
この記事は KLab Engineer Advent Calendar 2020 24日目の記事です。
Qiitaへの投稿は去年の12/24、つまりきっちり1年前のアドカレに続いて2回目になります suzuna-honda といいます。よろしくお願いします。
はじめに
Unityでテキストの描画を行う際、標準で用意されている選択肢には大きく2つ、「uGUI Text」と「TextMesh Pro」があります。
uGUI Text
uGUI Textは古くから存在する、Unity標準のテキスト描画システムです。
フォントファイルからビットマップを動的に生成し描画するダイナミックフォントという仕組みのおかげで、とにかく何も考えずにポン置きでテキストを画面に配置できる非常に便利なコンポーネントですが、設計の古さ故か、いくつか頭を抱えてしまう問題点を抱えています。
まず、ダイナミックフォントとはいえ最終的にはビットマップでフォントを描画しますので、テキストを持つオブジェクトを拡大すると、見た目がぼやけるだけではなく高周波の階段状ノイズが発生します。フォントサイズ自体を大きくすれば改善されますが、この場合はビットマップの再構築が必要となります。

より深刻なのが、uGUI Textのアウトライン(縁取り)描画です。アウトラインはテキストの視認性確保のためにとても重要な機能です。これがどのように実装されているかというと、テキスト描画用の頂点バッファを丸々4倍分複製し、斜め4方向に位置を少しずらして頂点カラーを書き換えています。このため、アウトラインを太くすると下の画像のようにアウトラインの見た目がおかしくなります。

また、アウトラインの付いているテキストが更新される度に、CPU上で頂点バッファの複製/書き換えが行われます。一度に更新される文字数が多くなると、この頂点バッファ複製処理でメインスレッドを長時間占有してしまいますので、見苦しいスパイクの原因になり得ます。
何故かインデックスバッファ=共有頂点を使っておらず1文字の矩形一つに6頂点が使われており、この点での効率も良くありません。パフォーマンスチューニングの観点では割とあり得ない作りです。(Unityは例えば他にも、公式ライブラリのフルスクリーンポスト処理でトライアングル2枚を使っていたり(一般的には1枚で画面全体を覆います、誤差とはいえその方が効率良いですからね)とか、なんで?って仕様がとても多いです)

また、シンプルに重ね塗りを繰り返しますので、結果オーバードローの面積も5倍となり、GPUフィル負荷も無視できなくなります。そして、テキスト全体を半透明で描画してしまうと見た目が壊れますので、アウトラインを使いつつ半透明でテキスト描画することはできません。
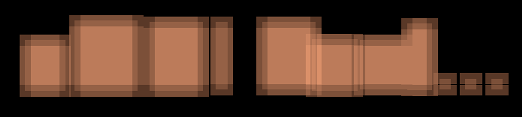
複製する頂点を4方向より更に細かく増やすことで、見た目の破綻を軽減するハックがよく使われているようです。が、標準で4方向までとなっているのは上記のような負荷の問題があってのものですから、あまり安易に濫用するのはお勧めできません(複製する頂点数も、オーバードロー回数もリニアに増えてしまいます)。更にアウトラインを2つ3つ重ねたりした日には、そこには宇宙が広がっています(困ったことに、そこそこよく見かけるんですよね...)。
その他にも例えば「(標準では)字間が調整できない」など諸々の問題があり、Unity社としては将来的にはuGUI Textを非推奨として、次に説明するTextMesh Proを次世代の標準テキスト描画システムとして移行を推奨しているようです。
TextMesh Pro
TextMesh Proはもともと有償の外部アセットであったものがUnity社に買収され無償のパッケージとして誰でも使えるようになったテキスト描画システムです。
大きな特徴としてはやはり、Signed Distance Field(SDF)テクスチャを用いたフォント描画手法を用いている点がまず挙げられます。
Signed Distance Field(SDF)フォント?
https://steamcdn-a.akamaihd.net/apps/valve/2007/SIGGRAPH2007_AlphaTestedMagnification.pdf
こちらの資料が大元ネタとなっている描画手法です。
SDFを用いたフォントの描画では、テクスチャにはカラー情報を持たせず、距離をもたせます。

直訳「符号付き距離場」の名前の通り、境界線(フォントでいえば縁の部分ですね)からの距離を各テクセルに格納します。更にフォントの内側と外側で+-の符号を変えることで、その場所がフォントとして塗る場所なのか、塗らない場所なのかを判断できるようになります。

