はじめに
今年(2026年)の2月からBizCodeXというプログラミングスクールに入り、現在は副業案件獲得を目標にPythonの学習を行っています。
そこの課題の一環としてアウトプットとなるプログラムを作成しており、こちらの記事では主にプログラムの内容について解説していきます。
やりたいことの概要
今回は「YouTubeで特定のキーワードを検索し、出てきた動画の情報(再生数や高評価数)をExcelファイルにまとめる作業を自動化する」ことを要件に設定しました。
YouTube動画のデータはYouTube Data APIを使用して取得し、pandasやopenpyxlでExcelファイルに情報をまとめていくことにしました。
作成したPythonプログラムの解説
ここでは今回作成したPythonプログラムの具体的な内容や手順を記載していきます。
1. YouTube Data API の利用準備
まず YouTube Data API を利用するためには以下の準備が必要になります。
- Googleアカウントの準備
- Google Cloudの設定
- APIキー
以下の記事が分かりやすかったため参考にしてください。
2. Pythonから検索用APIを叩いてデータを取得する
APIが利用できるようになったら、まずは検索用(Search)URLへリクエストを投げて、検索キーワードから取得できる動画のスニペット情報を取得します。
# requestsのインポート
import requests
# APIキーとエンドポイントURLの設定
API_KEY = '先ほど取得したAPIキー'
URL_SEARCH = 'https://www.googleapis.com/youtube/v3/search'
# 動画検索APIのパラメータを設定
params_search = {
'key': API_KEY, # 取得する情報のタイプ
'q': 'News', # 検索キーワード
'part': 'snippet', # スニペット情報
'type': 'video', # 取得する情報のタイプ
'maxResults': 10, # 取得件数の上限
}
# APIにリクエストを送信
res_search = requests.get(URL_SEARCH, params=params_search)
※なおAPI_KEYは機密情報になりますので、GitHub等のリモートリポジトリにアップロードはしないように気を付けてください。
実行すると以下の例の様なレスポンスが返ってきます。
{
"kind": "youtube#searchListResponse",
"etag": "pLwygpt4S4HLyGmO5LJbJ_PeLQg",
"nextPageToken": "CAEQAA",
"regionCode": "JP",
"pageInfo": {
"totalResults": 1000000,
"resultsPerPage": 1
},
"items": [
{
"kind": "youtube#searchResult",
"etag": "dUoofOQecuaa66FGUZXWeby4HQg",
"id": {
"kind": "youtube#video",
"videoId": "_uSO6YjSBbE"
},
"snippet": {
"publishedAt": "2026-02-26T08:45:10Z",
"channelId": "UCKjU3KzdbJE1EFcHVqXC3_g",
"title": "CBC News: The National | U.S. tells Canada to just accept tariffs",
"description": "Feb. 25, 2026 | U.S. President Donald Trump's trade envoy tells Canada to just accept higher tariffs as the price of making deals, ...",
"thumbnails": {
"default": {
"url": "https://i.ytimg.com/vi/_uSO6YjSBbE/default.jpg",
"width": 120,
"height": 90
},
"medium": {
"url": "https://i.ytimg.com/vi/_uSO6YjSBbE/mqdefault.jpg",
"width": 320,
"height": 180
},
"high": {
"url": "https://i.ytimg.com/vi/_uSO6YjSBbE/hqdefault.jpg",
"width": 480,
"height": 360
}
},
"channelTitle": "CBC News: The National",
"liveBroadcastContent": "none",
"publishTime": "2026-02-26T08:45:10Z"
}
}
]
}
3. 取得したデータから情報(動画タイトルなど)を抽出する
次に取得したデータから以下の情報を抽出していきます。
- 動画ID (
videoId) - 動画タイトル (
title) - チャンネル名 (
channelTitle)
抽出した情報はvideo_listという変数に格納していきます。
id_listにはIDのみを入れていき、後続の動画詳細情報を取得する際に使用します。
# レスポンスをJSONに変換し、動画IDとスニペット情報を取得
data_search = res_search.json()
item_list = data_search['items']
video_list = [] # 動画情報をまとめるリスト
id_list = [] # 動画IDリスト
for item in item_list:
video = {
'ID': item['id']['videoId'],
'タイトル': item['snippet']['title'],
'チャンネル名': item['snippet']['channelTitle'],
}
video_list.append(video)
id_list.append(item['id']['videoId'])
実行した結果、各リストには以下のようなデータが格納されます。
[{'ID': '_uSO6YjSBbE', 'タイトル': 'CBC News: The National | U.S. tells Canada to just accept tariffs', 'チャンネル名': 'CBC News: The National'}, {'ID': 'eykupkLCpFs', 'タイトル': 'ABC World News Tonight with David Muir Full Broadcast - Feb. 25, 2026', 'チャンネル名': 'ABC News'}]
['_uSO6YjSBbE', 'eykupkLCpFs']
4. 動画用APIを叩いてデータを取得する
次に動画用(Video)URLへリクエストを投げて、動画の統計情報を取得します。
# エンドポイントURLの設定
URL_VIDEO = 'https://www.googleapis.com/youtube/v3/videos'
# 動画統計情報APIのパラメータを設定(複数IDをカンマ区切りで指定)
params_video = {
'key': API_KEY,
'id': ','.join(id_list), # 'ID1,ID2,...'
