0. はじめに
こんにちは。都内でエンジニアをしている、@gkzvoiceです。
今回はホコリを被っていた「AWS Lamda上でSelenium/Headless Chrome」の実行環境の構築手順を供養しようと思います笑。
勤怠打刻プログラムを作ろうかなと思ったのですが、あれがあれする気もしなくもないと考えて。
なお、本記事では、Serverless Frameworkを使いますが、そのインストール手順や一般的な使い方は、深く取り扱いません。
手前味噌ですが、下記の記事をご参照ください。
1. 目次
-
- 環境/バージョン情報
-
- AWS Lambda上でSelenium環境を構築するポイント
-
- chromedriverとheadless-chromeのインストール方法
-
- Seleniumファイルのデプロイ手順とそのポイント
-
- Lambdaファイルのデプロイ手順とそのポイント
-
- chromedriverとheadless-chromeのバージョン選定ミスを防ぐ方法
-
- 文字化け対策
-
- 参考資料
2.環境/バージョン情報
ローカル開発環境
- serverless
- Framework Core: 1.60.4
- Plugin: 3.2.6
- SDK: 2.2.1
- Components Core: 1.1.2
- Components CLI: 1.4.0
ChromeDriver 2.40Headless Chromium v1.0.0-45
AWS Lambda
Amazon Linux- Python 3.7
Selenium環境の作成後のディレクトリ
gkz@localhost ~/serverless-scraper (master) $ tree -L 2
.
├── install.sh
├── lambda ## 「6. Lambdaファイルのデプロイ手順とそのポイント」で解説
│ ├── config
│ ├── handler.py ## Lambdaが実行するプログラム
│ ├── node_modules
│ ├── package.json
│ ├── package-lock.json