(https://dspace.cvut.cz/bitstream/handle/10467/62770/F8-DP-2015-Chlumsky-Viktor-thesis.pdf より引用)
この「距離」というのがミソで、これによりテクスチャを拡大した際、バイリニア補間による恩恵を最大限得られるようになります。要は境界線がボケることなく、くっきりとした輪郭で描画することができるのです。この「拡大表示に耐性がある」ことがSDFを使ってフォントを描画する最大のメリットです。

↑をSDFフォントとしてレンダリングした結果が↓になります。どんなに拡大しても、uGUI Textのようなボヤけた表示にはなりません。

ただし色の情報をテクスチャに持たせられませんので、テクスチャから拾える距離の情報と、別途用意した外部パラメータを用いて、シェーダを使ってコネコネしてフォントの描画色を生成する必要があります。ですがこれはむしろプラス要素で、見方を変えると、アウトラインやグローといったフォントの装飾を低コストで用意することが出来るようになるわけです。これもSDFフォントを採用する大きなメリットの一つとなっています。
TextMesh Proは特にこの装飾の追加に異常なほど力を入れており、無数のバリエーション・カスタマイズを実現しています。とはいえ、個人的にはゴテゴテした装飾は好きではなく、特にゲーム用途においては高品質なアウトライン・グロー・ドロップシャドウがあれば十分かな、と認識しています。「高品質な」というのが大事なポイントです。
multi-channel SDF (MSDF)?
SDFフォントは特に拡大時の輪郭線において優秀なルックを提供してくれますが、一方で欠点もあります。解像度が十分でないとき、「角が欠ける/丸くなる」というのがその典型です。

(https://github.com/Chlumsky/msdfgen より引用)
この画像の中央や右の文字のように、1つの距離情報(=single-channel)を持たせた一般的なSDFテクスチャを使って描画を行うと、角が欠けたり丸まってしまうのです。この問題を解決するために、複数の距離情報をもたせた(=multi-channel)SDFフォントテクスチャ、というものがあります。左の文字がmulti-channelなSDFで描画した文字に該当しますが、角が正しく表現されていますね。

