この記事は「Google Cloud Platform Advent Calendar 2019」8日目の記事です。
Cloud Dataflow SQLのデータソースにGCSが指定できるようになったので、試してみた話です。
Cloud Dataflow SQLとは
Cloud Dataflow SQL1は、BigQueryのコンソール画面でSQLを実行することでDataflowのストリーミングジョブを実行できる機能です。
Google Cloud Next '19のセッションでも紹介され、2019/05/16にパブリックα版として公開されました2。
GCPの公式ドキュメント内にウォークスルーがあります。
2019/11/18の変更点3
- Use Cloud Storage filesets as a data source
- Assign schemas to data sources in the Cloud Dataflow SQL UI
- Preview the content of Cloud Pub/Sub messages from the Cloud Dataflow SQL UI
ということで、GCSをデータソースとして使えるようになりました。
使い方のドキュメントはこちら。
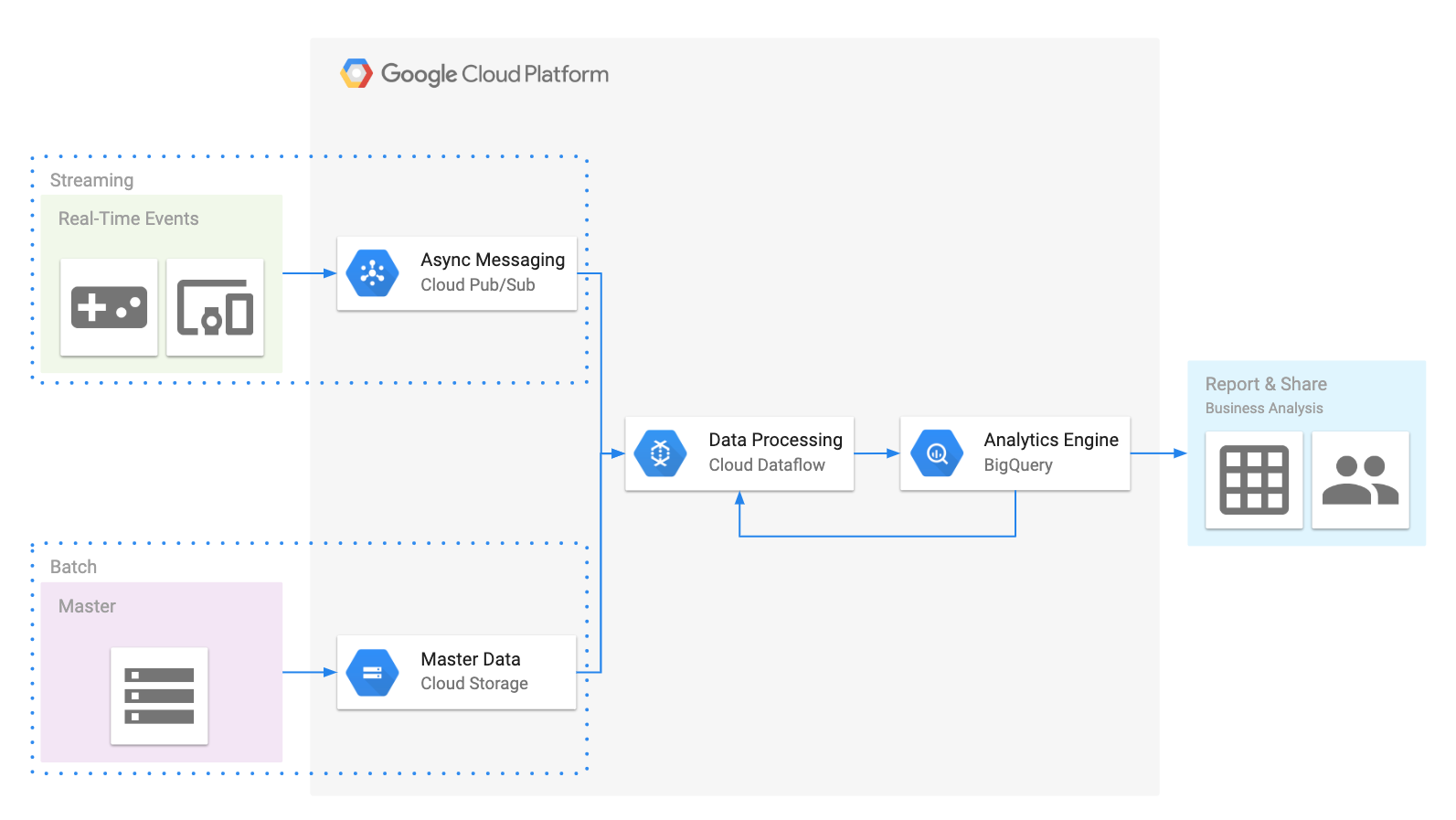
アーキテクチャのイメージ。
Cloud Dataflow SQLのデータソースとしてPub/Sub、GCS、BigQueryが指定できるので、Pub/Subから来たデータとGCSやBigQueryにあるデータをくっつけてBigQueryに格納する使い方になります。
試してみる
GCS上のファイルに対してCloud Data Catalogでメタ情報(スキーマ定義とか)を登録し、それをクエリで利用します。
Pub/SubをDataflowのソースとして使うときと同様の流れです。
$ gcloud beta data-catalog entry-groups create test_entry_group --location=us-central1
API [datacatalog.googleapis.com] not enabled on project [62041182717].
