この記事はなに
EKS+Terraform+CircleCI(+Go)な構成のアプリを作る際のインフラ周りのスターターキット的なリポジトリを作ったのですがそれの解説記事です。
元ネタは自分が以前(メインで)担当したマイクロサービスの構成で構築中/運用中に発生した種々のトラブルの問題解決を反映させています。
構成図
使っている要素技術をざっくり構成図にするとこんな感じです。

技術的なポイント/見どころ
- CircleCIからの
terraform apply及びkubeclt apply - HorizantalPodAutoscaler/ClusterAutoscalerによるオートスケール
- kustomizeによる環境ごとのマニフェストのレンダリング
インフラとして目指したい形
- システムの定常的な設定(=AWSリソース/K8sのオブジェクトなどで時間変化しないもの)の全てがコード化されている
- コードと実際のシステムの設定とが同期していることがCIによって保証されている(マネジメントコンソールやCLIからの操作は基本必要なし)
目次
Terraform関連
TerraformをCircleCIと一緒に使う場合の一般的な設定です。内容は以下のようになります。
- CircleCIから
terraform apply - tfstateはS3で管理、DynamoDBでロックを取る
- ローカルでplanの実行(docker-composeを使用)
- plan結果をPRのコメントにポスト
CircleCIからterraform apply
terraform applyは本番に近い環境の場合、CIから行うのが治安が良いと思います。
Terraformを使う設定の.circleci/config.yml
.circleci/config.ymlの中の関連する部分を紹介します。
executors:
terraform:
working_directory: ~/repo
docker:
- image: hashicorp/terraform:0.12.3
- run:
name: setup aws credentials
command: |
echo "export AWS_ACCESS_KEY_ID=$AWS_ACCESS_KEY_ID" >> $BASH_ENV
echo "export AWS_SECRET_ACCESS_KEY=$AWS_SECRET_ACCESS_KEY" >> $BASH_ENV
terraform-apply:
executor: terraform
steps:
- restore_cache:
key: terraform-{{ .Environment.CIRCLE_SHA1 }}
- setup_aws_credentials
- run:
name: terraform apply
command: |
cd terraform
terraform apply -auto-approve
tfstateはS3で管理、DynamoDBでロックを取る
tfstateはローカルではなくS3などの上で管理するのが好ましいです。
またtfstateが破壊されないようにDynamoDB上のロックを取るようにするとさらに良いです。
ここを参考にその設定を作っていきます。
Terraformの設定のコード
provider "aws" {
region = "ap-northeast-1"
version = "2.16"
}
terraform {
backend "s3" {
bucket = "terraform-backend-for-eks-sxarp"
key = "terraform"
region = "ap-northeast-1"
# tfstateに対してロックを取りつつ一貫性を維持しながら更新をかける
# Production環境の場合は使用することを推奨
dynamodb_table = "EKSSampleTfLock"
}
}
resource "aws_s3_bucket" "terraform-backend" {
bucket = "terraform-backend-for-eks-sxarp"
acl = "private"
}
resource "aws_dynamodb_table" "eks-sample-lock-table" {
name = "EKSSampleTfLock"
billing_mode = "PAY_PER_REQUEST"
hash_key = "LockID"
attribute {
name = "LockID"
type = "S"
}
}
ローカルからのplanの実行(docker-composeを使用)
