もともとAWSを使っていてGCPを勉強し始めた際、
AWSとの違いで一瞬「んっ?」っとなったポイントの備忘録
注意)あくまで2020年8月時点(+自身の知識範囲)
[1] Cloud IAM 系
①Policyはホワイトリストベース(DENYがない)
-
最小限の権限:least privilegeを付与しましょうが基本 - AWSのPolicyはカオス化しやすいので、個人的には逆にわかりやすい
- 逆に、"基本ALL OKで、1つだけ拒否したい" とかの場合は煩雑に
②上層のポリシーが下層に継承。許可は個々の設定の総和。
- 基本的には「必要最小限の許可をつけましょう」
- Organization/Folder/Project/Resourceの階層順で継承
- 下層で拒否とかできない
③サービスアカウント
- ユーザ以外のアプリやGCPリソース(VMなど)からの認証・認可用はサービスアカウントを利用
- サービスアカウント自体もGCPリソースの一つで、その編集権限などをユーザアカウント毎に管理できる(AWSのIAM ROLE/PolicyとSTSを合わせたようなイメージ)
- ユーザアカウントはAWSのIAM user相当
④「フォルダ」階層
- 組織/Project/Resourceの階層構成で、組織の配下に任意で「フォルダ」を定義できる
- 複数のProjectのポリシーなどをまとめたい場合に利用
⑤Cloud IdentityとG Suite
- AWSはせいぜいAWSアカウントとIAMユーザくらいだが、GCPはいろいろある
- 基本的にGCPを利用するユーザは
Googleアカウントを個々に発行する(基本は@gmail.com。独自のメアドを利用することもできる) - エンタープライズ利用では通常組織でユーザを一元管理する。その1つの方法が「
G Suite」。G SuiteはGoogleアカウントの他、GmailやGoogleドライブなど各種サービスも利用できる有料サービス。 - "余計なサービスはいらないよ" という場合に、G Suiteから各種サービスをそぎ落として、IDaaS的にユーザ管理に特化したものが「
Cloud Identity」 -
G SuiteまたはCloud Identityを利用すると、Organization層を定義でき、組織単位で権限一括管理などもできる(AWS Organization SCPに相当) - 複数のGoogleアカウントを束ねて権限一括管理したい場合は、
Googleグループが利用できる。(AWSのIAMグループ相当)
※Active Directory連携
- 既にActive DirectoryでID管理をしている場合、Googleアカウント(
Cloud Identity)を個別に管理せず、ID連携を自動化できる(ADで作れば勝手にGCP側も作られる) - 具体的には、
Google Cloud Directory Sync:GCDSでAD~CloudIdentity間のアカウントの同期を実現し、Active Directory フェデレーションサービス:ADFSで、CloudIdentity→ADのシングルサインオンによる認証連携を実現する - シングルサインオンによる認証連携は
SAMLプロトコルベース
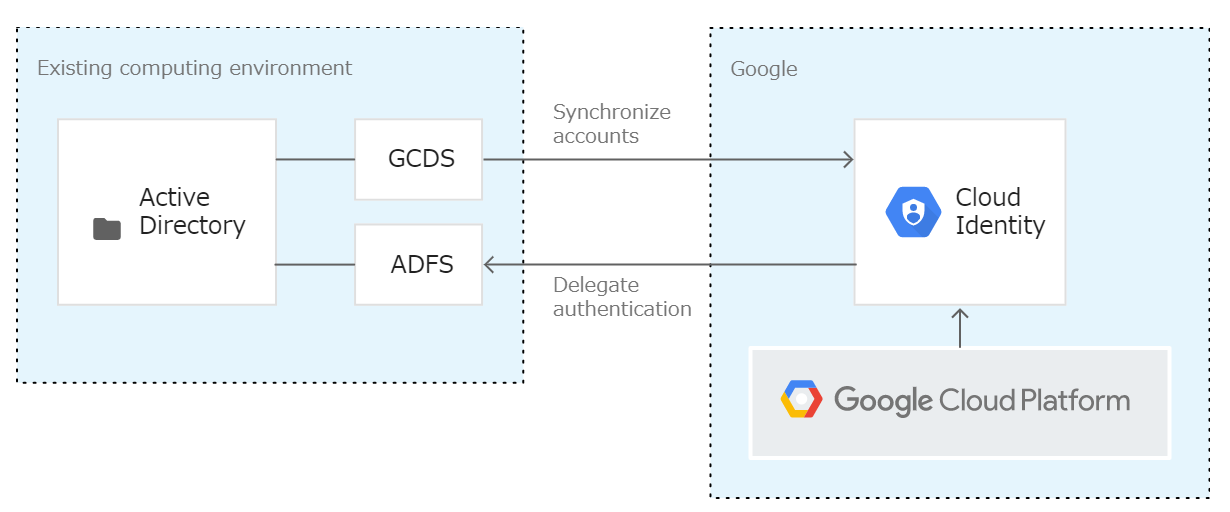
参考:https://cloud.google.com/solutions/federating-gcp-with-active-directory-introduction?hl=ja
⑥開発環境と本番環境の分離
- 開発環境と本番環境は「プロジェクト」を分離する
- 各プロジェクトに「Googleアカウント」を紐づけることができる
- AWSの場合は、AWSアカウントを開発用、本番用でそれぞれ作成し、それぞれにIAMユーザを作成する。環境(アカウント)の切り替えはIAMスイッチロールを利用する。(GCPの方かシンプル)
