いわゆるポイントインタイムリストア(Point In Time Restore、PITR)等と呼ばれるようなデータを特定地点に切り戻す機能が、GCP BigQueryでも使えることを知ったので試してみます。BigQueryではタイムトラベルと呼ばれる機能のようです。
基本的に下記ドキュメントの通りですが、実際にやってみます。
環境
2021/07/13時点のGCP BigQueryを使っています。
テストデータの作成
sandboxというデータセットを作っておいて、適当なテーブルを作ります。
CREATE TABLE sandbox.sushi (
id INT,
name STRING,
updated_at DATETIME
);
正しいデータの作成
適当なテストデータを作成します。なんでも良いんですが、CLOUD SHELLターミナルで下記コマンドを実行して適当なデータを生成しました。
$ seq 1 10 | while read -r i; do
bq query --use_legacy_sql=false "INSERT into sandbox.sushi VALUES ($i, 'まぐろ$i', DATETIME_TRUNC(CURRENT_DATETIME('Asia/Tokyo'), SECOND));"
echo $i; sleep 1;
done
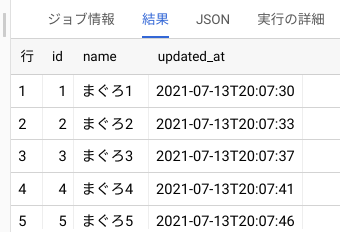
まぐろがたくさん入っています。この状態のデータが正しい状態、つまり切り戻し先の状態だとしましょう。
間違ったデータの挿入
ここで間違ったデータとして1件更新しました。
UPDATE sandbox.sushi
SET name = 'たまご', updated_at = CURRENT_DATETIME('Asia/Tokyo')
WHERE id = 8
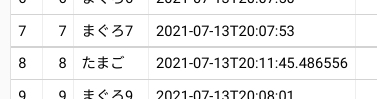
id=8に、間違ったたまごが混入しました。
今回は20時09分('2021-07-13 20:09:00')に不具合かなにか起きて、それより前に生成されたデータは正しくて、それ以降に更新されたデータが間違っている、という状況を想定します。updated_atというカラムがあって、それで切り分けができるイメージです。
正しいデータを確認
FOR SYSTEM_TIME AS OF 構文を使えば、特定の時点のデータをSELECTできます。
SELECT *
FROM sandbox.sushi
FOR SYSTEM_TIME AS OF TIMESTAMP('2021-07-13 20:09:00', 'Asia/Tokyo')
ORDER BY id

正しいまぐろ8のデータが得られました。
正しいデータの復元
上記SELECT結果をDMLに使うなどいくつか方法はありますが、$ bq cpコマンドを使えば特定のタイムスタンプのテーブルを取って来ることができます。
切り戻したい時点のタイムスタンプが必要ですが、これもBigQueryで取得できます。
SELECT UNIX_MILLIS(TIMESTAMP('2021-07-13 20:09:00', 'Asia/Tokyo'))
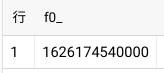
1626174540000が得られたので、これをスナップショットデコレータとして付与したコマンドをCLOUD SHELLで実行します。
$ bq cp sandbox.sushi@1626174540000 sandbox.sushi_restored
確認してみます。
SELECT * FROM sandbox.sushi_restored ORDER BY id
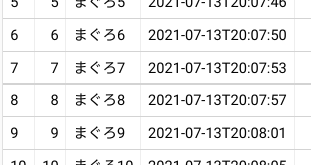
正しいデータの時点のテーブルが作られました。
このまま切り戻してしまってOKならば、ALTER TABLE ... RENAME TO ...で差し替えます。実は2021年5月にできるようになったばかりらしい最新の機能です。
ALTER TABLE sandbox.sushi RENAME TO sushi_mistake;
ALTER TABLE sandbox.sushi_restored RENAME TO sushi;
これで切り戻しが完了しました。
SELECT * FROM sandbox.sushi ORDER BY id
まとめ
BigQueryのデータを特定時点に切り戻すことができました。注意点として、過去7日間しかデータは保持されないようなので注意が必要です。