具体例:角の丸まった矩形2つのANDを取れば、角の丸まっていないシャープな菱形が手に入る
一見すると欠点を克服したベストな選択のように見えますが、実は致命的なネガティブ要素があります。複数チャンネルを組み合わせて一つの境界を作るアルゴリズムの都合上、「境界線からのスカラー距離」という貴重な情報が手に入らなくなってしまうのです。これが何を意味しているかというと、フォントの装飾が作りにくくなる、ということなのです。例えばアウトラインを描画したければ、頂点を複製して位置をずらして...と、uGUI Textの世代に逆戻りした手間とCPU/GPUコストが発生してしまうわけです。
また多チャンネルの情報が必要となりますので、テクスチャサイズは数倍に膨れ上がります。折角の小さい解像度(=省サイズ)でも拡大に耐えうるというウリも弱くなってしまうのです。じゃあsingle-channelの通常のSDFで解像度上げた方が装飾も付けられるし良くね?ってなりますよね。
もちろん、拡大に強いというメリットはより強固になるわけですから「使いみちが無い」とまでは言いませんが、以上のような理由から現在のところ主流の手法とはなっていません。
multi-channel SDF (MSDF)を活かせる場としては、フォントの描画よりも、例えば道路の白線や標識であったり、UI用のアイコンであったりといった、単色でかつクッキリした表現が必要な描画用途ではないかな、と私は考えます。
そして、TextMesh Pro
TextMesh Proはsingle-channelのSDFフォントを描画手法としたテキスト描画システムです。uGUI Text同様にシンプルに扱えることを目指しているようで、1pass描画で全てを完結させています。
簡単かつ便利であることは間違いないのですが、その代償として、以下のような問題点があります。
問題点1:文字同士の重なりを考慮していない
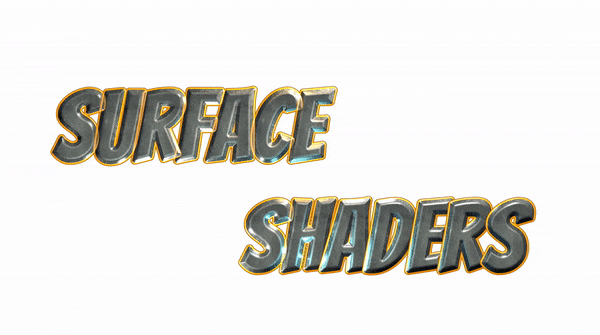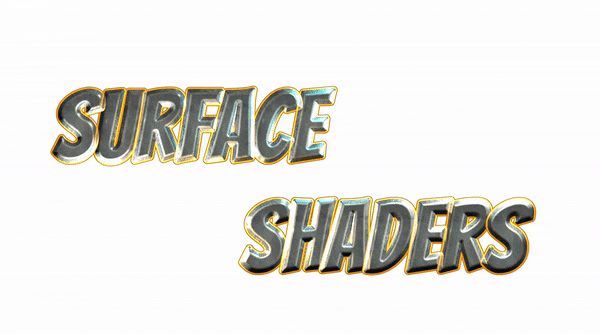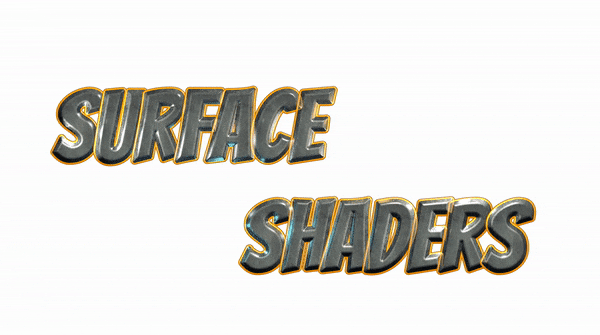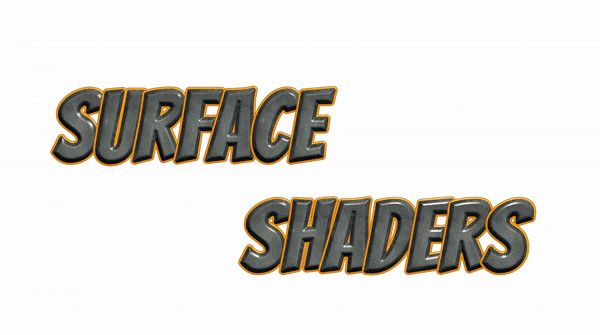
(https://blogs.unity3d.com/jp/2018/10/16/making-the-most-of-textmesh-pro-in-unity-2018/ より引用)
それぞれの文字同士の表示プライオリティが明確に破綻しています(文字同士がくっついている部分をよく見てください、おかしくなっていることが確認できますよね?)。後の文字が基本的には優先されて描かれているようですが、ハイライトのアニメーションによっては前の文字が上にあるように見えたり、挙動がとても怪しいです。(この画像を公式ブログに載せてしまうのか、と最初に読んだ当時とても衝撃を受けました。正直は美徳ですが、あまりにも正直過ぎるといいますか...)
実はこの文字同士の重なり破綻問題、uGUI Textでは問題なく表示することができます。アウトラインを先に描画するように頂点バッファの並びが調整されていますので、文字同士が重なっても見た目がおかしくなることはありません。uGUI Textと比べてTextMesh Proの方がスペック上完全に上位互換というわけではないことには留意の必要があります。
問題点2:半透明が破綻する

アウトラインを単色にして、アウトラインが重なる程度の衝突に抑えれば、前述のような見た目の破綻はバレにくくなります。が、しかし、今度は半透明でテキストを描画した際に重なった部分が破綻してしまいます。半透明を使ってふわっとテキストをフェードイン/フェードアウト、させたくないですか?
問題点3:ドロップシャドウが大きく動かせない

他の問題に比べたら些細なことですが、1pass描画で全てを完結させる都合上、ドロップシャドウの配置をあまり大きく動かせません。ドロップシャドウを描画するためだけに負荷の高いフィル面積が無駄に増えてしまいますから、仕方がありません。上の画像は、TextMesh Proでドロップシャドウを右下に最大限ずらした結果です。
というわけで
結局のところ、TextMesh Proを用いてテキスト描画を行う際には「装飾込みでも文字同士が重ならないように注意してUI構築を行う」か、あるいは「見た目が多少破綻しても気にしない」という選択肢のどちらかを取ることになります。Unityを使う以上、後者に慣れるのが正義...という気もしますが、テキストってユーザーにとって一番目を引く部分ですから、言うまでもなく大事ですよね...と私は思うわけです。
ので、これらの問題点を改善した、新しいテキスト描画システムを自作します。しました。
ここまで、全てただの前置きです。ここからが本題です。長いよ...
下準備
SDFフォントテクスチャの用意
今回自作するテキスト描画システムも、TextMesh Pro同様にSDFフォントを使用します。もう21世紀も1/5を過ぎたわけですから、テキスト描画にSDFフォントを使わないとかあり得ないわけです。
テクスチャは事前にフォントデータからオフラインで生成するツールを製作しました。現在のTextMesh Proはダイナミックフォントとしてランタイムでテクスチャ生成が可能ですが、そこまでは手が回っていません。

