#★参考
#❒本記事の目次
1.自己紹介:AIデータ分析を学ぶ理由
2.Aidemy(データ分析3か月コース)学習スケジュール
3.成果物として題目【中古自動車価格の予想モデルの作成】を選んだ理由や背景
4.データ分析~モデル作成と考察~
5.まとめと今後の活動
#1.自己紹介:AIデータ分析を学ぶに至った背景
当方、新卒で自動車関係の文系職種に就く、今年30歳となるサラリーマン。
普段の職場はプログラミングとは程遠く、アナログな業務も多い中、
エクセルで大量のデータを処理、分析することに多くの時間を費やし、計画や企画の検討を行っている。
その時間を費やすことに問題意識もなく、必要なものだと思っていたが、
部署移動に伴い、エクセルでマクロを使用する機会があり、業務の自動化に触れ、独学でPythonを学び始めた。
自動化や処理速度UPによる生産性の向上を行い、
限りある時間を付加価値のある行動に費やす投資的な考えが10年後大きな差になると思い、プログラミングを活用したいと思った。
プログラミングのレベル感としては以下の通り。
プログラミングレベル:使用できる言語はPython,VBAを多少。学習歴1年ほど。独学で基本文法を学び、
プロゲートのPythonコースを受講。仕事上で書類作成の自動化などを行う。
読んだ本や参考Web:Python1年生、Python2年生、Progate、その他業務自動化のためのWeb参考
保有資格:Python 3 エンジニア認定基礎試験 2021年3月合格
Pythonが昨今話題のAIを開発・活用するのに適した言語であることを知り、
今後の自分の能力開発/生涯学習のためにも本格的に学びたいと考えるようになる。
Aidemy受講期間:2021年5月3日~8月3日
自身の目標:様々なデータを業務の企画立案へ活かすこと。また、AI活用やデータ分析を通しての新たな付加価値の創出を行う。これは本業だけでなく、普段の暮らしの中でもデジタル化に伴うデータを分析し、AI活用することで客観的な判断や問題の可視化を行い、創造的に楽しみながら自身の技能を高めていきたいと思う。
想定読者:プログラミングに興味があり、新しいことを学びたいと考えている社会人の方
文系学部出身でもAIやデータ分析スキルを学び、使いこなすことで仕事に大きな付加価値を生むことができる。
学び続ける意欲と習慣さえあれば、仕事スキルの差別化ができる。
様々な業界業種で新しい創造的な工夫やビジネスを生み出す人と共にプログラミングを楽しみたい。
#2.Aidemy(データ分析3か月コース)学習スケジュール
1か月目・・・Python基礎や各種ライブラリの学習
→Pythonの基本文法は資格取得や独学で学んでいたため、さらさらと復習するような流れでGW連休中にざっと進める。
2か月目・・・データ前処理や機械学習、ディープラーニングの項目を学び進める。
→コースを一読してコードを実行するだけでは十分理解できているとは程遠いと感じながらも全体を把握するように心がけ、後で添削問題を行う際に復習や学びなおしを何度も行った。
