この記事は KLab Engineer Advent Calendar 2019 24日目の記事です。
AdventCalendarどころか、Qiitaへの、もっと言えばネットに向けた技術エントリの投稿自体が初めてになります suzuna-honda といいます。よろしくお願いします。
はじめに
私は書籍をスキャンして電子書籍として読む、いわゆる「本の自炊」を趣味としています。
不眠症のケがあり、眠くなるまでの暇潰しとして、自炊した本を読書するのが日課になっています。枕の横にはiPadが欠かせません。
どの程度、深く、この「本の自炊」と向き合っているかといいますと、
- 書籍のスキャン
- 1冊ごとにパッケージング、管理の為のタグ付け
- スキャンした画像の画質調整、端末(iPad/iPhone)への最適化
- 端末(iPad/iPhone)へのデータ転送、閲覧
までの一連のワークフロー、ほぼ全てのツール/ビューワを自作して揃えています。
ハードウェア系、要はスキャナーやiPad/iPhoneに関しては流石に自作しようがなく、仕方なく市販品をそのまま使っています。一方、ソフトウェア系で唯一自作できていないのが「スキャナーを動かすスキャン用アプリ」です。某メーカーの業務用スキャナーを愛用しており、この機種にはSDKが存在していまして、ドライバレベルで叩けるスキャン用アプリを作ることが出来る、という触れ込みなのですが、メーカーに問い合わせたところ「法人じゃないとSDKは出せない」と返答されてしまいました。ので泣く泣く自作を断念しています。この理由の為だけに、いつか法人を作るかもしれません。
動いているもの
自作ビューワ上で実際にどのようなUXを得られているのか、は、動画を観てもらうのが手っ取り早いですね。
— suzuna (@suzuna7144) December 23, 2019
iOSネイティブアプリとして製作しています。開発初期はObjective-Cで書いていましたが、今はSwiftに書き直してあります。高速化の為に一部C++で書いています。
「1/120秒以上メインスレッド/ユーザーを待たせない」というポリシーを最優先しています。悪魔的なサクサク感がウリです。故に、この手の電子書籍ビューワによくあるページ移動アニメーションすらも一切省いてあります。待たされるのが嫌いなのでそうしているだけで、出来ないわけじゃないんですよ。
書籍閲覧時の高速ページ移動は、サムネイルで誤魔化したりはしていません。1ページ1ページ通常通りの画像をデコードし表示しています。
「物理な本をパラパラめくってぼんやり中身を確認する、あの感覚をどうやって電子書籍でエミュレーションするか」という命題に対して、私なりの答えとして圧倒的なスピードを実現しました。「なんとなく本の中身が分かる」という目的には多少近づけた、かな、と自負しています。
完璧な解答は別の方向性な気もしていますので、試行錯誤の日々は続きますが。あとシンプルに速すぎる気もしますね。でも操作していてめっちゃ気持ちいいんですよこれ。
書籍データはWifi経由で端末のストレージに落とすことが出来、一度ダウンロードしておけばキャッシュされオフラインでいつでも閲覧が可能になります。ファイルサーバは普通のその辺にあるNASで、SMBで繋いでいます。
タッチパネルによる操作も出来ますが、bluetoothコントローラを用いておおよその操作が可能となっています。普段はこちらをメインで利用しています。指で画面が隠れたり画面が指紋で汚れるのが嫌というのもありますが、寒い冬場に、掛け布団から手を出さなくても閲覧可能にしたかったのが一番の理由です。
語りたいネタはまだまだうんざりするくらいありますが、ビューワの解説は本エントリの本筋ではないのでこれくらいにしておきます。
一度このようなUI/UXに慣れてしまうと、kindleに代表される既存の電子書籍はどれもこれも、ビューワの出来も微妙、画像データの画質も微妙、と身体が受け付けなくなります。それが良いことなのか悪いことなのかは、よく分かりません。
そして快適な閲覧環境を実現するには、ビューワ側の最適化も勿論のこと、書籍データ側の工夫(K.U.F.U.)も大きなウェイトを占めます。そんなわけでこのエントリでは...
本題はじめ
本をスキャンして得られた画像データを、どのように画質調整して実際に表示する画像データに加工するか、といった部分に関していくつかピックアップして雑に解説してみようと思います。
スキャンした直後の素の状態の画像データサンプルです。サイトに上げる為、解像度の25%縮小のみ行っています。
 |
|---|
引用全ての出典元 著者:九井諒子, 書名:ダンジョン飯 第6巻, 出版社:KADOKAWA, 出版年:2018.
使っているスキャナーの最大性能である600dpiでスキャンしています。画質調整に対する耐久力という意味で解像度は最も大きなファクターです。とにかく高いに越したことはありません。
スキャナー側での自動的な画像処理/調整は極力行わせない設定にしており、なるべく無加工な生の状態のままの画像データを出力させ、これを素材としてストレージに保存してあります。画質調整は非可逆な操作となりますので、一度何か変更を加えてしまうと、その後により良い画質調整アルゴリズムを思いついたとしても取り返しがつかなくなります。ので、何も加工していないデータを残しておくことはとても重要です。ストレージこそ圧迫しますが、今はHDD安いので気にしないのが丸いです。
そしてこれが最終的な画質調整まで完了させた、iPadで実際に閲覧される画像データです。iPad Pro 11inchに最適化されており、こちらも50%縮小のみ行っています。
 |
|---|
見比べて頂けると分かりますが、だいぶ印象が変わりますよね。個々人で好みの差はあると思いますが、私個人としては断然すっきり読みやすくなっていると認識しています。画質調整は全自動で行っており、手動で発生する手間は「エンコード」と書かれたボタンを一つ押すだけです。
