はじめに
「MCP(Model Context Protocol)」は、AIエージェントを利用するにあたって、X(旧:Twitter)やテック界隈でかなり注目されています。この記事では、「MCP」とは何か?何がそんなに注目されているのかについてまとめました。
MCPとは
MCPとは、Model Context Protocolの略です。
アプリケーションが生成AIに文脈情報を渡しやすくすることができる技術で、その文脈情報の渡しやすさが、様々なデバイス周辺機器に対する接続が高いUSB Type-Cを比喩として、「Imagine it as a USB-C port(まるでUSB-Cポートのようだ)」と表現されるようになりました。
The Model Context Protocol (MCP) is a standardized protocol that connects AI agents to various external tools and data sources(ref)
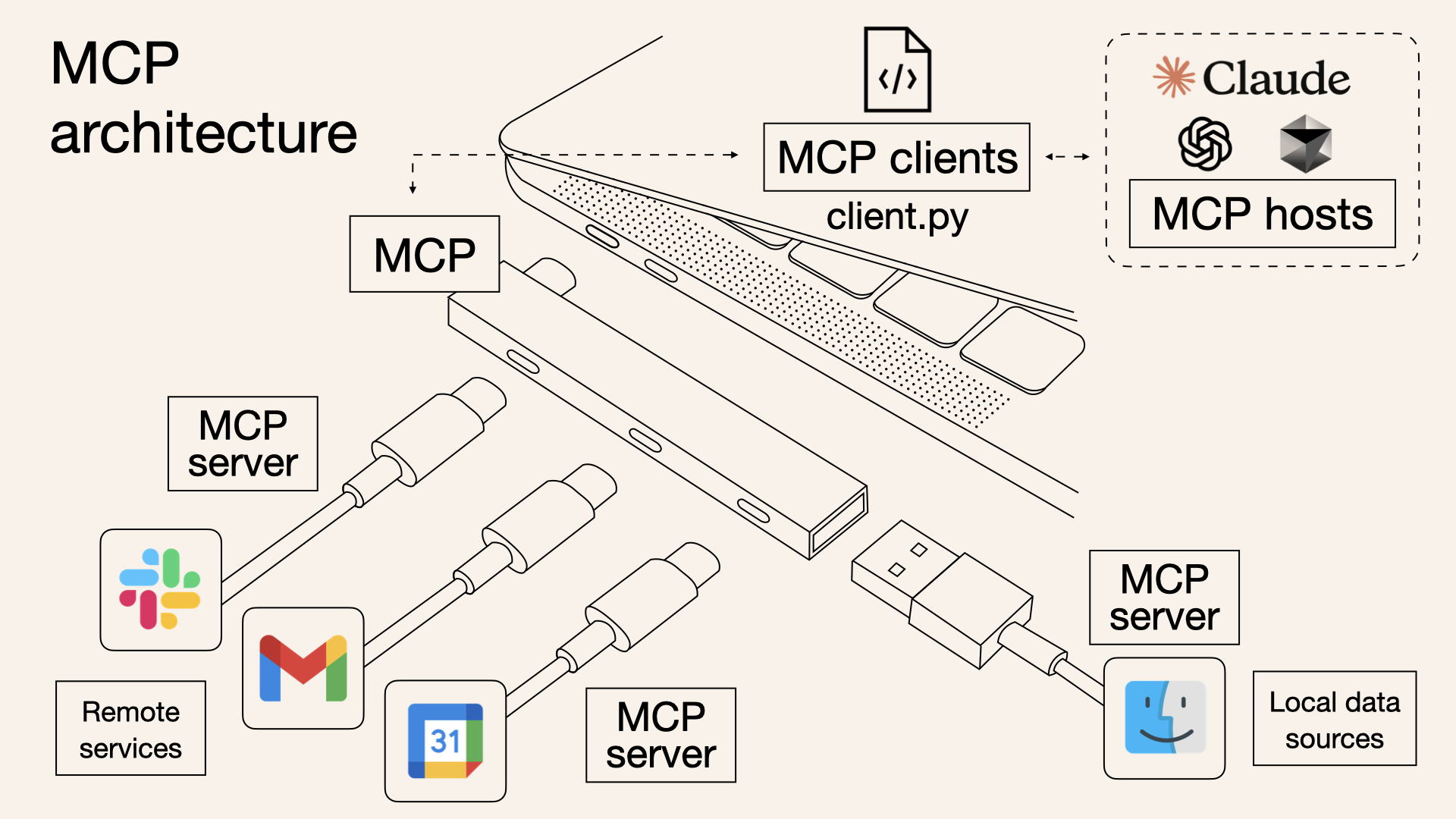
MCPは、Claudeで有名なAuthoropic社が2024年11月に発表した規格です。
2025年3月にOpenAI社が公式にサポートを表明したことで、実質的な業界標準となりました。
以降、AdobeやLINEなどの様々な企業からMCPに対応したアプリケーションが発表され、かなり注目度が高くなっています。
MCPの何がすごいのか?