│ └── serverless.yml
├── LICENSE
├── README.md
└── selenium-layer ## 「4. chromedriverとheadless-chromeのインストール方法とその注意点」と
##「5. Seleniumファイルのデプロイ手順とそのポイント」で解説
├── config
├── .fonts ## 「8. 文字化け対策」で解説
├── driver ## chromedriverとchromeを保管
├── node_modules
├── package.json
├── package-lock.json
├── selenium ## Pythonのseleniumライブラリを保管
└── serverless.yml
8 directories, 10 files
※本記事で紹介するサンプルコードはこちらのリポジトリにて公開しているので、ご利用ください。
gkz@localhost ~ $ git clone https://github.com/gkzz/serverless-scraper.git \
&& cd serverless-scraper
3. AWS Lambda上でSelenium環境を構築するポイント
- serverless deployコマンドを2回叩くこと
- 1回目は**
selenium-layer/[selenium|driver]をLayersに**デプロイするため - 2回目の**
lambda/handler.pyをFunctionsに**デプロイするため
gkz@localhost ~/serverless-scraper (master) $ ls */serverless.yml
lambda/serverless.yml selenium-layer/serverless.yml
Selenium関連ファイルがLayersに配置している様子
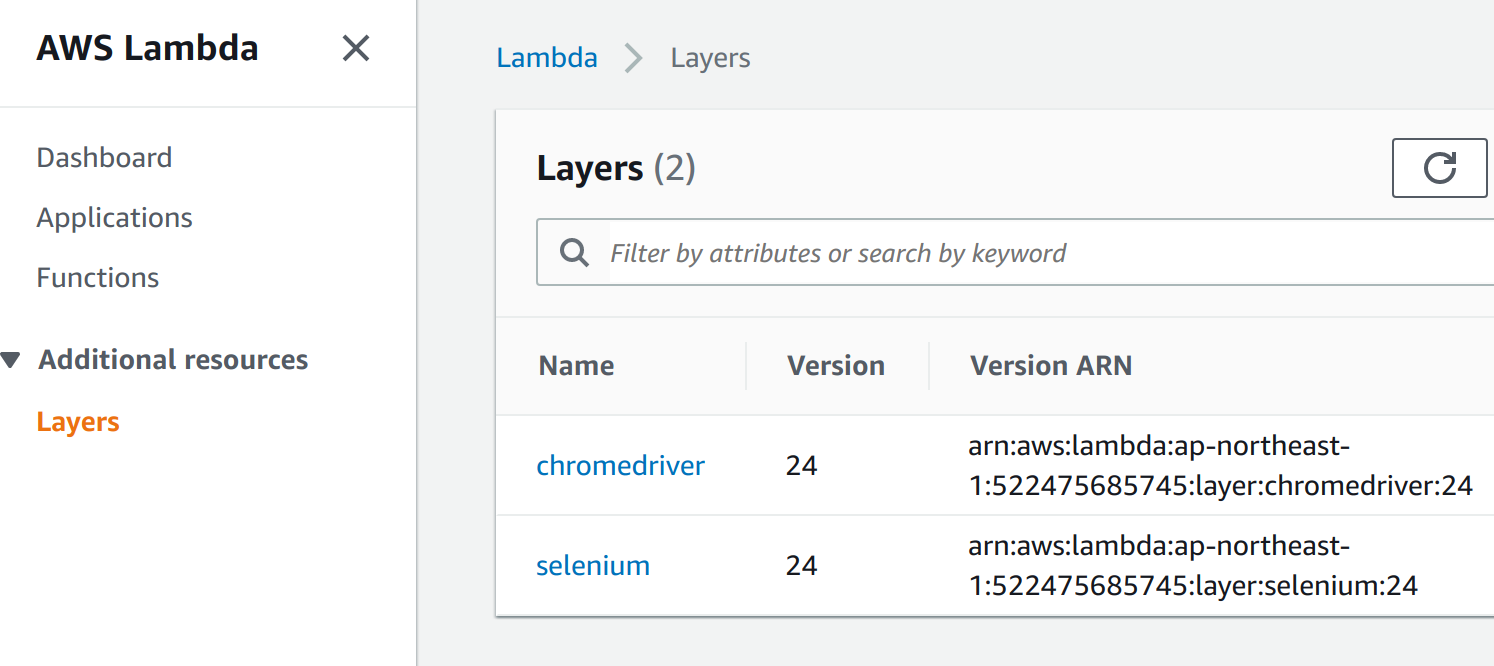
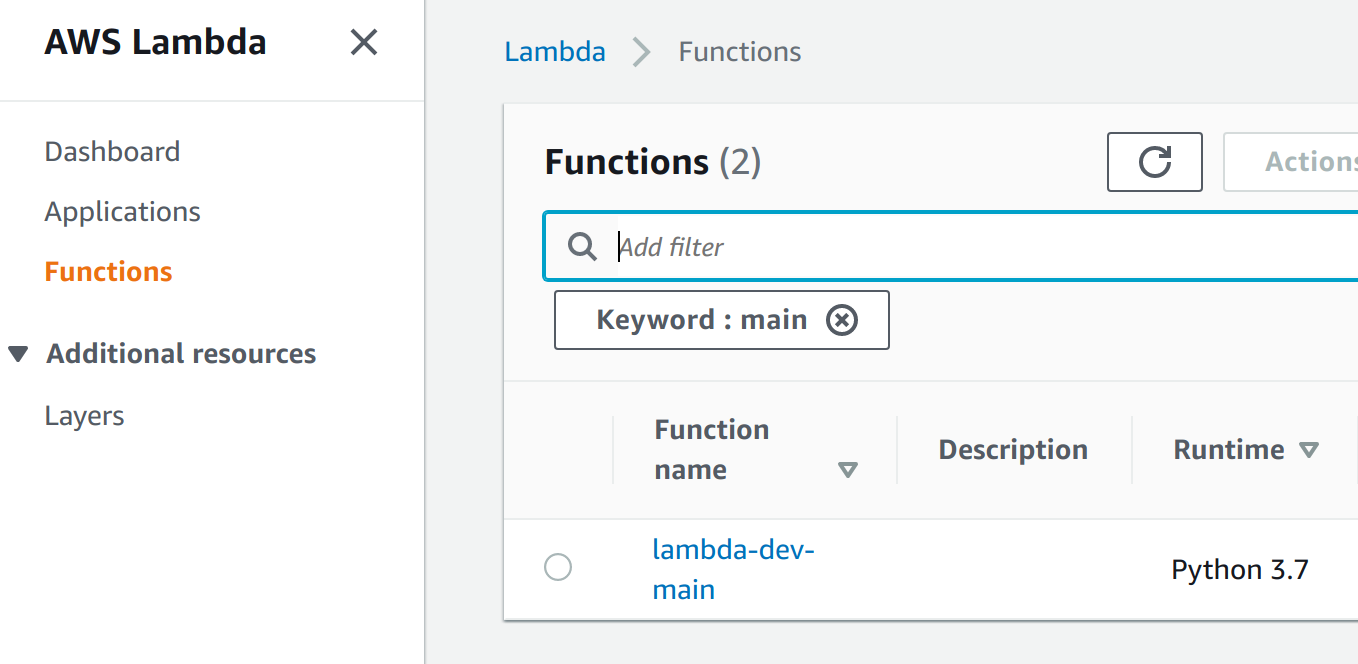
FunctionsにはLambdaが実行するプログラムが配置されている(おなじみ?)