ローカルからterraform planが打てるようにします。ローカルでのTerraformの管理はtfenvを使用するケースも多いですが、今回はdocker-composeを使い、簡単にplanが打てる環境を用意できるようにします。
Terraformを内包したdocker-composeの設定
services:
terraform:
image: hashicorp/terraform:0.12.3
working_dir: /terraform
command: tail -f /dev/null
volumes:
- ./terraform:/terraform
entrypoint: []
env_file: .env
.envにAWSのクレデンシャルを設定したうえで
$ cat .env
AWS_ACCESS_KEY_ID=xxxxxxxxxxx
AWS_SECRET_ACCESS_KEY=xxxxxxxxxx
docker-compose up -dして以下を打つとplanが実行されます。
$ docker-compose exec terraform terraform plan
なおMakefileにterarform-planというメニューも追加しているのでmake terraform-planを打つだけでもplanを実行することができます。
plan結果をPRのコメントにポスト
以下のようにPRにplan結果をポストするようにしています。メルカリさんのtfnotifyをありがたく使用させて頂いています ![]()
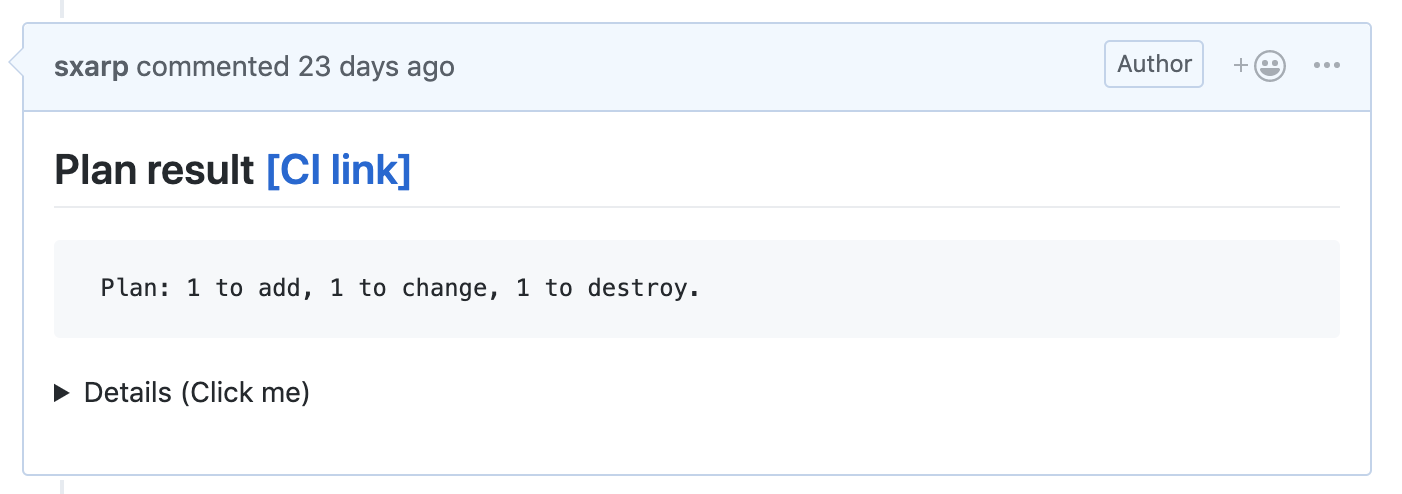
設定法はここからバイナリをダウンロードし、それを.circleci/bin/tfnotifyに配置した上で、CircleCIのここでポストしています。
K8s関連
K8s周りの設定です。
- CircleCIから
kubectl apply - kustomizeによるyamlのレンダリング
- クラスターにインストールするリソースの管理方法
- HorizontalPodAutoscalerによるPod数のオートスケール
- ClusterAutoscalerによるノード数のオートスケール
- kube-system上の重要なpodが落ちないようにする
CircleCIからkubectl apply
CircleCIからマニフェストの適用をするためにkubectlをEKSに対して使えるようにします。
kubectlをEKSに対して使うにはaws eks update-kubeconfigを打つ必要があるので、kubectlとAWS-CLIの2つが入ったCI用のイメージを用意します。
CI用イメージのDockerfile
FROM python:rc-alpine3.10
ARG CLI_VERSION=1.16.190
ARG KUBECTL_VERSION=1.15.0
# add aws-cli
RUN apk -uv add --no-cache groff jq less && \
pip install --no-cache-dir awscli==$CLI_VERSION
# add kubectl
# 最新バーションはこちらで探す:
# https://aur.archlinux.org/packages/kubectl-bin/
RUN wget https://storage.googleapis.com/kubernetes-release/release/v$KUBECTL_VERSION/bin/linux/amd64/kubectl ; \
mv kubectl /usr/local/bin/kubectl; chmod +x /usr/local/bin/kubectl
このimageをexecutorに指定して以下を打つことで、EKSに対してkubectlが使えるようになります。
$ aws eks update-kubeconfig --name terraform-eks-sample
なお、ここでAWS-CLIを使うのに指定するprofileはクラスターを作成したものと同一である必要があるので注意です(参考)。
kustomizeによるyamlのレンダリング
アプリケーションを環境ごと(develop/stagingなど)にnamespaceを切ってクラスターにデプロイする場合、kustomizeを使うとマニフェストのコピペを抑えられます。
今回の使い方としては、環境ごとに共通となるような設定をk8s/baseに置き、環境ごとに異なる(例えばstaging環境固有の)設定をk8s/staging以下に配置しています。
デプロイの際はimageの指定を以下のように行ってapplyしています。
cat <<EOF >> kustomization.yaml
images:
- name: sample
newName: $IMAGE_NAME
EOF