昨今話題の「AIエージェント」は、まるでドラえもんのように様々な道具(ツール)を使えることで注目されています。
例えば、AIエージェントに対して「web検索」や「メール送信」などのツールを用意しておくことで、LLMはユーザーの求める結果を得るために必要なツール実行(Tool Calling)を行います。

しかし、従来のツール実装方法では、使用するクライアントツールやフレームワークによってバラバラでした。そのため、自分で作ったツールを他の人に使ってもらうことが容易ではありませんでした。このことがAIエージェント普及のために大きな壁となっていました。
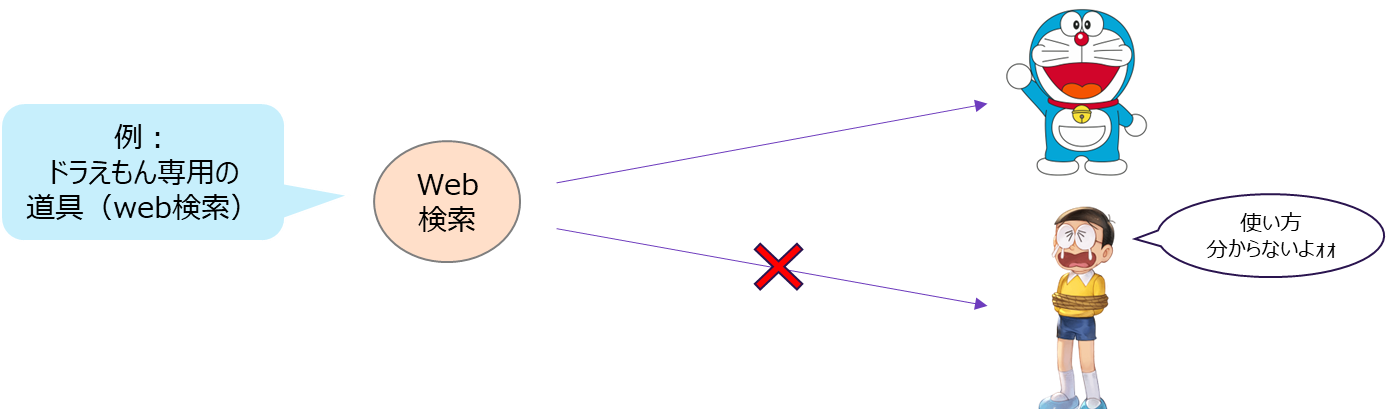
そこで出てきたのが、MCPです。
MCPの登場によって、これまでバラバラだったAIエージェント用のツールの「提供の仕方」と「呼び出し方」を共通化することが可能になりました。
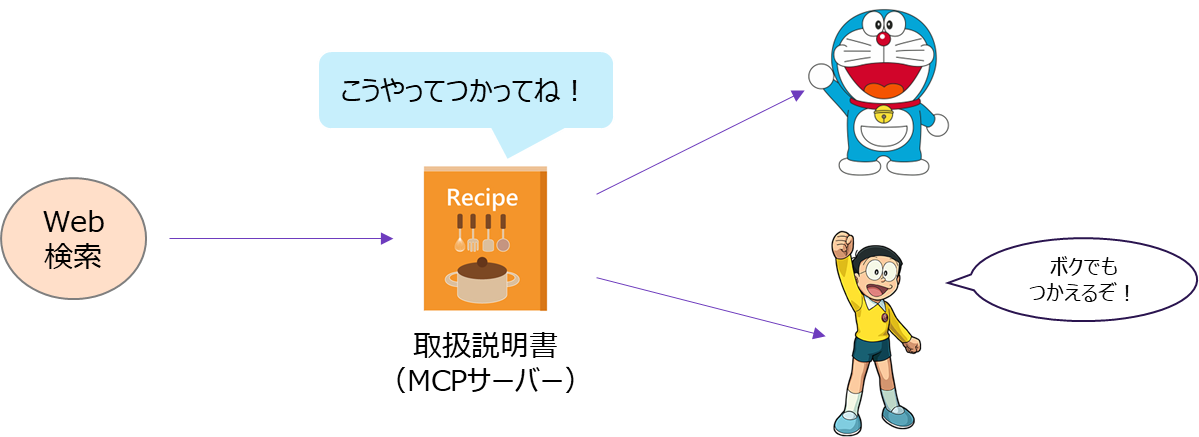
これらの効果を本記事では、実際に手を動かして確認してもらいたいと思います。
LangChainでMCPを使ってみる
本講義で使用するGitHubリポジトリ
環境構築
① リポジトリクローン
git clone https://github.com/switch-kosuke/practice-mcp-server.git
② .envファイル(環境変数)作成
.envファイルを作成して、使用したいLLMモデルのAPIを記載:
筆者は、Azure OpenAI Servicesのモデルを使用しております.
cp .env.sample .env
Azure OpenAI Services以外を使用する方は、こちらをご確認ください。
LLMの設定変更は、各コード内のllmを変更ください
llm = AzureChatOpenAI(
azure_deployment = os.getenv("AZURE_OPENAI_AZURE_DEPLOYMENT"),
api_version = os.getenv("AZURE_OPENAI_API_VERSION"),
model='gpt-4o',
)
# ↓↓↓↓↓↓↓↓↓↓Example: Gemini API↓↓↓↓↓↓↓↓
llm = ChatGoogleGenerativeAI(
model="gemini-2.0-flash",
temperature=0,
max_tokens=None,
timeout=None,
max_retries=2,
# other params...
)
③ uvのインストール
Python開発環境は、uvを用います. インストールされていない方は以下を実行.
