮城県', '1930', 1142784], ['秋田県', '1920', 898537], ['秋田県', '1925', 936408], ['秋田県', '1930', 987706], ['山形県', '1920', 968925], ['山形県', '1925', 1027297], ['山形県', '1930', 1080034], ['福島県', '1920', 1362750], ['福島県', '1925', 1437596], ['福島県', '1930', 1508150], ['茨城県', '1920', 1350400], ['茨城県', '1925', 1409092], ['茨城県', '1930', 1487097], ['栃木県', '1920', 1046479], ['栃木県', '1925', 1090428], ['栃木県', '1930', 1141737], ['群馬県', '1920', 1052610], ['群馬県', '1925', 1118858], ['群馬県', '1930', 1186080], ['埼玉県', '1920', 1319533], ['埼玉県', '1925', 1394461], ['埼玉県', '1930', 1459172], ['千葉県', '1920', 1336155], ['千葉県', '1925', 1399257], ['千葉県', '1930', 1470121], ['東京都', '1920', 3699428], ['東京都', '1925', 4485144], ['東京都', '1930', 5408678], ['神奈川県', '1920', 1323390], ['神奈川県', '1925', 1416792], ['神奈川県', '1930', 1619606], ['新潟県', '1920', 1776474], ['新潟県', '1925', 1849807], ['新潟県', '1930', 1933326], ['富山県', '1920', 724276], ['富山県', '1925', 749243], ['富山県', '1930', 778953], ['石川県', '1920', 747360], ['石川県', '1925', 750854], ['石川県', '1930', 756835], ['福井県', '1920', 599155], ['福井県', '1925', 597899], ['福井県', '1930', 618144], ['山梨県', '1920', 583453], ['山梨県', '1925', 600675], ['山梨県', '1930', 631042], ['長野県', '1920', 1562722], ['長野県', '1925', 1629217], ['長野県', '1930', 1717118], ['岐阜県', '1920', 1070407], ['岐阜県', '1925', 1132557], ['岐阜県', '1930', 1178405], ['静岡県', '1920', 1550387], ['静岡県', '1925', 1671217], ['静岡県', '1930', 1797805], ['愛知県', '1920', 2089762], ['愛知県', '1925', 2319494], ['愛知県', '1930', 2567413], ['三重県', '1920', 1069270], ['三重県', '1925', 1107692], ['三重県', '1930', 1157407], ['滋賀県', '1920', 651050], ['滋賀県', '1925', 662412], ['滋賀県', '1930', 691631], ['京都府', '1920', 1287147], ['京都府', '1925', 1406382], ['京都府', '1930', 1552832], ['大阪府', '1920', 2587847], ['大阪府', '1925', 3059502], ['大阪府', '1930', 3540017], ['兵庫県', '1920', 2301799], ['兵庫県', '1925', 2454679], ['兵庫県', '1930', 2646301], ['奈良県', '1920', 564607], ['奈良県', '1925', 583828], ['奈良県', '1930', 596225], ['和歌山県', '1920', 750411], ['和歌山県', '1925', 787511], ['和歌山県', '1930', 830748], ['鳥取県', '1920', 454675], ['鳥取県', '1925', 472230], ['鳥取県', '1930', 489266], ['島根県', '1920', 714712], ['島根県', '1925', 722402], ['島根県', '1930', 739507], ['岡山県', '1920', 1217698], ['岡山県', '1925', 1238447], ['岡山県', '1930', 1283962], ['広島県', '1920', 1541905], ['広島県', '1925', 1617680], ['広島県', '1930', 1692136], ['山口県', '1920', 1041013], ['山口県', '1925', 1094544], ['山口県', '1930', 1135637], ['徳島県', '1920', 670212], ['徳島県', '1925', 689814], ['徳島県', '1930', 716544], ['香川県', '1920', 677852], ['香川県', '1925', 700308], ['香川県', '1930', 732816], ['愛媛県', '1920', 1046720], ['愛媛県', '1925', 1096366], ['愛媛県', '1930', 1142122], ['高知県', '1920', 670895], ['高知県', '1925', 687478], ['高知県', '1930', 718152], ['福岡県', '1920', 2188249], ['福岡県', '1925', 2301668], ['福岡県', '1930', 2527119], ['佐賀県', '1920', 673895], ['佐賀県', '1925', 684831], ['佐賀県', '1930', 691565], ['長崎県', '1920', 1136182], ['長崎県', '1925', 1163945], ['長崎県', '1930', 1233362], ['熊本県', '1920', 1233233], ['熊本県', '1925', 1296086], ['熊本県', '1930', 1353993], ['大分県', '1920', 860282], ['大分県', '1925', 915136], ['大分県', '1930', 945771], ['宮崎県', '1920', 651097], ['宮崎県', '1925', 691094], ['宮崎県', '1930', 760467], ['鹿児島県', '1920', 1415582], ['鹿児島県', '1925', 1472193], ['鹿児島県', '1930', 1556690], ['沖縄県', '1920', 571572], ['沖縄県', '1925', 557622], ['沖縄県', '1930', 577509] }
今回のまとめ
複数のリストが%{}%に格納されたのがPADのデータテーブル型。
データテーブルのインデックスは0ベースです。
データテーブル行をインデックスで指定するとDataRow型として行の値を読みだせます。
値は%テーブル名[行インデックス][列インデックス]%または%テーブル名[行インデックス][列名]%で読みだせます。
いまのところ裏技的ですが変数名にインデックス指定して値の置換が可能です。
ハードコードは賛否あるかと思いますが、データテーブルを設定ファイルとして外に置かなくてよいのでフローを共有するときに役立つかもしれません。
参考
Robin - RPA language
note.nkmk.me - pandas.DataFrame, SeriesとPython標準のリストを相互に変換