はじめに
毎月の給与明細、賞与明細のPDFファイルが溜まっていくけど、Excelで管理したい...そんな悩みを解決するツールを作りました。
この記事で実現できること:
- 📊 給与・賞与PDFから全項目を自動抽出
- 📑 給与と賞与を別シートで管理
- 🎨 項目を色分けして見やすく表示
- 🔄 新しい手当や控除が追加されても自動対応
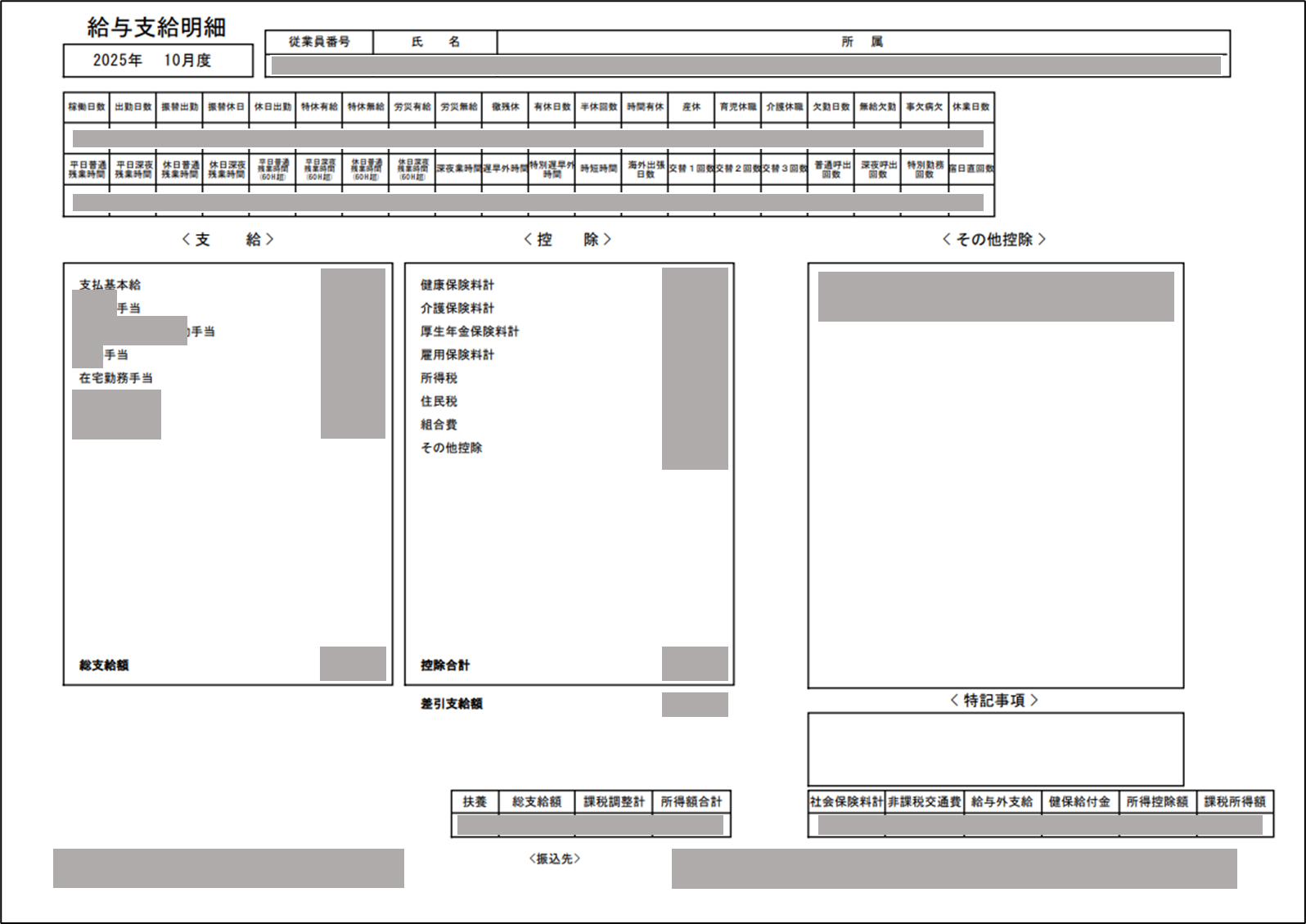
完成イメージ
| Before | After |
|---|---|
 |
 |
※個人情報が含まれる分は、グレーで隠してあります。
(手当名とかはGitHubのリポジトリ見ればほぼ分かりますが、ご愛敬で(笑))
Before(PDFの山...)