imageのtag指定は"kustomize edit set imageが使えたのですが、kubectlに組み込みのkustomizeだとこれが使えないのでこのようなやり方を採用しています(そして別にこれで困らない)。
なお、一般的に本番環境とその他とではクラスター自体を分けた方が良いとされているので、一つのクラスターの中に複数環境を詰め込むのは開発系だけにしましょう。
クラスターにインストールするリソースの管理方法
クラスターにインストールするリソース、例えばMetricsServerやClusterAutoscalerはk8s/cluster/以下にマニフェストを置き、CIで適宜(デプロイ時に毎回)applyしてクラスターに反映するようにしています。
クラスターをセットアップするCircleCIの設定
- run:
name: setup cluster
command: |
kubectl apply -R -f k8s/cluster/
すこし泥臭いですが、これでやっている理由は以下のようになります。
- シンプル
- クラスターに反映されているマニフェストが明確
- マニフェストの編集がしやすい
k8s/cluster配下で管理しているリソースは以下のようになります。
- HorizontalPodAutoscalerに必要なMetricsServer
- ノード数をスケールさせるClusterAutoScaler
- Podの優先度を指定するPriorityClass
- ノードをクラスターに参加させるConfigMap
HorizontalPodAutoscalerによるPod数のオートスケール
HorizontalPodAutoscalerを使ってPod数を負荷状況に応じてスケールさせます。
そのためにまずMetricsServerを導入しますが、こちらのマニフェストをそのまま持ってくると、EKSの場合以下のようなエラーが出る
`Error from server (ServiceUnavailable): the server is currently unable to handle the request (get nodes.metrics.k8s.io)`
$ kubectl top node
Error from server (ServiceUnavailable): the server is currently unable to handle the request (get nodes.metrics.k8s.io)
$ stern -n kube-system metric
....
metrics-server-6c6c6c6457-6s7ct metrics-server E0710 05:02:38.034206 1 manager.go:111] unable to fully collect metrics: [unable to fully scrape metrics from source kubelet_summary:ip-10-101-1-15.ap-northeast-1.compute.internal: unable to fetch metrics from Kubelet ip-10-101-1-15.ap-northeast-1.compute.internal (ip-10-101-1-15.ap-northeast-1.compute.internal): Get https://ip-10-101-1-15.ap-northeast-1.compute.internal:10250/stats/summary/: dial tcp: lookup ip-10-101-1-15.ap-northeast-1.compute.internal on 172.20.0.10:53: no such host, unable to fully scrape metrics from source kubelet_summary:ip-10-101-0-13.ap-northeast-1.compute.internal: unable to fetch metrics from Kubelet ip-10-101-0-13.ap-northeast-1.compute.internal (ip-10-101-0-13.ap-northeast-1.compute.internal): Get https://ip-10-101-0-13.ap-northeast-1.compute.internal:10250/stats/summary/: dial tcp: lookup ip-10-101-0-13.ap-northeast-1.compute.internal on 172.20.0.10:53: no such host]
....
