0. 本記事の概要
前回の記事では、A survey on Image Data Augmentation for Deep Learningで紹介されている基本的なData Augmentation手法を中心に説明を行いました。今回の記事は、深層学習を用いたData Augmentation手法に焦点を当てて、説明を行いたいと思います。
- 深層学習のための Image Data Augmentation(1:基本的な手法)
- 深層学習のための Image Data Augmentation(2:深層学習を用いた手法)←本記事
- 深層学習のための Image Data Augmentation(3:メタ学習を用いた手法)(準備中...)
1. 深層学習を用いたData Augmentation手法
今回は、下の図のDeep Learning Approachesに焦点を当てて説明を行います。
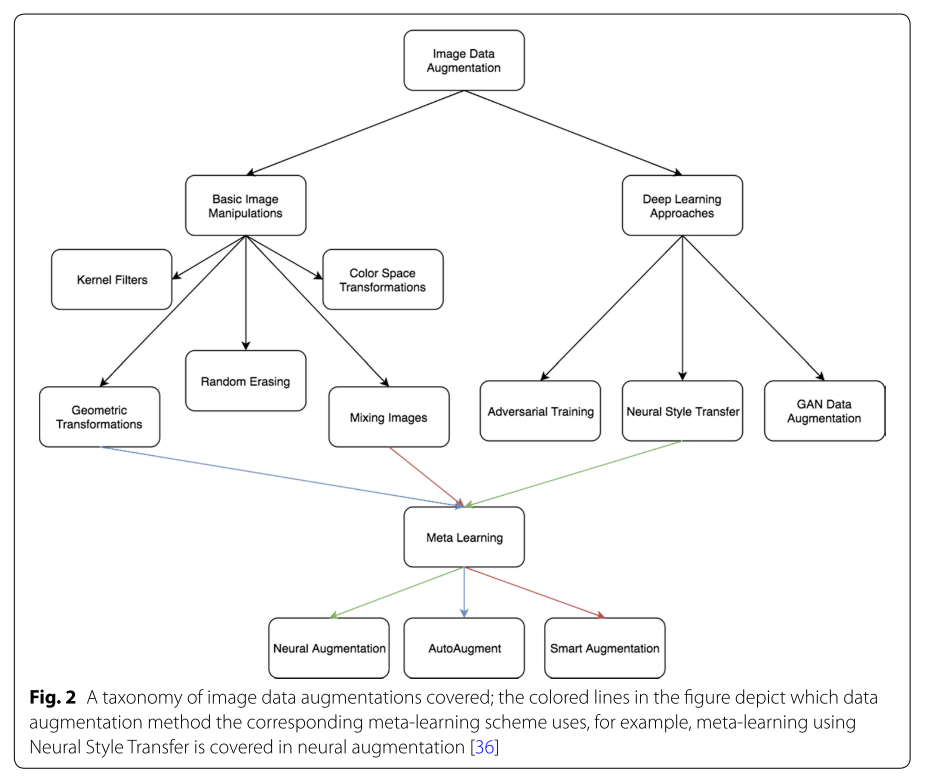
前回の復習になりますが、「Data Augmentation」の手法は様々存在する中、大きく2つに分けられます。
1. Data Warping Augmentation : データのラベルを保持しつつ加工を行うことで増強
2. Oversampling Augmentation : データから新しいデータを生成することで増強
つまり、「加工」するか「生成」するかで分けられています。
| Data Warping Augmentation | Oversampling Augmentation |
|---|---|
| Geometric Transformations | Mixing Images |
| Color Space Transformations | Feature Space Augmentations |
| Kernel Filters | Generative Adversarial Networks (GANs) |
| Random Erasing | - |
| Adversarial Training | - |
| Neural Style Transfer | - |
今回Deep Learning Approachesとして扱う手法は、「加工」からはAdversarial TrainingとNeural Style Transfer、「生成」からはFeature Space AugmentationsとGenerative Adversarial Networks (GANs)となります。
1.1 Feature Space Augmentation
Feature Space Augmentationについて説明を行います。
| Data Warping Augmentation | Oversampling Augmentation |
|---|---|
| Geometric Transformations | Mixing Images |
| Color Space Transformations | Feature Space Augmentations |
| Kernel Filters | Generative Adversarial Networks (GANs) |
| Random Erasing | - |
| Adversarial Training | - |
| Neural Style Transfer | - |
Feature Space Augmentationでは、Neural Networkによりマッピングされる低次元ベクトルに対してAugmentationを行います。Neural Networkを通して、低次元ベクトルへと変換されているデータであればAugmentationが可能なため、画像だけではなく様々なデータに適用可能性があるのが利点です。
本論文では、以下の2つの手法に関して言及がされていました。
以下でそれぞれの手法について説明を行います。
1.1.1 Icing on the Cake [74]
Icing on the Cakeとは洒落た名前ですが、手法のどこかの頭文字をとっているわけではなく、「Icing on the Cake」の英訳「花を添える喜び」から来ているそうです。Dataを花というあたり、洒落てるけど何か悟ってそうですね。ちなみに著者は日本人の方でした。