Lambda Layerについて
クラスメソッドさんの下記の記事でわかりやすく解説されていたので、適宜ご参照ください。
従来のLambdaではそれぞれの関数ごとにパッケージングしてデプロイしなければならなかった、複数のLambda関数で共有するカスタムコードやライブラリをビジネスロジックから使うことができるようになります。
新しいLambda Layerのアップデートでは、共有コンポーネントを一つのZIPファイルに固めてアップロードすることができます。既存の関数は通常参照を変更する必要がありません。レイヤーはバージョンでマネージされてイミュータブルです。削除されたり許可されないバージョンへの呼び出しは拒否されます。
出所:【速報】【アップデート】Lambdaが複数のファンクションで共有するコードを持てるようになりました(Lambda Layer) #reinvent
4. headless-chromeとchromedriverのインストール方法
- AWS Lambdaで使うSelenium関連のファイルの格納ディレクトリの作成
- ここでは **
selenium-layer/driver**とする - gkzz/serverless-scraperをクローンした方は不要
- このselenium-layerがAWS Lambdaの**
Lambda Layer**配下に配置するディレクトリ
- ここでは **
gkz@localhost ~/serverless-scraper (master) $ mkdir -p selenium-layer/driver
- headless-chromeのインストール
gkz@localhost ~/serverless-scraper (master) $ CHROMEVERSION="v.1.0.0-45" \
&& CHROMEFILE=https://github.com/adieuadieu/serverless-chrome/releases/download/${CHROMEVERSION}/stable-headless-chromium-amazonlinux-2017-03.zip \
&& curl -SL $CHROMEFILE > headless-chromium.zip \
&& unzip headless-chromium.zip \
&& rm headless-chromium.zip \
&& mv headless-chromium selenium-layer/driver/
- chromedriverのインストール
gkz@localhost ~/serverless-scraper (master) $ DRIVERVERSION="2.40" \
&& CHROMEDRIVER=https://chromedriver.storage.googleapis.com/${DRIVERVERSION}/chromedriver_linux64.zip \
&& curl -SL $CHROMEDRIVER > chromedriver.zip \
&& unzip chromedriver.zip \
&& rm -rf chromedriver.zip \
&& mv chromedriver selenium-layer/driver/
つまずきポイントは、headless-chromeとchromedriverのバージョン選定方法ですが、こちらについては、7. chromedriverとheadless-chromeのバージョン選定ミスを防ぐ方法で後述します。
5. Seleniumファイルのデプロイ手順とそのポイント
5-1. デプロイ手順
- serverless frameworkをインストール
gkz@localhost ~/serverless-scraper (master) $ sudo npm install -g serverless
-
Lambda Layer配下に配置するSeleniumファイルの作成
gkz@localhost ~/serverless-scraper (master) $ cd selenium-layer
gkz@localhost ~/serverless-scraper/selenium-layer (master) $ npm init
- seleniu-layer/serverless.ymlで使う環境変数をconfig/.envに定義
# base
STAGE=dev
REGION=ap-northeast-1
- Serverless Frameworkのプラグインのインストール
gkz@localhost ~/serverless-scraper/selenium-layer (master) $ sudo npm install --save serverless-dotenv-plugin
- seleniumを以下のディレクトリにインストール
selenium/python/lib/python3.7/site-packages selenium- ここで指定したディレクトリ(ここではselenium)がLambda Layers配下に配置される
gkz@localhost ~/serverless-scraper/selenium-layer (master) $ pip install -t selenium/python/lib/python3.7/site-packages selenium
- selenium-layer/serverless.ymlを編集
service: selenium-layer
custom:
dotenv:
basePath: ./config/
pythonVer: python3.7
stage: ${env:STAGE}
region: ${env:REGION}
provider:
name: aws
runtime: ${self:custom.pythonVer}
stage: ${self:custom.stage}
region: ${self:custom.region}
plugins:
- serverless-dotenv-plugin
layers:
selenium:
path: selenium
description: selenium layer
CompatibleRuntimes:
- ${self:custom.pythonVer}
chromedriver:
path: driver
description: chrome driver layer
CompatibleRuntimes:
- ${self:custom.pythonVer}
## 「5-2. Selenium-layerとLambda間でLayerを共有する仕組み」
resources:
Outputs:
SeleniumLayerExport:
Value:
Ref: SeleniumLambdaLayer
Export:
Name: SeleniumLambdaLayer
ChromedriverLayerExport:
Value:
Ref: ChromedriverLambdaLayer
Export:
Name: ChromedriverLambdaLayer
- Selenium関連ファイルをデプロイ!