のでこちらのissueを参考に以下の起動オプションを追加しました。
- --kubelet-preferred-address-types=InternalIP
また、ネットワーク的にマスターノード=>ワーカーノードでPort番号443が許可されている必要があるのでその設定もします。
443を許可するSGの設定
resource "aws_security_group_rule" "sample-node-ingress-cluster" {
description = "Allow worker Kubelets and pods to receive communication from the cluster control plane"
# cluster -> worker nodesで443が許可されてないとmetrics-serverがうまく動かない
from_port = 0
protocol = "tcp"
security_group_id = "${aws_security_group.sample-node.id}"
source_security_group_id = "${aws_security_group.sample-cluster.id}"
to_port = 65535
type = "ingress"
}
あとはHPAのマニフェストをapplyすればPod数がオートスケールされます。
HorizontalPodAutoscalerのマニフェスト
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: sample
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: sample
minReplicas: 2
maxReplicas: 20
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 15
なお、HPAを使う場合、Deploymentにレプリカ数を指定していると干渉しておかしなことになる(デプロイ時に瞬間的にPod数がゼロになる)のでレプリカ数は指定しないようにしましょう(参考)。
また、PodにResource Quotasを設定しないとスケーリングがうまく動かないので忘れずに設定するようにしましょう(設定例)。
ClusterAutoscalerによるノード数のオートスケール
ノードをオートスケールさせるやり方として、AutoScalingGroupに標準で付いているCPUやメモリの使用率でスケーリングさせる方法もありますが、今回はClusterAutoscalerを使用します。
理由としては、「Podがスケージュール不可能となったときにノード数を増やす」というシンプルなルールでスケールアウト/インを行いたいからです。
また、EKSではインスタンスタイプごとにスケージュール可能なPodの数に制限がかかっている(参考)ので、必ずしもPodがスケージュール不可=CPU/メモリ使用率が限界とはならないというのもあります。
ClusterAutoscalerの導入はここを参考にすると簡単に行なえます。基本的にこのyamlをそのまま持ってきますが、この部分だけ調整しています。
Terraform(AWS)側の設定(権限周りとタグ)は以下のようになります。
Terraformの設定
ClusterAutoScalerが動くノードに付加する権限
data "aws_iam_policy_document" "cluster-autoscaler" {
statement {
effect = "Allow"
actions = [
"autoscaling:DescribeAutoScalingGroups",
"autoscaling:DescribeAutoScalingInstances",
"autoscaling:DescribeLaunchConfigurations",
"autoscaling:DescribeTags",
"autoscaling:SetDesiredCapacity",
"autoscaling:TerminateInstanceInAutoScalingGroup"
]
resources = [
"*",
]
}
}
resource "aws_iam_policy" "cluster-autoscaler" {
name = "cluster-autoscaler"
path = "/eks-sample/"
policy = "${data.aws_iam_policy_document.cluster-autoscaler.json}"
}
resource "aws_iam_role_policy_attachment" "sample-node-cluster-autoscaler" {
policy_arn = "${aws_iam_policy.cluster-autoscaler.arn}"
role = "${aws_iam_role.sample-node.name}"
}
オートスケールの対象としてノードに付けるタグ
tag {
key = "kubernetes.io/cluster/${var.cluster-name}"
value = "owned"
propagate_at_launch = true
}
tag {
key = "k8s.io/cluster-autoscaler/enabled"
value = "true"
propagate_at_launch = true
}
kube-system上の重要なpodが落ちないようにする
落ちたら困るPod、例えばMetricsServerやClusterAutoScalerはPriorityを上げることでアプリケーションのPodよりも優先的にスケージュールさせることができます。
挙動としては、高優先度のPodがスケージュール出来ない場合、低優先度のPodを落としてスケージュールされるようになります。
If a Pod cannot be scheduled, the scheduler tries to preempt (evict) lower priority Pods to make scheduling of the pending Pod possible.
実際にオートスケールさせてみてこのような挙動は観測できましたが、長期的に頻繁にPodが停止されるような環境での確認はしていないので、より万全を期す場合、重要なPodを配置する専用のノードを用意するアプローチも良いかも知れません。
PriorityClassのマニフェスト
apiVersion: scheduling.k8s.io/v1beta1
kind: PriorityClass
metadata:
name: high-priority
value: 100
globalDefault: false
description: "This priority class should be applied for the pods which are not application pods."
---
apiVersion: scheduling.k8s.io/v1beta1
kind: PriorityClass
metadata:
name: application
value: 0
globalDefault: false
description: "This priority class is applied for application pods."
