本記事について
なろうみたいな記事タイトルですみません。
「ディープラーニング(CNN)で、ドル円の予測プログラムを作って億万長者や!」
と意気込んだ結果、__失敗したお話__です。__反面教師にされたい方のみ__ご参照ください。
成果物についての説明
あまり説明したくないですが、成果物について説明します。
CNN(畳み込みニューラルネットワーク)で、大量のチャート画像でレートの予測方法を学習し、
24時間後のレートが「上がる」「下がる」「分からない」の3択を出力するプログラムを作成しました。
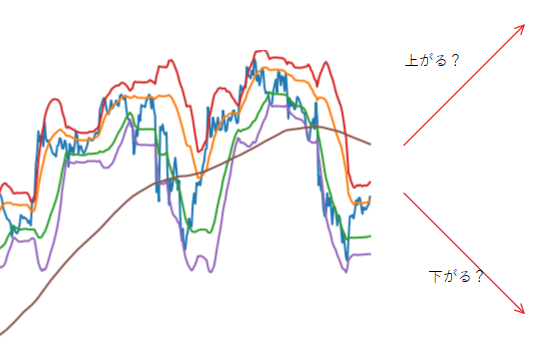
推論結果は正解率88%という好成績でした。
しかし、実データで予測させると「分からない」を連発するポンコツっぷり。。
作成期間3日もかけたので、ガックリ具合が半端ないですが、
作成した経過で勉強になることが多かったのでアウトプットとして残しておこうと思います。
構築環境
Google Colaboratory上で構築。
Python 3.6
Tensorflow 1.13.1
データの前処理
画像データの準備
CNNは画像分類の深層学習です。
というわけで、大量のチャート画像を用意する必要があります。
以下のような画像データを約8万枚ほど準備しました。

なお、8時間ほどかけて作成した8万枚の画像ですが、後述にある理由で、実際に使ったのは3万枚でした。
チャート画像作成方法については、こちらの記事を参照ください。
画像データの配列化とバイナリ形式への保存
学習作業は画像データそのままでは出来ません。
画像データをnumpyのarrayに変換する必要があり、1万枚ごとにnpy形式に保存してみました。
import glob
import cv2
import numpy as np
X=[]
# 対象の画像をリスト化
img_list = glob.glob('<画像の保存先フォルダ>/*.png')
# 画像をリサイズ
for i in range(len(file_list)):
file_name = '../Make_img/USDJPY/' + str(i) + '.png'
img = cv2.imread(file_name)
img = cv2.resize(img, dsize=(150, 150)) #リサイズ
X.append(img) #リストに追加
#1万枚毎にバイナリ形式で保存する
if (i > 0) and (i % 10000 == 0):
#numpyに変換して、バイナリ保存
X = np.array(X)
npy_name = 'traintest_' + str(i) + '.npy'
np.save(npy_name, X)
X = []
すると、1つあたりのnpyファイルが0.7GBもあり、
8万枚分だと6GB近い大容量になってしまいました。
今回はGoogleDrive上に保存したデータを、
GoogleColobで読み込ませて作業する予定なので、
こんな大容量ファイルをアップするのはよろしくありません。
複数npyファイルを1つに圧縮して、npz形式で纏めます。
※最初からこうすれば配列からnpyに変換して保存する必要は無かったと後で気づく。
arr1 = np.load('traintest_10000.npy')
arr2 = np.load('traintest_20000.npy')
arr3 = np.load('traintest_30000.npy')
arr4 = np.load('traintest_40000.npy')
arr5 = np.load('traintest_50000.npy')
arr6 = np.load('traintest_60000.npy')
arr7 = np.load('traintest_70000.npy')
arr8 = np.load('traintest_80000.npy')
np.savez_compressed('traintest_all.npz', arr1 , arr2, arr3, arr4, arr5, arr6, arr7, arr8)
圧縮すると、0.7GB程度になりました。