gkz@localhost ~/serverless-scraper/selenium-layer (master) $ serverless deploy
※Selenium関連ファイルをデプロイすると、Layersにchromedriverとseleniumが配置されていることが確認できます。
5-2. Selenium-layerとLambda間でLayerを共有する仕組み
-
layersでselenium関連のファイルを格納し、resourcesで次にデプロイするLambda側のserverless.ymlで活用する
- Exportで出力するSeleniumLambdaLayerやChromedriverLambdaLayerをRefで取得し、
後続のLambda側のserverless.ymlのlayersで参照出来るようにする
- Exportで出力するSeleniumLambdaLayerやChromedriverLambdaLayerをRefで取得し、
-
このLayer周りに関する記述がServerless Frameworkのドキュメントで見当たらず、下記の記事を参考にデバッグしながら実装したので正確に説明できているか自信がないです。
-
参考資料などありましたら、コメントにてご共有いただけるとうれしいです。
- Refなどの書き方はCloudFormationからきているというのは聞いたことがあるのですが。。
同じスタックのリソース(もしくはパラメータ)を参照したい場合は Ref を使う
別のスタックのリソース(もしくは何かしらの値)を参照したい場合は エクスポートされている名前、値を確認した上で ImportValue を使う
参考:CloudFormation の参照周りで意識すべきポイント・Tips
6. Lambdaファイルのデプロイ手順とそのポイント
6-1. デプロイ手順
- 必要なプラグインをインストール
gkz@localhost ~/serverless-scraper (master) $ cd lambda
gkz@localhost ~/serverless-scraper/lambda (master) $ npm init
$ sudo npm install --save serverless-python-requirements \
> && sudo npm install --save serverless-dotenv-plugin \
> && sudo npm install --save serverless-offline
- lambda/serverless.ymlで使う環境変数をconfig/.envに定義
# base
STAGE=dev
REGION=ap-northeast-1
# project dir
projectDir=serverless-scraper
- lambda/serverless.ymlを編集
service: lambda
custom:
dotenv:
basePath: ./config/
projectDir: ${env:projectDir}
pythonVer: python3.7
stage: ${env:STAGE}
region: ${env:REGION}
timeout: 900
TZ: Asia/Tokyo
seleniumLayer: selenium-layer
provider:
name: aws
runtime: ${self:custom.pythonVer}
stage: ${self:custom.stage}
region: ${self:custom.region}
timeout: ${self:custom.timeout}」
# selenium側のserverless.ymlの「service」の値
environment:
SELENIUM_LAYER_SERVICE: ${self:custom.seleniumLayer}
TZ: ${self:custom.TZ}
iamRoleStatements:
- Effect: 'Allow'
Action:
- "lambda:InvokeFunction"
- "lambda:InvokeAsync"
- "s3:ListBucket"
- "s3:GetObject"
- "s3:PutObject"
- "s3:DeleteObject"
# S3に保存するスクリーンショットのパス
Resource:
Fn::Join:
- ""
- - "arn:aws:s3:::"
- ${self:custom.projectDir}-${self:custom.stage}
- "/*"
plugins:
- serverless-python-requirements
- serverless-dotenv-plugin
- serverless-offline
functions:
main:
handler: handler.main
# seleniumとChromeのLayersにおけるパス
layers:
- ${cf:${self:custom.seleniumLayer}-${self:custom.stage}.SeleniumLayerExport}
- ${cf:${self:custom.seleniumLayer}-${self:custom.stage}.ChromedriverLayerExport}
environment:
S3BUCKET: ${self:custom.projectDir}-${self:custom.stage}
events:
# - schedule: cron(0/40 * * * ? *) # 毎日40分おき
- schedule: cron(3 * * * ? *) #毎日NN時03分おき
package:
include:
- '.fonts/**'
resources:
Resources:
Bucket:
Type: AWS::S3::Bucket
Properties:
BucketName: ${self:custom.projectDir}-${self:custom.stage}
- lambda/handler.pyを編集
import os
import json
import random
import time
import datetime
import logging
import traceback
import boto3
# selenium
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
from selenium.common.exceptions import NoSuchElementException
from selenium.webdriver.support.ui import Select
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.keys import Keys
# set up Logger
import logging
import sys
logger = logging.getLogger()
for h in logger.handlers:
logger.removeHandler(h)
handler = logging.StreamHandler(sys.stdout)
handler.setFormatter(logging.Formatter(
'%(levelname)s %(asctime)s [%(funcName)s] %(message)s'))
logger.addHandler(handler)
logger.setLevel(logging.INFO)
#logger.setLevel(logging.DEBUG)
def set_selenium_options():
""" Set selenium options """
options = Options()
options.binary_location = '/opt/headless-chromium'
options.add_argument('--headless')
options.add_argument('--window-size=1280,1024')
options.add_argument('--no-sandbox')
options.add_argument('--single-process')
options.add_argument('--disable-dev-shm-usage')
options.add_argument("--homedir=/tmp")
return webdriver.Chrome('/opt/chromedriver', chrome_options=options)
def wait_until_element_present(driver, key, location):
""" Wait until element is presented at location """
elm = None
counter = 4
timeup = 20
while counter < timeup:
try:
elm = WebDriverWait(driver, counter).until(
EC.presence_of_element_located((key, location)))
except NoSuchElementException as e:
logger.warn("[WARN] {e}".format(e=e))
logger.warn("counter: {val}".format(val=counter))
counter += 2
continue
except TimeoutException as e:
logger.warn("[WARN] {e}".format(e=e))
logger.warn("counter: {val}".format(val=counter))
counter += 2
continue
else:
break
return elm
def get_text_by_xpath(driver, location):
return driver.find_element_by_xpath(location).text
def save_screenshot(driver, filename):
""" Save screenshot at Amazon S3 """
s3client = boto3.client('s3')
driver.save_screenshot("/tmp/" + filename)
bucket = os.environ.get("S3BUCKET", "")
s3client.upload_file(
Filename="/tmp/" + filename,
Bucket=bucket,
Key=filename
)
return
def terminate_driver(driver):
""" Terminate driver """
driver.close()
driver.quit()
return
def main(event, context):
""" Entrypoint of lambda """
# Debug event to CloudWatch log
starttime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
logging.info("starttime: {}".format(starttime))
logging.info(json.dumps(event))
driver = None
target = None
url = "https://gkzz.github.io"
location = '//*[@id="featured"]/article/ul[1]/li[2]/p'
try:
driver = set_selenium_options()
driver.maximize_window()
driver.get(url)
presented = wait_until_element_present(
driver, By.XPATH, location)
save_screenshot(
driver, 'ss_' + datetime.datetime.now().strftime('%Y%m%d_%H%M%S' + '.png'))
if presented is not None:
target = driver.find_element_by_xpath(location).text
endtime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
logging.info("endtime: {}".format(endtime))
terminate_driver(driver)
return {
"statusCode": 200,
"body": target
}
except Exception as e:
logger.error("[ERROR] {e}".format(e=e))
terminate_driver(driver)
return {
"statusCode": 400,
"body": e
}
- lambda/handler.pyとlambda/.fonts/*.ttfファイルをデプロイ!