⑦ 様々なROLE
- Cloud IAMには3種類のROLEがある
- ① 基本ロール(Premitive Role)
- 予め容易されたオーナー、編集者、閲覧者の3パターンのレガシー用
- ② 事前定義ロール(Pre-Defined Role)
- Googleが予め細かい権限で設定し提供されるもの
- 2020/9現在で、ドキュメントではβ版のため商用利用は非推奨とある
- ③ カスタムロール(Custom Role)
- 自由に細かく定義できるもの
- ① 基本ロール(Premitive Role)
[2]VPCネットワーク 系
①VPCはグローバルリソース
- その配下のサブネットはリージョンリソース
- マルチリージョン(HA)化構成がしやすい
- AWSではVPCはリージョン依存
②IP帯域指定はVPC単位ではなくサブネット単位
- VPC配下のサブネット単位でIP帯域(CIDR)を指定できる
- 帯域はRFC1918プライベートIP
- 異なる帯域でサブネットを容易に追加できる
- AWSでは基本VPC単位でIP帯域(CIDR)を指定
③1つのサブネットが、複数ゾーンを跨げる
- マルチゾーン(HA)化構成がしやすい
- AWSではサブネットはAZ単位(跨げない)
④Firewallはステートフル。DENYもできる。
- ステートフルなので同一セッションの戻りの通信も許可される
- タグベースで複数VMのルール一括制御も可能
- AWSのSGとNACLを足したようなイメージ
- OUTBOUNDは暗黙のALLOW、INBOUNDは暗黙のDENY
- ルールはPRIORITYの数値が小さいものが優先(一般的なRTに近い)
⑤OUTBOUND SMTP(25)は許可できない
- Outbound Port 25 Blocking対応
- メール送信は、基本的にはSendGridなどサードパーティサービスを利用
⑥VPC 自動モードとカスタムモード
- VPCネットワークには自動モードとカスタムモードがある
- 自動モードはリージョン毎に自動的にサブネットを作成する(カスタムはしない)
- 自動モードからカスタムモードへは後で変換できるが、逆はできない
- 本番環境なら通常はカスタムモードがマッチする
⑦プライベートIPでのGCPサービス接続
- VPC内プライベートIPでセキュアにGCPサービスアクセスするには、「
限定公開の Google アクセス」または「サービスのプライベート アクセス オプション」 - AWS VPC Endpoint/PrivateLinkに相当
- 「
限定公開の Google アクセス」はサブネット単位で有効/無効を設定。有効にすると、外部IPがなくても、VPC内から公開インターネットを経由せずにGoogleAPIやGCPサービスへ接続できる - CloudSQLやmemorystoreなど一部サービスは未対応で「
サービスのプライベート アクセス オプション」を利用。こっちはGCPサービスとVPC Peering接続されるイメージ
⑧ Defaultネットワークのルーティング設定
- VPCは基本グローバルで、配下のサブネットはリージョン依存なので、各全リージョンのサブネットのIP帯域へのルーティングがあらかじめ設定されている
⑨ DefaultのFirewallルール
- デフォルトでは、SSH/RDP/ICMP/自リソースセグメントのINBOUNDのみが許可されている
- VM作成時に、HTTP/HTTPSのINBOUNDはチェックボックスで追加できる
- OUTBOUNDは全許可
⑩ サブネットサイズ(IPv4)
- GCP は CIDR /29(IP 8個/subnet)まで
- AWS は CIDR /28(IP 14個/subnet)まで
https://cloud.google.com/vpc/docs/using-vpc?hl=ja