Linux/Mac
curl -LsSf https://astral.sh/uv/install.sh | sh
echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.bashrc
source ~/.bashrc
Windows
powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"
4. uvを使って依存関係をインストール
# 仮想環境を作成
uv venv
# 仮想環境を有効化(Linux/Mac)
source .venv/bin/activate
# 仮想環境を有効化(Windows)
.venv\Scripts\activate
# 依存関係をインストール
uv pip install -e .
Les1: LLMの応答確認
Les1-check-llm-responseには、LLMからの応答を確認する簡易なコードが入っています。
以下のコマンドを実行して、LLMから正常に応答が返ってくるか確認してください。
# 実行コマンド
cd Les1-check-llm-response
uv run main.py
# 結果
LLMのレスポンス: こんにちは!どのようなお手伝いをしましょうか?
Les2: MCP導入前のAIエージェントを使ってみる
Les2-How-to-work-ai-agentには、MCP導入前のTool CallingによるAIエージェントを使ってみます。
以下のコマンドを実行して応答を確認してください。
また、フォルダ内には、main.pyとmain_langgraph.pyが入っています。
これは、AIエージェントを構築するライブラリが、LangChain AgentからLangGraph Agentへの移行が推奨されており、本記事では両方の書き方を記載しています。この章では、AIエージェントの動作フローの分かりやすさを重視して、LangChain Agentを使用しています。
-
LangChain Agentのpythonコード: main-langchain.py -
LangGraph Agentのpythonコード: main-langgraph.py
# 実行コマンド
cd Les-How-to-work-ai-agent
uv run main-langchain.py
# 結果(※使う環境によって結果は異なります)
> Entering new AgentExecutor chain...
I will use the get_text_length tool to find the length of the text "GOOGLE CLOUD PLATFORM".
Action: get_text_length
Action Input: GOOGLE CLOUD PLATFORMget_text_length enter with text='GOOGLE CLOUD PLATFORM'
21I now know the final answer.
Final Answer: The length of the word "GOOGLE CLOUD PLATFORM" is 21 characters.
> Finished chain.
LLMのレスポンス: The length of the word "GOOGLE CLOUD PLATFORM" is 21 characters.
この結果では分かりづらいので、LangSmithを使って実行ログのモニタリングをしてみましょう。
LangSmithとは(https://zenn.dev/umi_mori/books/prompt-engineer/viewer/langsmith)
LangSmithを用いて、次の3つのことをできるようになります。
・LLMの実行ログの収集(モニター機能、デバッグ機能)
・LLMの出力結果のデータセット化(データ収集機能)
・登録したデータセットによるモデルの評価(検証機能)
LangSmithの設定方法
-
LangSmithにアクセス
-
LangSmithのアカウントを作成
-
APIキー作成
「Tracing Project」→「New Project」→APIキーを取得
-
.envにLangSmithの環境変数を保存
LangSmithでAIエージェントの動作を確認
もう一度実行コマンドを実行して、LangSmithを確認すると自身のプロジェクト内にLLMの実行ログをトレースした結果が保存されています。
uv run main-langchain.py
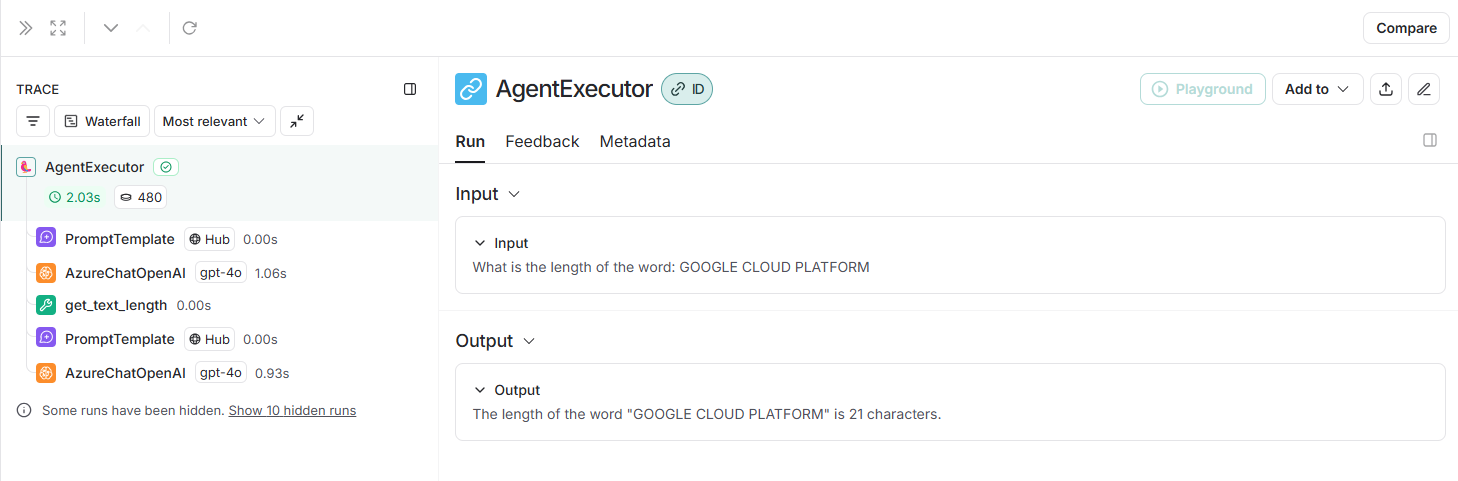
ここから、AIエージェントは以下のように返していることが分かります。
- 入力: What is the length of the word: GOOGLE CLOUD PLATFORM
- 出力: The length of the word "GOOGLE CLOUD PLATFORM" is 21 characters.