当初、250250にリサイズしたのですが、
Google Colabで読み込ませた結果、メモリがクラッシュしてしまい、150150のサイズに変更しました。
このサイズだとボヤける箇所があり、特徴量を上手く掴めているのか不安な感じです。
今回の予測が失敗した理由の1つかもしれません。
GoogleColabで訓練データ、テストデータ、正解ラベルの読み込み
作成したnpzファイルをGoogleDriveにアップし、
GoogleColabを起動して、それを読み込みます。
# パッケージのインポート
from tensorflow.keras.callbacks import LearningRateScheduler
from tensorflow.keras.layers import Activation, Add, BatchNormalization, Conv2D, Dense, GlobalAveragePooling2D, Input
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.regularizers import l2
from tensorflow.keras.utils import to_categorical
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
%matplotlib inline
# Google Driveマウント
from google.colab import drive
drive.mount('/content/drive')
# データセットの元となるnpzを読み込む
loadnpz = np.load(r'/content/drive/My Drive/traintest_all.npz')
ちゃんと8個読み込めていることを確認します。

続いて、訓練用と検証用とで画像を分けます。
それぞれ1万枚を読み込みます。
※これ以上読み込んだら学習中にメモリがクラッシュするため。
# 訓練とテスト画像データセット
train_images = loadnpz['arr_0']
test_images = loadnpz['arr_1']
正解ラベルが入ったCSVファイルをDataFrameで読み込んだのちにarrayに変換します。
変換後、訓練用と検証用とで正解ラベルを分けます。
# 正解ラベルのセット
df = pd.read_csv(r'/content/drive/My Drive/Colab Notebooks/npyファイル/tarintest_labels.csv')
df['target'] = df['target'].replace('Up', '0')
df['target'] = df['target'].replace('Down', '1')
df['target'] = df['target'].replace('Flat', '2')
df['target'] = df['target'].astype('int')
labels_arr = df['target'].to_numpy() #ラベル部分をarraryに変換
# ラベルデータを分ける
train_labels = labels_arr[0:10001] #訓練用
test_labels = labels_arr[10001:20001] #検証用
ラベルデータはOneHot形式に変換します。
# OneHot形式に変換
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
ここまで出来たら、Shape数を確認しましょう。