Would you like to enable and retry (this will take a few minutes)?
(y/N)? y
Enabling service [datacatalog.googleapis.com] on project [62041182717]...
Operation "operations/acf.43376de5-7d2b-4895-bf41-dbb6c56a40a0" finished successfully.
Created entry group [test_entry_group].
$ gcloud beta data-catalog entries create test_fileset \
--entry-group=test_entry_group \
--location=us-central1 \
--gcs-file-patterns=gs://sandbox-suzutatsu-bq-dataflowsql/*.csv \
--description="テストデータが入ったCSVファイルのファイルセットです。"
Created entry [test_fileset].
※ファイルセットには、ヘッダー行のないCSVファイルのみを含める必要があります。
次に、データソースとしてGCSのファイルを使ってみます。
BigQueryのコンソール画面で、展開をクリックしてクエリの設定を選択し、クエリエンジンをCloud Dataflow エンジンに切り替えます。
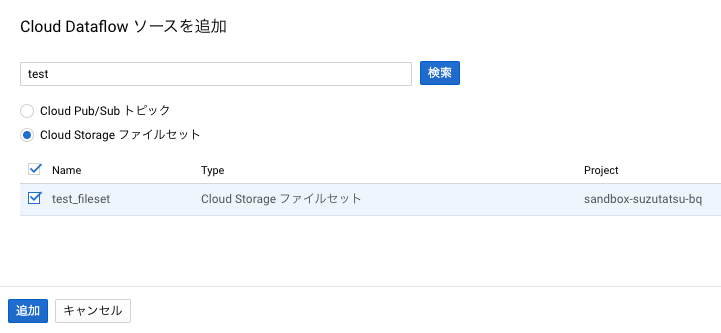
その後、BigQueryのコンソール画面のナビゲーションパネルにあるデータを追加からCloud Dataflow のソースを選択します。
Cloud Dataflowのソースを追加する際に、ラジオボタンが追加され、GCSのファイルセットが選べるようになっています。
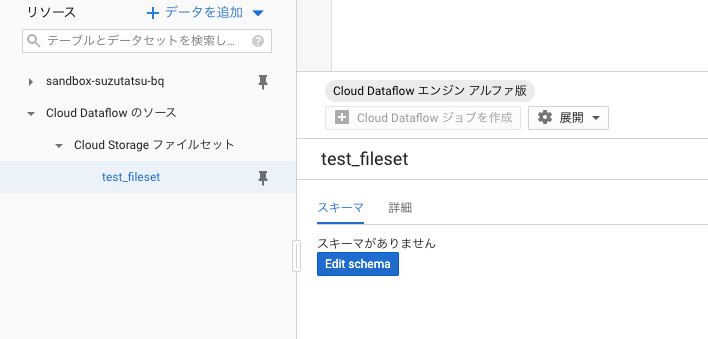
Cloud Dataflowのソースとして追加して、スキーマを見てみると、未登録の状態です。