$ serverless deploy
- ローカルから実行してみる
gkz@localhost ~/serverless-scraper/lambda (master)$ sls invoke -f main
Serverless: DOTENV: Loading environment variables from ./config/.env:
Serverless: - STAGE
Serverless: - REGION
Serverless: - projectDir
{
"statusCode": 200,
"body": "Current: Software Engineer at AP Communications Co., Ltd."
}
- スクリーンショットがS3に保存されていることが確認できました!!
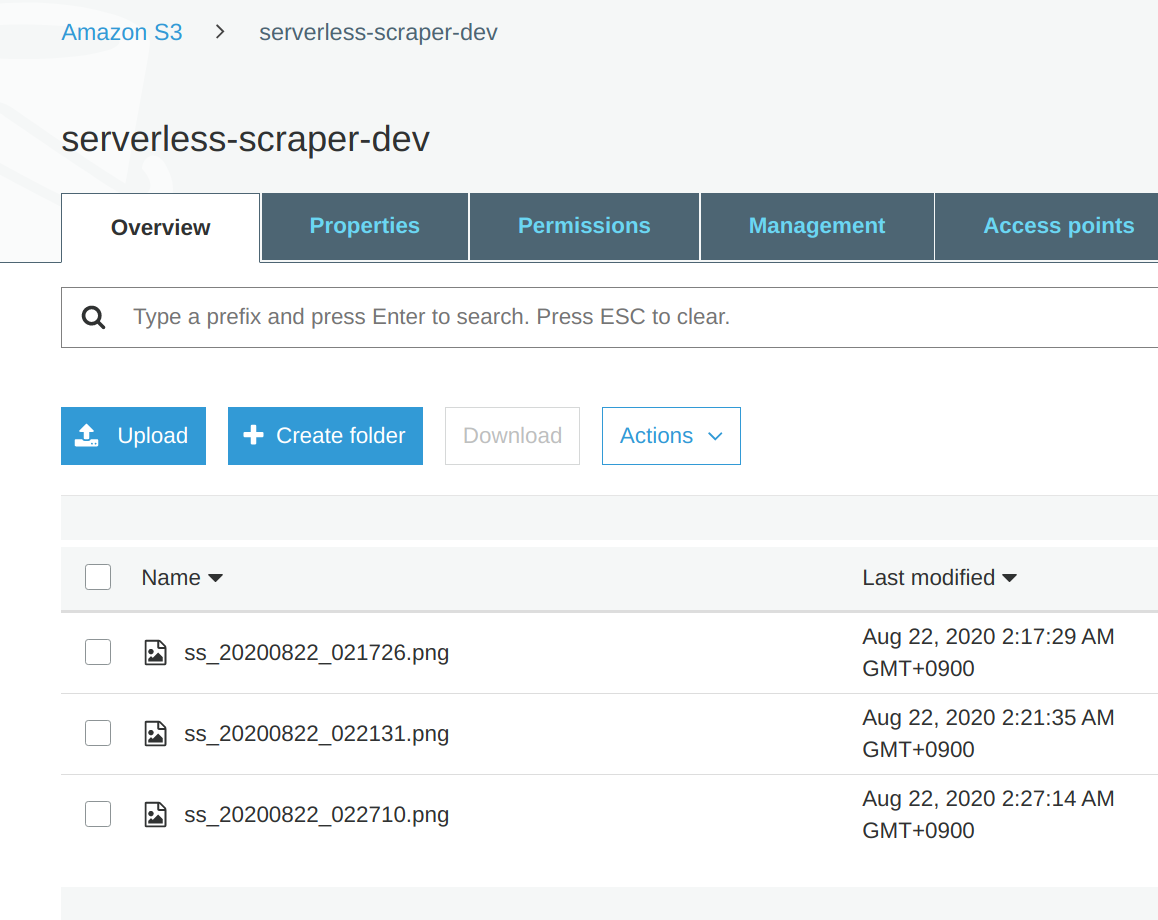
7. chromedriverとheadless-chromeのバージョン選定ミスを防ぐ方法
7-1. ChromeとChromeDriverのバージョン指定を誤った場合、デプロイ時にこのようなエラーを引く
- ローカルからAWS Lambdaを実行
gkz@localhost ~/serverless-scraper/lambda (master) $ serverless invoke -f main
Serverless: DOTENV: Loading environment variables from ./config/.env:
Serverless: - STAGE
Serverless: - REGION
Serverless: - projectDir
{
"errorMessage": "'NoneType' object has no attribute 'close'",
"errorType": "AttributeError",
"stackTrace": [
" File \"/var/task/handler.py\", line 133, in main\n terminate_driver(driver)\n",
" File \"/var/task/handler.py\", line 95, in terminate_driver\n driver.close()\n"
]
}
Error --------------------------------------------------
Error: Invoked function failed
at AwsInvoke.log (/usr/local/lib/node_modules/serverless/lib/plugins/aws/invoke/index.js:105:31)
at AwsInvoke.tryCatcher (/usr/local/lib/node_modules/serverless/node_modules/bluebird/js/release/util.js:16:23)
