ひさしぶりです。グラフ大好きのスーパーケロケロです。前回のテキストに含まれた情報を有向グラフに変換する話(二):依存構造グラフの章で依存構造のグラフについて色々考察しましたが、今回はその発展としての知識構造グラフを紹介します。
何故の知識構造グラフなのか
前回の考察で、依存構造グラフでは色々情報をなくしている事について説明しました。そのひとつの例として、下記のテキストから依存構造グラフを生成してみました:
猫はネズミが好きだ。
ネズミは犬が好きだ。
犬は猫が好きだ。
# ライブラリーのインポート
from naruhodo import parser
# パーサ取得
dp = parser(lang='ja', gtype='d')
#
dp.add("猫はネズミが好きだ。")
dp.add("ネズミは犬が好きだ。")
dp.add("犬は猫が好きだ。")
# Jupyter Notebook を使ている場合は show() で図を表示
# それ以外の場合は plotToFile(filename="pic.png")
dp.show()
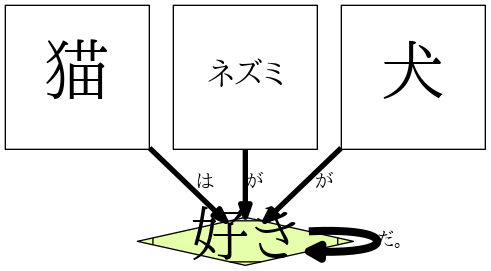
この文に含まれている情報をグラフで描こうとすれば、直感的に三角形になるはず、だが依存構造グラフではそうならない。
前回の考察で、依存構造グラフ自体は直接の応用が難しいという結論に辿り着きました。色々原因について考えたが、一番の理由は、前述の例で示した「有効な情報を一部抜けている」だと考えられる。
データ処理の一般論として、扱いずらいデータ(例えばテキスト)をある種の変換操作(例えばベクトル化する)を施す事で扱いやすくして、そこから色々解析して行く。ここで重要なのは、変換したデータ構造は重要な情報をしっかり保存する事です。
変換で重要な情報が抜けてしまったら、役に立たなくなります。私が「テキストをグラフ化にする」事を考えたのは、グラフというデータ構造でテキストに含まれた有効な情報を取り出し、さらに既存のグラフアルゴリズムを利用して効率的に情報を解析するためです。
前回で紹介した通り、テキストが持つ実際の意味をグラフのような構造化したデータに変換するというのは、知識表現という人工知能研究の領域に属する。既存の知識表現の多くは人工で構築する知識ベースの形になっていて、その応用として、ある特定の領域に特化したエキスパートシステムが一般的です。もっと汎用的な知識表現も近年色々研究されているが、オントロジーやロジックに基づいたフォーマルな物が多く、敷居の高い物になっています。自分も今 Michel Chein のGraph-based Knowledge Representation: Computational Foundations of Conceptual Graphsなどを頑張って読んでいるが、中々そう簡単に応用できる物ではありませんね。自動推論などをやりたければ恐らくこのレベルのフォーマル性は必要だと思いますが、一歩譲ってもっと低レベルで分かりやすいグラフ表現はないのかについて考えた結果がこれから紹介する知識表現グラフです。
知識表現グラフの仕組み
まず**「テキストに含まれる有効な情報とは何か?」**について考えてみる。
自分の理解している有効な情報は大抵の場合、実体と実体の関係や、実体にまつわるアクションや性質に関する記述になります。アクション自体も追加情報を持つ事があり、さらに前述の関係や記述自体が一つの実体として、別の関係や記述の一部になりうる。
「AはBだ」=> 実体と実体の関係・実体にまつわる性質に関する記述
「AはBをDする」=> 実体と実体の関係・実体にまつわるアクションに関する記述
「AはBをSでDする」=> アクションに関する記述への追加情報