後々使用するテクニックや確認プロセスのコード等はその意味を理解して使用することが大切であると非常に思う。
本業が忙しくなり、休出もあったたため、平日は1~2時間、休日は3時間程度の学習時間を確保していた。
3か月目・・・Kaggleデータ分析やTwitteの感情分析、ブログ作成
→プライベートや本業が忙しいこともあり、中々時間が取れず、理解が追いつかない部分が非常に多かった。終盤のコースは集大成の為、コードの目的が分からないときは過去のコースに戻り学び直す事でより力になると思う。
主に開発環境は以下の通り
【使用環境】
言語:Python3
PC :HP ENVY x360 convertible ※タッチもできるのでコード見るときに便利 楽天スーパーセールで購入
ブラウザ:Windows10-Chrome
開発環境:Colaboratory
開発環境構築は最も初心者が躓くところだと個人的に思っている。
何とか自分のローカル環境を組み立てたかったが、
そんなことに時間を使いたくなかったので、結局colaboratory上で開発した。
いまだに個人使用としてanacondaかVSコードを使用しようか迷っているが、
colaboratoryはライブラリのインストールも簡単で至れり尽くせりでとても便利である。
デスクトップ等ローカルにあるデータをインプットする等も必要になるがそのためのライブラリもあるので4章で解説する。
※CSVのアウトプットももちろん可能なため、ローカル環境構築のやる気がほぼなくなってしまった。
#3.成果物として題目【中古自動車価格の予想モデルの作成】を選んだ理由や背景
今回は題目として【中古自動車価格の予想モデルの作成とお得な中古車の発見】を目標とした。
中古車には様々なモデルや仕様、状態等の特徴があり、それが価格に寄与している。
中古車市場においてどのような特徴が価格を決定するのに重要であるか分析し、実際にモデル作成と価格の評価を行うことでお得な中古車を見つけることができるのではないかと考えた。
また、単純に私は車が好きで特徴に関してどんなものが価格に影響するかがイメージしやすく、分析の解説などもしやすいというのがある。
データ収集と確認、分析の前にも解決したい問題への答えの仮説を立てる。
データセットの前提によるが、基本的に市場においては価格は需要と供給によって決定される。
したがって、対象が車であるという特徴を考慮して以下の仮説を立てて次章よりモデル作成、検証を行っていく。
仮説:年式が新しく、走行距離が少なく、モデルの人気度により、価格は決定される。
#4.データ分析~モデル作成と考察~
前章で決めた課題と仮説の解決に必要なデータは何かを考えながら収集~確認&仮設~モデル分析と評価~考察を行っていく。
###⓵訓練およびテストデータの取得
今回使用するデータセットはKaggleより引用した。
Kaggle:https://www.kaggle.com/adityadesai13/used-car-dataset-ford-and-mercedes?select=vw.csv
活用したデータや環境の前提条件としてはイギリス市場であることとなる。
