0. 本記事の概要
Deep Convolutional Neural Networkは多くのComputer Visionのタスクにおいて非常に優れた性能を示しています。しかし時折、Over fitting(過学習)が問題として挙げられます。また、医療画像をはじめとする特定の分野においては、大量の学習データを集めることができない現状が散見されます。新型コロナウイルスへの感染を肺のX線画像からAIの力で診断しようという取り組みは世界で行わておりますが、日本においては特に、学習データとなる画像不足が問題点として挙げられています。
そのように、学習データが不足している(または多様でない)場合に、「Data Augmentation」を行い、その問題の解決を目指します。「Augmentation」 とは「増加・増強」という意味になりますが、その意味通り、「Data Augmentation」とは、データのサイズや品質を向上させ、それらを用いてより優れたDeep Learningモデルを学習できるようにする一連の技術のことを指します。
そんな「Data Augmentation」の体系についてまとめた論文が2019年に発表されております。
| 題名 | A survey on Image Data Augmentation for Deep Learning |
| 著者 | Connor Shorten and Taghi M. Khoshgoftaar |
| 出版 | Journal of Big Data |
| 発行日 | 2019.06.06 |
| URL | Springer |
私自身も「Data Augmentation」をデータに適用する必要があり、この論文をもとに調査を行ない、私が感じたことを含めて、備忘録としてまとめたいと思います。これから本記事で説明する内容は、こちらの論文に従い、図表なども引用させていただきます。とてもボリューミーな論文ですので、以下の3回に分けてまとめていきたいと思っています.
- 深層学習のための Image Data Augmentation(1:基本的な手法)←本記事
- 深層学習のための Image Data Augmentation(2:深層学習を用いた手法)
- 深層学習のための Image Data Augmentation(3:メタ学習を用いた手法)(準備中...)
本記事は、**深層学習のための Image Data Augmentation(1:基本的な手法)**となります。
1. 導入
近年、Convolutinoal Neural Network(CNN)を用いたDeep Learningの発展が著しくあります。CNNを用いて得られる特徴は、ハンドクラフトな特徴と比べて高次元で表現能力の高い特徴であることが知られています。このCNN特徴を用いてDeep Larningを行うことで、画像分類や物体検出の精度が著しく向上しており、Compute Visionの発展に欠かせない技術となっています。一般的に、Deep Learningを行う上で、より大きなデータセットはより優れたモデルを学習可能であることが知られています[23, 24]。
上でも述べた様に、医療画像をはじめとする特定の分野においては、大量の学習データを集めることができない現状が散見されます。これらの問題の解決のために、「Data Augmentation」という技術が種々提案されています。
