はじめに
AWS Advent Calender 22日目担当させていただきます,スライと申します.
やること
僕が利用しているとあるサイトは毎日0時~6時までメンテナンスでアクセスできないようになっています.そこには大学の講義動画にアクセスするためのURLなどが記載されています.
つまり上記のサイトは一日のうち6時間も停止しているわけです.さらに0時~6時といえば(生活リズムの乱れた)学生のゴールデンタイムです.僕にとってもこれは致命的なので,定期的にどこかに情報を保存することにしました.
システム構成図
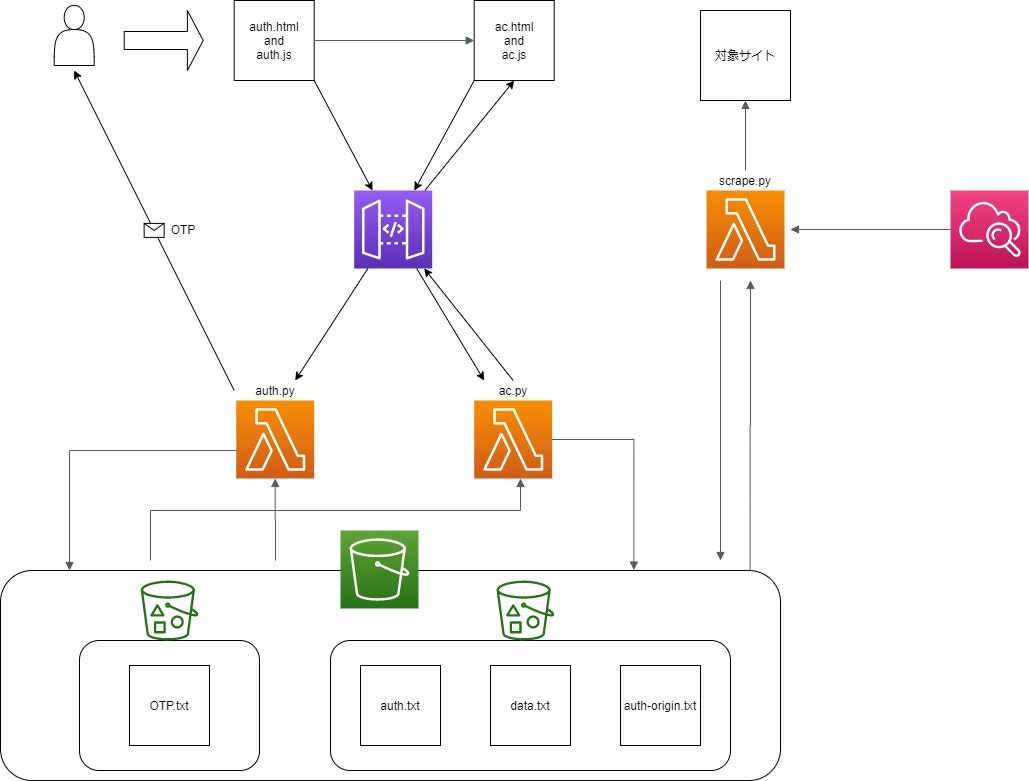
auth.html・・・ユーザー名とパスワードを入力する画面
ac.html・・・ワンタイムパスワード入力およびデータの表示を行う画面
auth.py・・・auth.jsから認証データを受け取りワンタイムパスワードの発行を行うスクリプト
ac.py・・・ac.jsから入力を受け取りワンタイムパスワード認証を行い,S3からデータを取得してくるスクリプト
scrape.py・・・対象サイトから一日一回データを取得してくるスクリプト
OTP.txt・・・auth.pyで発行したワンタイムパスワードと発行した時間が記録されたファイル
auth.txt, auth-origin.txt・・・認証情報が記録されたファイル
data.txt・・・scrape.pyで取得してきたデータが記録されたファイル
Lambda上でSeleniumを動かす
今回はLambda関数の作成,設定を行うためにAWS Cloud9 と Serverless Frameworkを利用します.
Cloud9のServerlessとSeleniumの環境構築は下記の記事を参考にしましたので,こちらを見ていただいたほうが早いと思います
サーバーレスなSelenium実行環境でブラウザのスクショをS3に保存する【AWS LambdaとServerless Framework編】
読んだ前提で変えた部分だけ解説していこうと思います.
記事にもありますがディレクトリ構成はこんな感じ
.