###⓶ライブラリのインポートとデータの内容確認と仮説
colaboratoryで開発するための環境を整えていく。
#ダイアログが出てローカルからデータをアップロードできるようになる。
from google.colab import files
uploaded = files.upload()
上記のライブラリを活用することでデスクトップなどのローカル環境からのデータ使用できるようになるため、非常に便利である。
データ分析や予測モデル作成に使用するライブラリは以下の通り、
#使用するライブラリのインポート
import pandas as pd #データ処理
import numpy as np #数列計算
import matplotlib.pyplot as plt #データの可視化
import seaborn as sns #データの可視化
import mplcyberpunk #データの可視化
import io #データのインポート
import lightgbm as lgb #予想モデル作成に使用
from sklearn.model_selection import train_test_split #予想モデル作成に使用:データ分割
from sklearn.metrics import mean_squared_error #予想モデルの評価
from sklearn.metrics import r2_score #予想モデルの評価スコア
必要なライブラリをインポートしたところで、まずはPandasを中心に利用して、データの確認を行っていく。
df_car = pd.read_csv(io.StringIO(uploaded['100,000 UK Used Car Data set_all.csv'].decode('utf-8')), header=1)
df_car.columns = ['maker', 'model', 'year', 'price',
'transmission', 'mileage', 'fuelType',
'tax', 'mpg', 'engineSize']
#データの上の行をピックアップ
df_car.head()
#データ内容の確認
df_car.info()
# データ形状の確認
print('データ形状:', df_car.shape)
# 欠損値の確認
print('欠損値の数:{}\n'.format(df_car.isnull().sum().sum()))
df_car.describe()
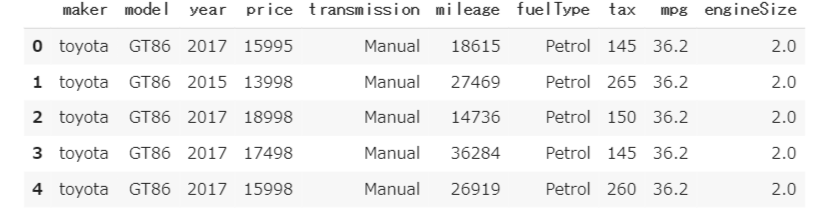
簡単な解説として、mileage:走行距離 fuel Type:燃料タイプ mpg:燃費 engineSize:排気量
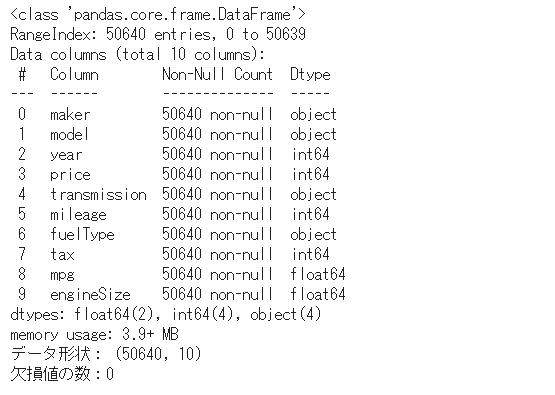
データの情報を一括で見ることができる。 50640行に10列(column)・・・サンプルの車は5万台ほどということである。
欠損値もないので今回は補完等は割愛する。