こちらは元論から引用した図ですが、手法自体はシンプルのように見えます。各ステップは以下のようになっています。

まずは通常通りDNNを学習します。
次に分類層直前の特徴ベクトルを取り出します。
さらにこの特徴ベクトルのみを用いて再学習します。
最後に再学習した分類器を元のDNNに付けなおします。
この手法のいいところは、

簡単にトライできる。
再学習に時間がかからない。
でした。
CIFAR-100に対して、ResNetを適用した実験では、しっかりと精度向上が確認されています。

1.1.2 Dataset Augmentation in Feature Space [75]
この手法では、LSTM-autoencoderを用いて得られた特徴ベクトルに対して
(a) ガウスノイズ付与
(b) Interpolation(補間)
(c) Extrapolation(外挿)

上の図において、(a)では$c$にガウスノイズの付与を行います。また、(b)と(c)では、$c$と$c_k$に対して、InterpolationおよびExtrapolationを行います。$c_k$とは、$c$の近傍点のことで、元論では$k=3$としています。InterpolationとExtrapolationの違いは、こちらのサイトでわかりやすく説明されていました。
下の図は、InterpolationによるData Augmentationの例です。

LSTM-autoencoderを使用している手法であり、画像だけでなく時系列データなどにも適用可能ということが示唆されます。

上の表は、MNISTよCIFAR-10に対してExtrapolationによるData Augmentationを行った際の精度向上を示しています。
1.1.3 Feature Space Augmentationのまとめ
Feature Space Augmentationの利点としては、autoencoderの利用によりデータの生成が容易にできる点やナイーブベイズやsupport vector machine (SVM)などの機械学習手法にも特徴ベクトルをそのまま用いることができる点です。欠点としては、特徴ベクトルの解釈が難しい点や計算時間の問題が挙げられていました。また、画像に対して直接Data Augmentationができる場合は、そちらの方が良いという報告もされているようです。
1.2 Adversarial Training
Adversarial Trainingは、Adversarial Examplesという、モデルに誤認識させるデータを使って、モデルの頑健性を向上させようという考え方です。論文では、下の代表的な画像で例が紹介されています。

これは、"panda"(パンダ)の画像に"nematode"(.007×なのでとても小さいノイズ)を加えると、"gibbon"(テナガザル)と誤分類される例です。このようなAdversarial Examplesを使って学習を行うことで、人間が直感的に気付きにくい部分のData Augmentationが実現し、モデルの頑健性が向上します。この例の手法は、Fast Gradient Sign Method [81]としてGoogfellowらによって提案されています。以下では、Adversarial Trainingの考え方で成り立つ代表的なその他の手法をいくつか紹介します。
1.2.1 DeepFool [77]
DeepFoolは、上で紹介したFast Gradient Sign Method [81] よりも小さなノイズを入れます。下の図の上側がDeepFool、下側がFast Gradient Sign Methodの元画像とノイズの例です。この手法でのノイズの入れ方は、分類境界からの距離に基づいて決められるそうです。

