はじめに
- AWS LambdaでRESTでデータ取得してSplunkに送信してみるではBlueprintを使用してLambdaからSplunkへのHEC送信に成功しました。
- しかしBlueprintはNode.jsでした。Splunk管理者はPythonの方が得意だと思いますので(偏見)、Pythonでできないか調べました。
- PythonでSplunk HECに送信するClass(Splunk-Class-httpevent)がありましたので、今回はこちらを使って実現します。
- Splunk-Class-httpeventはレイヤーにしてLambda上のPythonから呼び出せるようにします。
- Splunkで毎日運勢を占えるようになりました。
環境
- Lambdaからアクセス可能するためEC2などでグローバルIPを持つSplunk Enterprise、もしくはSplunk Cloud
- AWS Lambda
設定手順の概要
- SplunkでHEC設定
- AWS Lambdaのレイヤー作成(モジュールアップロード)
- AWS Lambdaで関数作成
- CloudWatchでLambdaを定期実行化
設定手順
1. SplunkでHEC設定
まずはいつも通り、AWS Lambdaからデータを受け取るためのHECを設定します。
- 設定 > データ入力
- HTTPイベントコレクターの [+ 新規追加] をクリック
- 名前を適当に入力して [次へ] をクリック
- 取り込み先のインデックスを選択 ※今回はaws_lambdaを作成しました。
- 生成されたトークンをメモ
以上です。
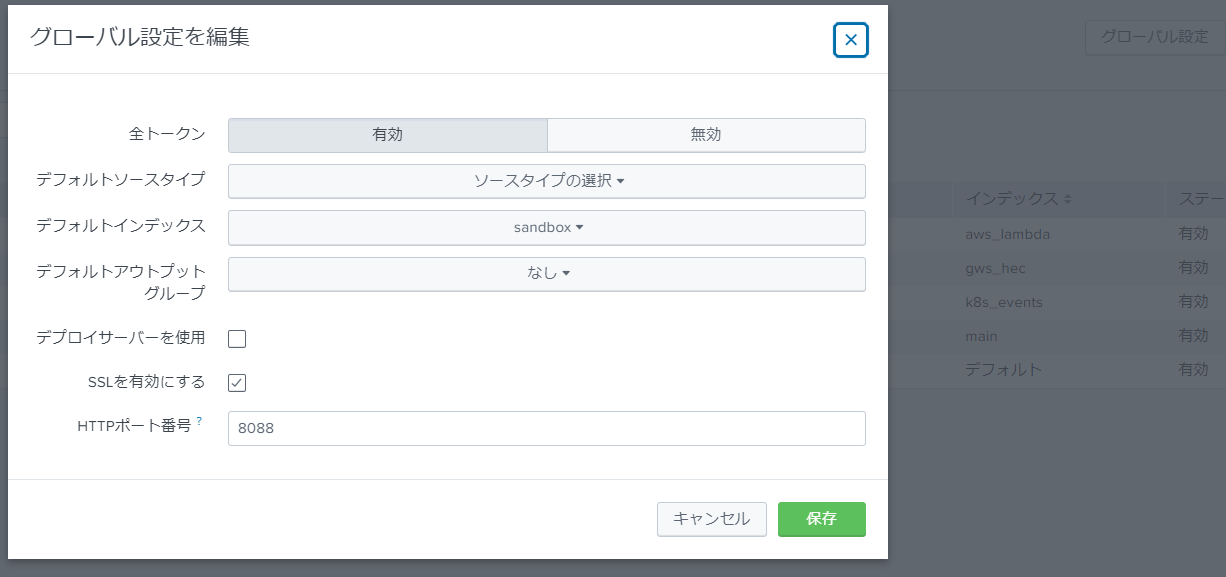
念のため、SSLの有効/無効状況やHTTPポート番号をグローバル設定から確認しておきましょう。
2. AWS Lambdaのレイヤー作成(モジュールアップロード)
PythonからSplunk HECでデータ送信する神ClassをSplunk Trustの方が作っていらっしゃいました。
Splunk-Class-httpevent
今回はこちらをありがたく使わせていただきます。
とは言ってもLambdaではpipでインストールはできません。
その代わりにLambdaのレイヤー機能を使用します。
モジュールなどをzipで固めてレイヤーにアップロードすることで、Lambda関数から呼び出すことができます。
AWS Lambda レイヤー
2-1. zipの準備
ローカルで以下のようにモジュールをpythonディレクトリにダウンロードしzip化します。
※ディレクトリ名は「python」である必要があります。レイヤーとしてアップロードしたときに/opt/配下に展開されるためです。zip名は任意です。
mkdir ./python
pip install git+git://github.com/georgestarcher/Splunk-Class-httpevent.git -d ./python
zip -r python-hec.zip ./python
2-2. レイヤーへのアップロード
Lambdaページのレイヤーメニューから [レイヤーの作成] をクリックします。
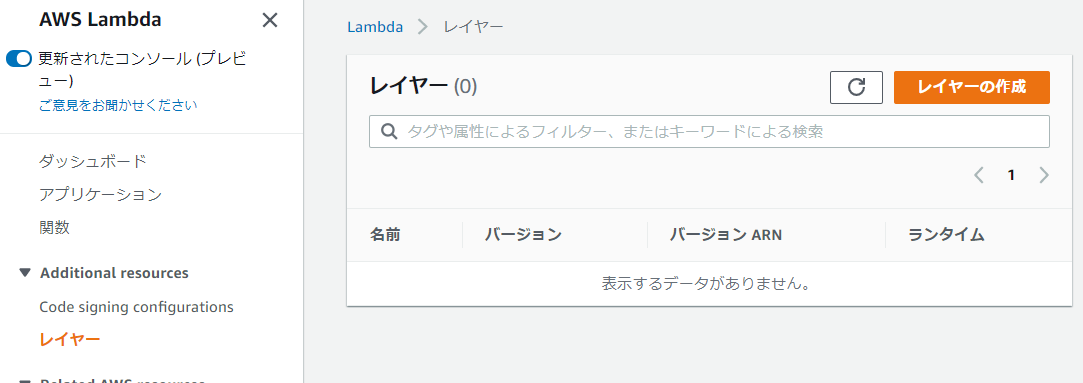
適当に名前を付け、作成したzipファイルをアップロードし、互換性のあるランタイムにPythonを選択し、[作成] をクリックします。
これでレイヤー作成は完了です。
