はじめに
仕事の関係で機械学習について学習する必要性がでてきたので、アルゴリズムを何個か軽く勉強することにしました。
Pythonが絡むと学習負荷が一気に高くなってしまう気がしたので、学習はJavaScript(TensorFlow.js)で行いました。
まずは、座標や床面積を入力してk近傍法で家の価格を予測するようなアルゴリズムを実装しました。
ほぼ学習メモみたいな感じなので、深い内容をお求めの方はその点ご了承ください。
TensorFlow.js
TensorFlow.jsはPythonのnumpyみたいな操作ができるライブラリです。
JSで簡単に行列計算をすることができます。
k近傍法(k-nearllest neighbor)
入力値に対する予測値を出すアルゴリズムの一つです。
指定した座標(lat, long)から家の価格(price)を予測する場合を考えると、予測まで以下のような流れになります。
- 座標と家の価格に関する実際のデータをたくさん集める(Training data)
- 価格を知りたい座標を指定して前ステップで集めた座標データとの差分をそれぞれとっていく
- 差分が小さい順にデータをソートする
- 差分が小さい順に指定した個数(k)分のデータを取得する
- 取得したデータの価格の平均値をとる(予測値)
理想的なkの値を探すために、Training dataとTest dataをそれぞれ用意します。
knnでTest dataの座標から価格を出し、Test dataの価格との差が小さくなるようにkを調整していきます。
また、座標だけではなく床面積(sqft_lot)やリビング面積(sqft_living)などの複数の要素を考慮すると、より精度の高い価格予測ができそうです。
前提知識
実装に際して前提となる超基本知識をまとめました。
分類と回帰
値予測のために分類(Classification)と回帰(Regression)について理解しておく必要があります。
入力値に対してその値が合格か不合格かを予測したい場合には分類、どのような値になるかを予測したい場合には回帰を使います。
正規化(Normalization)と標準化(Standardization)
データを最大値が1、最小値が0のデータとなるように変換することを正規化、元のデータの平均を0、標準偏差が1のものへと変換することを標準化と呼びます。
最大値及び最小値が決まっている場合(画像処理とか)などには正規化を利用します。
一方、最大値及び最小値が決まっていない場合や外れ値が存在する場合には、重みを学習しやすくするために標準化を利用します。
正規化の式
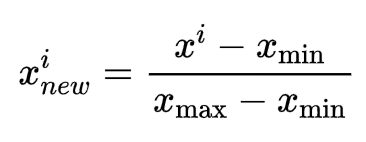
標準化の式 (μ: 平均, σ: 標準偏差)
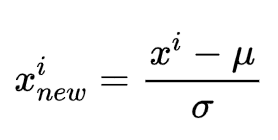
実装
実装の流れをまとめました。
データの準備
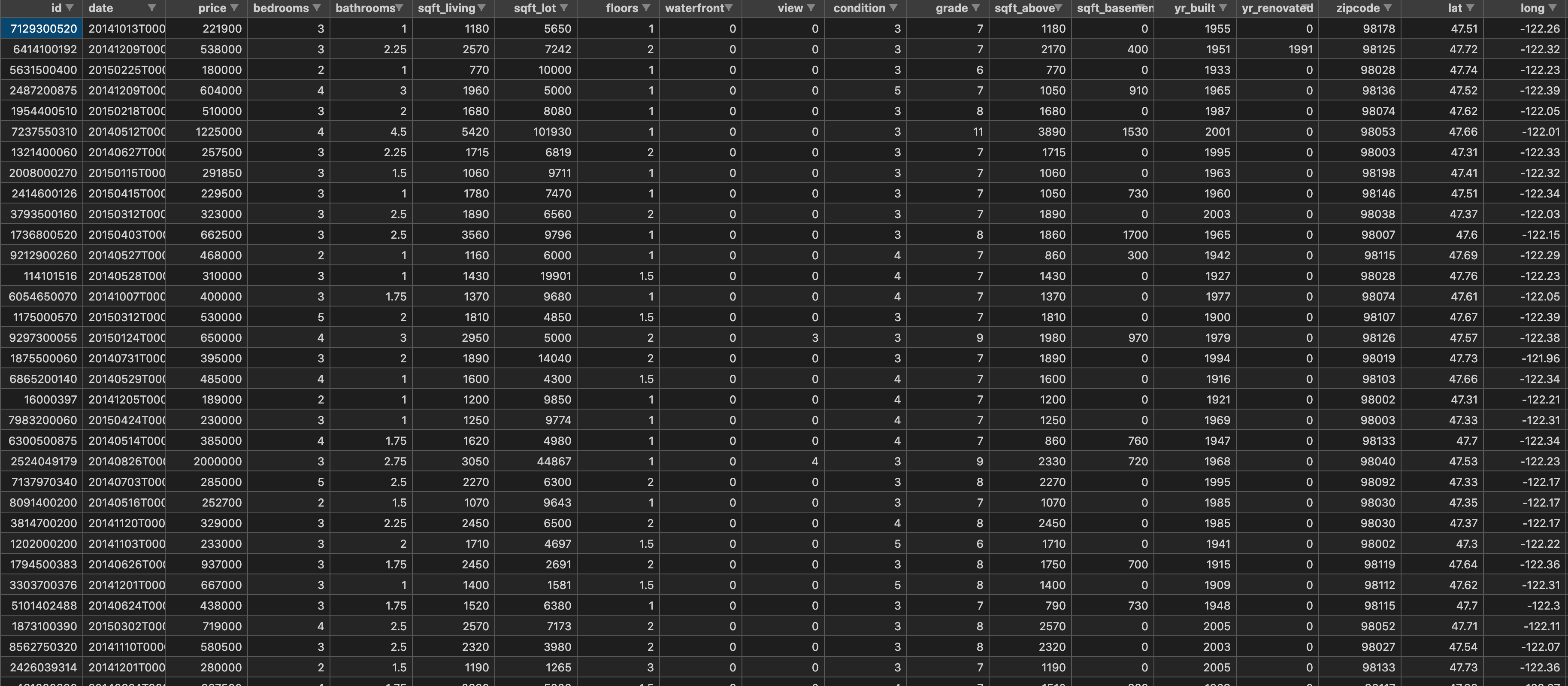
予測に使うデータ(kc_house_data.csv)を用意します。
Training dataとTest dataをこの中から抽出します。
index.jsの作成
この中にデータの予測処理を作成します。
ライブラリの読み込み
require('@tensorflow/tfjs-node');
const tf = require('@tensorflow/tfjs');
const loadCSV = require('./load-csv');
knn処理
//一番近いpriceを探索するknn
function knn(features, labels, predictionPoint, k) {
const { mean, variance } = tf.moments(features, 0); //平均値と分散の取得、第2引数でrowかcolumnを指定
const scaledPrediction = predictionPoint.sub(mean).div(variance.pow(0.5)); //入力値の標準化 (入力値-平均値)/標準偏差
return (
