KaggleのTitanicのチュートリアルをやってみました。
Pandasやscikit-learnの使い方を覚えるためにJupyter NoteBook上でのコードをここに記録しておきます。
Kaggleは実際のデータをもとに機械学習をしてそのスコアを競うサイトです。
コンペティションに参加しなくてもチュートリアルがいくつかあり、機械学習に使える実際のデータがそろっているので、機械学習を勉強するにはとても便利です。
Kaggleの使い方やタイタニック号のチュートリアルについては
【Kaggle初心者入門編】タイタニック号で生き残るのは誰?
を参考にしました。
私のコードは、上記記事を参考にしつつ、自分でわかりやすいように変えています。
Kaggleにユーザ登録すると
Titanic: Machine Learning from Disaster | Kaggle
からデータをダウンロードできるようになります。
アルゴリズムは決定木です。
これ以降は、
Jupyter NotebookをDockerを使って簡単にインストールし起動(nbextensions、Scalaにも対応) - Qiita
に従って準備したJupyter Notebookの環境で試しています。
このJupyterの環境でブラウザで8888番ポートにアクセスして、Jupyter Notebookを使うことができます。右上のボタンのNew > Python3をたどると新しいノートを開けます。
データ準備
import numpy as np
import pandas as pd
train = pd.read_csv("train.csv")
test = pd.read_csv("test.csv")
train、testはDataFrameのオブジェクトになります。
データの前処理をtrain、testとで共通して行うためにいったんデータを連結します。あとで再度分割できるようにフラグを入れておきます。またSurvivedという列はtrainにしか含まれていませんので、これはいったん削除します。
train["is_train"] = 1
test["is_train"] = 0
data = pd.concat([train.drop(columns=["Survived"]), test])
train.drop(columns=["Survived"])は列を削除した新しいDataFrameオブジェクトを返します。新しいオブジェクトを返すので、元のtrainには列は残ったままです。なお、train.drop(["Survived"], axis=1)と書いても同じです。axis=1は行ではなく列を削除というフラグです。が、前者のほうがわかりやすいです。
pd.concatは複数のDataFrameを連結した新しいDataFrameを返します。ちなみにpd.concatにaxis=1を渡すと横方向に連結します。
連結した結果、こんなデータになります。1309行のデータです。
欠損データに対応
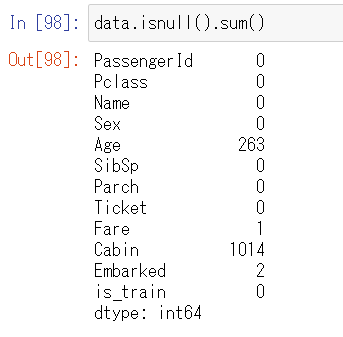
欠損データの状況を確認します。上のスクショでNaNと表示されている箇所がもとのCSVファイルでは空になっていた箇所でデータが欠損しています。
data.isnull().sum()
以下のコードでどんなデータがあるかや、中央値を確認できます。
data["Age"].unique()
data["Age"].median()
Ageの項目の欠損箇所には中央値を入れることにします。
data["Age"] = data["Age"].fillna(data["Age"].median())
Embarkedにはどんなデータがあるかを確認します。データごとにそのレコード数を確認できます。
data["Embarked"].value_counts()
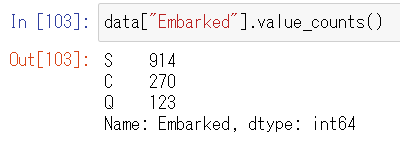
Embarkedは多くをSが占めているようですので、欠損箇所にはSを入れることにします。
data["Embarked"] = data["Embarked"].fillna("S")
data.isnull().sum()
文字列データを数値に変換
次に、文字列になっているSexとEmbarkedの項目を数値に変換します。
EmbarkedにはS, C, Qの3パターンしかありませんでしたので、こんな風に変換したいと思います。これをワンホットエンコーディング(one-hot encoding)といいます。
| Embarked |
|---|
| S |
| S |
| C |