'part': 'statistics', # 統計情報
}
# APIにリクエストを送信
res_video = requests.get(URL_VIDEO, params=params_video)
動画用APIから情報を取得する時に、idパラメーターに'ID1,ID2,..'のような形で複数のIDを文字列で指定出来る便利な仕様がありました。このお陰で余分なループが不要になりました。
先ほど作成したid_listをjoinメソッドにより,で連結させて必要な文字列に整形しました。
こちらを実行した結果、以下の例の様なレスポンスが返ってきます。
{
"kind": "youtube#videoListResponse",
"etag": "s3F54lM3qNCdlGu5O3q_nzA2DRo",
"items": [
{
"kind": "youtube#video",
"etag": "3FP3d4KVL183FPnB5MAH5JCRYyU",
"id": "_uSO6YjSBbE",
"statistics": {
"viewCount": "75283",
"likeCount": "610",
"favoriteCount": "0"
}
}
],
"pageInfo": {
"totalResults": 1,
"resultsPerPage": 1
}
}
5. 取得したデータから情報(再生数など)を抽出する
取得したデータから以下の情報を抽出し、video_listへ追加していきます。
- 再生回数 (
viewCount) - 高評価数 (
likeCount)
# レスポンスから再生回数・高評価数を取得してvideo_listに追加
data_video = res_video.json()
video_item_list = data_video['items']
for i in range(len(video_item_list)):
video_list[i]['再生回数'] = video_item_list[i]['statistics']['viewCount']
video_list[i]['高評価数'] = video_item_list[i]['statistics']['likeCount']
ここではvideo_listとvideo_item_listの各動画が同じ順番で入っている前提でループを回しているのですが、もし違っていた場合データの入れ違いが起こってしまうので注意が必要です。
一応検証で同じ並び順になることと、ループを少なく出来るという理由からこの方法を取っていますが、将来的にAPIの仕様が変更される可能性もあるためご留意ください。
実行した結果、video_listには以下のようなデータが格納されます。
[{'ID': '_uSO6YjSBbE',
'タイトル': 'CBC News: The National | U.S. tells Canada to just accept tariffs',
'チャンネル名': 'CBC News: The National',
'再生回数': '77255',
'高評価数': '617'},
{'ID': 'eykupkLCpFs',
'タイトル': 'ABC World News Tonight with David Muir Full Broadcast - Feb. 25, 2026',
'チャンネル名': 'ABC News',
'再生回数': '777594',
'高評価数': '10284'}]
これでExcelファイルにまとめるために、必要な情報を全て抽出することが出来ました。
6. 抽出したデータをExcelファイルとして保存する
それでは抽出した情報をExcelファイルに書き出します。
pandasをインポートして、video_listをデータフレームへ変換後、Excelファイルに書き出します。
なお、再生回数と高評価数の値はstr型になっているため、そのままだと並び替えやフォーマットが出来ません。そのためastypeメソッドでint型へ変換しておきます。
# pandasをインポート
import pandas as pd
# 動画情報をDataFrameに変換し、数値型にキャスト
df = pd.DataFrame(video_list)
df['再生回数'] = df['再生回数'].astype(int)
df['高評価数'] = df['高評価数'].astype(int)