at Promise._settlePromiseFromHandler (/usr/local/lib/node_modules/serverless/node_modules/bluebird/js/release/promise.js:547:31)
at Promise._settlePromise (/usr/local/lib/node_modules/serverless/node_modules/bluebird/js/release/promise.js:604:18)
at Promise._settlePromise0 (/usr/local/lib/node_modules/serverless/node_modules/bluebird/js/release/promise.js:649:10)
at Promise._settlePromises (/usr/local/lib/node_modules/serverless/node_modules/bluebird/js/release/promise.js:729:18)
at _drainQueueStep (/usr/local/lib/node_modules/serverless/node_modules/bluebird/js/release/async.js:93:12)
at _drainQueue (/usr/local/lib/node_modules/serverless/node_modules/bluebird/js/release/async.js:86:9)
at Async._drainQueues (/usr/local/lib/node_modules/serverless/node_modules/bluebird/js/release/async.js:102:5)
at Immediate.Async.drainQueues [as _onImmediate] (/usr/local/lib/node_modules/serverless/node_modules/bluebird/js/release/async.js:15:14)
at processImmediate (internal/timers.js:456:21)
For debugging logs, run again after setting the "SLS_DEBUG=*" environment variable.
Get Support --------------------------------------------
Docs: docs.serverless.com
Bugs: github.com/serverless/serverless/issues
Issues: forum.serverless.com
