漢なら C++11 だけで単一画像からの 3D 顔復元したいですね!
やりましょう!
できました.
PRNetInfer is a C++11 port of PRNet https://t.co/ZAXpWTQiC2 in Tensorflow C++ API(Inference only). You can reconstruct 3D face 😃 purely in C++11 🎉 Raytraced visualization of reconstructed mesh as a bonus! 💪💪💪 https://t.co/hF1O2wwP6l pic.twitter.com/va2Tystufh
— Syoyo Fujita (@syoyo) 2018年6月7日
手順
PRNet https://github.com/YadiraF/PRNet を C++11 で動くようにします.
PRNet は横顔でも検出がしやすかったり(その代わり正面顔には弱い?), 推論も高速を謳っているのが特徴です.
PRnet は TensorFlow で実装されていますので, これを TensorFlow C++ API で使うようにします.
まず, TensorFlow の C++ ライブラリをビルドと, それを利用する CMake プロジェクトをセットアップしておきます.
TensorFlow C++(libtensorflow_cc.so) で推論アプリを CMake でビルドする(r1.8 対象)
https://qiita.com/syoyo/items/c102611ff63a6bbadc80
を参考に, libtensorflow_cc.so を使って C++ で動かすようにします.
モデルファイル
モデルは freezed 形式で利用することにしました.
freeze 後のモデルと重みの入ったグラフファイルは, 51MB くらいになります.
推論
画像のクロップ
画像データをテンソルにし, Session::Run すると結果(三次元位置情報)がこれまた画像(256x256x3)として出力されます.
dlib を使って顔領域を切り出すのがよいのですが, 今回はとりあえず人力でやりました.

dlib を使わない推論では, PRNet では x1.6 倍に縮小して推論に渡すような仕組みになっているので, それに合わせて画像縮小のコードも C++ で実装しました.
実際に推論に渡すのは以下のように画像中心を基準にして縮小したものになります. 周りは黒で埋めておきます.

推論する
画像をテンソルにして, Session::Run を呼んで推論します.
推論の部分は 優秀な C++ 機械学習若人さまが人類史上最速(3 時間くらい)で実装してくれました
重要なことなので繰り返します.
推論の部分は 優秀な C++ 機械学習若人さまが人類史上最速(3 時間くらい)で実装してくれました
素晴らしいですね, ありがたいですね.
PRNet 側なのか, Tensorflow 側なのかは不明ですが, 出力結果のテンソルでは height, width の順になっているので注意です.
で width, height の順になるように補正しています.
CPU で推論実行していますが, 2~3 秒くらいとそれほど早くはありませんでした.
シングルコアで実行しているのが原因です.
TensorFlow の Session::Run は CPU だとマルチスレッド実行できない(?)ようなので, 推論に特化した TensorFlow Lite に期待でしょうか.
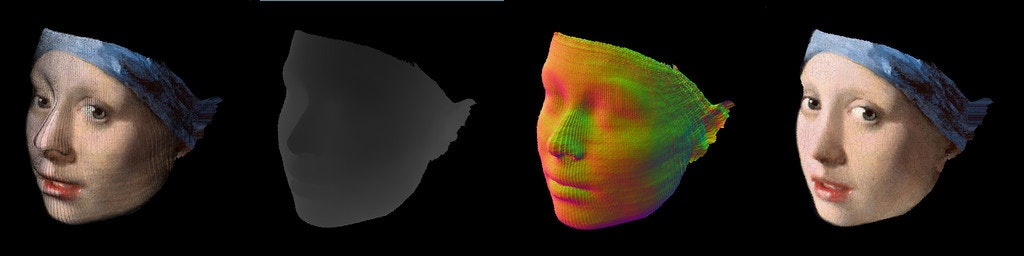
形状の取り出し
推論の結果は三次元位置情報が 256x256x3 の画像として出力されます.

(画像の下の部分は, メッシュの復元では使われない領域です)
実際にはここで結果の値を画像サイズ(256)x1.1 倍します. x1.1 はなんらかの理由で PRNet がつけた係数かなにかでしょうか.
その後, 推論のところで x1.6 倍縮小しているので, 頂点座標に x1.6 倍とオフセットをかけてもともとの座標に戻します.
だいたい座標データの x, y は (0, 255) の位置に収まっているので, 頂点位置に対応する元画像のピクセルを取得することでテクスチャを復元できます.
実際に利用するピクセルは, メッシュの三角形を定義する頂点インデックスとして別途定義されています(numpy(fortran?) データなので, 1 から始まることに注意です)
PRNet の Data/uv-data にあるのでそれを利用します.
これで三次元位置とテクスチャを取得することができます!
GUI 表示
prnet-infer では, せっかくなので結果をレイトレーシングで描画するようにしてみました.
レイトレーシングライブラリには NanoRT を使っています.
冬到来! NanoRT ではじめよう C++ レイトレーシング
https://qiita.com/syoyo/items/1aae159f9b262fbd4aa3
実装上の注意点
PRNet では, 入力画像を少しスケーリングして推論を行ったり(crop)とかちょっとした落とし穴がありました.
ポーティングする場合は, 元の python 実装を注意深く読んでおく必要がありますね.
Caffe2 で動かしたいが現時点では ONNX 変換ができなかった
モバイルで動かしたいので ONNX 経由で Caffe2 に変換し, Caffe2 で動かそうとしましたが, tensorflow-onnx では FusedBatchNorm op がサポートされておらず変換できませんでした.
tensorflow-onnx でのサポートを待つか, とりあえず libtensorflow でやってしまうか, 推論部分だけなら自前で実装したほうが早いかもしれませんね.
tf-coreml https://github.com/tf-coreml/tf-coreml では FusedBatchNorm に対応していて変換まではできるのを確認しました.
CoreML で iOS で動したい
tf-coreml https://github.com/tf-coreml/tf-coreml で CoreML に変換できるところまでは確認しました.
tf-coreml のソースコードにしか記載がありませんが, 今回は画像を入力にしているため, 変換時のパラメータで
image_input_names に Placeholder:0(入力レイヤー名)を指定する必要があります
(そうしないと, 入力の型が MLMultiArray となってしまう)
TODO
- 正面顔に変形する機能(frontialization)を C++ でも実装する
- CPU でマルチスレッドで推論する方法を探す
- GPU で推論する
- モバイル(caffe2)で動かす.
- 優秀な C++ 若人と, 優秀な機械学習若人が, 日々切磋琢磨し, 人類史上最速で優秀な C++ 機械学習若人へと昇華なされるスキームを確立し, 1 億総優秀な C++ 機械学習若人活躍社会が到来してほしい.