次は関数を作成します。
3. AWS Lambdaで関数作成
3-1. 関数作成
- Lambdaの関数メニューから [関数を作成] をクリック
- [一から作成] を選択し諸々入力
- 関数名:任意
- ランタイム:Python (本記事の作成時点で最新版の3.8)
- 実行ロール:「基本的なLambdaアクセス権限で新しいロールを作成」のまま
- [関数の作成] をクリック
3-2. レイヤーの追加
- 関数ページの下の方にあるレイヤー枠の [レイヤーの追加] をクリック

- 「カスタムレイヤー」を選択し、カスタムレイヤーから先ほどアップロードしたレイヤーとバージョンを選択。
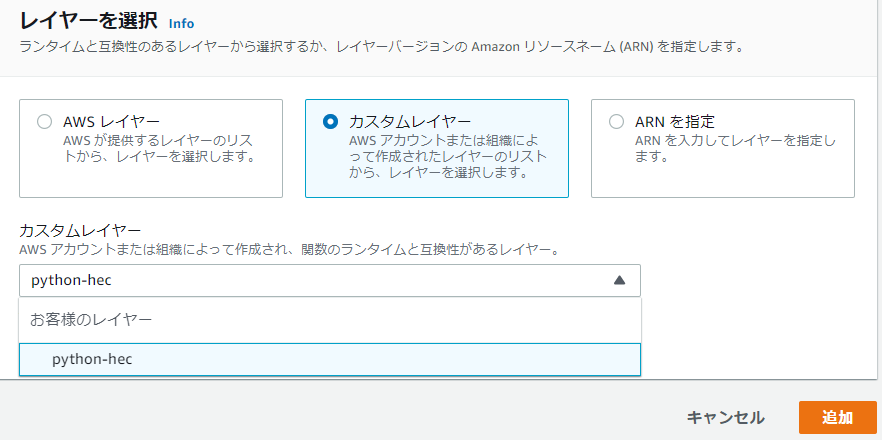
- [追加] をクリックして完了。
これで関数から通常のimportで呼び出せるようになりました。
3-3. Pythonスクリプト作成
それではPythonスクリプトを作っていきましょう。
Splunk-Class-httpeventの使い方としてサンプルが提供されています。
特に重要な箇所は以下です。
# HEC URLおよびトークン
http_event_collector_key = "4D14F8D9-D788-4E6E-BF2D-D1A46441242E"
http_event_collector_host = "localhost"
# Splunkメタデータ
payload = {}
payload.update({"index":"test"})
payload.update({"sourcetype":"crime"})
payload.update({"source":"witness"})
payload.update({"host":"mansion"})
# データ送信(単発)
for i in range(5):
event = commitCrime()
event.update({"action":"success"})
event.update({"crime_type":"single"})
event.update({"crime_number":i})
payload.update({"event":event})
testevent.sendEvent(payload)
# データ送信(バッチ)
for i in range(50000):
event = commitCrime()
event.update({"action":"success"})
event.update({"crime_type":"batch"})
event.update({"crime_number":i})
payload.update({"event":event})
testevent.batchEvent(payload)
testevent.flushBatch()
それでは、今回も適当なREST APIでデータを取ってみましょう。
占いAPIでSplunkで毎日お手軽に占えるようにしたいと思います。
Web ad Fortune 無料版API
※利用規約あり。商用利用の場合はビジネス版あり。
このような感じで年月日を渡せば良いようです。
http://api.jugemkey.jp/api/horoscope/free/year/month/day
これを使ってデータ取得と送信のスクリプトを作ってみます。
できたものがこちらです。
from splunk_http_event_collector import http_event_collector