Your Environment Information ---------------------------
Operating System: linux
Node Version: 12.18.3
Framework Version: 1.79.0
Plugin Version: 3.7.1
SDK Version: 2.3.1
Components Version: 2.34.6
issueでも、バージョン指定のミスが原因とコメントがありました。
After a lot of tooling around, I got it to work on Lambda. The problem was
with incompatible versions of serverless-chrome, chromedriver, and Selenium. These are the versions that play well together in Lambda. Why is beyond me:
chromedriver v.2.37
severless-chrome v.0.0-37
selenium 2.53.6 (for Python)
参考:Chrome not reachable with Selenium Python · Issue #133 · adieuadieu/serverless-chrome
7-2. バージョンの確認方法
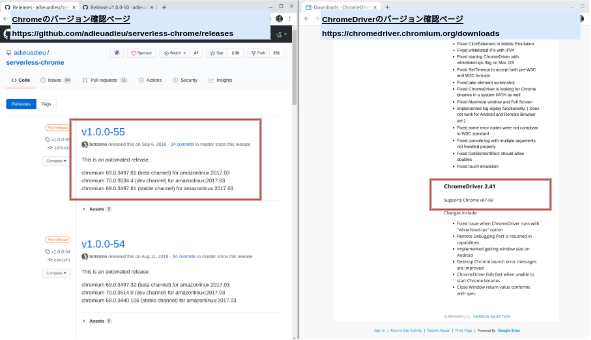
例)Chromeのバージョンはv1.0.0-55としたとき、対応するChromeDriverのバージョンを確認する
-
- スクリーンショットの左側の「Chromeのバージョン確認ページ」からChromeの任意のバージョンを決める
- ここでは**
v1.0.0-55**とする
-
- スクリーンショットの左側の「Chromeのバージョン確認ページ」で決めたChromeのバージョンの少し下のbeta/dev/stableのいずれかからChromeのバージョン名とzipリンクを控えておく
| 例 | |
|---|---|
| バージョン名 | chromium 67.0.3396.99 (stable channel) for amazonlinux:2017.03 |
| zipリンク | https://github.com/adieuadieu/serverless-chrome/releases/download/v1.0.0-50/stable-headless-chromium-amazonlinux-2017-03.zip |
-
-
スクリーンショットの右側の「ChromeDriverのバージョン確認ページ」から、
2で控えていたChromeの任意のバージョンを探す
-
スクリーンショットの右側の「ChromeDriverのバージョン確認ページ」から、