また、本論文では、過学習の問題にも言及がなされています。過学習は、学習モデルの汎化能力の不足を意味し、言い換えれば学習データとテストデータに大きな差があるとき生じる問題の1つです。
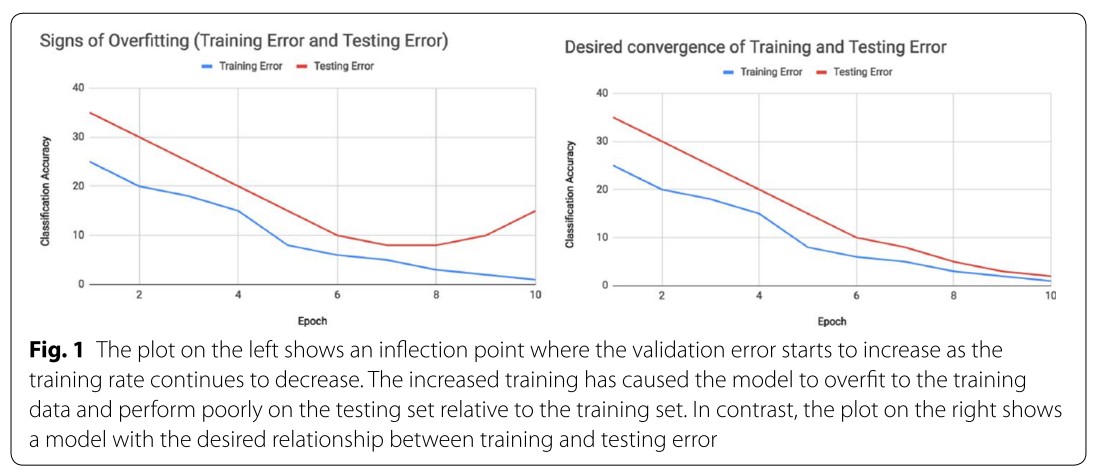
過学習を発見する1つの方法は、学習中の各エポックでの学習精度と検証精度をプロットすることです。上のグラフは、これらの精度を学習エポックで可視化したときの過学習の様子を示しています。左側のプロットは、学習エポックが増加するにつれてテストデータの誤差が増加し始める変曲点を示しています。対照的に、右のプロットは、学習データとテストデータの誤差が望ましい関係を保ったままモデルの学習が進んでいます。
この差を埋めるために、学習データを増強する「Data Augmentation」は有効な手段であると考えられます。過学習を抑制するための「Data Augmentation」以外の基本的な手法がいくつか紹介されています。
| Dropout [7] | 学習中にニューロンの活性化をランダムで0にする |
| Batch Normalication [9] | 各活性化からバッチ平均を減算し、バッチ標準偏差で除算する |
| Transfer Learning [10, 11] | 他のデータセットで学習して得られた重みの1部を新しい分類タスクの初期重みとして用いる |
| Pretraining [15] | ネットワークを最初に定義し、他のデータセットで学習を行う |
| Zero/One Shot Learning [16, 17] | 学習データに含まれないクラスに対しても分類を可能にする |
以上のような手法とは対照的に、「Data Augmentation」は学習データ自体にメスを入れ、良いモデルを学習させようという考え方です。
「Data Augmentation」の手法は様々存在しますが、大きく2つに分けられます。
1. Data Warping Augmentation : データのラベルを保持しつつ加工を行うことで増強
2. Oversampling Augmentation : データから新しいデータを生成することで増強
「加工」するか「生成」するかで分けられています。それぞれの例をいくつか例を紹介します。
| Data Warping Augmentation | Oversampling Augmentation |
|---|---|
| Geometric Transformations | Mixing Images |
| Color Space Transformations | Feature Space Augmentations |
| Kernel Filters | Generative Adversarial Networks (GANs) |
| Random Erasing | - |
| Adversarial Training | - |
| Neural Style Transfer | - |
さらに、Data Augmentationを適用する最適な手法を学習するmeta-learningというものもいくつかあり、そちらは以下のようになっています。
| Meta-learning Method |
|---|
| Neural Augmentation |
| AutoAugment |
| Smart Augmentation |
これらのmeta-learning methodは、Neural Architecture Search [33]の概念を取り入れたものです。