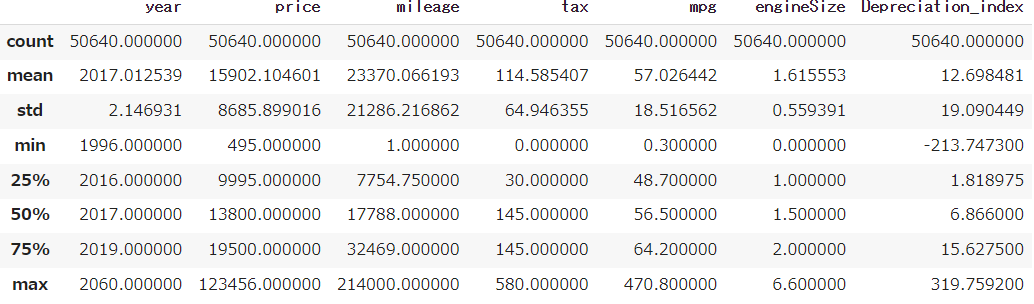
しかし、describe()で要約統計量を見ていくと
値そのものについて疑わしいものがいくつかあるため、確認していく必要があるようだ。
❒外れ値の削除・・・今回異常と感じた点を確認し、必要であれば外れ値として削除していく。
1.中古車で2060年式は2021年現在ありえないので削除していく。
#year columnの2021年以上のインデックスを出力
df_car[df_car.year >= 2021]

#外れ値の削除と確認
df_car2=df_car.drop(35244)
df_car2.query('year == 2060')

無事、異常なデータに関しては削除完了。
同様に外れ値の確認と削除を行っていく。
2.価格1200万!?車種やプレミアによってもありえなくもないが、そもそもの前提がお得な中古車を探すモデルでもあり、
結果どんだけお得であろうとも買えない!削除!
#価格1200万のインデックスを出力
df_car2[df_car2.price >= 123455]

#外れ値の削除と確認
df_car3=df_car2.drop(10375)
df_car3.query('price == 123456')

消えていることを確認。
3.税金0?580? 妥当性を確認
#税金0
df_car3[df_car3.tax == 0]
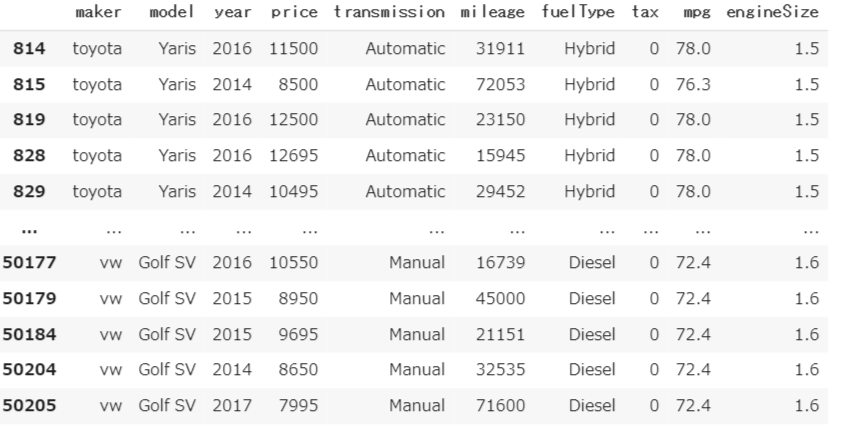
HybridやDieselなのでおそらくこれはエコカー減税的なものだろうか・・・
怪しいのでそのままにしておくことにする。
税金580
df_car3[df_car3.tax == 580]
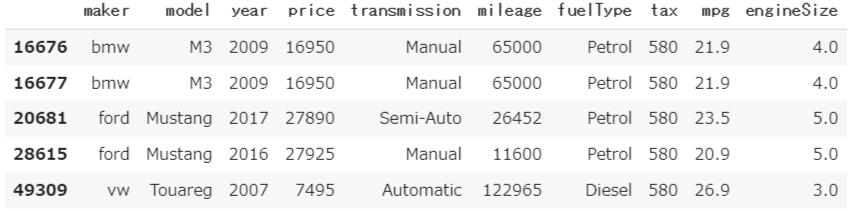
こちらは車種やエンジンサイズを見る限り、車体も大きく、排気量が多く、環境に負荷が高いため、
税金が多く掛かっているのではないかと感じる。
EUは昨今、新車種を全てEVにするという政策や事業方向性も出しているので今後は多くなりそうだ。
こちらも削除なせず、そのままにしておく。
4.燃費 470?平均とかけ離れている
#高燃費なデータの確認
df_car3[df_car3.mpg == 470.8]
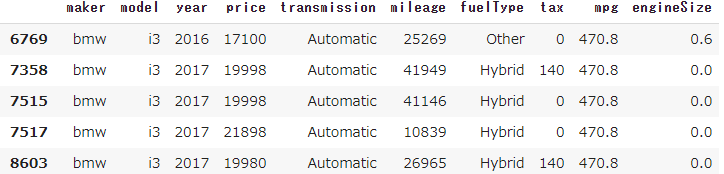
見たところBMWのi3のみと見られる。

ググってみたが問題なさそうだ。
5.エンジンサイズ 0=人力?
df_car3[df_car3.engineSize == 0]
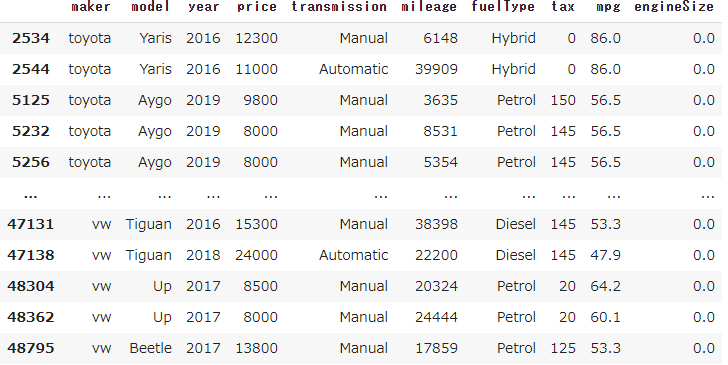
パッと見、問題なさそうだが、ガソリン車で排気量0が納得いかないので削除する。
#エンジンサイズ0のインデックスを取得して削除
df_car4=df_car3.drop(df_car3.index[df_car3['engineSize'] == 0])
df_car4.query('engineSize == 0')

完了!