「AがDすることはEだ」=> アクションに関する記述を実体として別の関係や記述の一部
もちろん他にも色々ありますが、有効な情報には、実体に関する記述が欠かせないと考えられます。さらに、同じアクションでも主体・客体が変われば別の情報になるので、アクションについての記述がある場合、主体・客体を明白に判別する必要があります(主体・客体が無いケースも含めて)。
実体をノードにして、関係やアクションをエッジとして表示するのが一番普通な考えで、多くの知識表現スキームに採用されています。例えば前述の動物三角形はこんな感じになります:
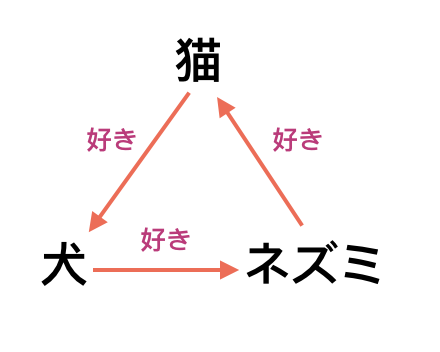
ここで注目すべき所は関係やアクションがエッジになっているから、主体と客体(エッジの両端)の違いによって例え名前が同じでも区別されている事。つまり、情報を保持したければ、関係やアクションを主体と客体でマークする必要がある。
勿論、同じ実体ペアの間に複数の関係があっても良いはずなので、同じノードのペアの間に複数のエッジが存在することから、有向グラフは有向マルチグラフになります:
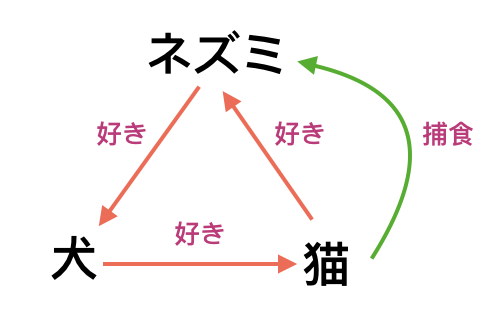
これで動物三角形の問題は解決できました。しかし、まだ問題があります。アクションや性質に関する記述の場合、必ずしも主体と客体を同時に持っているとは限りません。例えば「猫が鳴いた」の場合、「鳴る」というアクションは客体を持たない。アクションをエッジにしている分、両端をちゃんと決めなければならない。こういうマルチグラフ表示では、端が欠けている情報をうまく表現できない。解決方法として、「空き」を表現するノードを用意すればこういった情報でも記述可能になりますが、、、

これをやっても幾つかの問題があります:
- 「空き」ノードを一つだけ用意する場合、本来関係無いノードでも勝手に繋がってしまい、「空き」周りのエッジがグラフのエッジの大半を占める事になって、グラフに「空き」ブラックホールがあるようで、かなり見ずらくなります(ある意味ブラックホールで大正解な気もしますが┐(´-`)┌)。
- 「空き」ノードを主体・客体・アクションで区分する場合、グラフ上に大量の「空き」ノードが出現します。今度は「宇宙ゴミ」がいっぱい出てきて、グラフを見るたびに掃除したくなる。
- さらにアクションノードに時間や手段などを表す情報がある場合、エッジの属性として付加することしか選択肢はないので、この場合は一部の実体がグラフのノードにならなくなり、本来捉えるべき一部実体間の繋がりが取れない可能性があります。前述の「空き」問題はあくまで見た目の問題で、取る情報自体にディメリットは無いはずだが、ここの情報不全は大きなディメリットになります。
- 最後に一番厄介なのは、「アクションに関する記述を実体として別の関係や記述の一部になる」場合です。基本は「ノードの集合をクラスターにして新しいノードとして扱う」か「エッジをノードとして扱う」の二択になります。クラスターのやり方を取ると、マルチレイヤーマルチグラフになり、扱いが一気に複雑になります(マルチグラフだけでも結構やりずらいなのに)。エッジをノードとして扱う方がよっぽど現実的です。
というわけで、「エッジをノードとして扱う」方向で行く事にしたが、これをやると、ノードとエッジが区分できなくなって、もはや我々が知っているグラフではなくなります。グラフ大好きマンとしての私には許しがたい事態です(๑ʘ∆ʘ๑)。
でもちょっと待って......
エッジをノードにすれば良いという事でしょう?
エッジをノードにすれば良いんだよな?
エッジをノードに......
じゃ単純に今のエッジの属性として記述している述語の部分をノードにすれば良いんじゃ無いか(๑ʘ∆ʘ๑)?