私は給与明細や賞与明細をこのようにフォルダ内に保存していました。
しかし、すべてのファイルを開いて詳細を確認するのがめんどくさかったんですよね…。
そこで、実行ファイル一つでエクセルに集約できるようにしてみました。
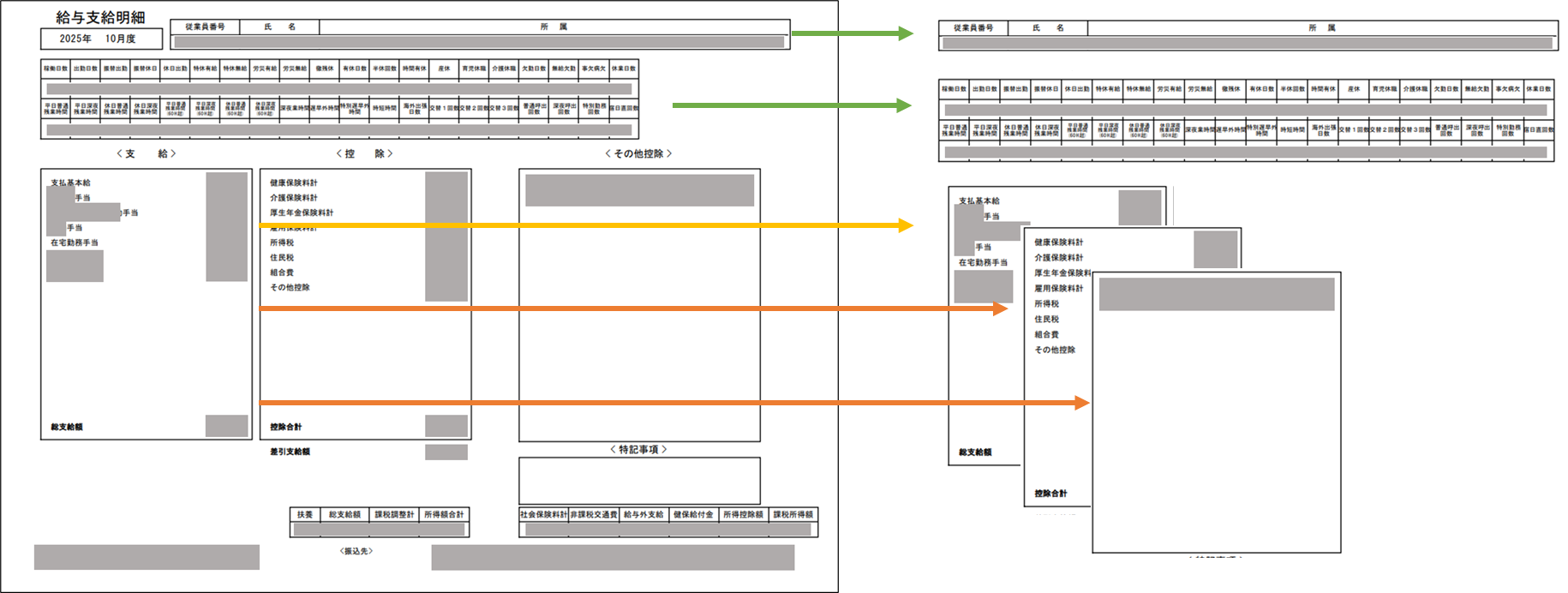
After(1つのExcelファイルに集約!)