https://aws.amazon.com/jp/vpc/faqs/
[3] Compute Engine (GCE)
①単一のゾーン永続ディスクを複数VMで共有できる
- ゾーン永続ディスクを複数のVMで共有できる(他VMからはREAD ONLY)
- ちゃんとした共有ファイルサーバにするには
Cloud Filestoreなど - AWSでもEBSのMulti-Atachがサポートされた(2020/2)
②複数のネットワークに足を持つVMを作れる
- 異なるサブネットに属するネットワークインターフェースをアタッチでき、複数のサブネットに属するVMが作れる
- 例えば、パブリックセグメント(フロント)とプライベートセグメント(DBなどのバックエンド)でサブネットを分離したWEBアプリケーションで、両者と接続するVMが、それぞれと接続するIFを分離する場合など
- AWSでも複数のENIをEC2にアタッチできるが、サブネットは跨げない
③セカンダリIPアドレス範囲とエイリアスIP
- サブネットにはプライマリCIDR範囲と別にセカンダリCIDR範囲を設定できる
- VMには通常のプライマリIPの他に、エイリアスIPとして内部IPを設定できる
- エイリアスIPは、プライマリ/セカンダリCIDRのどちらを採用してもよい
- 主な用途としては、VM上のコンテナで別IPでサービス稼働したい場合など

参照 https://cloud.google.com/vpc/docs/alias-ip?hl=ja
④継続利用割引
- GCEとGKEのVMは、継続利用(1カ月など)すると、手続き不要で勝手に割引される
- GAE FlexとDataflowのVM、GCE特定マシンタイプ(E2)は適合外
- AWS Reserved Instanceに相当する「確定利用割引」も別途ある
⑤ライブマイグレーション
- VMのメンテナンスやHW障害、アップグレードなどでも再起動不要
- AWS EC2だとたまに「バージョン古くてサポート切れるから再起動しろ」的なメールが来たりするが、その心配もない。
⑥ VMへの接続方法
- VMへのログイン方法はたくさんある
- ①Google Cloud Console - Compute Engine の [SSH] ボタンをポチる
- ②該当インスタンスにSSH公開鍵を登録して SSH接続 ※一般的なイメージ
- ③該当プロジェクトにSSH公開鍵(
プロジェクト全体の公開 SSH 認証鍵)を登録して SSH接続 - ④gcloud SDK(
gcloud compute ssh)で接続 - ⑤
OSログインで接続
-
プロジェクト全体の公開 SSH 認証鍵はインスタンス別にOFFも可能 - SSH公開鍵の追加・編集はコンソールから可能(AWS EC2は作成時に事前登録したキーペアを設定する。キーペア設定不備でインスタンス作り直し問題はGCPはなさそう)
-
OSログインは、Cloud IAMを利用した方法で、2段階認証設定も可能
⑦ 非マネージドインスタンスグループ(MIG)
- 複数VMを束ねる
マネージドインスタンスグループ(MIG) - MIGは
インスタンステンプレートで規定した単一VM構成で、オートスケール設定可能 - Cloud Load Barancerのバックエンドで利用する
- MIGはさらに
リージョンMIGとゾーンMIGがある - 「オートスケールしない + グループ内のVM構成を個別に変えたい」場合は
非マネージドインスタンスグループ
[4] BigQuery
①アーキテクチャ
- AWS Redshiftはもともとコンピュートとディスクが一体のインスタンス(node)ベースのクラスタとして利用するサービスだが、BQは分離されているサーバレスサービス。
②料金
- クエリ実行(スキャン量)とディスク使用量それぞれの従量課金の和
- クエリ実行課金には、500 SLOT単位で定額制がある(時間 or 月)