次に、仮説の確認のため、カラムに対してのデータ統計を確認する。
#メーカごとのサンプル数の出力
import mplcyberpunk
gry=df_car
maker_buys= gry.groupby('maker')['maker'].count()
maker_buys = pd.DataFrame(maker_buys)
maker_buys.columns = ['Volume']
maker_buys.sort_values(by=['Volume'], inplace=True, ascending=False)
maker_buys = maker_buys.head(10)
print(maker_buys.head(20))
plt.style.use("cyberpunk")
maker_buys.plot.bar()
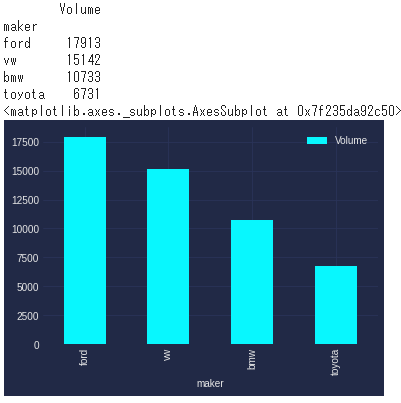
結論:UKではFordが人気 EU系メーカが強い
#サンプル数の多いモデルの出力
import mplcyberpunk
gry=df_car4
model_buys= gry.groupby('model')['model'].count()
model_buys = pd.DataFrame(model_buys)
model_buys.columns = ['Buys']
model_buys.sort_values(by=['Buys'], inplace=True, ascending=False)
model_buys = model_buys.head(10)
print(model_buys.head(20))
plt.style.use("cyberpunk")
model_buys.plot.bar()
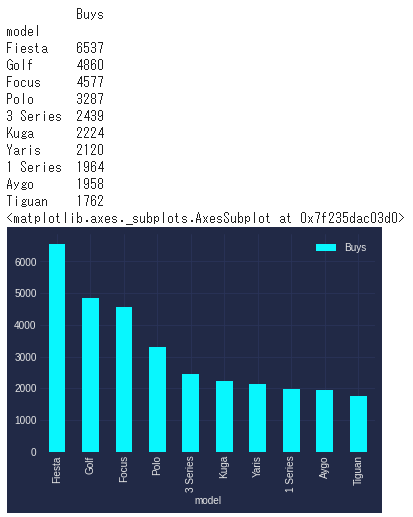
結論:モデルはFordのFiesta、VWのGolfが人気 ※ヤ〇スに似てる
#ギアボックスの種類
gry=df_car4
transmission_buys= gry.groupby('transmission')['transmission'].count()
transmission_buys = pd.DataFrame(transmission_buys)
transmission_buys.columns = ['Volume_trans']
transmission_buys.sort_values(by=['Volume_trans'], inplace=True, ascending=False)
transmission_buys = transmission_buys.head(10)
print(transmission_buys.head(20))
plt.style.use("cyberpunk")
transmission_buys.plot.bar()
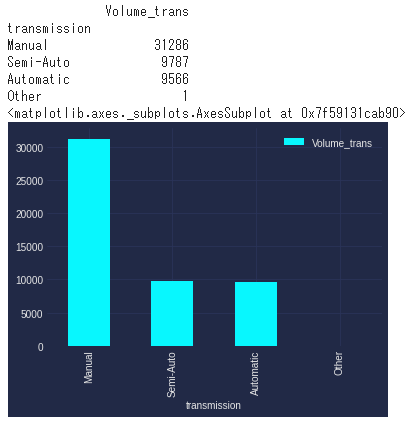
結論:Manualが主流
#エンジンタイプの種類
gry=df_car4
fuelType_buys= gry.groupby('fuelType')['fuelType'].count()
fuelType_buys = pd.DataFrame(fuelType_buys)
