Kaggle learingとは
データサイエンスのオンラインプラットフォーム「Kaggle」が提供するデータサイエンスのいろはを学べるところ.(https://www.kaggle.com/learn)
無料で質が高いのはいいが,(海外のフラットフォームなので)全て英語で記述されており敬遠されがち.
今回,Intro to machine lerningという機械学習の初歩となる章をそれぞれのセクションごとにまとめていく.
また,機械学習ではpythonが使われるが,pythonの初歩的な構文(pandas,numpy,matplotlibなど)や統計学の知識はある程度知っているものとして記述していく.
How Medel Work
ここでは機械学習のモデル構築において,最初に扱いつつもそれの組み合わせで最も優れたモデルを構築することができる決定木について述べていく.
仮に自分が不動産投資をするとなったらどのように行うだろう?1つの方法として「駅近なのか」,「ベットは2つ以上あるか」などそれぞれの条件でグループ分けする方法が存在するだろう.これが決定木の考え方である.実際にこれを図示すると,以下のようになる.
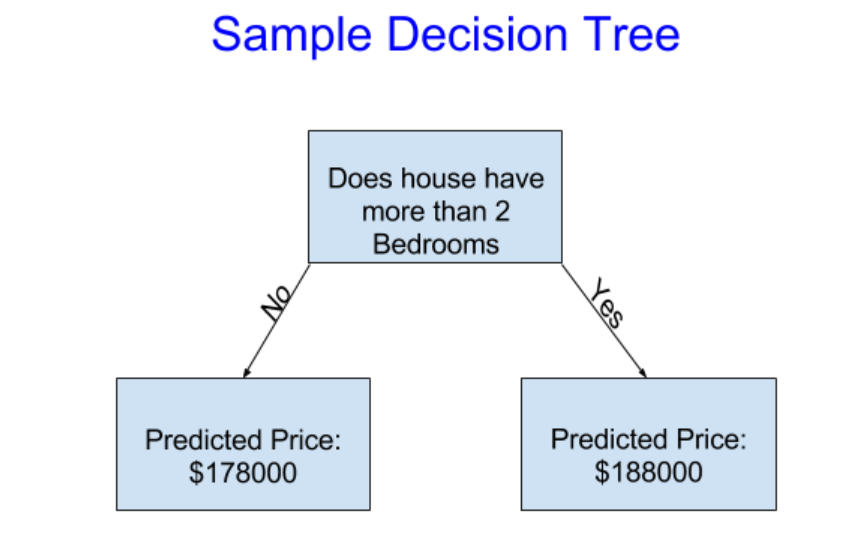
上の図は深さが1(depth=1)の決定木である.「ベットが2つ以上存在するか?」という問いに対して「No」の分岐をしている左側は予想価値(Predicted Price) = $178000と述べられている.このNoの分岐の結果として返される予想価値は学習の際に用いた(後述するが,機械学習は学習⇒予想の順で行われる)「ベットが2つ以上存在しない家の平均価値」である.同様に「ベットが2つ以上存在するか?」という問いに対して「Yes」の分岐をしている右側は学習の際に用いたベットが2つ以上存在する家の平均価値が$188000だったので,予想価値として$188000を返している.
今回例として出したのは深さが1の決定木であるが,実際に決定木を用いて家の価値を推測する際にはさらなる要因(ex.駅から徒歩10分以上か10分未満か,築浅かどうか)を用いて分岐を増やすことで精度を高めようとするだろう.
また,その「分岐をおこなう条件」(上でいうベットが2つ以上存在するか?)はfittingで学習することになるが,これは後ろのセクションで詳しく説明する.
Basic Data Exploration
機械学習の第一歩は,データに慣れることである.これには主に,データ解析を容易にする機能を提供するPythonのデータ解析ライブラリをである「pandas」用いる.pandasは通常以下のように読み込ませる.
import pandas as pd
pandasは慣習的にpdという名前で扱えるようにすることが多い.pandasで最も重要なライブラリがDataFrame型である.
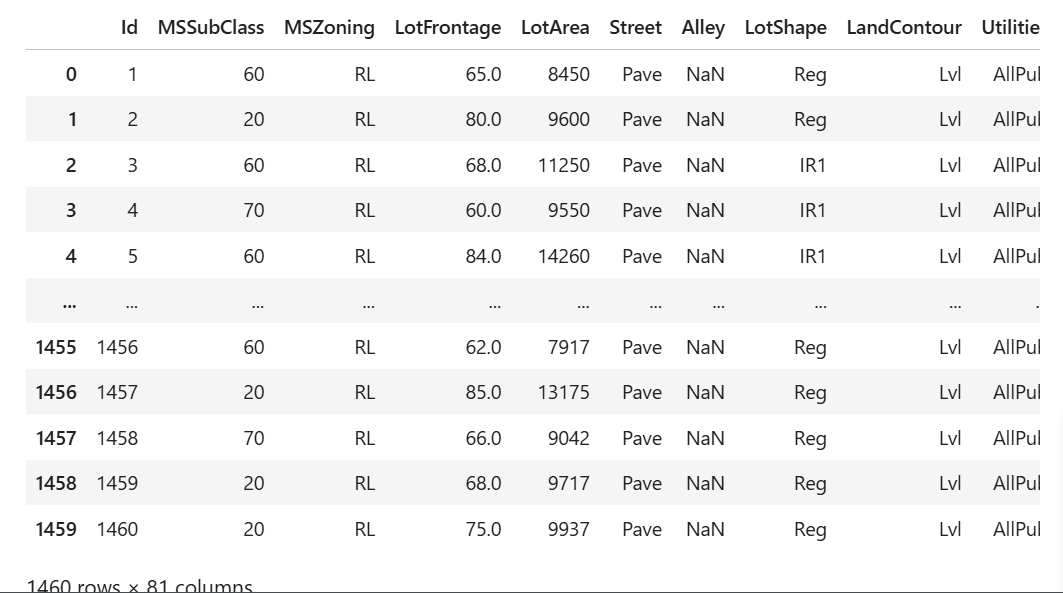
上の図は,iowa州に存在する物件をDataFrame型で表示させた図である.図を見てわかるようにDataFrame型はテーブル型のようなものであり,ExcelのシートやSQL databaseのテーブルと同じ構造をしている.さらに,DataFrameに対してdescribeという関数を用いることで,各列の要約統計量を知ることができる.以下は実際にpandasを読み込ませ,describe関数を用いるまでの流れである.