要は境界線からの符号付き距離を書き出せればそれで良いので、今回はブルートフォースで実装してしまいました。SDFフォントはその距離情報の精度が地味に大事です、1文字1文字丁寧に生成しましょう。
ダイナミックフォントに対応するなど、高速化が必要な際には
http://webstaff.itn.liu.se/~stegu/edtaa/
こちらの資料等が参考になります。
https://techblog.kayac.com/unity_advent_calendar_2018_23
こちらのブログではテクスチャ生成をComputeShaderを用いて高速化を行っています。とても興味深いです。
フォント描画用の各種情報の用意
テキストの描画にはそれぞれのフォント毎のパラメータが必要になります。配置/UV等の情報は当然として、
・カーニング:例えば"V"と"A"が並んだときは普段よりもスペースを詰める、といった処理
・リガチャ:例えば"f"と"i"が並んだときに"fi"をくっついた1文字にまとめる、といった処理
等々の為に、フォントファイルから情報を抽出し、ランタイムでそれを反映させなければなりません。
今回は話が膨らみすぎるので割愛しますが、とても泥臭くて辛いです。
実装
当たり前ですがランタイム実装はUnity上で行います。バージョン・環境はまあ、最近のものであれば特に問わないのではないでしょうか。
0.SDF Font描画用テンポラリRenderTargetを用意
画面解像度と同じサイズのRenderTexture(RGBA8_Unorm)を確保します。他で使っているバッファの使い回しで構いません。DepthTestを行うので、DepthBufferも同サイズで用意します。Depthの精度は16bitで十分で、ステンシルバッファは使いません。
1.RenderTargetのクリア
描画前にはまずColor/Depthのクリアを行いましょう。(わざわざ書くことじゃないように見えますが、後々理由が分かります)
2.フォントをSDFテクスチャを用いて描画
SDFフォントテクスチャを参照し、フォントの縁からの符号付き距離値を拾います。この値を元に、フォントを描画します。ここまではTextMesh Proがやっていることと変わりませんが、以下の点が異なります。
・DepthTest, 及びDepthWriteを行う
PixelShader中でSDFの距離値を深度(SV_DEPTH)として出力し、その上でDepthTestを行います。フォントの"芯"に近い部位であるほど表示の優先順位を上げることで、アウトラインによってフォント本体が隠れてしまう...といったアーティファクトを避けることが出来ます。
・OpaqueでRenderTargetへ描画する
BackBufferへいきなり半透明で描いてしまうと、いくらDepthTestが働いていても、文字が重なった際に見た目が破綻します。ので、RenderTargetに対して不透明で描画します。結果、最も優先度の高い部位だけが残ります。
不透明で描きますが、アルファ値は透明度としてRenderTargetへ出力しておきます。これはコンポジット時に参照され、そのタイミングで半透明として機能します。また、乗算済みアルファを適用します(乗算済みアルファについては後述します)。
3.RenderTargetをBackBufferへコンポジット
RenderTargetは乗算済みアルファで作りましたので、ブレンドファクターはSrc:One, Dst:OneMinusSrcAlphaでBackBufferへコンポジット描画を行います。
このとき、参照するUVをずらしてRenderTargetのアルファ値(余裕があればデプス値も使いたいのですが...)を読み、この値を元にドロップシャドウを描画しています。ドロップシャドウ専用の描画パスは必要ありません。
実装としては以上です。意外とシンプルにまとまりましたね。この時点では...。
結果、どんな絵が得られたか?