| Q |
↓
| Embarked_C | Embarked_Q | Embarked_S |
|---|---|---|
| 0 | 0 | 1 |
| 0 | 0 | 1 |
| 1 | 0 | 0 |
| 0 | 1 | 0 |
one-hot encodingはpd.get_dummiesという関数でできます。pd.get_dummies(data["Embarked"], prefix="Embarked")]というコードはEmbarked_S, Embarked_C, Embarked_Qという3列のDataFrameを生成します。3列のうちのどれかが1になっていて、それ以外が0になっています。これをもとのdataと横に連結して、もともとのEmbarked列を削除します。
data = pd.concat([data, pd.get_dummies(data["Embarked"], prefix="Embarked")], axis=1).drop(columns=["Embarked"])
Sexはmaleとfemaleしかありませんでしたので、2列にする必要はなく、0, 1の1列で足ります。
| Sex |
|---|
| male |
| female |
| female |
↓
| Sex |
|---|
| 1 |
| 0 |
| 0 |
pd.get_dummiesにdrop_first=Trueというオプションを付けると1列目を削除して、結果1列のみにしてくれるようです。
data["Sex"] = pd.get_dummies(data["Sex"], drop_first=True)
pd.get_dummiesで生成した2列のうち1列目がたまたまfemaleだったからか、maleのほうが1でfemaleが0になりました。どっちになってもいいと思います。
結果こういうデータになりました。
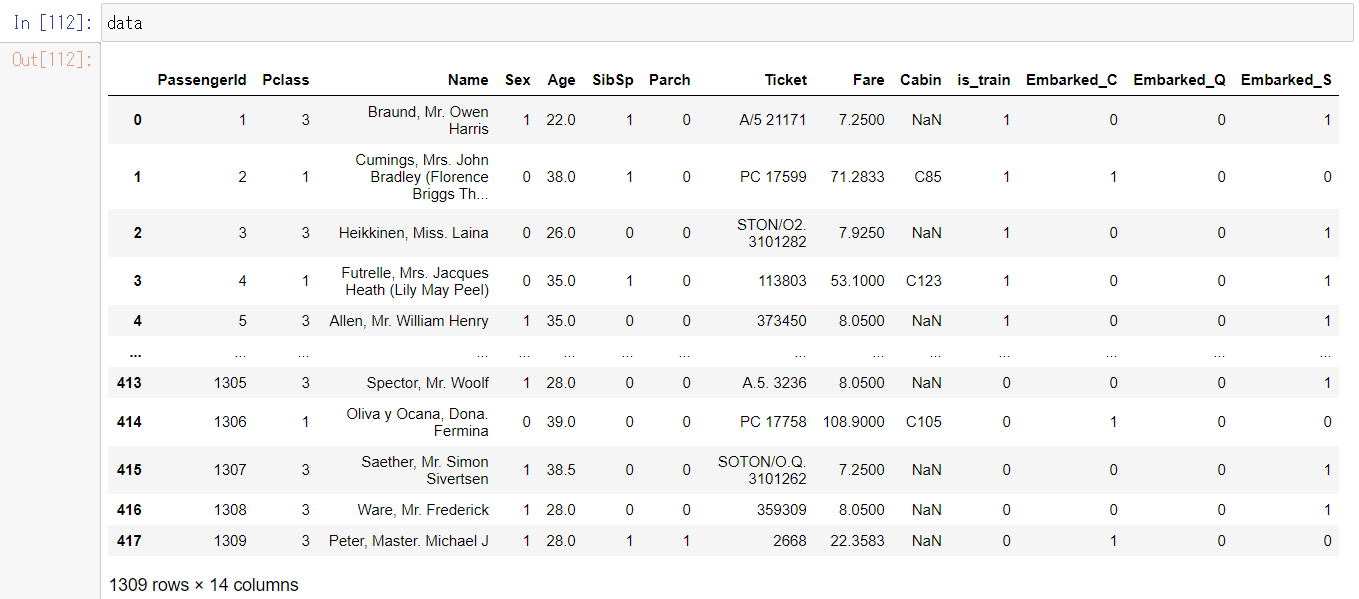
前処理をしたdataを再び訓練データと検証データに分割し、さらに今回使用する列のみに絞ります。
feature_columns =["Pclass", "Sex", "Age", "Embarked_C", "Embarked_Q", "Embarked_S"]
feature_train = data[data["is_train"] == 1].drop(columns=["is_train"])[feature_columns]
feature_test = data[data["is_train"] == 0].drop(columns=["is_train"])[feature_columns]
目的変数はdataには含まれてませんでしたので、最初のtrainから抽出します。
target_train = train["Survived"]
学習
モデルを学習します。
from sklearn import tree
model = tree.DecisionTreeClassifier()
model.fit(feature_train, target_train)
参考
sklearn.tree.DecisionTreeClassifier — scikit-learn 0.21.3 documentation
訓練データで正解率を見てみます。
from sklearn import metrics
pred_train = model.predict(feature_train)
metrics.accuracy_score(target_train, pred_train)
0.9001122334455668と出ました。9割が正解のようです。
評価
Kaggleに推論結果を登録して評価してみます。
まずmy_prediction.csvに検証データでの推測結果を保存します。
pred_test = model.predict(feature_test)
my_prediction = pd.DataFrame(pred_test, test["PassengerId"], columns=["Survived"])
my_prediction.to_csv("my_prediction.csv", index_label=["PassengerId"])
CSVファイルの1行目はヘッダ行で、PassengerId,Survivedになっています。
このファイルをKaggleのサイトにアップすると、スコアを出してくれます。
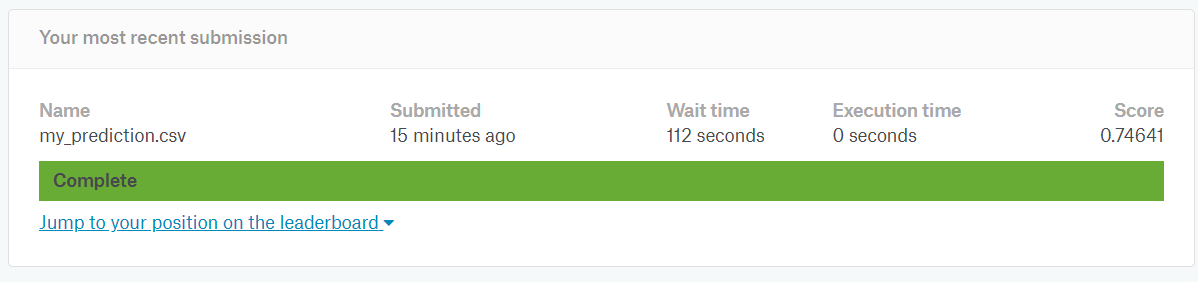
0.74641でした。