それをやってみた結果がこれです:

述語を主体で区分した上に単独のノードとして扱うだけで、前述の問題が全て解決できます。「空き」ブラックホールや宇宙ゴミの心配もなければ、アクションの追加情報やアクションの集合を実体としてさらに関係を構築することも可能です。そして何より嬉しいのがグラフ自体は普通の有向グラフになるから、ややこしいマルチグラフの扱いも考えなくて済む。これが今naruhodoに採用されている知識構造グラフの基本的な仕組みです。
グラフ生成自体は意外と簡単な方です。基本的に依存構造グラフのROOTを順番に辿って、各要素(主体・客体など)を判定してからルールに従ってエッジを作ればいい。前回で話した「親と子の間の相互関係をエッジの属性として与えられる」タイプ情報付き依存構造(Typed dependency structure)を出力する機能はCabochaやKNPなどの日本語構造解析パッケージにはなかったが、機能語や品詞の情報で割りと判断できるようになっているからさほど問題ではない。
知識構造グラフから得られる情報
一つの例としてWikipediaのミケランジェロ・ディ・ロドヴィーコ・ブオナローティ・シモーニのテキストを知識構造グラフにしました。ノード数がかなり大きいので、JupyterNotebookでは中々表示できないから、JavaScriptで動くnaruhodo-viewerを使って可視化してみました(下の図)。自分でnaruhodo-viewerを使っていれば拡大・縮小などインターラクティブにグラフの中身を確認できるので、興味があれば試してみてください。naruhodo-viewerに関しては、時間があればまた別のブログ記事で紹介します。
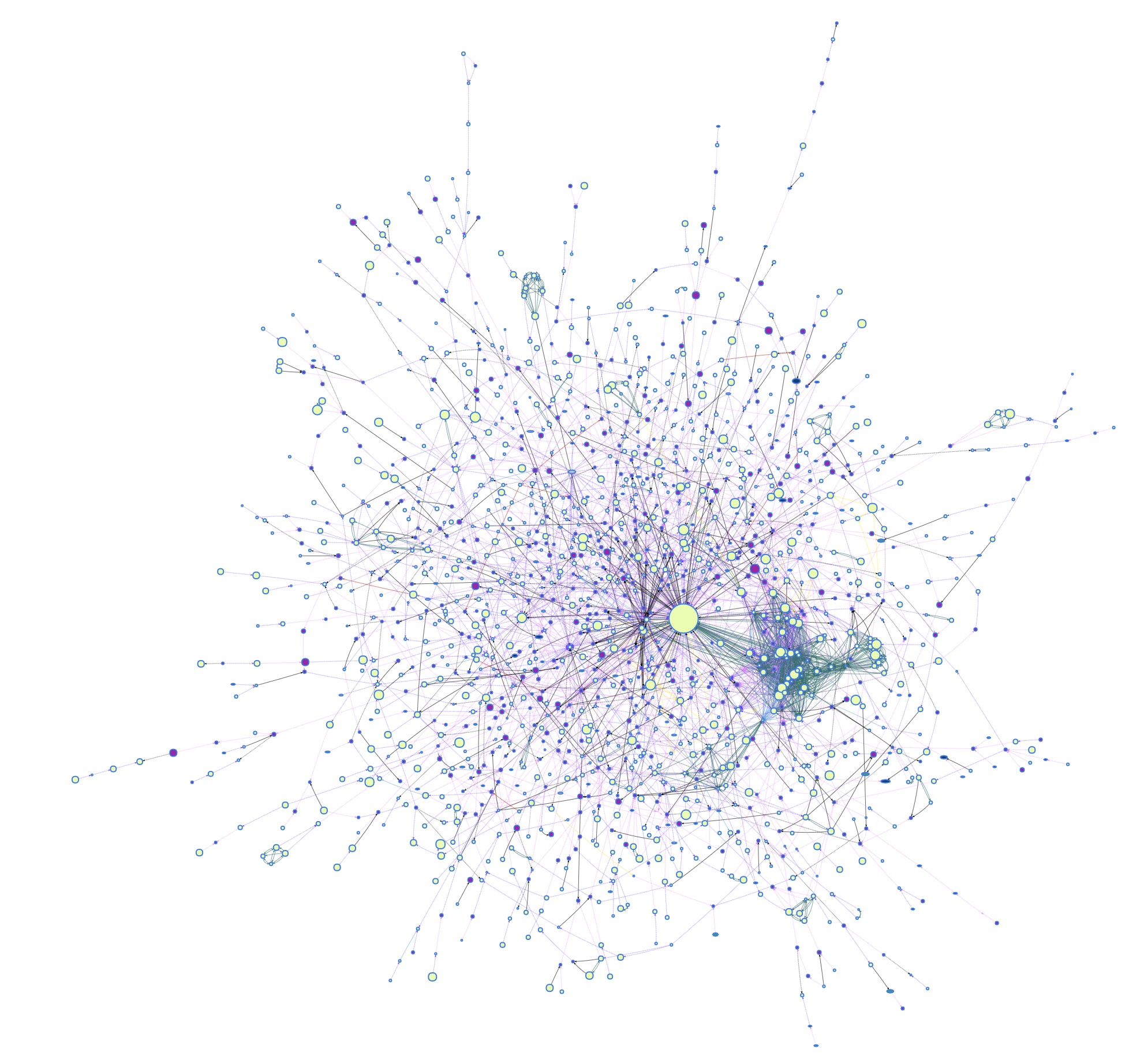
因みにこの図の真ん中の一番でかいノードは「ミケランジェロ」のノードです。Wikipediaの記事だから、ま、予想通りと言ったところか。
知識構造グラフは基本的に実体のネットワークなので、実体について見ていくのがいいでしょう。まずはミケランジェロが主体になっているアクションを出力させてみます。
# ライブラリーをインポート
from naruhodo import parser
# preprocessText は改行や括弧を除去する為の関数
from naruhodo.utils.misc import preprocessText
# パーサを取得して、グラフにテキストを追加
KA = parser(lang="ja", gtype="k")
texts = KA.addUrls("https://ja.wikipedia.org/wiki/%E3%83%9F%E3%82%B1%E3%83%A9%E3%83%B3%E3%82%B8%E3%82%A7%E3%83%AD%E3%83%BB%E3%83%96%E3%82%AA%E3%83%8A%E3%83%AD%E3%83%BC%E3%83%86%E3%82%A3")
# SUB->ACTION->OBJ 関係抽出
keyword = 'ミケランジェロ'
for key in KA.G.successors(keyword):
if KA.G.edges[keyword, key]['type'] == 'sub':
objs = list()
poss = list()
hasobj = False
for key2 in KA.G.successors(key):
if KA.G.edges[key, key2]['type'] == 'obj':
hasobj = True
objs.append(preprocessText(key2))
poss.append([])
# ポジションを特定
for val in KA.G.nodes[key]['pos']:
if val in KA.G.nodes[key2]['pos']:
poss[-1].append(val)
if not hasobj:
objs.append(" ")
poss.append(KA.G.nodes[key]['pos'])
# 結果をプリント
for item, item2 in zip(objs, poss):