(サイズの縮小によってこの画像では変わってしまっているとは思いますが、)4bppつまり16階調のグレイスケールにまで色数を落としています。これによりファイルサイズを大きく低減させ、読み込みとデコードの高速化を図ることが出来ます。より強く階調数を落とすとファイルサイズは更に小さくなりますが、私の目で劣化の判別不可能なギリギリのラインが16階調でした。ただしディザは必須です。それなりに高品質なディザを入れないと16階調でも結構きつい絵になります。とはいえ、ディザはファイルサイズが膨らむ、という諸刃の剣だったりも...。バランス加減が問われます。
これより先、真面目な画像処理の専門家からすると噴飯もの、ツッコミどころが多々あるかと思います。所詮はお遊びですので、生暖かい目でお読みください。
なおOpenCVなどを活用するのが正解なのは分かりきっているのですが、あくまで趣味なので敢えて全コード自作しています。
カラー印刷/単色印刷の判定
単色印刷された紙面と、カラー印刷された紙面とでは、画質調整で動ける範囲が大きく変わります。単色印刷の場合、紙の質感は基本的にノイズと判断でき「単色のインク」と「紙」の2軸のみを考慮の対象に絞れるので、ドラスティックな画質調整アプローチを取ることができます。要はアドが取れます。
ここで問題となるのが「カラー印刷なのか単色印刷なのかを判定」する方法です。
この程度でも、私のような初心者レベルの人間には結構ハードルが高いのです。
画像処理に少しでも慣れてる人ならば、「色空間HSVにしてHueの標準偏差でもみて閾値超えてたらカラー判定するだけじゃね?しょうもな」くらいはパッと出てくるかと思いますが、そこまで単純な話ではありません。
なぜかと言うと、スキャンした紙は特に古い本だと「日焼け」していることが多いんですね。
本のページを開く側(小口)は真っ赤に焼けていて、内側(のど)は綺麗な淡黄色、綺麗なグラデーションになっている...なんて状態もレアケースではありません。このような紙の状態では、人間の目にはモノクロのページに見えていても、パコソンさんにそれを理解させるのはなかなかに大変なのです。他にも、単色印刷だけどインクが青色だったり、と、シンプルなカラー/グレスケ判定の枠に収めるのが難しいケースが稀によくあるのが自炊画像の扱いの難しさです。今回用意したサンプル画像(↑)も、グレイスケールか?って言われたら違いますよね。
現状、私が行っている判定方法は、複数のアプローチを組み合わせています。
1つ目の方法は先程書いたような、HueやSaturationなどの偏り/ばらつきから経験則的に判定する手段です。
破綻するケースが多々あり信頼性には欠けますが、パラメータの調整でなんとかやりくりしています。
2つ目の方法は減色を用います。
k-means法という有名なアルゴリズムを少し弄って、
- 画像をn*n(非常に小さい解像度)まで平均画素法で縮小処理を行い、それぞれの色を代表色とします。
- オリジナル画像の全ピクセルに対して、代表色から一番近いものを選び、クラスタとしてグルーピングします。
- クラスタ内の画素の色の平均を取り、新たな代表色とします。
- 代表色が閾値以上に近いクラスタを同じクラスタとしてまとめます。
- 代表色が変化せずクラスタ数も落ち着くまで2-4を繰り返します。
- クラスタ数が多く残ったらカラー、少なければ単色印刷と判定します。
日焼けの度合いが激しいと誤判定しますが、意外とそれっぽく判定できています。
減色アルゴリズムを使ってカラー判定、というアイディアは自分で考えました。自賛になりますがそこそこ正しく判定できています。
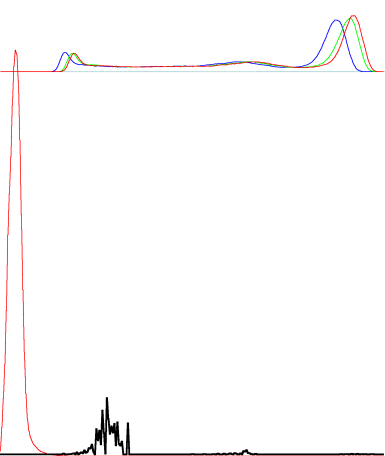
3つ目の方法はヒストグラムを用います。
日焼けした紙、というものは大抵の紙質において青>緑>赤の順に情報量が削られた状態とみなすことができます。この削られ具合は経験則上、ある程度リニアになっています。ので、RGB毎にヒストグラムを用意し、その形状が相似形であればモノクロ印刷であると判断してもいいのでは、という考え方です。問題点として、この手法では青いインクなど特殊な単色印刷は認識できません。
デバッグ用に出力している、先程の画像データサンプルのヒストグラム情報です(他の情報も混ざっていますが気にしないでください)。ここまで綺麗に相似形だとモノクロ画像だろうな、と判断しても問題なさそうですよね。
 |
|---|
以上の3つの手法を経験則で組み合わせて、総合的に判定を行っています。
結構な手間と時間を掛けて調整はしているのですが、誤判定はまだ偶に起きています。「経験則というのがダメなんじゃないですか?」という答えは既に出ているのですが、そこは最終段にて触れますので...
紙の形状に切り取る
サンプル画像のオリジナルを確認して頂けると分かりますが、紙の形状よりも少し大きめにスキャンしています、ので、実際の紙の形状を判定する必要があります。スキャナに紙の形状/サイズを自動判定させることもできますが、誤爆して変な形状に切り取られてしまうことがままあり、現在は自前で判定することにしています。
処理は上下左右の辺毎にそれぞれ行います。適当な間隔で、端から中央へ向けてピクセルのサンプリングを進め、閾値以上の色を見つけた座標を保持しておきます。これらの座標群に対して、実際の紙の形状を構成する直線を求めます。典型的な最小二乗法の出番ですね。とはいえ、単なる最小二乗法ではノイズに弱く使い物になりませんので、ロバスト推定と呼ばれるもう少し賢いアルゴリズムを扱います。ここでは、その中でもRANSACとLMedSというアルゴリズム、これらを足して3で割ったような代物を実装しています。
- 座標郡の中からランダムに数点選択する。今回は直線なので2点でOK
- 選択した2点から直線の式を作成
- 選ばれなかった座標群と2で求めた直線との最短距離の分散を求める
- 1から3を複数回繰り返し、そのうち最も分散の小さくなった直線を選択する
- 4辺でそれぞれ同じ様に直線を求め、形状を把握し外枠を切り落とす
RANSACのような閾値を決めるのが難しい、LMedSのような中央値だと色々と問題が出る、と試行錯誤した結果このような実装になっています。
これにより求まる直線が以下のようになります。