# DataFrameをExcelファイルに出力
df.to_excel('youtube.xlsx', index=False)
実行した結果、同じフォルダにyoutube.xlsxというExcelファイルが出力されました。内容も問題なさそうです。
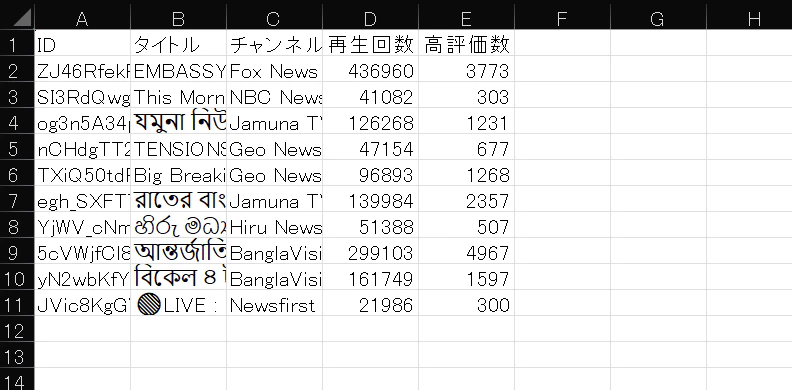
7. Excelを見やすく装飾する
このままだと少し味気ないので、仕上げにExcelファイルを装飾して見やすくしたいと思います。
装飾などのExcelファイルの操作にはopenpyxlのインポートが必要です。
以下の様な修正をしていきます。
- タイトル列とチャンネル名列の列幅を大きくする
- 1行目(ヘッダー)の背景色などのスタイルを設定する
- 再生回数・高評価数(D列・E列)で数値の書式を設定
# openpyxlのインポート
import openpyxl
from openpyxl.styles import PatternFill, Font, Alignment
# 出力したExcelファイルを開いてシートを取得
wb = openpyxl.load_workbook("youtube.xlsx")
ws = wb["Sheet1"]
# タイトル列・チャンネル名列の列幅を調整
ws.column_dimensions['B'].width = 50
ws.column_dimensions['C'].width = 30
# 1行目(ヘッダー行)のスタイルを設定(背景色・文字色・太字・中央揃え)
for col in range(1, ws.max_column + 1):
cell = ws.cell(row=1, column=col)
cell.fill = PatternFill(start_color="1F4E78", end_color="1F4E78", fill_type="solid")
cell.font = Font(color="FFFFFF", bold=True)
cell.alignment = Alignment(horizontal="center", vertical="center")
# 再生回数・高評価数(D列・E列)に桁区切り書式を設定
for i in range(2, ws.max_row + 1):
cell_D = ws.cell(row=i, column=4)
cell_E = ws.cell(row=i, column=5)
cell_D.number_format = r"#,##0"
cell_E.number_format = r"#,##0"
# 書式設定を反映してExcelファイルを上書き保存
wb.save('youtube.xlsx')
実行した結果、Excelファイルが以下のとおり修正されて少しだけ見やすくなりました。
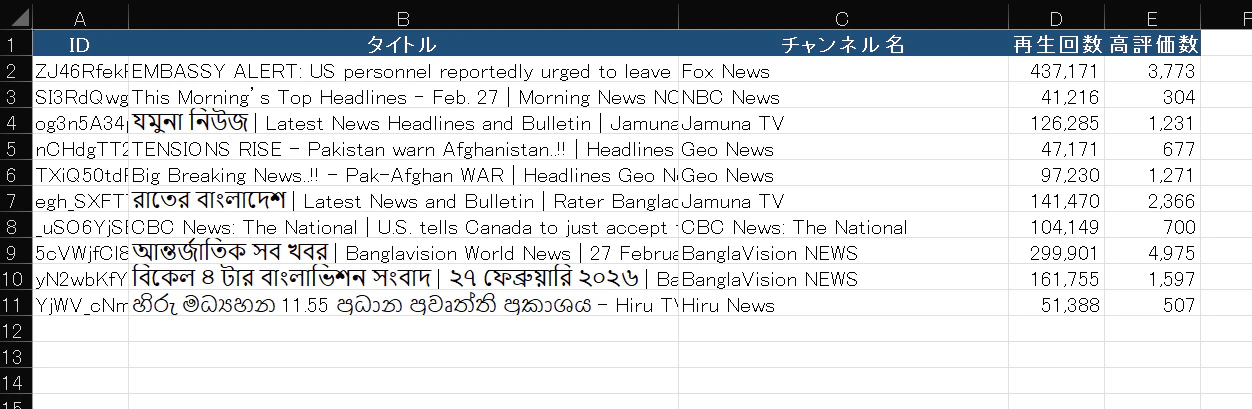
プログラムの内容は以上になります。
プログラム全体
これまでの内容をまとめました。
# ライブラリのインポート
import requests
import pandas as pd
import openpyxl
from openpyxl.styles import PatternFill, Font, Alignment
# APIキーとエンドポイントURLの設定
API_KEY = '先ほど取得したAPIキー'
URL_SEARCH = 'https://www.googleapis.com/youtube/v3/search'
URL_VIDEO = 'https://www.googleapis.com/youtube/v3/videos'
# 動画検索APIのパラメータを設定
params_search = {
'key': API_KEY, # 取得する情報のタイプ
'q': 'News', # 検索キーワード
'part': 'snippet', # スニペット情報
'type': 'video', # 取得する情報のタイプ
'maxResults': 10, # 取得件数の上限
}
# APIにリクエストを送信
res_search = requests.get(URL_SEARCH, params=params_search)
# レスポンスをJSONに変換し、動画IDとスニペット情報を取得
data_search = res_search.json()
item_list = data_search['items']
video_list = [] # 動画情報をまとめるリスト