print("| {0} | {1} | {2} |".format(preprocessText(key), item, item2))
| Action | Object | Position |
|---|---|---|
| 得る | 評価 | [3] |
| 制作 | [4, 33, 47] | |
| 変更 | 設計 | [11] |
| 存在 | [13] | |
| ある | [15] | |
| 生まれる | [17] | |
| 信じる | これ | [21] |
| 送る | 幼少期 | [22] |
| 死去 | 母フランチェスカ | [23] |
| 派遣 | [30] | |
| 参加 | [31] | |
| 学ぶ | 彫刻 | [32] |
| 交流 | 詩人たち | [32] |
| ... | ... | ... |
次はミケランジェロに関する陳述や属性について見よう:
for key in KA.G.successors(keyword):
if KA.G.edges[keyword, key]['type'] == 'stat':
print("| 陳述 | {0} | {1} |".format(preprocessText(key), KA.G.nodes[key]['pos']))
for key in KA.G.predecessors(keyword):
if KA.G.edges[key, keyword]['type'] == 'attr':
print("| 属性 | {0} | {1} |".format(preprocessText(key), KA.G.nodes[key]['pos']))
| Type | Attribute | Position |
|---|---|---|
| 陳述 | 人物 | [6, 84, 116] |
| 陳述 | 少年 | [28] |
| 陳述 | 性質 | [155] |
| 陳述 | 人物 | [38, 157] |
| 属性 | 保つ | [5] |
| 属性 | 当時 | [10, 15, 24, 29, 32, 51, 56, 76, 77, 96] |
| 属性 | 若年 | [27] |
| 属性 | 16歳頃 | [32] |
| ... | ... | ... |
このように知識構造グラフを辿れば各実体に関するアクションや性質などが容易にクエリできるようになります。naruhodoはさらにcabochaで解析したNEを分類ごとにentityListで保存している。
| NE ID | Description |
|---|---|
| 0 | Not named-entity(or unknown) |
| 1 | Person |
| 2 | Location |
| 3 | Organization |
| 4 | Number/Date |
| 5 | General |
例えば、テキストの中に現れる人の名前を確認したい場合、こうすれば全部見れる:
for key, val in KA.entityList[1].items():
print("| {0} | {1} |".format(preprocessText(key), val))
| Name | Position |
|---|---|
| ミケランジェロディ・ロドヴィーコ・ブオナローティ・シモーニ | [0] |
| ミケランジェロ自身 | [2, 8, 73, 75, 150] |
| ミケランジェロ | [3, 4, 5, 6, 7, 11, 12, 13, 14, 15, 16, 17, 18, 21, 22, 23, 24, 25, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 38, 39, 41, 43, 44, 46, 47, 48, 49, 50, 51, 52, 53, 55, 57, 58, 59, 60, 61, 63, 64, 65, 66, 67, 68, 70, 73, 74, 75, 76, 78, 79, 80, 86, 87, 88, 89, 90, 91, 93, 94, 97, 98, 103, 104, 105, 107, 108, 109, 110, 111, 116, 117, 119, 121, 122, 126, 127, 128, 129, 130, 131, 133, 136, 137, 139, 141, 143, 145, 147, 151, 152, 153, 154, 155, 156, 157, 158, 159, 160, 161, 163, 164, 165, 167, 170, 172] |