└── selenium-scrape
├── lambda
│ ├── config
│ ├── handler.py
│ └── serverless.yml
├── README.md
└── selenium-layer
├── config
├── driver
├── node_modules
├── package.json
├── package-lock.json
├── selenium
└── serverless.yml
Lambda側のserverless.yml
functions:
main:
handler: handler.main
layers:
- ${cf:${self:custom.seleniumLayer}-${self:custom.stage}.SeleniumLayerExport}
- ${cf:${self:custom.seleniumLayer}-${self:custom.stage}.ChromedriverLayerExport}
environment:
S3BUCKET: ${self:custom.projectDir}-${self:custom.stage}
memorySize: 256
events:
- schedule: cron(45 14 * * ? *)
functions部分のmemorySizeとeventsのscheduleの部分を変更しました.Seleniumは結構メモリを使うっぽいのでメモリサイズを明示的に指定して256MBとしています.
また,毎日23:45にLambda関数を実行したいのでcron式には(45 14 * * ? *)と記述しています.cron式のフォーマットはcron(分 時間 日 月 曜日 年)です.なお時間の指定はグリニッジ標準時であるため日本標準時から-9時間してください.
あとはお好みで利用するS3の指定とかを行ってください
provider:
name: aws
runtime: ${self:custom.pythonVer}
stage: ${self:custom.stage}
region: ${self:custom.region}
timeout: 600
environment:
SELENIUM_LAYER_SERVICE: ${self:custom.seleniumLayer}
TZ: ${self:custom.TZ}
iamRoleStatements:
- Effect: 'Allow'
Action:
- "lambda:InvokeFunction"
- "lambda:InvokeAsync"
- "s3:ListBucket"
- "s3:GetObject"
- "s3:PutObject"
- "s3:DeleteObject"
Resource:
Fn::Join:
- ""
- - "arn:aws:s3:::datafile-auth"
- "/*"
Lambda関数本体
import os
import json
import random
import time
import datetime
import logging
import traceback
import boto3
import sys
# selenium
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
from selenium.common.exceptions import NoSuchElementException
from selenium.webdriver.support.ui import Select
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.keys import Keys
def set_up_logger():
logger = logging.getLogger()
for h in logger.handlers:
logger.removeHandler(h)
handler = logging.StreamHandler(sys.stdout)
handler.setFormatter(logging.Formatter(
'%(levelname)s %(asctime)s [%(funcName)s] %(message)s'))
logger.addHandler(handler)
logger.setLevel(logging.INFO)
return logger
def set_selenium_options():
""" Set selenium options """
print("start-selenium-setting")
options = Options()
options.binary_location = '/opt/headless-chromium'
options.add_argument('--headless')
options.add_argument('--window-size=1280,1024')
options.add_argument('--no-sandbox')
options.add_argument('--single-process')
options.add_argument('--disable-dev-shm-usage')
options.add_argument("--homedir=/tmp")
print("setting_end")
return webdriver.Chrome('/opt/chromedriver', chrome_options=options)
def login_acweb(driver):
s3 = boto3.resource('s3')
bucket = s3.Bucket("datafile-auth")
bucket.download_file("origin.txt","/tmp/origin.txt")
with open("/tmp/origin.txt") as f:
id,pas = list(map(str.strip,f.readlines()))
element_id = driver.find_element_by_id("Userid")
element_pas = driver.find_element_by_id("Userpw")
element_button = driver.find_element_by_id("Login")
element_id.send_keys(id)
element_pas.send_keys(pas)
time.sleep(2)
element_button.click()
time.sleep(3)
url_list = driver.find_elements_by_class_name("text")
first_click = [i for i in url_list if url_list.index(i) % 2 == 1 and len(i.text) >= 8][0]
data_list = []
first_click.click()
time.sleep(1)
for i in range(10):
title = driver.find_element_by_id("Title").text
detail = driver.find_element_by_id("Detail").text
next_button = driver.find_element_by_id("Next")
data_list.append(title)
data_list.append(detail)
next_button.click()
time.sleep(1)
terminate_driver(driver)
data = "$".join(data_list)
return data
def data_set(data):
with open("/tmp/data.txt",mode="w") as f:
f.write(data)
s3 = boto3.resource('s3')
bucket = s3.Bucket("datafile-auth")
bucket.upload_file("/tmp/data.txt","data.txt")
os.remove("/tmp/data.txt")
def main(event, context):
logger = set_up_logger()
starttime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
logging.info("starttime: {}".format(starttime))
logging.info(json.dumps(event))
driver = None
target = None
url = "ここにURL"
try:
driver = set_selenium_options()
driver.maximize_window()
driver.get(url)
time.sleep(3)
data = login_acweb(driver)
data_set(data)
return {
"statusCode": 200,
"body": "Complete."
}
except Exception as e:
logger.error("[ERROR] {e}".format(e=e))
terminate_driver(driver)
return {
"statusCode": 400,
"body": e
}
あとがき
なにかもう少し書きたいことがあった気がするのであとから書き足すかもしれないです.