本論文では、これらをまとめて「Data Augmentation」の体系を表す図が示されています。
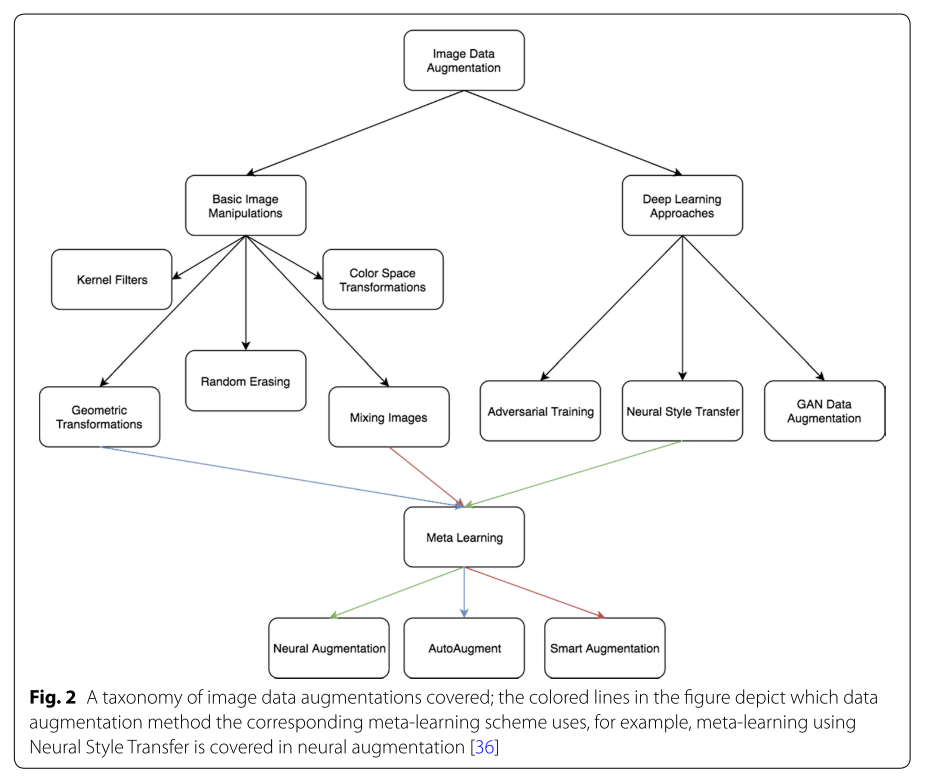
今回は、上の図のBasic Image Manipulationsの手法をピックアップして、説明をしていきます。
| Data Warping Augmentation | Oversampling Augmentation |
|---|---|
| Geometric Transformations | Mixing Images |
| Color Space Transformations | Feature Space Augmentations |
| Kernel Filters | Generative Adversarial Networks (GANs) |
| Random Erasing | - |
| Adversarial Training | - |
| Neural Style Transfer | - |
今回Basic Image Manipulationsとして扱う手法は、「加工」からはGeometric Transformations、Color Space Transformations、Kernel Filters、Random Erasing、「生成」からはMixing Imagesとなります。
2. Data Augmentation 手法
ここからは様々なData Augmentation手法について説明をしていきます。
自分でも簡単にできそうなData Augmentationは友人A君の画像を用いて行ってみています。
2.1 Geometric Tranformations
Geometric Transformationsすなわち幾何学的な変換についていくつかの例を紹介します。
| Data Warping Augmentation | Oversampling Augmentation |
|---|---|
| Geometric Transformations | Mixing Images |
| Color Space Transformations | Feature Space Augmentations |
| Kernel Filters | Generative Adversarial Networks (GANs) |
| Random Erasing | - |
| Adversarial Training | - |
| Neural Style Transfer | - |
2.1.1 Flipping(反転)
横軸に対する反転(Horizontal axis flipping)の方が縦軸に対する反転(Vertical axis flipping)よりも一般的です。
| Original | Horizontal axis flipping | Vertical axis flipping |
|---|---|---|
 |
 |
 |
ImageNetやCIFER-10での有効性が確認されています。ただし、MNISTやSVHNのデータに適用した場合、安全性が保証されない場合があります。例えば、MNISTにおいて6をVertical axis flippingすると9になります。
2.1.2 Color Space(色空間)