fuelType_buys.columns = ['Volume_fuel']
fuelType_buys.sort_values(by=['Volume_fuel'], inplace=True, ascending=False)
fuelType_buys = fuelType_buys.head(10)
print(fuelType_buys.head(20))
plt.style.use("cyberpunk")
fuelType_buys.plot.bar()
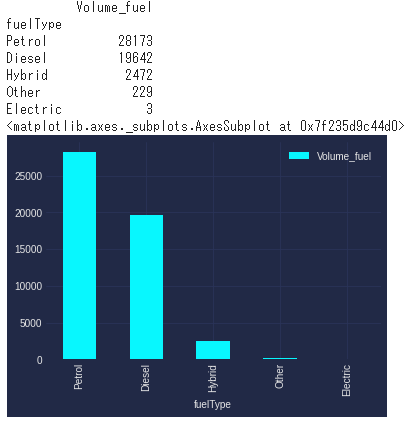
結論:ガソリンが主流、ハイブリッドは少ない ※電動化は今後大きな特徴になっていくと思われる。
#年式ごとの市場にある数
gry=df_car4
model_buys1= gry.groupby('year')['model'].count()
model_buys1 = pd.DataFrame(model_buys1)
model_buys1.columns = ['Buys']
model_buys1.sort_values(by=['Buys'], inplace=True, ascending=False)
model_buys1 = model_buys1.head(10)
plt.style.use("cyberpunk")
model_buys1.plot.bar()
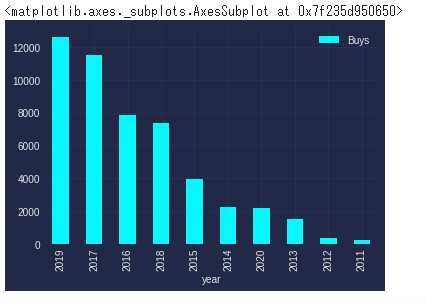
結論:2019年が多い、以外にも2020年は7位、傾向としては新しいほど人気
#年式ごとの価格平均
model_buys2=df_car
model_buys2=model_buys2[["price","year"]].groupby('year').mean()
model_buys2.sort_values(by=['price'], inplace=True, ascending=False)
model_buys2 = model_buys2.head(10)
print(model_buys2.head(20))
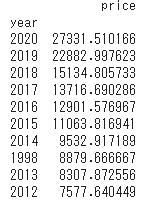
結論:年式が新しいほど価格は高いが、例外として1998年があるが、サンプル数も少ないので平均が高めに出たのかもしれない。
大まかにデータの傾向がつかめたところで特徴量ごと、特に価格への相関関係を見ていく。
df_car4.corr()
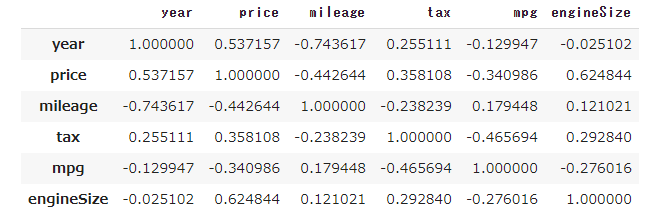
価格に対して相関関係を見るとエンジンサイズや年式は正の相関、走行距離に対しては負の相関が見られる。
よって、ここでは年式やエンジンサイズが大きいほど、走行距離が少ないほど価格は上昇傾向にあるようだ。
各特徴量のプロットデータで相関関係を可視化して分析していく。
#全体相関関係のプロット
sns.pairplot(df_car4)
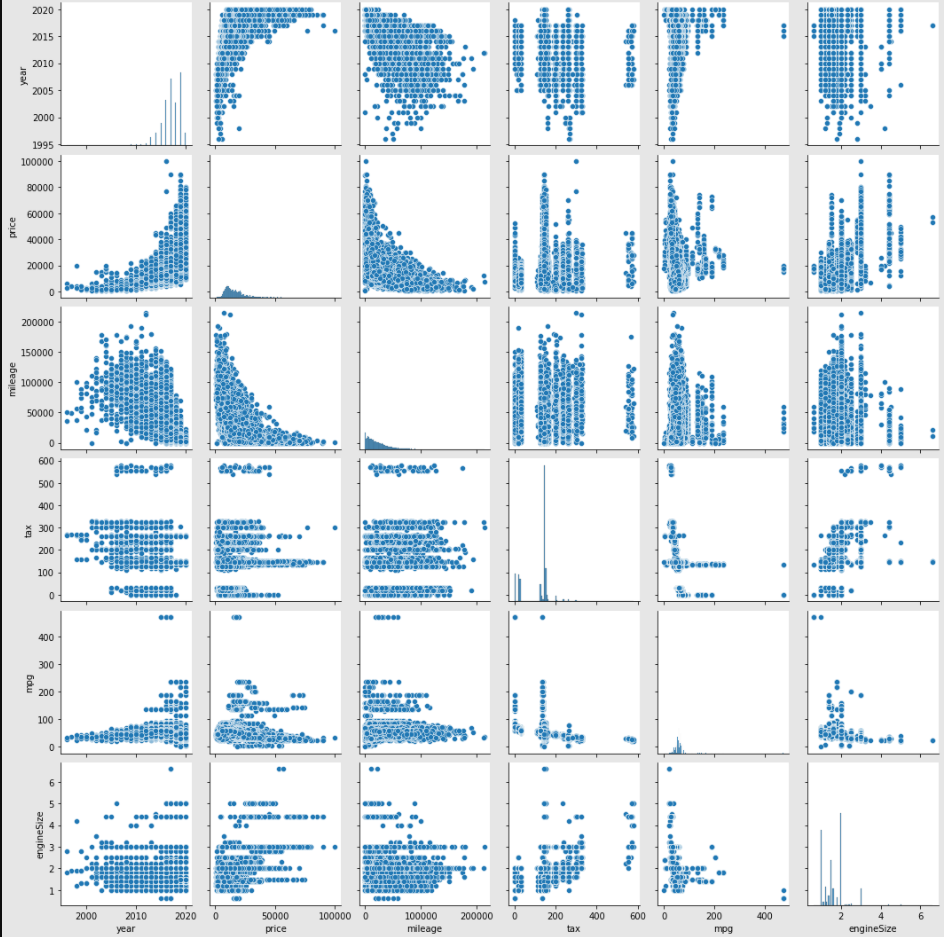
sns.pairplot()を使用することで特徴量の相関関係がプロットで可視化の確認ができる。
❒価格に言えること
・年式が新しいほど高い
・走行距離が少ないほど高い
・燃費が悪いほど高い?