ClusterAutoScalerへのPriorityClassの適用
priorityClassName: high-priority
なおcoredns/aws-node/kube-proxyなどのビルドインで起動しているkube-systemのPodには最初から優先度2,000,000,000のPriorityClassであるsystem-cluster-criticalが割り当てられています。
coredns/aws-node/kube-proxyのPriorityClass
$ kubeclt get po -n=kube-system
NAME READY STATUS RESTARTS AGE
aws-node-ffw8g 1/1 Running 0 93m
aws-node-xrcgn 1/1 Running 0 98m
cluster-autoscaler-6d4c7bffc4-bxwv2 1/1 Running 0 19m
coredns-57df9447f5-gzmsv 1/1 Running 0 128m
coredns-57df9447f5-h58lg 1/1 Running 0 128m
kube-proxy-5n2c7 1/1 Running 0 93m
kube-proxy-7px4k 1/1 Running 0 98m
metrics-server-7896b47b65-4lgnx 1/1 Running 0 17m
$ kubectl get priorityclasses.scheduling.k8s.io system-cluster-critical -o=jsonpath={.value}
2000000000%
$ kubectl get deployments.apps coredns -n kube-system -o json | jq '.spec.template.spec.priorityClassName'
"system-cluster-critical"
$ kubectl get daemonset aws-node -n kube-system -o json | jq '.spec.template.spec.priorityClassName'
"system-node-critical"
kubectl get daemonset kube-proxy -n kube-system -o json | jq '.spec.template.spec.priorityClassName'
"system-node-critical"
AWSリソース関連
EKS関連のリソースをTerraformで定義していきます。元ネタはこちらです。内容は以下のようになります。
- ALB(IngressControllerではなくTerraform管理の)
- ワーカーノード
ALB(IngressControllerではなくTerraform管理の)
外部からのリクエストがPodに到達する経路は以下のようになります。
ALB => TargetGroup => ノードのEC2 => NodePort => Pod
この構成をEKSのIngressControllerを使うと簡単に構築できるのですが、今回はK8s以外のリソースは基本的にTerraformを使用して作成します。
理由は以下のような感じです。
- AWSのリソースはTerraformで一元管理したい
- Terraformを使った方がブラックボックス感が薄い
- Terraformで作るのは別にそんなに手間ではない
大事なのはIaCが出来ていることだと思うのでIngressControllerのマニフェストがちゃんとgit管理されているのであればIngressControllerでも良いんじゃないかなと思います。
ALB、TargetGroup、SecurityGroup(ALB => ノードを許可する)は以下のようになります。
ALBとListerner
/* ALB関連
*/
resource "aws_lb" "sample" {
name = "eks-sample"
internal = false
load_balancer_type = "application"
security_groups = ["${aws_security_group.sample-alb.id}"]
subnets = aws_subnet.sample[*].id
# access logの有効化を推奨
# access_logs {
# bucket = "${aws_s3_bucket.sample_alb_log.bucket}"
# prefix = "sample_alb_lb"
# enabled = true
# }
tags = {
Environment = "staging"
}
}
resource "aws_lb_listener" "sample" {
load_balancer_arn = "${aws_lb.sample.arn}"
port = "80"
protocol = "HTTP"
default_action {
type = "forward"
target_group_arn = "${aws_alb_target_group.sample.arn}"
}
}
SecurityGroup
0.0.0.0/0 => ALB => ノードを許可するようなSGを定義します。
0.0.0.0/0 => ALB
resource "aws_security_group" "sample-alb" {
name = "terraform-eks-sample-alb"
description = "Security group for alb"
vpc_id = "${aws_vpc.sample.id}"
egress {
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = ["0.0.0.0/0"]
}
}
ALB => ノード
resource "aws_security_group_rule" "access-from-alb" {
description = "Allow access from ALB"
from_port = 0
protocol = "-1"
security_group_id = "${aws_security_group.sample-node.id}"
source_security_group_id = "${aws_security_group.sample-alb.id}"
to_port = 65535
type = "ingress"
}
TargetGroupとNodePortとのつなぎ込み
30001番ポートでTGとNodePortとを繋ぎます。
一つのクラスタに複数のエンドポイントを生やす(例えば環境ごとに)場合、このポート番号は被らないようにする必要があります。
TargetGroupとAutoscalingGroupへのアタッチ
resource "aws_alb_target_group" "sample" {
name = "sample-target-group"
port = 30001
protocol = "HTTP"
vpc_id = "${aws_vpc.sample.id}"
health_check {
path = "/health"
}
}
resource "aws_autoscaling_attachment" "sample" {