緑のフォントに、白と黒の2重のアウトライン+ドロップシャドウを付けた場合はこんな見た目になります。白いアウトラインの厚みを変化させています。TextMesh Proのようにアウトラインが他の文字の本体にめり込んだりすることなく描画できていることが分かるでしょうか?まさにこれが、今回自作したテキスト描画システムでやりたかったことです。

字間を変えて文字同士がくっついてしまっても見た目は破綻しません。レイアウト構築もこれで楽になりますよね。

透明度もこのように調整し放題です。もちろん破綻はありません。ドロップシャドウも勝手にアルファ値に応じて薄くなってくれます。便利ですね。

グリフやアウトラインのどれかだけアルファ値を減らす、といった調整も自在なわけです。
補足
乗算済みアルファ(premultiplied alpha)とは
普段はラスターオペレーション(ROP)内のブレンドファクターを通常のアルファブレンド:Src = SrcColor * SrcAlphaとしている部分に関して、シェーダ内あるいはそれ以前に、アルファ値を予めRGBカラー値に乗算しておく手法です。事前乗算アルファとも呼ばれます。
(シェーダで行う場合は)シェーダ命令数が増え、カラー精度も少々犠牲になる可能性がありますが、バイリニアフィルタリングを通した際の透明部分と不透明部分の境界で色が漏れる/腐る問題が解決されます。UI描画・コンポジットには必須のテクニックです。
higenekoさんのブログ記事が詳細解説として非常にまとまっていて素晴らしかったのですが、消えてしまっていますね...残念です(youtube動画のみ生き残っていました: https://youtu.be/dU9AXzCabiM )。
乗算済みアルファを利用する副次的なメリットとして、加算合成とアルファブレンドをレンダーステートを切り替えずに(=コンテキストスイッチを発生させずに)共存させることができるようになります。これは古くはMetalGearSolid4にて「ブレンドバッファ」という手法でやられていたものと同等です( https://game.watch.impress.co.jp/docs/20081203/3dmg4.htm )。
Unityにはレンダーステートが切り替わらないドローコールを1つにまとめる「バッチング」という優秀な機能がありますので、それを期待する意味でも、乗算済みアルファは検討の価値が大いにあります。

今回のフォント描画でも全面的に乗算済みアルファを採用しており、ルック改善とともに、グロー(フォント周辺の発光)表現を加算合成/アルファブレンドをグラデーションで調整可能な仕組みを用意しました。
ソフトエッジ化によるアンチエイリアシング
UI描画で大事なことは、アンチエイリアシングについての配慮です。UI描画はTemporalAAやFXAAといったポストプロセスとしてのアンチエイリアシングによる画質サポートを期待することが出来ません。また、SDFフォント描画はポリゴンエッジをなぞらないので、MSAAはエイリアシング改善に全く繋がりませんし、SSAAは負荷の面で頼ること自体がリスキーです。
しかし、アンチエイリアシングを一切意識しないテキスト描画は非常に汚いです。例えばフォントの本体(グリフ)とアウトラインをアンチエイリアシングなしにパッキリと分けてしまうと、非常に見苦しい見た目になります。ですので、これらの間をsmoothstep()である程度クロスフェードさせて馴染ませてやることでソフトエッジ化を図り、結果としてアンチエイリアシングを実現しています。単純に静止画としての画質だけではなく、サブピクセル単位のテキスト配置/移動における時間軸エイリアシングにも良い影響があります。
ソフトエッジなし

適度なソフトエッジ

やりすぎソフトエッジ

このクロスフェード強度は調整できるようにしており、例えばテキストをゆっくり動かす際などはエイリアシングが目立つのでフェード強度を強めに取り、逆に動かないテキストであれば弱めにすることでシャープな見栄えを確保できます。ボケ具合とチラツキ具合はトレードオフの関係なので、アーティストさんが調整できるのがベストだと判断しています。
ソフトエッジあり/なしでテキストをゆっくり動かした際のエイリアシング改善度合いは、以下のアニメーション画像を見ていたたければ一目瞭然ではないでしょうか。AAなどは全て切った状態で、ソフトエッジのパラメータ調整以外は全て同じ条件で等倍表示しています。下の画像も微妙にカクついている...ように見えるのはキャプチャ時のフレームレートのせいで、実際は引っかかることは一切なく滑らかに動いています。


さらにもう一つ、エイリアシングは改善したいがボケさせたくない、ある程度GPU演算リソースを費やしてもOK、といった状況の為に、フォント描画シェーダ内部でスーパーサンプリングを行いアンチエイリアシングを実現する実装も行っています。GPUコストパフォーマンスという観点では最悪といえますので、実際に使える環境は限られてしまいますが、それでも簡単に高画質化を狙える選択肢はあって誰も損はしません。
レイヤー化
ひとまず狙い通り、TextMesh Proの問題点を改善したテキスト描画システムを作ることができました。では、これで完成?いや、残念ながら問題はまだ残っています。次のアニメーション画像を御覧ください。