データ$x_0$があるとき、分類境界を超えるように移動させることができれば、誤分類を起こさせるサンプル(Adversarial Examples)を作ることができます。

ここの移動の部分だけで良いので、ノイズが少なくなると解釈しています。
下の例では、"lionfish"の画像に、人間の目には確認できないようなノイズを入れるだけで、"hen"(にわとり)と識別されていることが分かります。

1.2.2 One Pixel Attack [78]
One Pixel Attackdは、たった1ピクセルですが、変化を与えることで誤分類を起こすというものです。下の図では、黒文字が元のクラス、青文字が1ピクセル変化(画像中に見える小さな点)させた後のクラスとその確率値です。

たった1ピクセルの違いで、これだけ分類結果が変わっていることからも、これらのモデル(AllConv、NiN、VGG)の頑健性の低さが示唆されます。この手法では、差分進化(Differential Evolution)という考え方を利用して、より少ない変化で、より多くの種類のネットワークを誤分類させることを実現しています。実験結果より、CIFAR-10データセットの画像の67.97%とImageNetデータセットの画像の16.04%が、わずか1ピクセルを修正するだけで、平均74.03%、22.91%で誤分類することを確認しています。
1.2.3 DisturbLabel [84]
DisturbLabelは、入力画像ではなく、ラベルに変化をもたらそうという手法です。敢えて誤ったラベルで学習を行うことで、過学習を防ぐことが狙いです。

