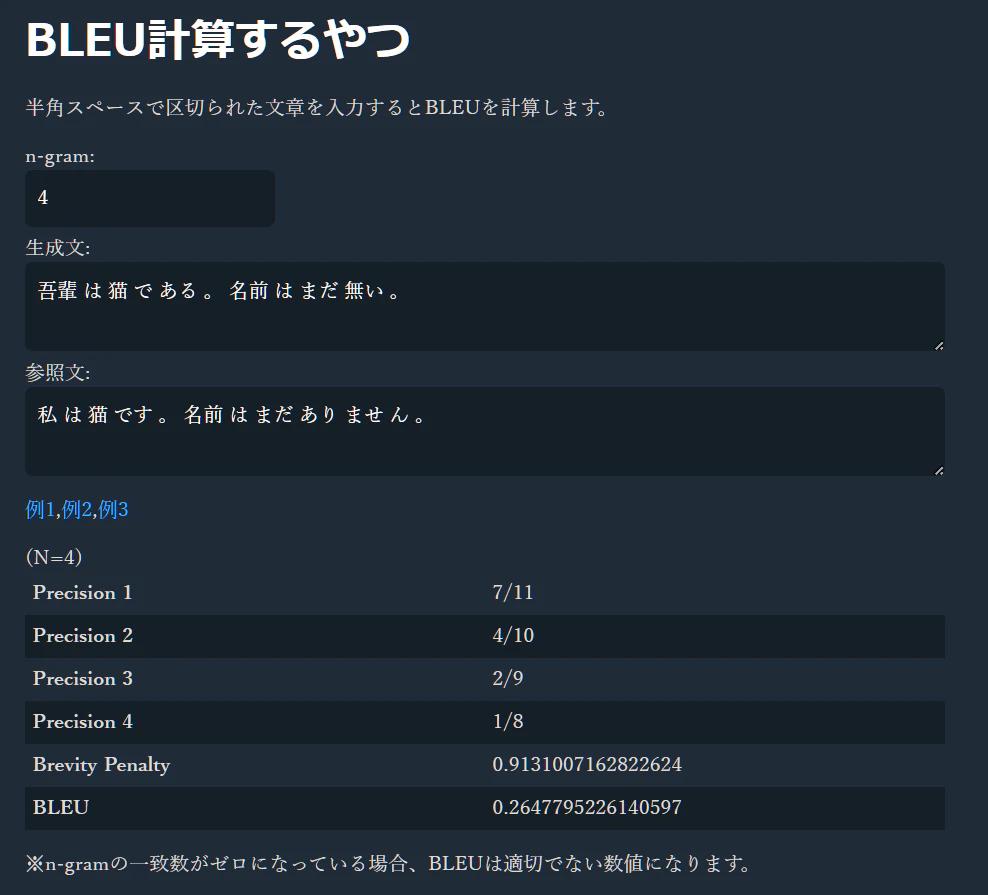
機械翻訳等で用いられる BLEUスコア をフロントエンドで計算するページを作ってみました。
BLEUスコアは本来コーパスに対して適用するものであり、実際の場面で単体の文に対して計算をするのはあまり意味が無いと思いますが、これは理解を助けるためのものです。自分でちょっと仕組みを確認したいと思ったので作ってみました。
BLEUとは
以下のような計算式で表されるものです。
$$
\text{BLEU}=\text{BP}(\prod_{i=1}^{N}precision_i)^{1/N}
$$
$$
\text{BP}=min(1, e^{1-\frac{reference-length}{hypothesis-length}})
$$
計算式の解説は下記のようなページを参照してください。
概要だけを示すと、文章をn-gramで区切った時にどれだけ一致するか個数を計算したものです。0~1の値をとり、大きいほど一致している語が多いということになります。正解データとして用意した参照文と、機械的に生成した生成文とを比べて、どれくらいの語が一致しているかを数えて、一致している語が多いほど生成したものの精度が良い、とする指標です。
たとえば「This is a pen .」「This is an apple .」は、1-gramでは5件中3件一致、2-gramでは4件中1件一致している、といった具合です。
| token1 | token2 | token3 | token4 | token5 |
|---|---|---|---|---|
| This | is | a | pen | . |
| This | is | an | apple | . |
| 指標 | 値 |
|---|---|
| Precision 1 | 3/5 |
| Precision 2 | 1/4 |
この「n-gramがいくつ一致しているか」というのを見れるようにしたのが、今回作ったものです。
BLEUスコアは機械翻訳の評価指標としてよく用いられるものです。仕組みとしては大雑把な指標になりますが人手での評価と一定の相関があることが知られていること、比較的容易に利用できることなどから、よく用いられているようです。
その性質上、機械翻訳でなくても正解となる文章が用意できる生成系タスクにおいて自動評価指標として用いられることもあります。
使用技術
CodeSandboxでざっくり動くものを作って検証したあと、React+Next.js+TypeScriptで作ってGitHub Pagesに載せました。スタイルはWater.cssを当てました。
入力に対して、半角スペースで区切られた範囲を1tokenとする処理を行っています。入力が英文なら特に問題は無いと思いますが、日本語を入力する場合は予め形態素解析等を行って半角スペースで区切られた文章を入力する必要があります。
実際のソースコードは下記です。
開発時はJestでテストをしています。PythonのNLTKの結果と突き合わせてテストをしました。
NLTKにはSmoothingの処理などもありますが、それらは使わない初期設定の結果を使っています。
import nltk
from nltk import word_tokenize
from nltk import bleu_score
nltk.download('punkt')
hyp = word_tokenize("A NASA rover is fighting a massive storm on Mars .")
ref = word_tokenize("The NASA Opportunity rover is battling a massive dust storm on Mars .")
bleu_score.sentence_bleu([ref], hyp)
#=> 0.27221791225495623