緑の点がサンプリングで見つけた座標郡、白い線がロバスト推定で求められた直線です。綺麗に紙の形状を拾っていますね。申し分ない精度です!
なお、紙の形状は綺麗な直線になっておらず、弓形に反っていたりすることがそこそこありますので、求める先を直線ではなくn次の曲線等にした方が、より正しい結果を得られるかとは思います。↑の画像を見ても確認出来ますが、左辺側が微妙に紙の形状に対して対応しきれておらず、左下がはみ出てしまっていますね。しかし、私のようなアリアハン住民には少々荷が勝ちすぎており、そこまで手が回っていません。
また余談ではありますが、RANSACにしろLMedSにしろ乱数を用いるので、結果が冪等ではなくなってしまう点が懸念点として挙げられます。私のツールではエンコードした結果に対してCRC32のタグを付けデータ化けの検証をビューワ側で行っていますが、同じ設定でエンコードしてもCRCが異なるデータが出来てしまうんですよね。現状では乱数シードを固定して急場を凌いでいますが、対策としてはお粗末に過ぎます。
紙の形状を矩形に修正する
スキャンした紙の形状はたいてい、綺麗な矩形(長方形,つまり内角が全て90度)にはなっていません。これは製本の時点で裁断が傾いていることもありますし、本屋が下手なヤスリがけをしたせいかもしれませんし、私が裁断機で本を裁断した際に真っ直ぐ切ることができなかったからかもしれません(だいたいにおいて最後のケースです)。画像データはきっちり矩形でないと扱いにくいので、矩形への変形を行います。縁が垂直に切り落としても問題なさそうな空白であれば、縁を垂直に切り落とします。そうでないならアフィン変換で画像を歪ませます。多少歪んだ程度では気付かれない程度に人間の目は鈍感ですので問題ありません。