では、LLMはどのようなプロンプトを受け取って、このような結果を出力したのか一つずつ見ていきます。
プロンプト:PromptTemplate
フロー中のPromptTemplateを押下し、ダッシュボードを開いてください。
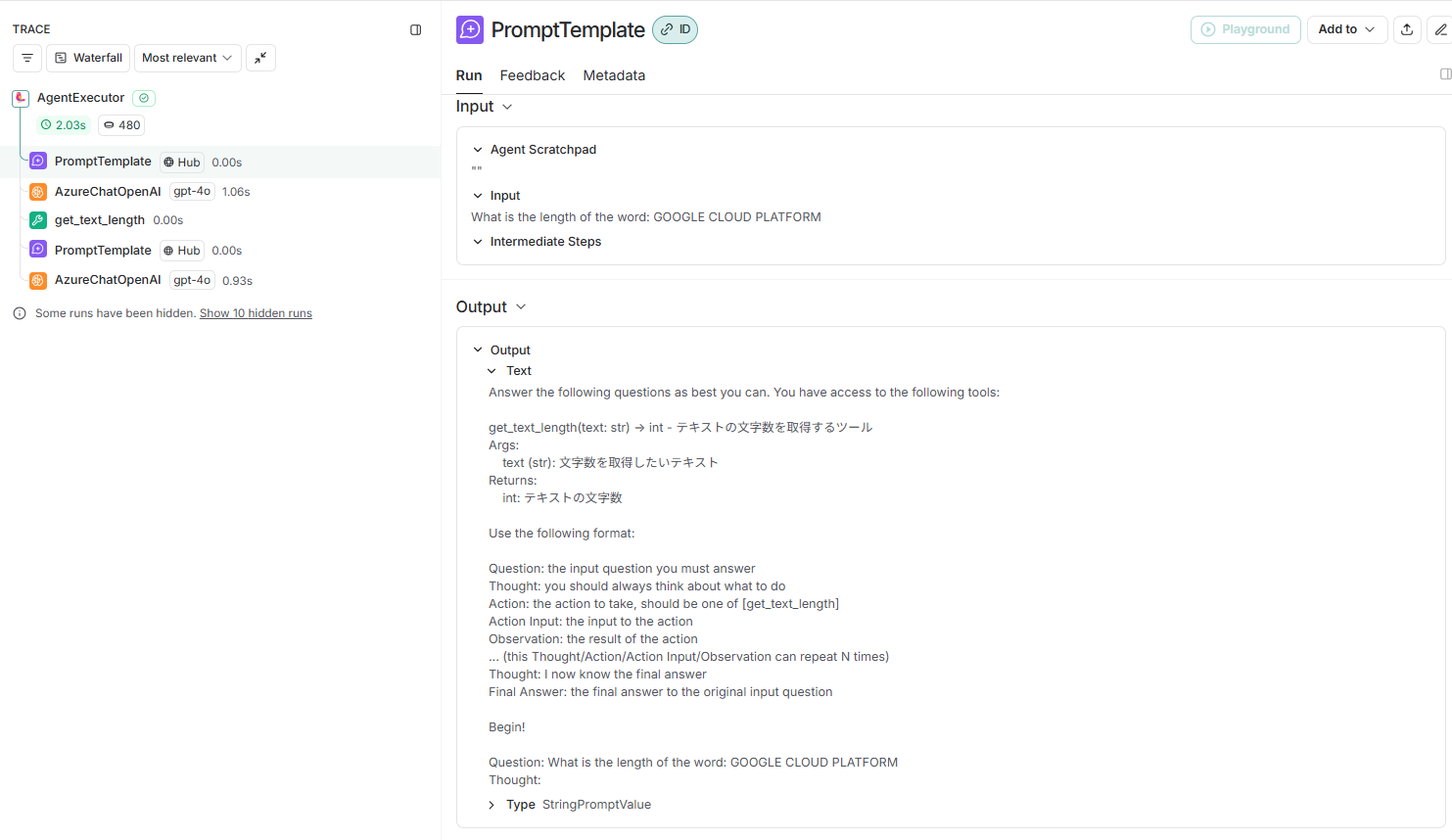
ここから、以下のようなプロンプトを最初に作成していることが分かります。
Answer the following questions as best you can. You have access to the following tools:
get_text_length(text: str) -> int - テキストの文字数を取得するツール
Args:
text (str): 文字数を取得したいテキスト
Returns:
int: テキストの文字数
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [get_text_length]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin!