id_list = [] # 動画IDリスト
for item in item_list:
video = {
'ID': item['id']['videoId'],
'タイトル': item['snippet']['title'],
'チャンネル名': item['snippet']['channelTitle'],
}
video_list.append(video)
id_list.append(item['id']['videoId'])
# 動画統計情報APIのパラメータを設定(複数IDをカンマ区切りで指定)
params_video = {
'key': API_KEY,
'id': ','.join(id_list), # 'ID1,ID2,...'
'part': 'statistics', # 統計情報
}
# APIにリクエストを送信
res_video = requests.get(URL_VIDEO, params=params_video)
# レスポンスから再生回数・高評価数を取得してvideo_listに追加
data_video = res_video.json()
video_item_list = data_video['items']
for i in range(len(video_item_list)):
video_list[i]['再生回数'] = video_item_list[i]['statistics']['viewCount']
video_list[i]['高評価数'] = video_item_list[i]['statistics']['likeCount']
# 動画情報をDataFrameに変換し、数値型にキャスト
df = pd.DataFrame(video_list)
df['再生回数'] = df['再生回数'].astype(int)
df['高評価数'] = df['高評価数'].astype(int)
# DataFrameをExcelファイルに出力
df.to_excel('youtube.xlsx', index=False)
# 出力したExcelファイルを開いてシートを取得
wb = openpyxl.load_workbook("youtube.xlsx")
ws = wb["Sheet1"]
# タイトル列・チャンネル名列の列幅を調整
ws.column_dimensions['B'].width = 50
ws.column_dimensions['C'].width = 30
# 1行目(ヘッダー行)のスタイルを設定(背景色・文字色・太字・中央揃え)
for col in range(1, ws.max_column + 1):
cell = ws.cell(row=1, column=col)
cell.fill = PatternFill(start_color="1F4E78", end_color="1F4E78", fill_type="solid")
cell.font = Font(color="FFFFFF", bold=True)
cell.alignment = Alignment(horizontal="center", vertical="center")
# 再生回数・高評価数(D列・E列)に桁区切り書式を設定
for i in range(2, ws.max_row + 1):
cell_D = ws.cell(row=i, column=4)
cell_E = ws.cell(row=i, column=5)
cell_D.number_format = r"#,##0"
cell_E.number_format = r"#,##0"
# 書式設定を反映してExcelファイルを上書き保存
wb.save('youtube.xlsx')
まとめ
本記事ではYouTube Data APIを使って特定のキーワードの動画情報を取得し、Excelに見やすくまとめるプログラムの内容を解説しました。
また、試みとしてAIに作成したコードをレビューしてもらったりしたのですが、(今回は練習用としてスルーしましたが)API_KEYをハードコードしている点や、forループの潜在的な問題点などを具体的に指摘してもらい、非常に頼りになるなと感じました。
今回のアウトプットで得た学びを活かし、引き続きより実践的なプログラムを作成出来るように学習を続けていきたいと思います。
最後まで読んでいただき、ありがとうございました!