import requests
import os
import json
import logging
import sys
import datetime
def lambda_handler(event, context):
# init logging config, this would be job of your main code using this class.
logging.basicConfig(format='%(asctime)s %(name)s %(levelname)s %(message)s', datefmt='%Y-%m-%d %H:%M:%S %z')
# Create event collector object, default SSL and HTTP Event Collector Port
# HEC URL、トークンは環境変数化。[設定]タブ > [環境変数]から環境変数を作成できる。
http_event_collector_key = os.environ["SPLUNK_HEC_TOKEN"]
http_event_collector_host = os.environ["SPLUNK_HEC_URL"]
testevent = http_event_collector(http_event_collector_key, http_event_collector_host)
# perform a HEC reachable check
hec_reachable = testevent.check_connectivity()
if not hec_reachable:
sys.exit(1)
# Set to pop null fields. Always a good idea
testevent.popNullFields = True
# set logging to DEBUG for example
testevent.log.setLevel(logging.DEBUG)
# Start event payload and add the metadata information
payload = {}
payload.update({"index":"aws_lambda"})
payload.update({"sourcetype":"horoscope"})
payload.update({"source":context.function_name})
payload.update({"host":"lambda"})
# 本日の占い取得。LambdaはUTCで動作するためJSTに変換する。
dt = datetime.datetime.utcnow() + datetime.timedelta(hours=9)
url = "http://api.jugemkey.jp/api/horoscope/free/{}/{}/{}".format(dt.year, dt.month, dt.day)
event = requests.get(url).json()
# Splunk HECへ送信
payload.update({"event":event})
testevent.sendEvent(payload)
さて、これを実行してみます。[Test] ボタンからテストできます。 [Deploy] で更新内容を反映してからテストしてみましょう。
Splunkで見てみましょう。無事取り込めました。すごい!