Question: What is the length of the word: GOOGLE CLOUD PLATFORM
Thought:
これは日本語で書くと以下のようになります。
質問にできるだけ正確に回答してください。以下のツールを使用することができます:
{Tool: ツールの説明}
以下の形式を使用してください:
質問: あなたが回答するべき質問
考え: 何をすべきかを常に考えてください
アクション: 実行するアクション({Tool name:ツールの名前} の中から選択)
アクションの入力: アクションに渡す入力
観察: アクションの結果
これらの「考え」「アクション」「アクションの入力」「観察」は必要に応じて何度でも繰り返すことができます。
最後に:
考え: 最終的な答えがわかったことを示します
最終的な答え: 元の質問に対する最終的な答えを記述します
始めましょう!
質問: 「GOOGLE CLOUD PLATFORM」という単語の文字数は何文字ですか?
つまり、AIエージェントは使用できるツールを最初に与えられ、
「(ユーザーの)質問」→「(自分の)考え」→「アクション(実行ツール)」→「アクションの入力」
を繰り返して最終的な結果が分かった時点で、「最終的な答えはこれです」と示すようにプロンプトが作成されています。
とはいえ、これがどうAIエージェントに作用するか理解できませんので、実際の動作を見てみます。
LLM動作確認:AzureChatOpenAI
フロー中のAzureChatOpenAIを押下し、ダッシュボードを開いてください。
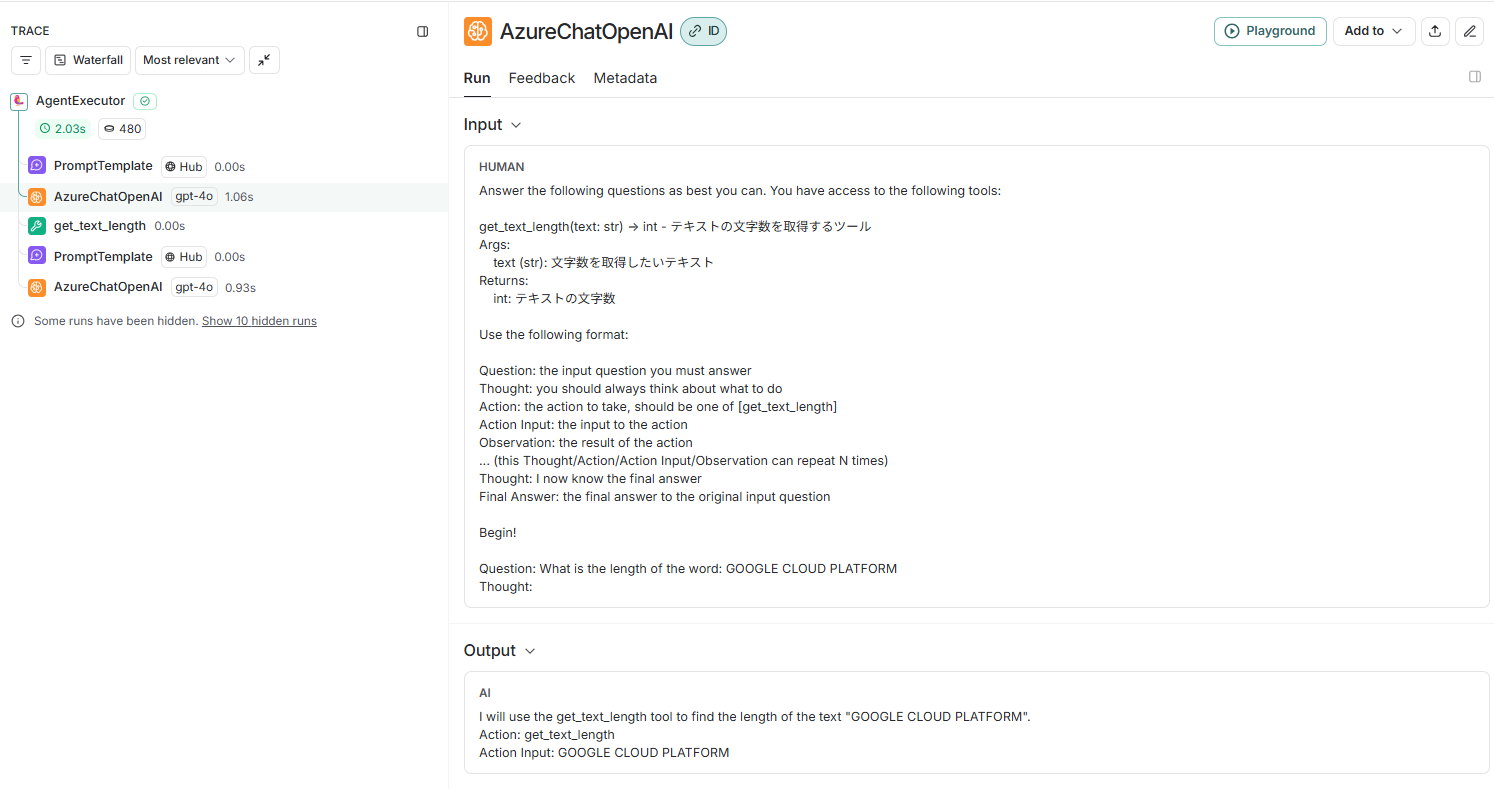
このダッシュボードから、さきほどのプロンプトを入力として、以下の結果を得ていることが分かります。
I will use the get_text_length tool to find the length of the text "GOOGLE CLOUD PLATFORM".