給与賞与明細まとめ_20260117.xlsx
├── 給与シート
└── 賞与シート

- 🟢 緑:支給項目
- 🔴 赤:控除項目
- 🟠 オレンジ:合計項目
技術スタック
- Python 3.7+
- pdfplumber: PDFからテキスト・表を抽出
- pandas: データ整形
- openpyxl: Excel出力・スタイル設定
実装のポイント
1. PDFから表データを抽出
給与明細は表形式になっているため、pdfplumberで表を抽出します。
import pdfplumber
def extract_pdf_tables(pdf_path):
with pdfplumber.open(pdf_path) as pdf:
tables = []
for page in pdf.pages:
page_tables = page.extract_tables()
if page_tables:
tables.extend(page_tables)
return tables
2. 動的な項目検出と分類
給与明細は月によって項目が変わることがあります(給与改定差額、特別手当など)。
そのため、項目を動的に検出し、キーワードで分類します。
class PayslipExtractor:
def __init__(self, base_dir):
self.all_columns = set() # 全項目を保持
# 設定ファイルから分類用キーワードを読み込み
self.allowance_keywords, self.deduction_keywords = self._load_config()
def parse_payslip(self, text, pdf_name):
data = {}
# 【動的検出】正規表現で「項目名 金額」のパターンを全て抽出
pattern = r'([ぁ-んァ-ヶー一-龥々a-zA-Z0-9()]+?)\s+([-−]?\d{1,3}(?:,\d{3})*)'
matches = re.findall(pattern, text)
for item_name, amount in matches:
# 【分類判定】キーワードで支給/控除を判定
if any(kw in item_name for kw in self.allowance_keywords):
col_name = f'支給_{item_name}'
elif any(kw in item_name for kw in self.deduction_keywords):
col_name = f'控除_{item_name}'
else:
continue # マッチしない項目はスキップ
data[col_name] = int(amount.replace(',', ''))
self.all_columns.add(col_name) # 項目を記録
return data
ポイント:
- 正規表現で項目名を動的に検出(新しい手当が追加されても自動対応)
- 設定ファイル(config.json)のキーワードで支給/控除を分類(会社ごとにカスタマイズ可能)
-
self.all_columnsで全PDFから出現した項目を収集 - 分類により色分け表示が可能に(緑=支給、赤=控除)
3. 給与と賞与を別シートに分離
def create_excel(self, data, output_path):
df = pd.DataFrame(data)
# 給与と賞与を分離
df_salary = df[df['種類'] == '給与'].copy()
df_bonus = df[df['種類'] == '賞与'].copy()
# Excelに書き出し
with pd.ExcelWriter(output_path, engine='openpyxl') as writer:
if not df_salary.empty:
df_salary.to_excel(writer, sheet_name='給与', index=False)
self._format_sheet(writer.book['給与'])
if not df_bonus.empty:
df_bonus.to_excel(writer, sheet_name='賞与', index=False)
self._format_sheet(writer.book['賞与'])
4. 色分け表示で見やすく
def _format_sheet(self, worksheet):
# 色を定義
allowance_fill = PatternFill(start_color='70AD47', end_color='70AD47', fill_type='solid') # 緑
deduction_fill = PatternFill(start_color='FF6B6B', end_color='FF6B6B', fill_type='solid') # 赤
summary_fill = PatternFill(start_color='FFC000', end_color='FFC000', fill_type='solid') # オレンジ
for cell in worksheet[1]:
column_name = str(cell.value)
if column_name.startswith('支給_'):
cell.fill = allowance_fill
elif column_name.startswith('控除_'):
cell.fill = deduction_fill
elif column_name in ['総支給額', '控除合計', '差引支給額']:
cell.fill = summary_fill
ポイント:
- 列名のプレフィックスで色を判定
- 視覚的に項目を区別しやすくなる
プロジェクト構成
給与・賞与明細/
├── 実行.bat # ダブルクリックで実行
├── 給与賞与明細まとめ_*.xlsx # 出力ファイル
├── tools/ # プログラム関連
│ ├── extract_payslips_to_excel.py # メインスクリプト
│ ├── config.json.sample # 設定ファイルのサンプル
│ ├── requirements.txt
│ ├── README.md
│ └── .venv/ # 仮想環境
├── 給与/ # 給与PDFフォルダ
└── 賞与/ # 賞与PDFフォルダ
セットアップ方法
1. 必要なパッケージをインストール
# 仮想環境を作成
python -m venv tools/.venv
# 仮想環境を有効化(Windows)
tools\.venv\Scripts\activate
# パッケージをインストール
pip install -r tools/requirements.txt
requirements.txt
pdfplumber==0.11.0
pandas==2.2.0
openpyxl==3.1.2
Pillow==10.2.0
2. PDFファイルを配置
給与/ フォルダに YYYYMM.pdf 形式で配置
賞与/ フォルダに YYYYMM.pdf 形式で配置
3. 実行
# 実行.batをダブルクリック
# または
python tools/extract_payslips_to_excel.py
使い方
- 新しい給与・賞与PDFを該当フォルダに追加
-
実行.batをダブルクリック - 最新のExcelファイルが自動生成される
出力例:
給与賞与明細まとめ.xlsx ← 固定ファイル名(毎回上書き更新)
├── 給与シート
│ ├── 支払年月: 20XX年04月, 20XX年05月, ...