autoscaling_group_name = "${aws_autoscaling_group.sample.id}"
alb_target_group_arn = "${aws_alb_target_group.sample.arn}"
}
NodePort、staging環境のkustomizeの中で宣言しています(環境ごとにNodePortを持つ想定)。
apiVersion: v1
kind: Service
metadata:
name: sample
spec:
ports:
- protocol: TCP
port: 80
targetPort: 8080
nodePort: 30001 # ALBのTGで指定する、各クラスタごとに固有であること
ワーカーノード
AutoscalingGroupで管理されたワーカーノードを用意します。
Launch Configration
resource "aws_launch_configuration" "sample" {
associate_public_ip_address = true
iam_instance_profile = "${aws_iam_instance_profile.sample-node.name}"
/* image_idの選び方
Kubernetesのversion:
\```
$ kubectl version -o json | jq '.serverVersion.minor'
"12+"
\```
Tokyoリージョンの1.12.*でGPUのサポートなしを[https://docs.aws.amazon.com/eks/latest/userguide/eks-optimized-ami.html]から選ぶ
*/
image_id = "ami-0a9b3f8b4b65b402b"
/*
インスタンスタイプはネットワークの性能保証があるm4系がオススメ
ネットワークが遅いとimageのpullに異常に時間がかかることがあるので
参考: https://aws.amazon.com/ec2/instance-types/
*/
instance_type = "t2.small" # microだとmetrics-serverが立ち上がらない
/*
worker nodesにsshできるようにする
worker nodes内で問題が起きる場合もあるので設定することを推奨
worker nodeのIPを特定(コンソールからも見られる):
$ kubectl get node -o json | jq '.items | map(.status.addresses) | flatten | map(select(.type=="ExternalIP"))'
ssh:
$ ssh ec2-user@IP_ADDRESS -i ~/.ssh/eks-sample.pem
kubeletのログを見る:
$ [ec2-user@ip-10-101-0-59 ~]$ journalctl -u kubelet
*/
key_name = "eks-sample"
name_prefix = "terraform-eks-sample"
security_groups = ["${aws_security_group.sample-node.id}"]
user_data_base64 = "${base64encode(local.sample-node-userdata)}"
lifecycle {
create_before_destroy = true
}
}
Autoscaling Group
resource "aws_autoscaling_group" "sample" {
launch_configuration = "${aws_launch_configuration.sample.id}"
# 0にしておくと、desired_capaciry=0でインスタンスを全部落とせる
min_size = 0
max_size = 5
lifecycle {
ignore_changes = [
desired_capacity, // Terraformではなく、CusterAutoscalerが管理する
]
}
name = "terraform-eks-sample"
vpc_zone_identifier = aws_subnet.sample[*].id
tag {
key = "Name"
value = "terraform-eks-sample"
propagate_at_launch = true
}
tag {
key = "kubernetes.io/cluster/${var.cluster-name}"
value = "owned"
propagate_at_launch = true
}
tag {
key = "k8s.io/cluster-autoscaler/enabled"
value = "true"
propagate_at_launch = true
}
}
ポイントとしては
- ワーカーノードにはsshできるようにする(トラブル発生時に
journalctl -u kubeletとか打ちたい) - インスタンスタイプはネットワークの性能保証があるm4系を使う(t2系だとimage pullが異様に遅くなることがあった)
- AutoscalingGroupのmin_sizeは0にしておくと、インスタンスを全て落とせるので開発には便利
- AutoscalingGroupのdesired_capacityはignore_changesしておく(この値はClusterAutoscalerが管理するので)
などがあります。
アプリケーションのCI/CD
アプリケーションコード(Golang)の開発/デプロイに関連する部分を紹介します。内容は以下のようになります。
- コンテナイメージのビルド/ECRへのプッシュ
- ローカル開発環境
- test/lintをCIで回す
- マルチステージビルド
- Graceful Shutdown
コンテナイメージのビルド/ECRへのプッシュ
コンテナイメージののビルドは一番お手軽なCircleCIのsetup_remote_dockerを使っています。
ビルド時間が長くなってきた場合はCodeBuildやCloud Buildを使うと良いと思います。
ECRへのイメージのpushはeval $(aws ecr get-login)してdocker pushで行えます。
.circleci/config.ymlのコード
eval $(aws ecr get-login)
- run:
name: build and push image
command: |
IMAGE_NAME=705180747189.dkr.ecr.ap-northeast-1.amazonaws.com/terraform-eks-sample/app:$(git rev-parse HEAD)
docker build -t $IMAGE_NAME app
docker push $IMAGE_NAME
ローカル開発環境(docker-composeを使用)
Dockerの中に実行環境を封じ込めることで、簡単に開発環境の立ち上げができるようにしています。
例えばテストを実行する場合以下を打つだけで済むようにしています。
$ docker-compose up -d && docker-compose exec app go test -v ./...