上の図では、MNISTデータセットでの学習の際に、各バッチごとにラベルをランダムに変更しています。こんなんでうまくいくのかという感じがしますが、実験では、以下のように、MNISTデータセットとSVHNデータセット(いずれも数字に関するデータセット)で誤り率の低下が確認されています。
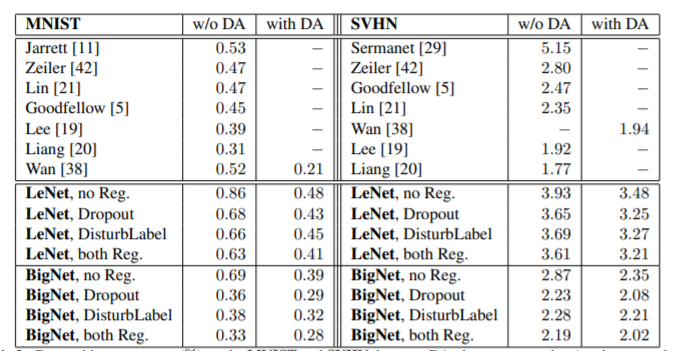
1.2.4 Adversarial Trainingのまとめ
ここまで、Adversarial Trainingとして、入力画像に対して変更を加えるAdversarial Examplesに関する手法、ラベルを変更する手法について説明を行いました。いずれもCNNの弱点を突くような手法が目立ち、それぞれモデルの頑健性にの向上を目標としています。その他の手法としては、Adversarial Trainingの損失関数に歪みを抑制する新たな項を加えることで、頑健性の高いモデルを学習しようという手法[83]もあるようです。
1.3 GAN based Data Agmentation
Generative Adversarial Network (GAN)は、Data Augmentationへの応用として期待されています。Bowlesら[85]は、GANをデータセットから新たな情報を「解き放つ手段」として説明しています。GANは計算速度が速いにも関わらず、良質な結果をもたらすことから注目を集めています。同じ生成モデルの1つとしてVariational Auto-encoder (VAE)があります。VAEは、入力画像(入力特徴)をガウス分布が仮定された低次元空間で表現します。GANとVAEを組み合わせることで、さらなる精度向上も報告されています[31]。
GAN[31]は、敵対的生成ネットワークと呼ばれ、下の図([A Beginner's Guide to Generative Adversarial Networks (GANs) | Skymind]より引用)のように、Disciriminatorに本物と識別させようと、本物に近い偽物を生成しようとするGeneratorと、本物と偽物を識別しようとするDiscriminatorから構成され、これらを敵対的に学習します。詳しくは、他のサイトなどを眺めてみてください。
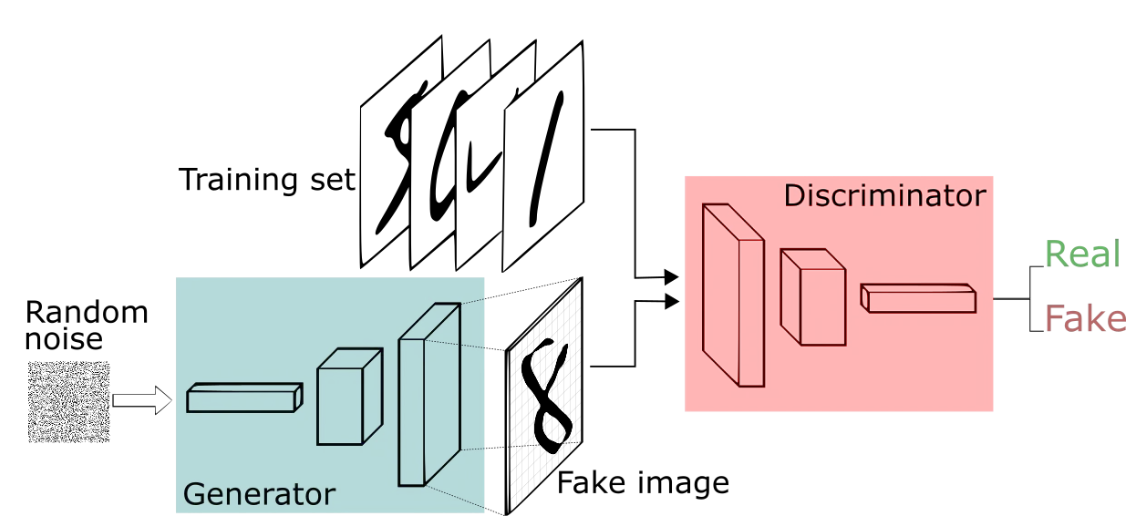
GAN[31]におけるGeneratorとDiscriminatorのネットワークには、多層パーセプトロン(MLP)が採用されています。MLPでは、MNISTデータセットのように、低次元(28×28×1)なデータに対しては十分な結果をもたらします。しかし、ImageNetデータセットやCIFAR-10データセットでは、画像サイズが256×256×3程度あり、約250倍のピクセル数になります。このような高解像度な画像の生成を可能とする拡張手法として、Deep Convolutional GAN (DCGAN)[91]、Progressively Growing GAN (PGGAN)[34]、CycleGAN[92]、Conditional GAN[95]などが提案されており、これらはData Augmentationへの応用が期待されています。これら手法をベースとしたData Augmentation手法を以下で説明していきます。
1.3.1 DCGAN [91]
DCGAN [91]は、GeneratorとDiscriminatorの内部複雑性を拡張するために提案されたアーキテクチャです。DCGANでは、下の図のように、MLPではなくCNNを使用します。この構造は、より高解像度の画像を生成することを可能とします。

Frid-Adarら[49]は、DCGANを利用して、肝病変の医療画像のData Augmentationを行い、その有効性を確認しました。

具体的に、上の図のようなネットワークを構築するし、Data Augmentationを行うことで、感度78.6%、特異度88.4%を感度85.7%、特異度92.4%まで上昇させました。これは、冒頭で話したコロナウイルスの件にも応用できそうです。
1.3.2 PGGAN[34]
PGGANの概要図は下のようになっています。

PGGANでは、低解像度の画像から学習を始め、層を追加していくことで徐々に画像の解像度を上げていきます。 層を追加する際、ランダム要素が強く働き、Generatorの出力が安定しません。 そこで、PGGANでは下の図のように、追加した層の影響度を段階的に増やす方法をとっています。