カラーチャネル(RGB)の各要素の抽出、コントラスト調整、カラーヒストグラム調整など、色空間を操作することでData Augmentationを行います。
| Original | R | G | B |
|---|---|---|---|
|
 |
 |
 |
2.1.3 Cropping(くり抜き)
画像のClippingを行うことでData Augmentationを行います。中央のClipping(Center)の場合は、様々なサイズの画像が含まれるデータセットに有効といえます。また、ランダムでClipping(random)を行う場合は、サイズによって、特に、小さすぎると安全性が保証されないことがあります。
| Original | center | random |
|---|---|---|
|
 |
 |
2.1.4 Rotation(回転)
RotationによるData Augmentationの安全性はその回転角度によって変化します。例えば、上のFlippingでも述べたように、MNISTにおいて6をVertical axis flippingすると9になります。
| Original | 30° | 120° | 270° |
|---|---|---|---|
|
 |
 |
|
2.1.5 Translation(平行移動)
TranslationによるData Augmentationは、データの位置的な偏りに対して効果を示します。例えば、顔画像のデータセットの画像は、一般的には中央に顔が配置されています。このままでは、テスト画像も中央である必要がある為、様々な位置の顔の検出・分類を行うためには、TranslationによるData Augmentationが効果的です。
| Original | Translation 1 | Translation 2 | Translation 3 |
|---|---|---|---|
|
 |
 |
 |
実際、顔画像のData Augmentationをしようとした時、Translation 3のように顔画像が切れるTranslationをしてしまうと、安全性は保証されないと思います。
2.1.6 Noise Injection(ノイズ注入)
Noise InjectionによるData Augmentaionでは、通常はガウス分布により生成されたランダムなノイズを画像に注入します。Noise Injectionでは、CNNがよりロバストな特徴を学習するのに役立つことが知られています。
| Original | Noise |
|---|---|
|
 |
2.1.7 Geometric Transformationsのまとめ
ここまでで、いくつかのGeometric Transformationsの例を紹介しました。Geometric Transformationsは、学習データの位置的な偏りに対して有効です。また、実装も簡単にできることも利点として挙げられます。しかし、RotationやTranslationによるData Augmentationでは対象物の場所を毎回確認する必要もあるため、労力を要することもあります。計算コストが高いこともあり、こちらも問題点です。
2.2 Color Space Transformationsの概要
2.2.1 Color Space Transformations
Color Space Transformations(Photometric Tranformations)について説明します。