| ミケランジェロ誕生当時 | [19] |
| 聖遺物櫃 | [44] |
| ラオコーン像 | [60] |
| 聖ヨセフ | [68] |
| ... | ... |
当然のことですが、NEの精度はcabochaのモデルによって決まります(´・ω・`)。
naruhodoから生成した知識構造グラフから直接取れる情報はこのくらいですが、エッジの属性を利用してグラフを辿って行けば、原則として色んな細かい情報が得られるはず(アクションが起こった時間や場所など)。これを元にテキストから色んな知識ベースを作るのにだいぶ楽になると思います。テキストに含まれた情報を有向グラフに変換する話(一):可視化の章で下の図で自然言語解析の流れを説明した事があると思いますが、今の知識構造グラフを小麦粉を発酵させた「生地」だと例えれば分かりやすいでしょうか。

こういう「生地」の応用はそれなりにあると思います。例えば、複数のレビューテキストから生成した知識構造グラフを使えば実体別の感情分析ができるようになります。naruhodoが解析した結果は否定関係の情報(nodeの属性'negative')も取れているので、極性辞書と合わせば、シンプルで直接な感情分析が可能です。他の統計学習に基づいた感情分析テックニックと比べて、専用の訓練データなしで色んな種類のテキストに応用可能なのが一番の売りではないでしょうか。今は小林や乾研究室の極性辞書を参考してnaruhodo専用の極性辞書を作っているので、そのうちにGithubで公開しようと思います。
知識構造グラフの精度
気づいている人がいると思いますが、知識構造は依存構造から生成されることになっているので、その精度は完全に依存解析の精度に依存する。一つ有名な例を見ましょう:
望遠鏡で泳ぐ少女を見た。
cabochaのデフォルトモデルでの依存構造解析結果がこうなっている。

普通、望遠鏡で泳ぐ事はないだろうけど、パソコンには中々理解できないんですね(余談だがKNPはこの例を正確に解析できる、(´・ω・`)めちゃくちゃ遅いが)。
この場合、知識構造も不正確なものになります。

こう言った例はテキストが多くなると、どうしても混じってしまうので、注意が必要です。精度を上げたい場合はまずcabochaのモデルを検討する必要があるでしょう。
これに加えて、naruhodoではヒューリスティックな手法で解析しているので、あくまで「普通」のケースしか対応していない。Twitter、2ちゃん、記事板などでよく見かける変な文を投げると高確率で失敗する。
もう一つ言わなければならないのが、「共参照」と「同義語」(こちらも本当は共参照解析に入りますが)の解析です。こういう解析が正しく行えない場合、グラフに本来ある関係を取れなくなります。こう言った問題が一番顕著に出るのは人称代名詞がよく出てくる小説とかを解析する場合です。さらに日本語では主語が頻繁に省略されることもあり、今の所、こういうテキストは諦めるしかありません。今の共参照解析のSOTAメソッドは深層強化学習に基づいた方法(“Deep Reinforcement Learning for Mention-Ranking Coreference Models”)のようですが、大量のラベル付きデータが必要で日本語では中々実装できないし(深層学習がお金かかるのは計算資源だけじゃない)、これでも精度は完璧とは程遠いから、用途によっては全く使えない場合も少なくありません。
まとめ
今回は知識構造グラフについて色々説明しました。ここまでなると少しは実用性が見えて来た。次回はnaruhodo専用極性辞書の公開に合わせて、知識構造グラフでの感情分析について書きたいと思います。お楽しみに(≖ ‿ ≖)〜