・エンジンサイズが大きいほど高い?
###⓷データ分析と予想モデル作成&評価
今回が予測モデルとしてlightgbmを使用する。以下のような特徴があり、使いこなせれば役に立ちそうである。
- 欠損値をそのまま扱える
- カテゴリ変数の指定ができる
- 特徴量のスケーリングが不要
- feature importanceが確認できる
- 精度が出やすく最終的なモデルとして残る可能性が高い
- 比較的大きいデータも高速に扱える
- 過去の経験からハイパーパラメータの勘所がある
逆に汎用的過ぎてデータサイエンティストとしての力がつかないのではないかと不安ではあるが。。。
y = df_car4["price"]
#LIGHTGBMはカテゴリ値も使える・・・objectタイプをカテゴリ値へ変換
df_car4['maker']=df_car4['maker'].astype('category')
df_car4['model']=df_car4['model'].astype('category')
df_car4['transmission']=df_car4['transmission'].astype('category')
df_car4['fuelType']=df_car4['fuelType'].astype('category')
X = df_car4.drop(['price'], axis=1)
X_train, X_test, y_train, y_test = train_test_split(X, y,test_size=0.2, random_state=0)
X_train, X_valid, y_train, y_valid = train_test_split(X_train, y_train,test_size=0.2, random_state=0)
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_valid, y_valid, reference=lgb_train)
lgbm_params = {
'objective': 'regression',
'metric': 'rmse'
#'min_data_in_leaf':5
#'num_leaves':80
}
model = lgb.train(lgbm_params, lgb_train, valid_sets=lgb_eval, verbose_eval=-1, early_stopping_rounds=20,num_boost_round=1000)
y_pred = model.predict(X_test, num_iteration=model.best_iteration)
print(r2_score(y_test, y_pred) )
lgb.plot_importance(model, figsize=(12, 6))
plt.show()
y_pred
mse= mean_squared_error(y_test, y_pred)# 評価
print("LightGBM : %.2f" % (mse** 0.5))
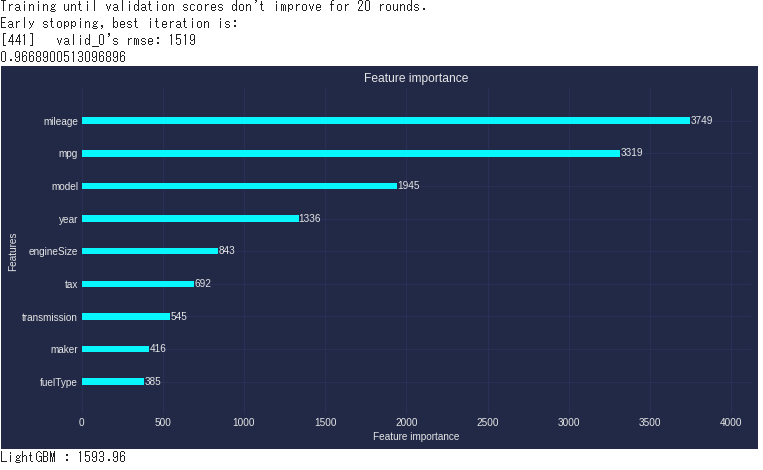
このfearture importanceは非常に便利である。
これをもとにデータの中のエラーやモデルのパラメータを調整すればモデルや結果を改善していくことができる。
###⓸予測モデルの結果に対して、仮設の検証
モデルを作成した後、そのモデルを活用して仮説を検証していく。
まずは下のコードでモデルで作成した予測値と実価格の差、差の変動率を計算していく。
df_for_search = df_car4.copy()