- ディスク使用課金には、長期保存(90日間変更なし)データは自動的に50% OFF
③パーティション分割
- BigQueryはクエリスキャン課金で、クエリエンジン(コンピュート)とストレージが分離されているので、格納データのパーティショニングすることで、スキャン範囲を制限でき、コストとパフォーマンス改善になる
- 取り込み時間、DATE/TIMESTAMP型、またはINTEGER型カラムをパーティションキーとした分割テーブルとして規定できる
- PARTITIONが設定されたテーブルへ読み込んだデータは、自動で振り分けされる
- DATE(_YYYYMMDDをPREFIX)でテーブルを分割するシャーディングも可能
- AWS Redshift Spectrumだと、データをパーティション化した状態でS3に格納し、ALTER TABLE ADD PARTITIONで外部テーブルにPARTITION設定を追加するので結構手間。
④テーブルの有効期限
- テーブルに有効期限を設定でき、超過すると自動削除される
- 一時利用テーブルの消し忘れ防止に使える
[5] Cloud SQL
①Cloud SQL Proxy
- Cloud SQLへの接続は、「
From IP制限でパブリックIP接続」するか、「プライベートサービスアクセスでプライベートIP接続」する方法がある。 - さらに、
Cloud SQL Proxyを利用してセキュアに接続できる。 - このProxyはSSL/TLSと認証機能を有し、
サービスアカウントとCloud SQL Admin APIを利用する - このProxyはVMの場合はクライアントツールとしてDL/Installして利用し、GKEの場合はDB接続するアプリケーションPod内のsidecarとして利用する
②Oracle DB on GCP
- Cloud SQLは、MySQL、PostgreSQL、MS SQL Serverには対応しているが、Oracle、Maria DBは非対応
- AWS RDSはManaged版でOracleを提供し、ライセンスのBYOLもサポート
- 基本的にOracleを移行したい場合の選択肢は、
①Cloud SQLかSpannerに切り替え(非Oracle)るか、②Bare Metal SolutionでOracle DB on GCPを実現する
③SQL Server on GCPのHA化
- 当初Cloud SQLはSQL Server未対応で、2019年に追加された
- それまではGCE上でSQL Server Enterpriseのイメージから立てる方法だった
- Cloud SQL for SQL Serverでは、リージョン内のマルチゾーンでのHA化とフェイルオーバー構成が組める
- 従来のGCE実装の場合は、Windows Server Failover Clustering と SQL Server AlwaysOn の可用性グループを使用してHA化とフェイルオーバー構成を組む
④PITR:ポイントインタイムリカバリ
- DBが死んだ場合などに、指定した位置で復旧する機能
- Cloud SQLインスタンスで
バイナリログとバックアップを有効にする必要がある -
バイナリログから復元位置を決めて、その地点のクローンを作るイメージ
[6] Cloud Storage (GCS)
①デュアルリージョンとマルチリージョン
- 通常の単一リージョンの他に
デュアルリージョンとマルチリージョンがある -
デュアルリージョンは、EURO4がEUROPE-NORTH1 と EUROPE-WEST4、NAM4がUS-CENTRAL1 と US-EAST1のペアで構成される -
マルチリージョンは、ASIA、EU、USという粒度で、配下の複数のデータセンター(リージョン)で構成される -
デュアルリージョンとマルチリージョンは、地域的な冗長性(少なくとも 100 マイル離れている 2 つ以上の場所に保存)が担保される