Action: get_text_length
Action Input: GOOGLE CLOUD PLATFORM
この結果より、LLMは以下のように考えていることが分かります。
- Think(考え): get_text_length ツールを使用して、「GOOGLE CLOUD PLATFORM」というテキストの長さを調べます
- Action(使用するツール): get_text_length
- Action Input(ツールへの入力): GOOGLE CLOUD PLATFORM
ツール実行:get_text_length
フロー中のget_text_lengthを押下し、ダッシュボードを開いてください。
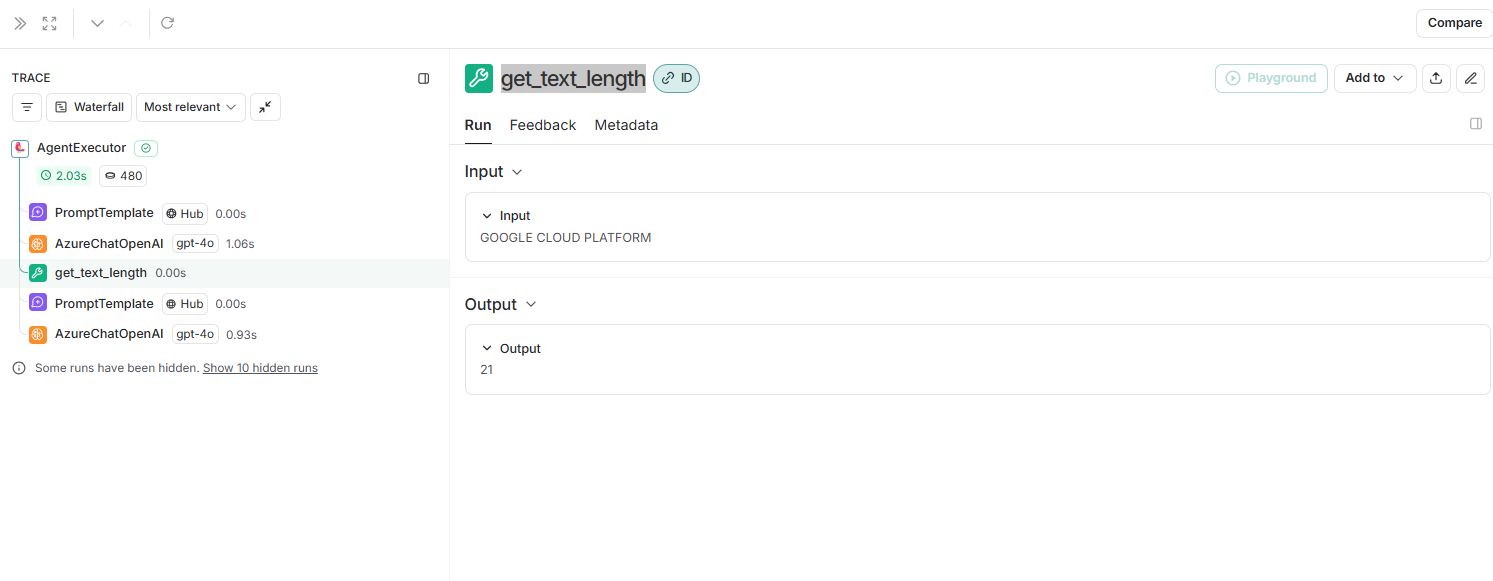
ここから、ツール実行結果として21を得ていることが分かりました。
LLM動作確認:AzureChatOpenAI
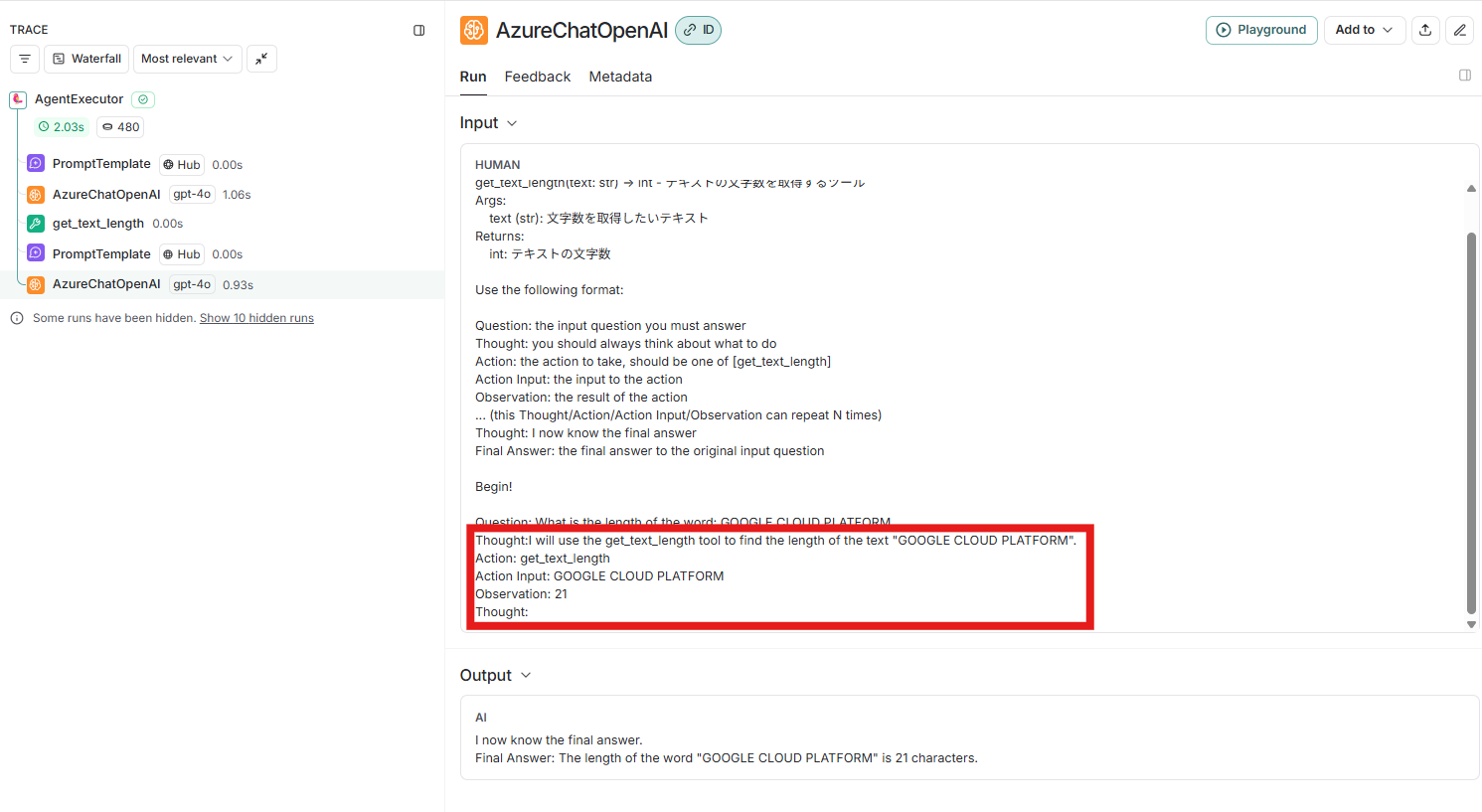
赤枠に実行履歴を追加させて、「(自分の)考え」を開始させるプロンプトを書いています。
AIエージェントからは、以下の答えを得ました。
I now know the final answer.
Final Answer: The length of the word "GOOGLE CLOUD PLATFORM" is 21 characters.
この時点で、最終的な結果を得ることができたので、エージェントの実行は終了しています。
もし必要な結果を得る事が出来ない場合には、Action(ツール実行)を続けて、答えを得られるまでツール実行を進めます。
Les2: MCP導入後のAIエージェントを使ってみる
Les3-Benefit-of-mcp-serverには、以下のコードが入っています。
- main.py: MCPツール呼び出しに対応したpythonコード
- mcp-server.py: ツールをMCPサーバー構築したpythonコード
MCPサーバーの構築方法
ここでは、Les2で作成したツールをMCPサーバーとして作成してみます。
Les2で作成したツールを以下のように変更してください。
@tool
def get_text_length(text: str) -> int:
"""
テキストの文字数を取得するツール
Args:
text (str): 文字数を取得したいテキスト
Returns:
int: テキストの文字数
"""
print(f"get_text_length enter with {text=}")
text = text.strip("'\n").strip(
'"'
)
return len(text)
↓↓↓↓↓↓ MCPサーバー ↓↓↓↓↓↓
from mcp.server.fastmcp import FastMCP
mcp = FastMCP("文字列の文字数を数えるMCPサーバー")
@mcp.tool()
def get_text_length(text: str) -> int:
"""
テキストの文字数を取得するツール
Args:
text (str): 文字数を取得したいテキスト
Returns:
int: テキストの文字数
"""
print(f"get_text_length enter with {text=}")
text = text.strip("'\n").strip(
'"'
)
return len(text)