features
.sub(mean)
.div(variance.pow(0.5)) //Training dataの標準化
.sub(scaledPrediction) //入力値(標準化済)との差
.pow(2) //各要素を2乗
.sum(1) //各要素の和
.pow(0.5) //ルートをとる(distance算出)
.expandDims(1) //連結するためにdimを操作
.concat(labels, 1) //labels(price)と連結
.unstack() //sort, sliceの操作を行うためにobj化
.sort((a, b) => (a.get(0) > b.get(0) ? 1 : -1)) //distance小さい順にソート
.slice(0, k) //k個データを取得
.reduce((acc, pair) => acc + pair.get(1), 0) / k //priceの平均値(knnの結果)
);
}
データの取得
splitTest:10でTest data(testFeatures, testLabels)をランダムに取得し、それ以外をTraining data(features, labels)として取得します。
let { features, labels, testFeatures, testLabels } = loadCSV(
'kc_house_data.csv',
{
shuffle: true,
splitTest: 10, //testFeatures, testLabelsの数を指定
dataColumns: ['lat', 'long', 'sqft_lot', 'sqft_living'], //featureカラムを指定 指定数増やすと精度上がる
labelColumns: ['price'], //labelカラムを指定
}
);
features = tf.tensor(features);
labels = tf.tensor(labels);
予測値の出力
10個のTest data(testFeatures)をknnで処理した結果(Guess)とtestLabelsとの乖離度合(Error)を出力しました。
testFeatures.forEach((testPoint, i) => {
//testFeature10個それぞれのerrをみる
const result = knn(features, labels, tf.tensor(testPoint), 10); //knnの結果(予測値)
const err = (testLabels[i][0] - result) / testLabels[i][0]; //Test dataのpriceと予測値の乖離度合
console.log('Error', err * 100);
console.log('Guess', result, testLabels[i][0]);
});
出力結果
Error -15.323502304147466
Guess 1251260 1085000
Error -11.344580119965723
Guess 519756.5 466800
Error -2.047058823529412
Guess 433700 425000
Error 19.327433628318584
Guess 455800 565000
Error 7.806324110671936
Guess 699750 759000
Error -14.106372465729613
Guess 584260 512031
Error -8.782552083333334
Guess 835450 768000
Error 13.227406199021207
Guess 1329790 1532500
Error -36.336911441815076
Guess 279422.5 204950
Error 7.381578947368421
Guess 228767.5 247000
おわりに
ほんとに触りだけなので、数式がわかればそこまで実装は難しくないという印象。
参考資料