| Data Warping Augmentation | Oversampling Augmentation |
|---|---|
| Geometric Transformations | Mixing Images |
| Color Space Transformations | Feature Space Augmentations |
| Kernel Filters | Generative Adversarial Networks (GANs) |
| Random Erasing | - |
| Adversarial Training | - |
| Neural Style Transfer | - |
Geometric Transformationsで説明したColor Spaceとの大きな違いは分かりませんが、論文中では分けて説明がされていました。Color Space Transformationsでは、RGBや明るさ(コントラスト)を調整することによりData Augmentationを行います。画像の色分布を変更することは、画像編集アプリケーションでも簡単に行うことができます。
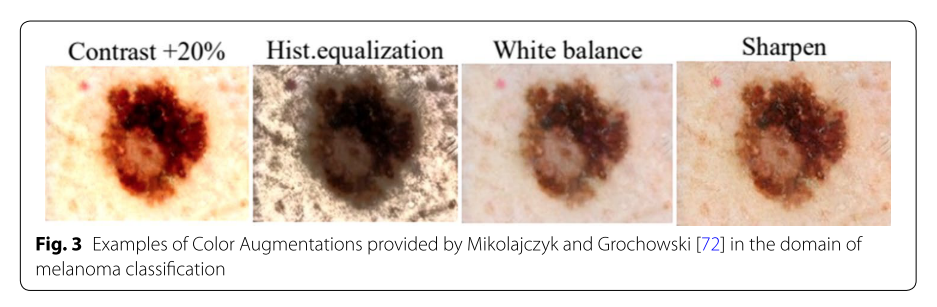
上の図では、悪性黒色腫(melanoma)のColor Space Transformationsのコントラスト調整、ヒストグラム調整などを行い、それらの分類精度の向上を目指しています。

また、こちらの図では、各RGB要素の強調やVignette(画像の中心よりも周囲のほうが暗くなること)によるData Augmentationを行っています。その他にも、Gray Scaleを用いたり、RGB空間をYUV空間、CMY空間、HSV空間に変換するData Augmentationもよく行われる手法です。
2.2.2 Color Space Transformationsのまとめ
Color Space Transformationsでは、色の変換によりData Augmentationを行いました。Color Space Transformationsは実装が簡単ですが、学習コストが大きいことが問題点として挙げられています。また、特定の色の操作を行うことで、物体が消えてしまったりすることもあり、必ずしも安全性が保証されるData Augmentationではありません。
2.3 Geometric Transformations と Color Space Transformations の比較
文献 [63]では、Geometric TransformationsとColor Space Transformationsの比較を行っています。
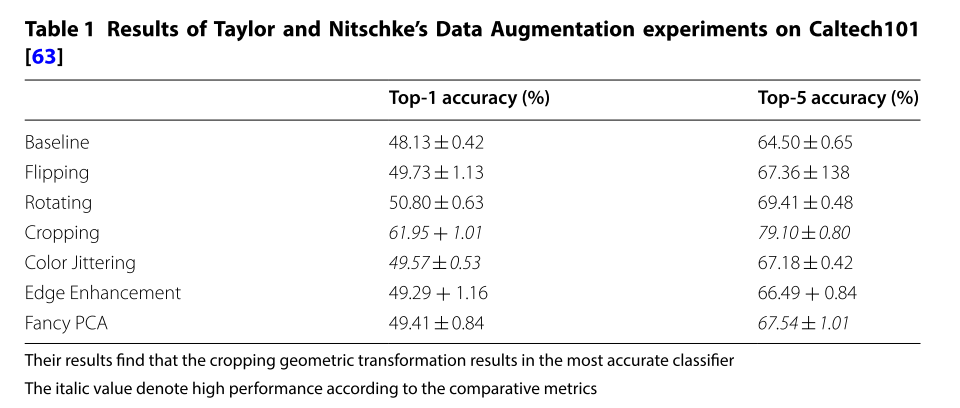
Caltech101データセットを用いて、各Augmentation手法が精度にどの程度寄与しているかを示した表です。一番上がBaselineで、Augmentationをしていないときの結果です。2番目から4番目(Flipping、Rotation(-30°、30°)、Cropping)がGeometric Transformationsの手法です。5番目から7番目(Color Jittering、Edge Enhancement、Fancy PCA)がColor Space Transformationsの手法です。この表からは、Croppingが他の手法と比較して群を抜いて精度が良いことがわかります。