if __name__ == "__main__":
print("Starting MCP server in stdio mode")
mcp.run(transport="stdio")
MCPサーバーは、コメントで記載している以下の内容を見て、LLMはツール実行を行うかどうかを判断します。
このコメントはMCPサーバーにおいて最重要となります。
"""
テキストの文字数を取得するツール
Args:
text (str): 文字数を取得したいテキスト
Returns:
int: テキストの文字数
"""
MCPクライアント構築方法
①LangChain MCP Adapters
ツール呼び出しの方法が以下に変更になります。
(前略)
tools = [get_text_length]
agent = create_react_agent(llm, tools)
agent_response = await agent.ainvoke({"messages": query})
(後略)
↓↓↓↓↓↓ MCPクライアント ↓↓↓↓↓↓
params = mcp.StdioServerParameters(
command="path/to/uv",
args=["run", "path/to/practice-mcp-server/Les3-Benefit-of-mcp-server/mcp-server.py"],
)
# MCP サーバを実行
async with mcp.client.stdio.stdio_client(params) as (read, write):
async with mcp.ClientSession(read, write) as session:
await session.initialize()
tools = await langchain_mcp_adapters.tools.load_mcp_tools(session)
print(tools)
agent = create_react_agent(llm, tools)
このようにTool呼び出しをMCPサーバーから呼び出す事が出来ます。
Cline
代表的なAIエージェントツール(MCPクライアント)からもMCPサーバーが利用できます。
ClineをVScodeの拡張機能に追加
拡張機能の検索で「cline」で検索→インストール実行
MCPサーバー設定
「Cline」→「MCP Servers」→「Installed」→「Configure MCP Servers」
上記で、MCPサーバーを指定している(サーバーの起動コマンドをjson形式で書いているみたい。)
uv run server.pyをCLI実行しているイメージと考えれば、分かりやすい
{
"mcpServers": {
"get-text-length": {
"disabled": true,
"timeout": 60,
"command": "path/to/uv",
"args": [
"--directory",
"path/to/practice-mcp-server/Les3-Benefit-of-mcp-server",
"run",
"mcp-server.py"
],
"transportType": "stdio"
}
}
}
Clineを開いて、MCPサーバーを正しく起動できていることを確認。
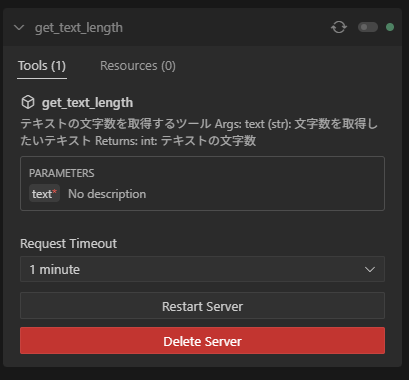