さらにテスト実行などよく使うコマンドをMakefileに纏めているので実際にはmake app-testでテストが回せます。
Makefile
# 開発環境立ち上げ
start:
docker-compose up -d
# テストの実行
app-test: start
docker-compose exec app go test -v ./...
# ファイルが変更された時にテストをまわす
# entrが入ってない場合は`brew install entr`
app-watch: start
find app -name '*.go' | entr make app-test
# serverを起動する、Port 8080でlistenしている
app-server-start: start
docker-compose exec app go run ./...
docker-compose.yml
app:
image: golang:1.12.6
working_dir: /go/src/github.com/sxarp/eks-terraform-ci-sample/app
command: tail -f /dev/null
environment:
- GO111MODULE=on
ports:
- "127.0.0.1:8080:8080"
volumes:
- ./app:/go/src/github.com/sxarp/eks-terraform-ci-sample/app
test/lintをCIで回す
lintは多数のlintをアグリゲートしたgolangci-lintを使っています。
testを回す際は/go/pkg/modをsave_cacheすることで依存のキャッシュをしています。
CIでのlintの設定
本来ならCI用のイメージにlintを含めるのがスタンダードですが、今回は以下のようにCircleCIのキャッシュの中に放り込んでいます。
- restore_cache:
keys:
- go-lint-1.17.1
- run:
name: lint
command: |
# golangci-lintをインストール
# 参考: https://github.com/golangci/golangci-lint#ci-installation
[[ ! -f /go/lint/golangci-lint ]] && curl -sfL https://install.goreleaser.com/github.com/golangci/golangci-lint.sh | sh -s -- -b /go/lint v1.17.1 || true
cd app # go.modのあるディレクトリに移動しないと変なキャッシュの効き方をしてしまう
/go/lint/golangci-lint run ./...
- save_cache:
key: go-lint-1.17.1
paths:
- "/go/lint"
CIでのGoの依存キャシュの設定
- save_cache:
key: go-mod-{{ checksum "app/go.sum" }}
paths:
- "/go/pkg/mod"
マルチステージビルド
マルチステージビルドを行いベースイメージをFROM scratchとすることでイメージサイズを4Mぐらいにしています。
なお、今回はビルドのキャッシュによる高速化は行っていませんが、マルチステージビルドをキャッシュを使って高速化する場合、ビルダーは完成イメージに含まれないの工夫する必要があります(別途ビルダー自体をキャッシュするなど。)
マルチステージビルドしているDockerfile
FROM golang:1.12.6 AS builder
ENV GO111MODULE=on
WORKDIR /app
COPY . .
# CGO_ENABLED=0を指定しないと、以下のようなエラーが出る:
# `standard_init_linux.go:207: exec user process caused "no such file or directory"`
RUN CGO_ENABLED=0 GOOS=linux GOARCH=amd64 go build -ldflags="-w -s"
FROM scratch
COPY --from=builder /app/app /app
ENTRYPOINT ["/app"]
Graceful Shutdown
K8sではpodは頻繁に落ちる想定(例えばスケールイン時)なのでGraceful Shutdownを行うようにしたほうが良いでしょう。
Graceful Shutdownの実装コード
func gracefulShutdown(srv *http.Server) {
c := make(chan os.Signal, 1)
signal.Notify(c, syscall.SIGINT, syscall.SIGTERM)
<-c
ctx, cancel := context.WithTimeout(context.Background(), time.Second*15)
defer cancel()
if err := srv.Shutdown(ctx); err != nil {
log.Fatal(err)
}
log.Println("shutting down")
os.Exit(0)
}