2.4 Kernel Filters
Kernel FiltersによるData Augmentationについて説明します。
| Data Warping Augmentation | Oversampling Augmentation |
|---|---|
| Geometric Transformations | Mixing Images |
| Color Space Transformations | Feature Space Augmentations |
| Kernel Filters | Generative Adversarial Networks (GANs) |
| Random Erasing | - |
| Adversarial Training | - |
| Neural Style Transfer | - |
ここでは、Kernel Filtersとして、Gaussian Blur Filter、Edge Filter、PatchShuffle Regularization [64]について説明をします。
2.4.1 Gaussian Blur Filter
Gaussian Blur Filiterでは、ガウス分布を利用して「注目画素からの距離に応じて近傍の画素値に重みをかける」という処理を行い、自然な平滑化を実現します。
つまり、Blur(ぼかし)を与えるような処理になります。
| Original | Gaussian Blur Filter |
|---|---|
|
 |
このようなBlur(ぼかし)を与えることで、モーションブラー(手振れ)などにロバストなData Augmentationが実現します。
2.4.2 Edge Filter
Edge Filiterでは、隣り合う画素値の変化を微分により検知し、その変化が大きい部分をEdgeとして強調する処理を行います。
| Original | Edge Filter | Sobel Filter | Laplacian Filter |
|---|---|---|---|
|
 |
 |
 |
若干ですが、Edge Filterによってくっきりしていることが分かります。輪郭抽出の手法として、Sobel FilterとLaplacian Filterを適用してみましたが、こちらは多くの情報が失われる可能性が高く、このような自然画像に対しての適用は不向きのように感じます。Edge Filterによって対象の物体をよりカプセル化(際立たせること)できるようなData Augmentationが実現します。
2.4.3 PatchShuffle Regularization [64]
[64] では、下の図のようにn×nのスライドウィンドウ内の画素値をランダムに入れ替えるカーネルフィルタを用いて実験を行っています。
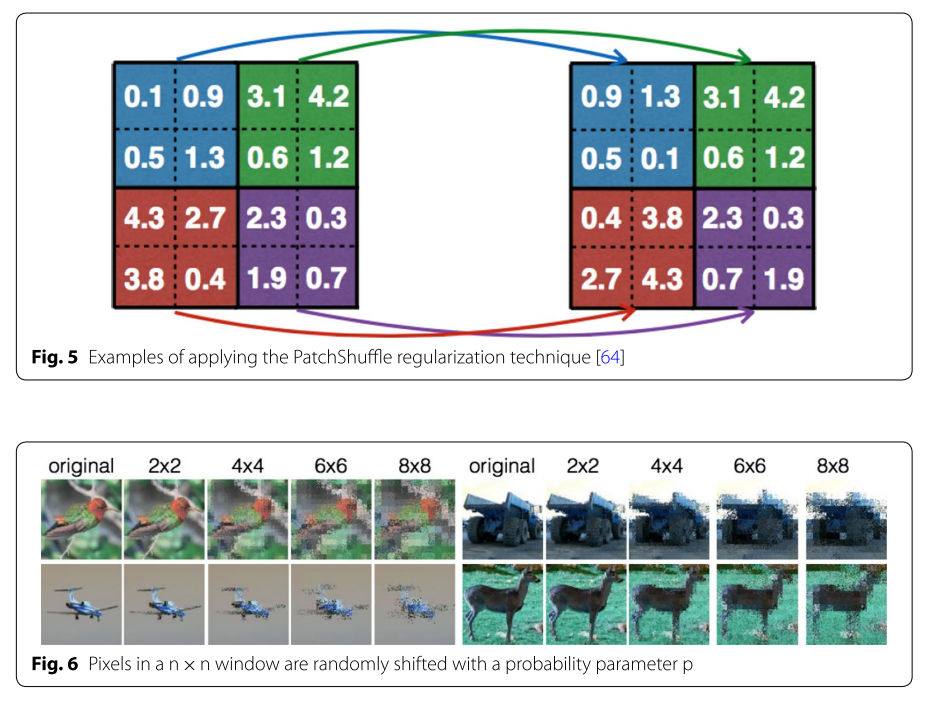
CIFAR-10データセットを用いて、nを2、4、6、8と変化させたときの結果が示されています。実験よりerror rateが6.33%から5.66%に低下したことが報告されています。
2.4.4 Kernel Filtersのまとめ
Kernel Filtersの研究は未開拓な分野のようです。
なぜかというと、CNNがその代わりやそれ以上の性能を持っているからです。
CNNは、Kernel Filterを学習データに合わせて最適化する仕組みです。