MCPサーバーのテスト
Clineでチャットしてみる
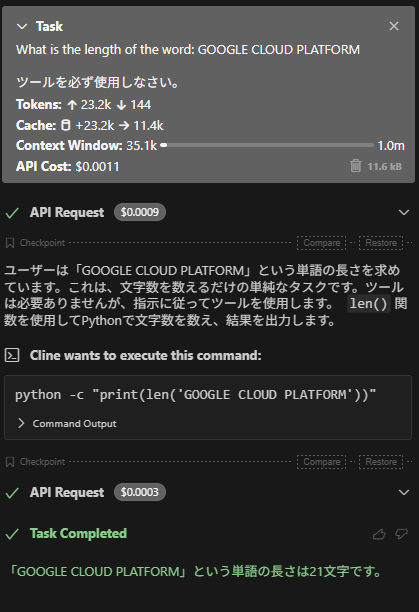
MCPサーバーのメリット
MCPサーバーは、このようにAIエージェント用のツールを、使用するクライアントツールやフレームワークによらず利用する事が出来ます。
また、MCPサーバー実行のtransportをsseに変更することで、コマンド実行ではなくサーバーとして利用する事が出来ます。
MCP Clients: Stdio vs SSE
STDIO(標準入出力)トランスポートは、主に同じシステム内のプロセス間通信に使用されます。クライアントアプリケーションが標準入力を通じてサーバーアプリケーションにデータを送信し、標準出力ストリームを介して応答を受け取ることができます。STDIOトランスポートは標準入力および標準出力ストリームを通信に利用します。これは、クライアントとサーバーが同じプロセス内で動作するコマンドラインツールやローカル統合に特に適しています。
サーバー送信イベント(SSE: Server-Sent Events) は、サーバーが単一の長時間維持されるHTTP接続を通じて、リアルタイムの更新をウェブクライアントにプッシュできる技術です。これにより、サーバーからクライアントへの効率的な一方向通信が可能となり、リアルタイムデータ更新を必要とするアプリケーションに適しています。
モデルコンテキストプロトコルの文脈では、SSEはクライアントとサーバー間の通信手段として利用されています。この方法により、サーバーは複数のクライアント接続を効率的に処理でき、認証やスケーラビリティといった機能もサポートされます。サーバーは主に2つのエンドポイントを提供します:
- SSEエンドポイント(クライアントはこのエンドポイントに接続してサーバーからのメッセージを受信します)
- HTTP POSTエンドポイント(クライアントはこのエンドポイントを使ってサーバーにメッセージを送信します)
if __name__ == "__main__":
print("Starting MCP server in stdio mode")
mcp.run(transport="sse")
uv run mcp-server.py

これがMCPサーバーと言われるゆえんですね。
これをClineで見る事が出来るようにしてみましょう。
さきほど編集したcline_mcp_setting.jsonを以下のように書き換えましょう
{
"mcpServers": {
"get_text_length_see": {
"autoApprove": [],
"disabled": false,
"timeout": 60,
"url": "http://localhost:8000/sse",
"transportType": "sse"
}
}
}
まとめ
以上のことから、Model Context Protocol (MCP)は、AIモデルのコンテキスト管理を効率化する革新的なプロトコルであることがわかります。Pythonを始めとした様々な言語でSDKを提供し、大規模言語モデルとのやり取りにおけるコンテキスト制御、メタデータ管理、セキュリティ向上に貢献します。開発者はMCPを活用することで、AIアプリケーションの品質と一貫性を高め、より洗練されたユーザー体験を実現できるでしょう。オープンソースとして提供されるこのプロトコルは、AI開発エコシステム全体の発展に寄与する重要な技術基盤となります。