水平/垂直に縞模様のラインの通りに、紙の形状とカラーを調査し情報量を測定しています。
今回のサンプル画像の場合、どうやら紙の左側だけ大きく傾いているようですね。端っこに情報はなく空白っぽいので、垂直に切り落としてしまって問題なさそうです。これで綺麗な矩形が手に入りました!
印刷時の傾きを補正する
紙の本というものは割と適当で、想像よりも傾いた状態で印刷されているものです。紙のまま読むのであれば表示領域が平面ではないのであまり気にはなりませんが、電子書籍だと平たい画面の上に表示するのでこの傾きが地味に気になります。特に漫画はコマが傾いているのが目にはっきり映ってしまいます。サンプル画像も、よく見ると、ほーんの僅かですが傾いているのが見て取れるかと思います。
漫画のコマにしろ小説の文字にしろ、直線を求めてその傾きを垂直/水平に補正してやれば良さそうです。というわけで、素直に直線を検出しましょう。まさにその為にあるような、Hough変換という便利なアルゴリズムがあります。
Hough変換を行うためには輪郭抽出をまずは行う必要がありますので、それを含めて順番に流れを追っていきます。
-
デノイズ(雑音低減)の為、画像を縮小し、ガウシアンブラーを適当に掛ける

-
エッジ強度を求める

-
エッジ勾配を求める

-
細線化

-
Hysteresisで2値化

これで輪郭抽出ができました。ここからが本番です。 -
2値化画像にHough変換を掛ける

-
ピーク値をいくつかピックアップしHough逆変換、複数の直線の式が求まる

なんだか知らないうちにそれっぽい直線が手に入りました!sugoi!tanoshii!
先人の知恵というものは本当に素晴らしいですね。
Hough変換を用いると、上記のように直線や円など画像の特徴を検出することができます。文章書くのが面倒くさくなってきたので説明をざっくりデバッグ用画像で済ませてしまいましたが、やっていることは教科書どおりです。詳しく知りたい方はググりましょう(Qiitaでこの言い草!)。
外れ値検出
求まった複数の直線の式のうち、あまりに角度が付きすぎている、他の直線と乖離が激しい、といった外れ値(outlier)/異常値を取り除くことで、目的の傾きが手に入ります。この「外れ値検出」も定番のアルゴリズムが先達によっていくつも用意されていますが、私はこのように実装しています。
- それぞれの直線の傾きを用意する
- 順番に1つずつ省いては標準偏差を求める
- 2のうち最も標準偏差の低くなった時に省いた傾きをoutlierと判断し、除去する
- 2-3を繰り返し、閾値以下の標準偏差になるか傾きの数が2つになったら打ち切る
- 残った傾きのうち最も傾きが小さいものを拾う
つまりは、一連の直線の傾きのうち、より密度が高いものを選定しています。なんていうアルゴリズムになるんでしょうね?よく分かっていません。こんな適当な考え方と実装でも、ちゃんと動いているのですから懐が広いです。
傾きが求まれば、あとはアフィン変換で回転するだけなので簡単ですね。
ほかにも
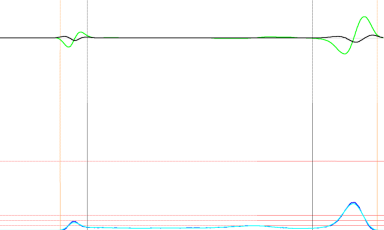
空白箇所を検出してトリミングしたり、

(赤い色の範囲はトリミング対象、緑色の範囲はトリミングしても構わないがターゲット端末のアス比に合わせてトリミングを保留している対象)
ヒストグラムでコントラスト調整(美白化)を行ったり、
様々な画質調整が、画像処理をぶん回すことで実現できています。
さらには、リニアワークフローの徹底、シャープネス、モアレ軽減、リサイズアルゴリズム、出力画像フォーマットの選定、etcetc...このツール内だけでも語るべきことはまだまだありますが、それらは次の機会があれば、ということで。
さいごに
時間配分をミスってしまい後半は駆け足になってしまいましたが、どうですか?**画像処理、面白くないですか?**今回紹介したようなアルゴリズムはどれも初歩中の初歩程度のものばかりですが、それでも実際に役に立つ運用ができています。定番というものは優秀だから定番になるわけですね。
ここから更に高みを目指そうとすると、その先に確実に待っているのは機械学習/深層学習、となってくるわけです。ヒューリスティックな解決法にはどうしても限界があることは、今回紹介した画質調整ツールの制作だけでも十二分に体感しました。
というわけで、まずは機械学習をこの画質調整ツールに取り入れていくのが私の現在の目標となっています。なっていますが、実用として組み込めるようになるのはいつになることでしょう...ま、兎にも角にも人生日々勉強ですね。