そのため、上記で紹介したような固定のKernel Filterを適用するまでもないことが多いということです。
2.5 Mixing Images
Mixing Imagesでは、複数の画像を混ぜ合わせることでData Augmentationを行います。
| Data Warping Augmentation | Oversampling Augmentation |
|---|---|
| Geometric Transformations | Mixing Images |
| Color Space Transformations | Feature Space Augmentations |
| Kernel Filters | Generative Adversarial Networks (GANs) |
| Random Erasing | - |
| Adversarial Training | - |
| Neural Style Transfer | - |
本論文では、SamplePairing、Non-linear Methods、Random Image Cropping and Patching (RICAP)が取り上げられていました。
これらの手法について説明をしていきます。
2.5.1 SamplePairing [65]
SamplePairning [65] では、対象とするデータセットの中からランダムで抽出した二枚の画像の平均画像を生成することでData Augmentationを行います。生成された画像に付与するラベルは、片方に揃えます。ランダムに抽出しているので、どっちのラベルにするべきか考えなくてよいということだと思います。
| Image 1 | Image 2 | Mixing Images |
|---|---|---|
|
 |
 |
下の図はSamplePairning [65]の概要ですが、Croppingを挟んでから平均画像の生成を行っています。
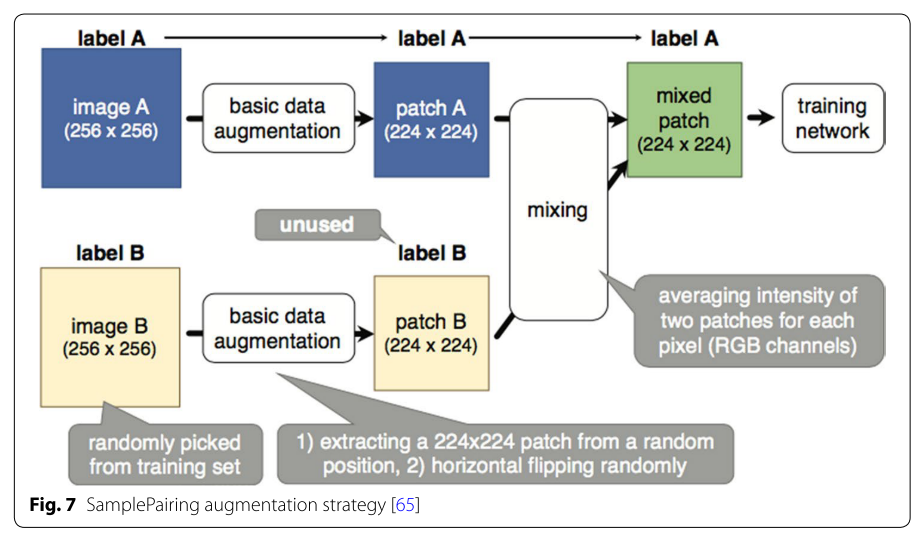
CIFAR-10データセットを用いた実験では、このData Augmentationによってerror rateが8.22%から6.93%へ減少したことが報告されています。また、CIFAR-10において各クラスの画像総数を100枚に減らしたところ、error rateは43.1%から31.0%に減少したことが報告されています。
さらに、下の図では、2枚の画像の選び方によるerror rateのぶれを示しています。
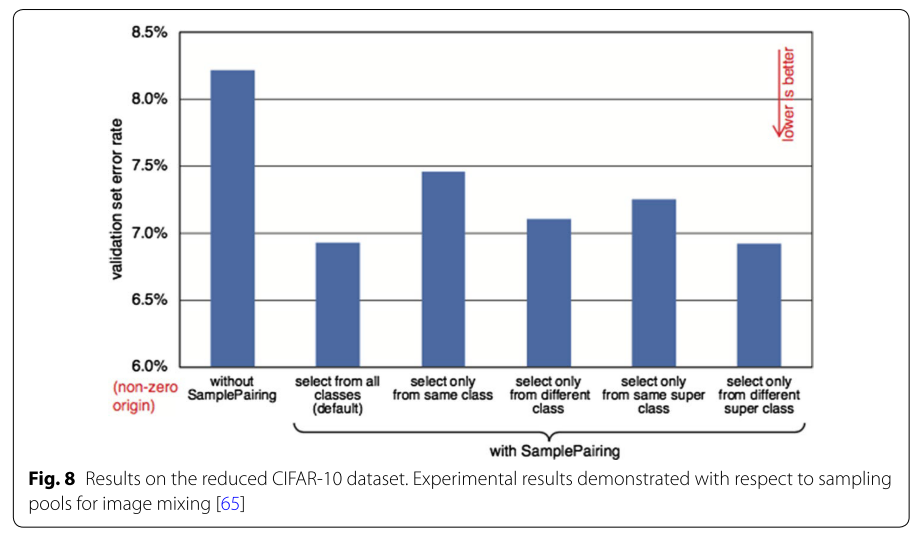
全てのクラスから抽出する場合がクラスを絞って抽出するよりも結果が良いことが分かります。SamplePairingは、他のData Augmentation手法とも組み合わせて使うことができることも良い点であると述べられています。
2.5.2 Non-linear Methods [66]
SamplePairingでは線形的な合成を行いましたが、Non-linear method [66]のように非線形的な合成を行うData Augmentation手法も存在します。

2.5.3 Random Image Cropping and Patching (RICAP) [68]
Random Image Cropping and Patching (RICAP) [68]では、まず、データセット内からランダムに4枚の画像を抽出します。次に、ランダムに領域をCroppingして、合成します。合成された画像が下の図の真ん中の画像です。