この方法によって、学習が安定化します。論文内では具体的なData Augmentation手法は紹介されておりませんでしたが、調べたところ、胃炎画像や脳のMR画像に適用する手法が提案されていました。
1.3.3 CycleGAN[92]
CycleGAN[92]は、各ドメインの分布を学習し、スタイル変換を行う際に、1対1のペア画像を必要とせず、さらにタスクに合わせて学習方法を変える必要がない手法です。詳しくは、以前にこちらの記事で紹介と実装を行っています。Data Augmentationを行う手法として、感情分類のタスクにおいてこのCycleGANを用いる手法[93]が提案されています。

この手法では、感情認識用のデータセットである、FER2013[94]を用いて、不均衡データ(怒り、嫌悪感、恐怖、幸せ、悲しみ、驚き、中立)を解消するためにData Augmentationを行っています。ここでCycleGANは、下の図で表されるように、オーバーサンプリング(サンプル数を増やすため)に用いられています。

実験では、分類精度が5~10%上昇していることが報告されています。下の図は、t-SNE[87]によって二次元空間に落とし込み可視化を行ったものです。a、b、c、dでそれぞれData Augmentationの条件を変えていますが、対象のラベルの分類境界がはっきりしていることが分かります。

1.3.4 Conditional GAN[95]
Conditional GANは、下の図のように、ノイズデータ(z)だけではなく、条件データ(y)も与えながらGANの学習を行います。これにより、Conditional GANでは、特定の条件のデータの生成を実現します。ここでの「条件」はクラスラベルやテキストデータであることが多いですが、特に縛りはないので、他のデータでも適用可能です。
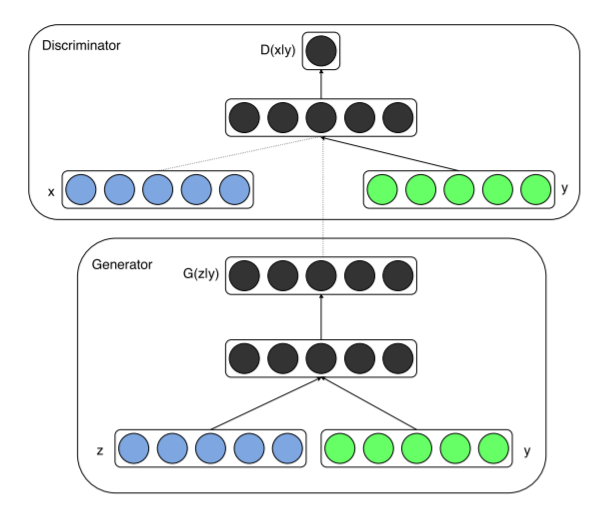
Pix2Pixは、画像データに対してConditional GANを導入した代表例です。Conditional GANを用いたData Augmentationとしては、CT画像や音声データに適用される例もあります。様々なデータに適用可能ということから、分野を選ばず、Conditional GANの応用が期待されます。
1.3.4 GAN based Data Agmentationのまとめ
GANの適用可能性に期待が持てますが、現時点では、高解像度の出力を得ることの困難さが課題として挙げられています。Generatorが生成する画像の出力サイズを大きくすると、学習が不安定になり、変換がうまくいかない可能性があります。また、GANは、学習データを大量に必要とします。Data Augmentationを行う前の元のデータセットによっては、GANは良い解決策になり得ないと思います。Salimansら[99]は、GANの学習に関する問題点をより詳細に説明しています。こちらの文献も参照することで適切なData Augmentation手法の選択ができるかもしれません。
1.4 Neural Style Transfer
Neural Style Transferとは、画風変換と呼ばれ、ある画像のスタイルを〇〇風に変換するような技術です。具体的には下の図(CycleGAN[92]の文献より引用)のように、写真をモネ風、ゴッホ風、セザンヌ風、浮世絵風に変換するような処理のことを指します。