pred = pd.Series(y_pred,index=y_test.index, name="予測値")
df_for_search = pd.merge(df_for_search, pd.DataFrame(pred),left_index=True, right_index=True)
df_for_search['予測値との差'] = df_for_search['price']-df_for_search['予測値']
df_for_search['変動率'] = df_for_search['予測値との差']/df_for_search['price']*100
df_for_search = df_for_search[['maker','model','year',"予測値",'price','予測値との差','変動率']]
df_for_search[df_for_search['model']=='Corolla']
わかりやすいので日本の国民車ともいえるカローラを出す。
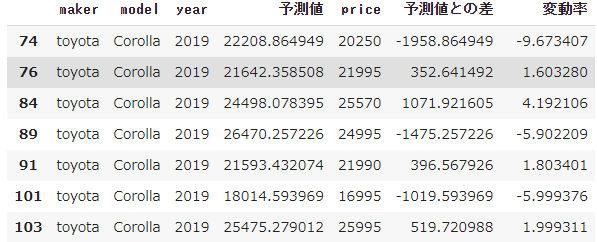
見方としては変動率が正で大きいほど割高、逆に負で小さいほど割安ということになる。
データのまとめもみていく。
df_for_search.describe()
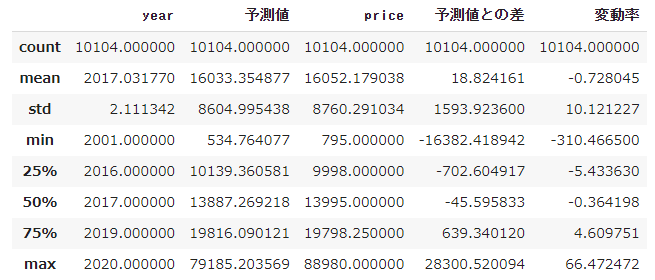
一番割安な車とは一体どんなものだろうか?
df_for_search[df_for_search.price == 795]

FordのKAである。ポンドが1ポンド200円ほどとすると、16万円。。。
df_for_search[df_for_search.変動率 >= 66.0]

割高なもの、言うなれば価値が落ちにくいともとれる。
BMWの5シリーズである。
df_car4.query('price == 1595')

変動率で出すと桁の違う安い価格帯の車が出てきてしまうので改善の余地はありそうだ。
おまけにcsvで結果をダウンロードする。
全体をさらーっと見ていくのはCSVが慣れているからである。
df_for_search.to_csv('output.csv',index=True)
from google.colab import files
files.download('output.csv')
#5、まとめと今後の活動
今回はKaggleでまとまったデータセットをもとにデータ分析を行い、中古車価格の予測モデルを作成した。
今後は中古車のwebサイトよりグレードやオプション仕様等を特徴量として活用する為のスクレイピング、データクレンジングを実施し、より問題解決や企画提案できる実用的なモデルへと拡張を行なっていきたい。
今回Aidemyデータ分析3か月コースを受講して大まかにデータ分析の流れを通して興味のある分野をプログラミングで問題解決することを行った。
結論としては、受講して良かったと感じている。
カリキュラムのステップが細かく、完全に理解していなくとも進めることで全体が見えてくるようになり、
添削課題や成果物を自分で作成しようとしたときに主体的に考えて取り組むことができる。
プログラミングというツールを使用して何を行いたいのか、主体的であることがが重要だと改めて感じている。
どんな課題を解決したいのかや何を見つけたいのかの全体ストーリーがあれば、
プログラミングは非常に強力なツールとなり、今後の学びや創造的な工夫へのモチベーションにもつながる。
様々な言語があり、向き不向きもある上、情報の更新も速いが、前向きに捉えれば、生涯学習としてこれほどできると楽しいものはないだろうとも感じている。
今後もブログ等を活用して問題解決や付加価値を見つけるためのプログラミング活用の企画を行っていきたい。
###参考文献/サイト
・Kaggleデータセット