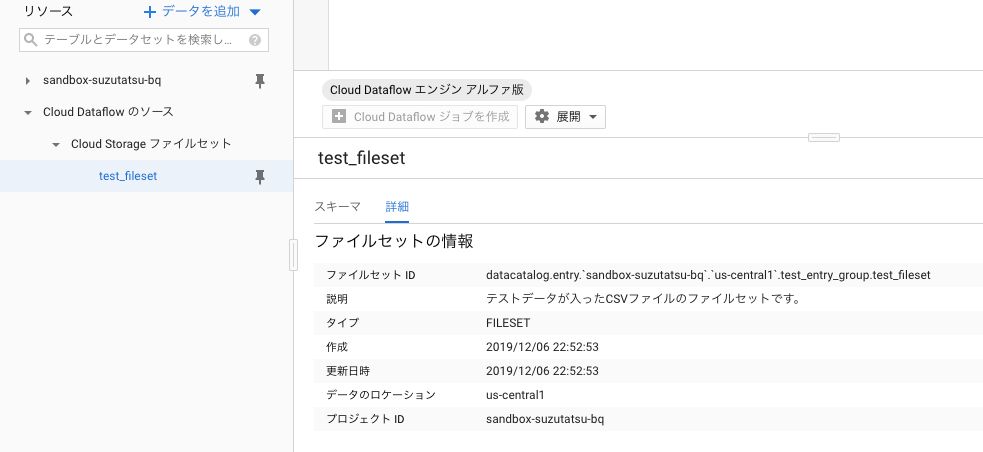
詳細はこんな感じ。
ファイルセットIDにロケーションが入っていたり、タイプがFILESETになっていたりします。
スキーマの設定はGUIでも、JSONを貼り付けてもOK。BigQueryのテーブルを作るときと同じです。
ここまで設定できたら、Pub/Subのデーターソースと組み合わせて、以下のようなSQLクエリを書いて、Cloud Dataflowのストリーミングジョブとして実行できます。
SELECT
a.*,
b.department_name
FROM
pubsub.topic.`sandbox-suzutatsu-bq`.sales AS a
LEFT JOIN
datacatalog.entry.`sandbox-suzutatsu-bq`.`us-central1`.test_entry_group.test_fileset AS b
ON
a.payload.department_code = b.department_code
※なお、クエリをフォーマットするボタンは選択できますが、クエリは変わらずでした。
現時点では、クエリ構文やデータ型に様々な制約事項がありますので、BigQueryの時と同じ気持ちで書くとエラーが出ます。実行時エラーもあります。
2019/11/18のその他の変更点
Cloud Dataflow SQLのUIでスキーマをデータソースに割り当てられるようになった
データソースのスキーマ定義画面にEdit schemaボタンが追加され、スキーマの設定が変えられるようになりました。
スキーマ定義が不適切でDataflowジョブが失敗した時に、UIからすぐ直せるのは便利です。
Cloud Dataflow SQL UIからCloud Pub/Subメッセージのコンテンツをプレビューできるようになった
データソースのスキーマ定義画面にトピックをプレビューというリンクが追加されました。
Pub/Subのトピックの詳細画面でメッセージを表示をクリックした時と同じ画面が表示されます。
さいごに
まだα版なので実戦投入はできませんが、SQLクエリでストリーミングデータの加工が書けるのは魅力的なので、今後の機能拡張にも期待したいです。