GAN based Data Augmentationの節でも紹介したCycleGAN[92]は、Neural Style Transferの代表例です。GAN based Data AugmentationでのCycleGANは顔画像へ適用されており、画風変換とは違った意味合いを持つので、そちらで紹介されていたのだと思います。以下では、Neural Style Transferを用いたData Augmentation手法として、Style Augmentation[103]、Domain Randamization[104]、Playing for Data[106]について説明を行います。
1.4.1 Style Augmentation[103]
Style Augmentation[103]は、こちらの文献のStyle Transfer手法をもとに、下の図のように、色、テクスチャ、コントラストのスタイル変換をData Augmentationとして用いています。この際、スタイル画像をPainter by Numbersデータセットからランダムに抽出して用いております。


実験では、Style Augmentationと従来のData Augmentation手法を組み合わせることで精度向上を確認しています。

この手法は、ドメインシフトに対するロバスト性を大幅に向上させ、ドメイン適応に代わるシンプルでドメインに依存しない代替手段として使用できると言われています。
1.4.2 Domain Randamization[104]
この論文では、物体(撮像されている)をロボットで掴むという動作のシミュレーションを目的とした画像のData Augmentationを行います。イメージは下の図です。

照明の位置・数、カメラの位置・視野・向き、テーブル上の物体の数・形状、画像に付与するノイズなど、様々な条件をランダムに設定することでData Augmentationを行います。Data Augmentationによってシミュレーションの精度向上を確認した初めての論文といわれています。これらの画像から深層学習を用いて実現するロボット制御では、誤差1.5cm以内(物体検知)の精度を達成しています。
1.4.3 Playing for Data[106]
セマンティックセグメンテーションタスクにおけるアノテーション作業は、一枚の画像に一つのラベルを付与するアノテーションとは違い、ピクセルレベルでの領域アノテーションが必要となり、領域のクラス数が増えれば増えるほど労力が莫大となります。これは深層学習を行う上で大きな外壁となり、"curse of dataset annotation"(アノテーションの呪い)と呼ばれています。ここで、Playing for Data[106]では、Grand Theft Auto V(グラセフ5)のゲーム画像を用いて画像とその領域アノテーションのData Augmentationを行います。

最近のゲームは実に写実的で、現実との区別もつかなくなってきています。領域アノテーションは、detouringと呼ばれる技術を使って取得しているようです。

かなり細かい領域までのアノテーションが正確にできます。個人的には、このData Augmentationは、かなり理にかなっているなという気がしました。CamVidデータセットやKITTIデータセットを用いだ実験で、精度向上が確認されました。
(上:Camvidデータセット、下:KITTIデータセット)


さらに、1枚の画像に60~90分かかると言われている領域アノテーション作業をこの手法では、約7秒(49時間/25,000枚)のオーダーまで短縮することを可能としました。ゲームだから取得できるデータ、車に人が轢かれる映像なんかはこういうゲームを使うと深層学習の適用ができ、交通×AIが発展するのでは、と私は思います。
1.4.4 Neural Style Transferのまとめ
Neural Style Transferは非常に魅力的で、可能性を感じるData Augmentation手法です。しかし、Neural Style Transferの欠点は、画像の画風変換を行う際のスタイル画像を選択の難しさです。このスタイル画像の選び方を失敗すると、データセットにかえってバイアスを与えてしまいかねません。このような問題を考慮しながら、他のData Augmentation手法と組み合わせたりし、様々なタスクに応用していくことが大事です。
2 まとめ
本記事では、深層学習のための Image Data Augmentation(2:深層学習を用いた手法)と題して、A survey on Image Data Augmentation for Deep Learningで紹介されている深層学習を用いたData Augmentation手法を中心に説明を行いました。基本的な手法Data Augmentation手法、メタ学習を用いたData Augmentation手法は以下のの記事で紹介しています。気になる方は是非ご覧ください。
- 深層学習のための Image Data Augmentation(1:基本的な手法)
- 深層学習のための Image Data Augmentation(2:深層学習を用いた手法)←本記事
- 深層学習のための Image Data Augmentation(3:メタ学習を用いた手法)(準備中...)