例)バージョン名が**chromium 67.0.3396.99 (stable channel) for amazonlinux:2017.03**の場合
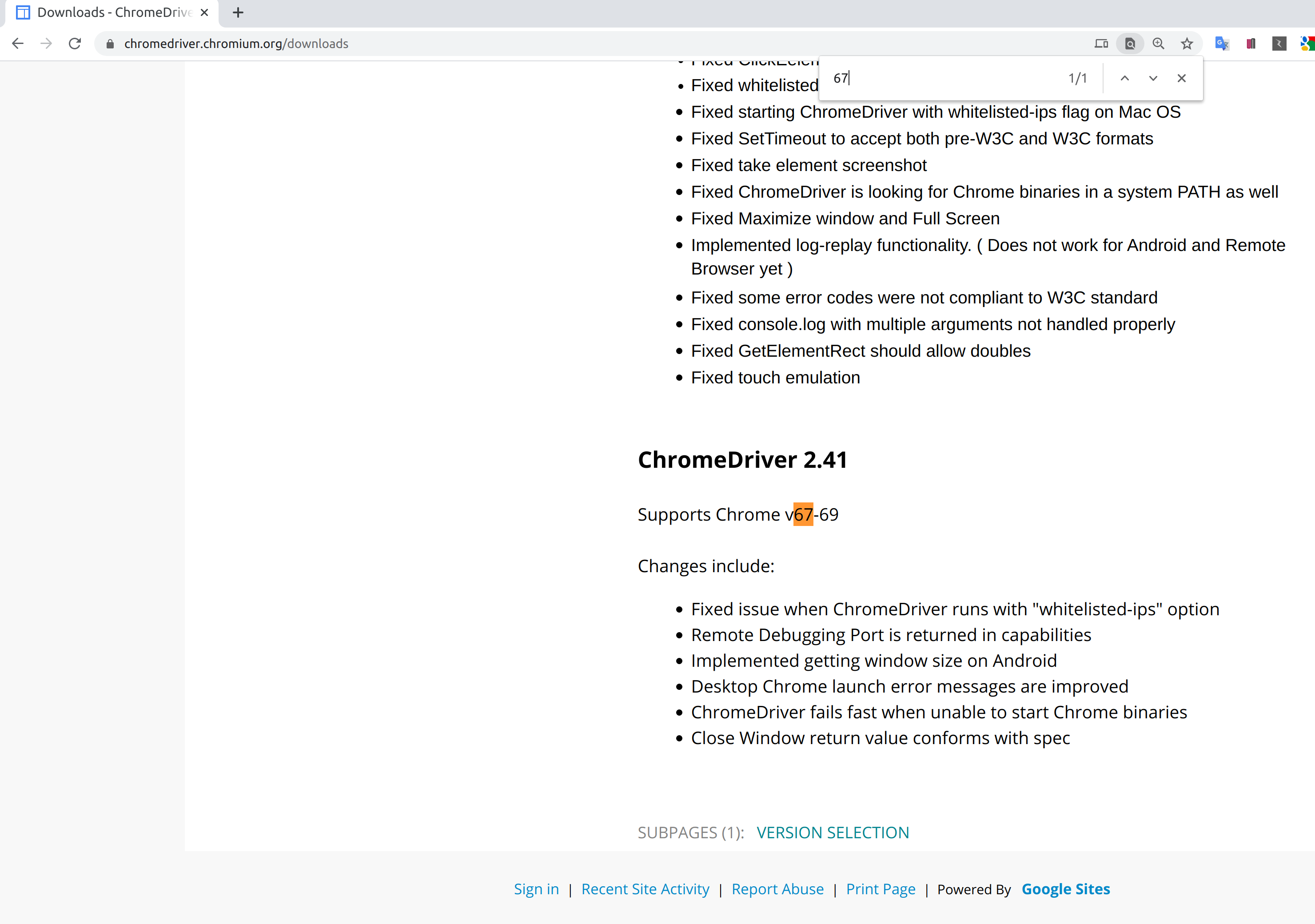
-
- これでChromeとChromeDriverのバージョンはこのように確認できた。
| 例 | |
|---|---|
| Chromeのバージョン名 | chromium 67.0.3396.99 (stable channel) for amazonlinux:2017.03 |
| zipリンク | https://github.com/adieuadieu/serverless-chrome/releases/download/v1.0.0-50/stable-headless-chromium-amazonlinux-2017-03.zip |
| ChromeDriverのバージョン名 | ChromeDriver 2.41 |
| zipリンク | https://chromedriver.storage.googleapis.com/2.41/chromedriver_linux64.zip |
出所:
ダウンロードリンクが公開されていない場合
本記事執筆時点ではChromeDriver 2.41のダウンロードリンクが公開されていませんでした。
そこで、本記事ではWayback Machine を使ってダウンロードリンクを調べました。
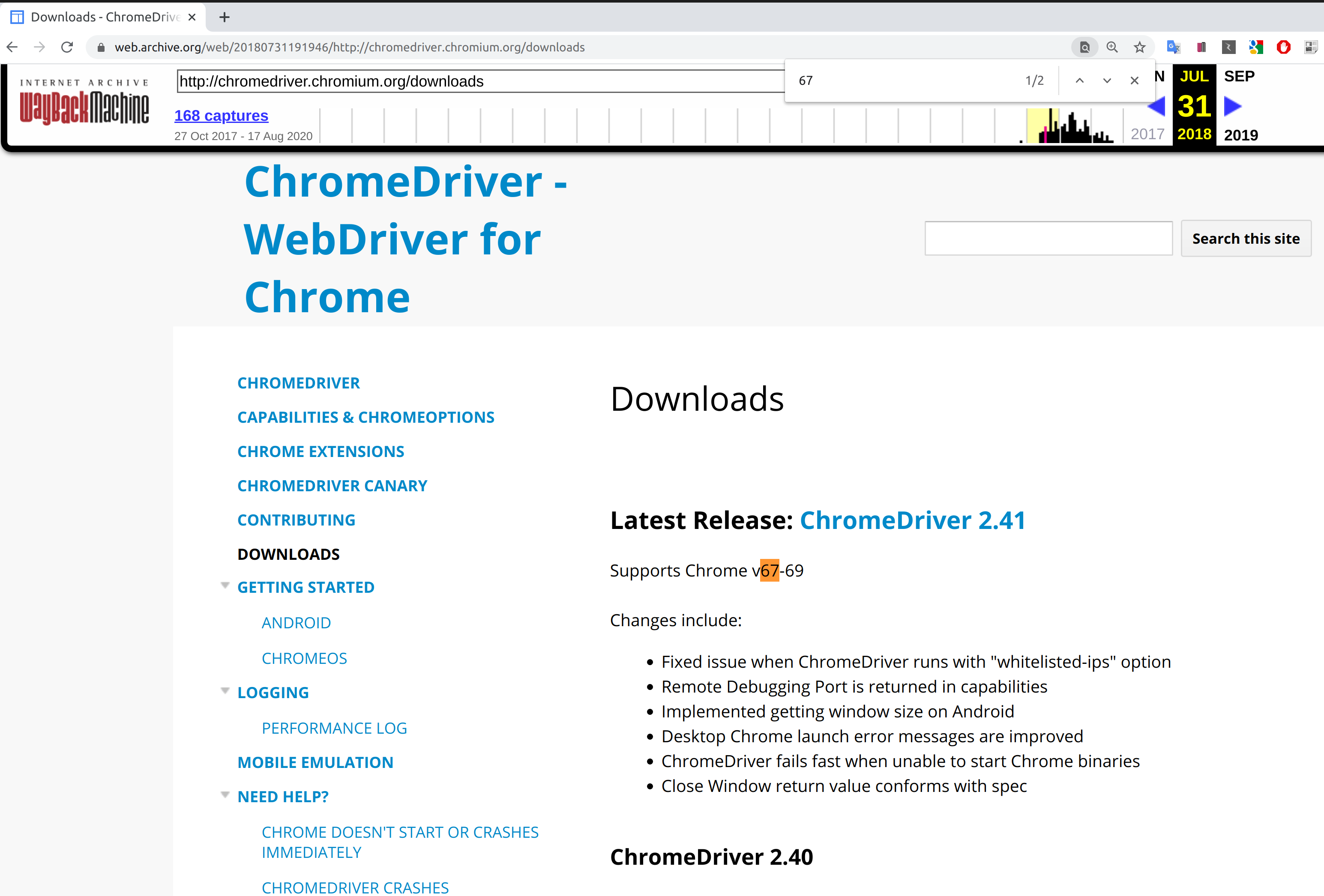
参考:web.archive.org/web/20180731191946| Downloads - ChromeDriver - WebDriver for Chrome
8. 文字化け対策
下記の記事を参考にlambda/.fonts配下にIPAexフォント ダウンロードページ
Download IPAex Fontsからipaexg.ttfとipaexm.ttfを配置します。
gkz@localhost ~/serverless-scraper (master) $ ls lambda/.fonts/
ipaexg.ttf ipaexm.ttf
最終的に、”.fonts”ディレクトリをLambdaのパッケージに含めて一緒にデプロイすることで解決しました
出所:Headless ChromeとSeleniumをLambdaで動かす
9. 参考資料
- サンプルコード
- Lambda Layerについて
- seleniumとChrome、ChromeDriverの使い方
- Refなどの書き方
- chromedriverとheadless-chromeのバージョン選定ミスに関するIssue
- Chrome not reachable with Selenium Python · Issue #133 · adieuadieu/serverless-chrome
- 文字化け対策