│ ├── 稼働日数: XX, XX, ...
│ ├── 支給_基本給: XXXXX, ...
│ ├── 控除_健康保険料: XXXXX, ...
│ └── 差引支給額: XXXXX, ...
└── 賞与シート
└── (同様の構成)
カスタマイズ方法
設定ファイルで分類キーワードを調整
項目は自動検出されますが、「支給」か「控除」かの判定には設定ファイルが必要です。
他の会社の給与明細でも使えるように、config.jsonでキーワードをカスタマイズできます。
なぜ設定ファイルが必要?
- 「住宅手当」→ 支給項目として分類
- 「住民税」→ 控除項目として分類
- この判定にキーワードマッチを使用(会社や業界で異なる項目名に対応)
初回セットアップ:
# サンプルファイルをコピーして個人用設定を作成
Copy-Item config.json.sample config.json
config.json
{
"allowance_keywords": [
"基本給",
"支払基本給",
"手当",
"賞与",
"あなたの会社の支給項目" // ← ここに追加
],
"deduction_keywords": [
"健康保険",
"所得税",
"住民税",
"あなたの会社の控除項目" // ← ここに追加
]
}
実装のポイント:
def _load_config(self):
"""設定ファイルからキーワードリストを読み込む"""
config_path = Path(__file__).parent / "config.json"
# デフォルトのキーワード(フォールバック用)
default_allowance = ['給', '手当', '賞与', ...]
default_deduction = ['保険', '年金', '税', ...]
# 設定ファイルが存在すれば読み込む
if config_path.exists():
try:
with open(config_path, 'r', encoding='utf-8') as f:
config = json.load(f)
return (
config.get('allowance_keywords', default_allowance),
config.get('deduction_keywords', default_deduction)
)
except Exception as e:
print(f"設定ファイルの読み込みに失敗: {e}")
return default_allowance, default_deduction
メリット:
- コードを触らずに設定を変更できる
- 他の会社の明細でも簡単に使い回せる
- 設定ファイルを共有すれば同じ環境を再現できる
工夫したポイント
1. 項目の動的検出
給与改定や手当の追加があっても、自動的に検出して列に追加されます。
ハードコーディングしていないため、メンテナンスフリーです。
2. 2パスアルゴリズム
- 全PDFを読み込んで存在する項目を収集
- 統一された列構成でExcelを作成(項目がない月は0)
これにより、月によって項目数が違っても、きれいな表になります。
3. バッチファイルで簡単実行
非エンジニアの家族でも使えるように、バッチファイルでワンクリック実行できるようにしました。
@echo off
cd /d "%~dp0"
call tools\.venv\Scripts\activate.bat
python tools\extract_payslips_to_excel.py
pause
ハマったポイント
1. PDFのテキスト抽出精度
PDFによってはテキスト抽出がうまくいかないことがあります。
pdfplumberのextract_tables()を使うことで、表構造を正確に取得できました。
2. 項目名の揺れ
「健康保険料」「健康保険料計」など、微妙に名前が違う項目があります。
正規表現のキーワードマッチで柔軟に対応しました。
3. 稼働日数の抽出
稼働日数は表の特定位置にあるため、ヘッダー行を検出してから次の行の値を取得する必要がありました。
for i, line in enumerate(lines):
if '稼働日数' in line and '出勤日数' in line:
if i + 1 < len(lines):
next_line = lines[i + 1]
numbers = next_line.split()
if numbers and numbers[0].isdigit():
data['稼働日数'] = int(numbers[0])
まとめ
給与明細のPDF管理を自動化することで、以下のメリットがありました:
- ✅ 手作業でのExcel入力が不要に
- ✅ 過去の給与推移が一目で把握できる
- ✅ 年収計算や税金の確認が簡単に
- ✅ 新しい項目が追加されても自動対応
ソースコード
完全なソースコードは以下のリポジトリで公開しています:
参考資料
この記事が誰かの役に立てば幸いです!
質問やフィードバックがあれば、コメント欄でお気軽にどうぞ 😊