モデル作成
続いて、モデルの作成です。
今回、ResNetという構造体で作成します。
ResNetって何だよという方はこちらの記事を参照ください。
読み込む画像データ大きすぎると、メモリがクラッシュ連発で全然先に進みません。
その場合は、学習時のbatch_sizeを小さくするか、画像データ自体を小さくする必要があります。
私の場合は、当初画像データ250*250でやってメモリクラッシュ連発で全進めなかったので、150*150にリサイズしました。
# 畳み込み層の生成
def conv(filters, kernel_size, strides=1):
return Conv2D(filters, kernel_size, strides=strides, padding='same', use_bias=False,
kernel_initializer='he_normal', kernel_regularizer=l2(0.0001))
# 残差ブロックAの生成
def first_residual_unit(filters, strides):
def f(x):
# →BN→ReLU
x = BatchNormalization()(x)
b = Activation('relu')(x)
# 畳み込み層→BN→ReLU
x = conv(filters // 4, 1, strides)(b)
x = BatchNormalization()(x)
x = Activation('relu')(x)
# 畳み込み層→BN→ReLU
x = conv(filters // 4, 3)(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
# 畳み込み層→
x = conv(filters, 1)(x)
# ショートカットのシェイプサイズを調整
sc = conv(filters, 1, strides)(b)
# Add
return Add()([x, sc])
return f
# 残差ブロックBの生成
def residual_unit(filters):
def f(x):
sc = x
# →BN→ReLU
x = BatchNormalization()(x)
x = Activation('relu')(x)
# 畳み込み層→BN→ReLU
x = conv(filters // 4, 1)(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
# 畳み込み層→BN→ReLU
x = conv(filters // 4, 3)(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
# 畳み込み層→
x = conv(filters, 1)(x)
# Add
return Add()([x, sc])
return f
# 残差ブロックAと残差ブロックB x 17の生成
def residual_block(filters, strides, unit_size):
def f(x):
x = first_residual_unit(filters, strides)(x)
for i in range(unit_size-1):
x = residual_unit(filters)(x)
return x
return f
# 入力データのシェイプ
input = Input(shape=(150,150, 3))
# 畳み込み層
x = conv(16, 3)(input)
# 残差ブロック x 54
x = residual_block(64, 1, 18)(x)
x = residual_block(128, 2, 18)(x)
x = residual_block(256, 2, 18)(x)
# →BN→ReLU
x = BatchNormalization()(x)
x = Activation('relu')(x)
# プーリング層
x = GlobalAveragePooling2D()(x)
# 全結合層
output = Dense(3, activation='softmax', kernel_regularizer=l2(0.0001))(x)
# モデルの作成
model = Model(inputs=input, outputs=output)
# TPUモデルへの変換
import tensorflow as tf
import os
tpu_model = tf.contrib.tpu.keras_to_tpu_model(
model,
strategy=tf.contrib.tpu.TPUDistributionStrategy(
tf.contrib.cluster_resolver.TPUClusterResolver(tpu='grpc://' + os.environ['COLAB_TPU_ADDR'])
)
)
# コンパイル
tpu_model.compile(loss='categorical_crossentropy', optimizer=SGD(momentum=0.9), metrics=['acc'])
# ImageDataGeneratorの準備
train_gen = ImageDataGenerator(
featurewise_center=True,
featurewise_std_normalization=True)
test_gen = ImageDataGenerator(
featurewise_center=True,
featurewise_std_normalization=True)
# データセット全体の統計量を予め計算
for data in (train_gen, test_gen):
data.fit(train_images)
学習
学習作業を実施します。
TPUモデルに変換したとはいえ、容量が容量なので5時間近くかかります。
# LearningRateSchedulerの準備
def step_decay(epoch):
x = 0.1
if epoch >= 80: x = 0.01
if epoch >= 120: x = 0.001
return x
lr_decay = LearningRateScheduler(step_decay)
# 学習
batch_size = 32
history = tpu_model.fit_generator(
train_gen.flow(train_images, train_labels, batch_size=batch_size),
epochs=100,
steps_per_epoch=train_images.shape[0] // batch_size,
validation_data=test_gen.flow(test_images, test_labels, batch_size=batch_size),
validation_steps=test_images.shape[0] // batch_size,
callbacks=[lr_decay])
学習終了後、検証データでの正解率(val_acc)が88%に!
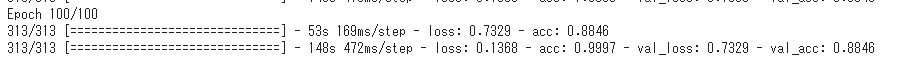
実データでの予測
新規に検証用データをtest_imagesに読み込んで、予測してみます。
test_predictions = new_model.predict_generator(
test_gen.flow(test_images[0:10000], shuffle = False, batch_size=16),
steps=16)
test_predictions = np.argmax(test_predictions, axis=1)[0:10000]
予測結果は、「0:上がる」「1:下がる」「2:分からない」の3択で出力されます。
確認してみましょう。

「2:分からない」を連発してます・・・。
ところどころ「0:上がる」「1:下がる」もありましたが、
正解率は50%を割り込む悲惨な結果でした・・・。
なぜ失敗したのか?
以下の2つが大きいのかなと思います。
- リサイズ後の画像サイズが小さすぎて特徴量が大雑把になりすぎた。
- 検証期間の画像が少なすぎる
1は画像のサイズを大きくすれば解決するのですが、
無料のGoogleColab環境だと厳しいです。
月額10ドルの有料会員になると、倍のメモリが利用できるようになるらしいので、解決するかもしれません。
2は全画像をシャッフルすれば色々なチャートパターンを学習できるので、ある程度は良くなるかもしれません。また、画像自体をあえて簡略化し、似たようなチャートを増やすというのもありかもしれません。記事中ではボリンジャーバンドを利用していますが、外して終値と移動平均線だけのプロットにすることで、改善する可能性もあります。
2の対策は無料で出来るので、暇なときに試してみようと思います。