2つの文字列が混ざって滅茶苦茶な見た目になってしまいました。同一文字列の連続する文字同士はくっついて欲しいわけですが、連続していないそれぞれ別のテキストであるならば、くっつかずに分離して描画して欲しいわけです。というわけで、コードに修正を入れていきましょう。
まずは「まとまって描画したい文字のリスト」を「レイヤー」としてそれぞれグルーピングします。これはテキスト描画を要求する側がレイヤーのIDとして指定します。そして描画システム側は、このレイヤー毎に今まで実装した一連の処理(RenderTargetのクリア→テキストのレンダリング→BackBufferへのコンポジット)を繰り返していきます。
このとき、RenderTargetの全画面領域に対してバッファクリア及びコンポジットを毎回行っていくのは処理負荷の面で大きな無駄になりますので、テキストの描画される範囲をダーティな領域としてAABBを予めCPU側で構築しておいて、この範囲のみバッファクリアとコンポジットを行うように修正しました。これで発生するGPUフィル負荷も最小限に抑えられるはずです。
その結果、下の画像のようになりました。

このシーンでは2つのレイヤーを用意して処理を分離させることで、意図通りの表現を得ることが出来ました!
おおよそ満足のいく結果が得られて良かったのは良かったのですが、ただ、少々仕組みがややこしくなってしまいました。特にテキスト描画コール側にレイヤーのIDを指定させる、といった仕様はあまり美しいとは言えませんね。TextMesh Proが問題点を抱えつつも現状の仕様となっているのは、このような煩雑さを避けてなるべくシンプルに使えるようにするため、なのでしょうね。
負荷について
PixelShaderでのSV_DEPTH出力によるDepth書き換えは、ハードウェアにもよりますが基本的にとても重たい処理になります。これはEarly Z-Cullingと呼ばれるGPU内部の最適化処理が走れなくなる為です。またコンポジットの分、pass数はTextMesh Proと比べて1pass増えて2pass(バッファクリアも含めれば3pass)描画とフィル回数は増えてしまっています。
以上のことから、GPU負荷が微妙に気になりますね。uGUI Textでアウトラインをベタベタ追加したものよりはマシだと思いますが、TextMesh Proで変に装飾を付けていない状態よりは確実に重たいでしょう。モバイルでロースペック端末もサポート対象、となると少々厳しいかもしれません。文字の総数&フィル面積がそこまで多く大きくなければ気にしなくてよい程度だとは思いますが、モバイルのロースペックは本当にびっくりするくらいロースペックなんですよね...いずれにしても、もし実際のゲームに組み込む際は、その前にきちんとプロファイリングする必要があるでしょう。なぜ今やらないかって?答えは単純、面倒だからです。
CPU負荷についてはuGUI Text/TextMesh Proと比べて重たくなる要素が見当たらないので問題ないでしょう。
メモリ負荷は...ASCIIなフォントに絞って使う、程度であれば気楽に扱えそうですが、日本語やその他Unicode圏に対応しようとするとなかなかハードそうですね。ダイナミックフォントに対応すればある程度は解決しますが...。
さいごに
いかがでしたか?今回はテキストの描画というニッチなネタでした。本当は別のネタを記事にする予定だったのですが、人生の時間配分をまたミスってしまい、仕方なく有り合わせで済ませてしまいました。
現実にゲームアプリのタイトルに組み込む、となると、例えば禁則処理であったり、アラビア語のように逆方向に進む言語への対応だったり、考えなければならない、そして正直なところ手間とリターンが見合わない近寄りたくない問題が山積しているのがこの界隈です。
何も考えずにテキストが描画できるuGUI TextやTextMesh Proはとても優秀で、見た目の破綻やパフォーマンス面なんかよりも重要ではあるんですよね、正直なところを言ってしまうと。
ちなみに、この記事に使われている画像は、引用先から引っ張ってきたものを除いて全て今回実装したテキスト描画システムによって作られています。ページの一番上に配置したタイトル画像もその一つです。このようなテキストが、ランタイムで動的に表示できる...というのは、結構なインパクトがありませんか?UIデザイナーの皆さん。
それではまた、来年のアドカレ12/24に投稿できたらいいですね!