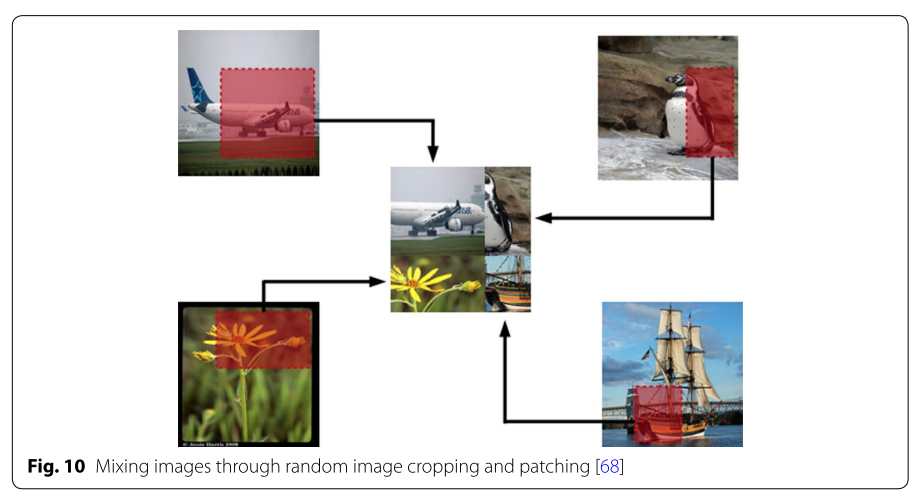
ラベルは、元画像に基づいて各領域の面積に従って付与されます。この画像だと、[Airplane, Pengin, Flower, Ship]が[0.4, 0.25, 0.25, 0.25]くらいでラベル付けされていることになります。
2.5.4 Mixing Imagesのまとめ
Mixing Imagesの欠点は、人間が合成された画像を見たときに、ほとんど意味が分からないことです。画像を合成することで得られる精度の向上は、理解や説明が非常に難しいものです。これは、データセットのサイズが大きくなったことで、線や辺などの低レベルの特徴をよりロバストに表現できるようになったことが1つの説明として考えられます。
その他にも、Mixing Imagesの手法として、mixupなどの有名なData Augmentation手法が存在します。mixupに関しては、こちらで解説をします。
2.6 Random Eracing [70]
Random Eracing [70]では、画像の一部分をランダムに消したり(輝度値を0もしくは255に変換する)、ごま塩ノイズに変更するData Augmentationです。画像内で、オクルージョン(物体が重なり合っている時など)に有効とされています。

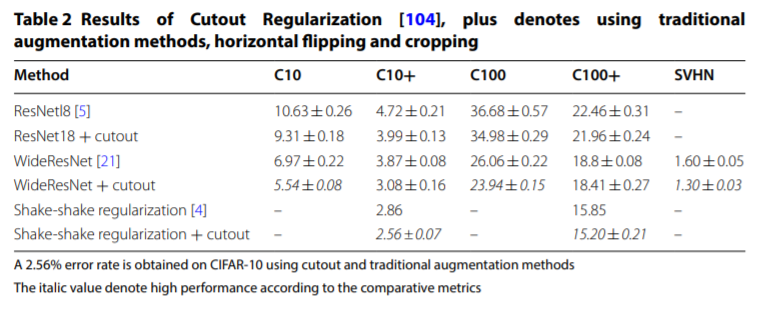
上の図では、消す領域もランダムですが、Cutout [71]という手法では、その領域と比率を固定しており、精度向上が確認されています。
これらの手法で注意しなければいけない点としては、データセットによっては人手の処理が必要になるということです。たとえば、手書き数字のMNISTデータセットでは、6と8の一部分は同一であり、消す領域によっては違う数字であっても同じような画像を作ってしまいます。また、Stanford Carsデータセットでは、車のロゴマークなどを消してしまうと,直接的に精度低下を引き起こしてしまいます.
2.6 Data Augmentationの組み合わせに関して
今までで紹介してきたData Augmentation手法を組み合わせることで、データ量を飛躍的に増加させることが可能となる.しかし、組み合わせればよいというわけではなく、データをよく観察し、適切なData Augmentation手法を選択していく必要は不可欠となります.
3 まとめ
本記事では、深層学習のための Image Data Augmentation(1:基本的な手法)と題して、A survey on Image Data Augmentation for Deep Learningで紹介されている基本的なData Augmentation手法を中心に説明を行いました。深層学習を用いたData Augmentation手法、メタ学習を用いたData Augmentation手法は以下の続きの記事で紹介しています。気になる方は是非ご覧ください。
- 深層学習のための Image Data Augmentation(1:基本的な手法)←本記事
- 深層学習のための Image Data Augmentation(2:深層学習を用いた手法)
- 深層学習のための Image Data Augmentation(3:メタ学習を用いた手法)(準備中...)