いい感じに動いたので、次はこのスクリプトを定期実行したいと思います。
3. CloudWatchでLambdaを定期実行化
前回記事と同様に、CloudWatchで定期実行化します。
早速設定してみましょう。
- 設定 > トリガーから [トリガーを追加] をクリック
- EventBridge (CloudWatch Events) を選択
- ルールタイプで「スケジュール式」を選択。cron(0 15 ? * * *)で毎日日本時間の0時0分に取得するようにします。
- [追加] をクリックすれば定期実行化が完了
これで毎日、その日の運勢を取得してSplunkに送ってくれるようになりました。
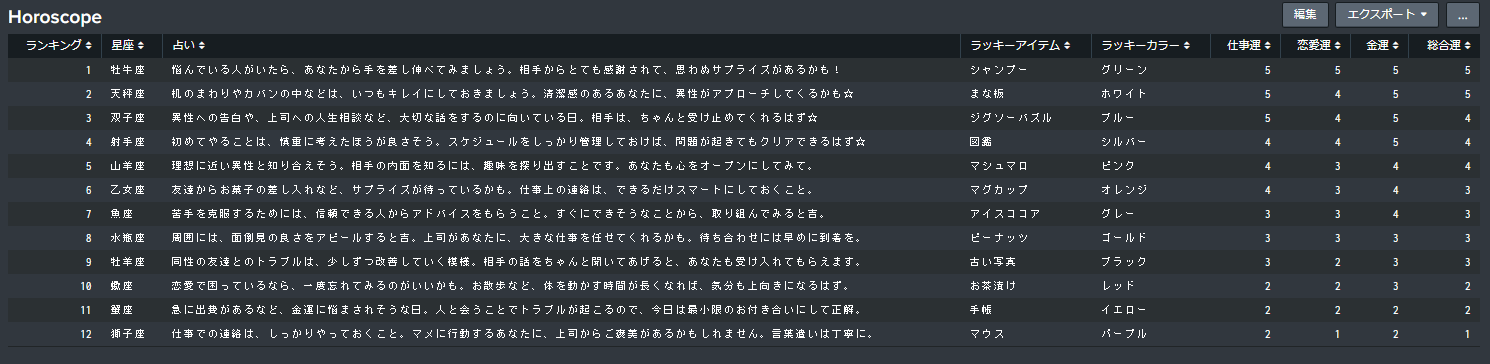
4. 今日の運勢をダッシュボード化
せっかくなのでダッシュボードで本日の運勢を見れるようにしてみましょう。
SPLは以下です。
index=aws_lambda sourcetype=horoscope earliest=@d
| table horoscope*
| foreach horoscope.*.* [rename <<FIELD>> as <<MATCHSEG2>>]
| mvexpand color
| streamstats count
| eval content=mvindex(content,count - 1)
| eval item=mvindex(item,count - 1)
| eval job=mvindex(job,count - 1)
| eval love=mvindex(love,count - 1)
| eval money=mvindex(money,count - 1)
| eval rank=mvindex(rank,count - 1)
| eval sign=mvindex(sign,count - 1)
| eval total=mvindex(total,count - 1)
| fields - count day
| table rank sign content item color job love money total
| sort rank
| rename rank as "ランキング", sign as "星座", content as "占い", "item" as "ラッキーアイテム", "color" as "ラッキーカラー", "job" as "仕事運", love as "恋愛運", money as "金運", total as "総合運"
ダッシュボードにします。
なんならトップページに載せてしまいましょう。
まとめ
- AWS LambdaでPythonを使用し、RESTでデータ取得、SplunkにHEC送信できるようになりました。
- レイヤーを使えば任意のモジュールをアップロードし呼び出せますのでお好みのモジュールで色々なことができそうです。