import pandas as pd
# 使いたいデータのパスを変数(melborn_file_path)に格納する.
melbourne_file_path = '../input/melbourne-housing-snapshot/melb_data.csv'
# 用いたいcsvファイルをread_csv関数で読み込んでそれをmelbourn_dataという名前のDataFrame型に格納している
melbourne_data = pd.read_csv(melbourne_file_path)
# melbourn_dataの要約統計量をdescribe関数で記述している.
melbourne_data.describe()
上のコードにおけるdescribe関数によって現れる要約統計量は以下のとおりである.
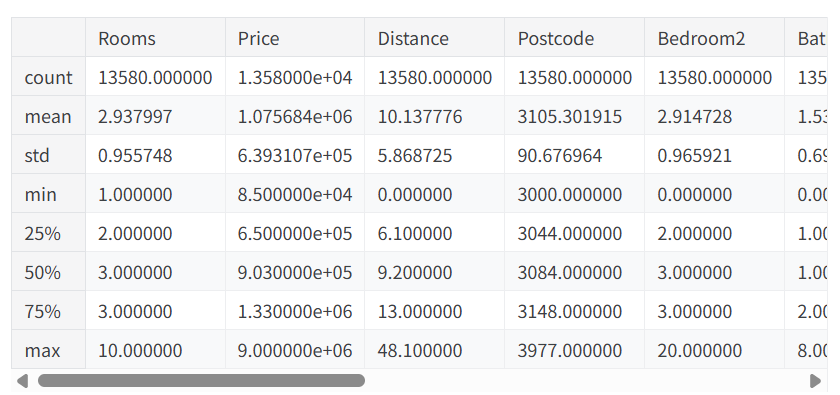
上のようにdescribe関数によって8つの統計量が出現していることが見て取れる.以下,それぞれ解説していく.
count
欠損値がないデータの数.例えば,上のDataFrameにはBedroom2という列が存在するが,この値は寝室が2つ以上存在する物件でなければ集計できないものであり,寝室が1つしか存在しない物件のデータでは,欠損値が存在することになる.以降の統計量では欠損値が存在していた場合,欠損値を無視して統計量を算出する.
mean
mean(平均値)のこと.
std
standard deviation(標準偏差)のこと
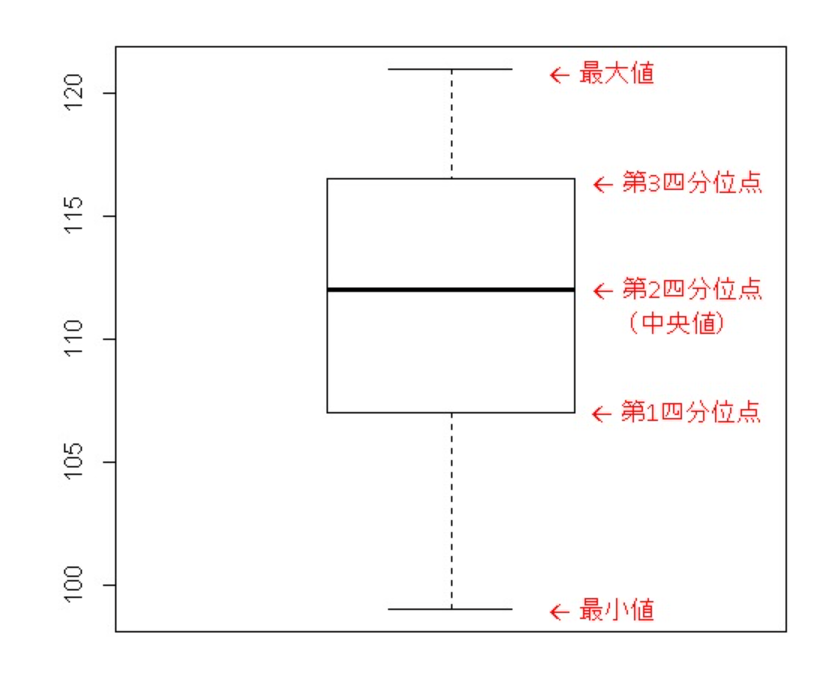
min,25%,50%,75%,max
いわゆる箱ひげ図における
min=最小値,25%=第1四分位点,50%=中央値,75%=第3四分位数,max=最大値 のことである.
Selecting Data for Modeling
このセクションでは学習させる前のデータの前処理と実際にモデルを構築する手法を述べていく.
データの前処理
まず,データには変数の数が多すぎる場合がある.例えば,以下のデータはSiganteというデータサイエンスのコンペの1つ(日本語のプラットフォームなので英弱はこれを使いがち)でJリーグの来場者数を予測する際に提供されたデータの一部である.
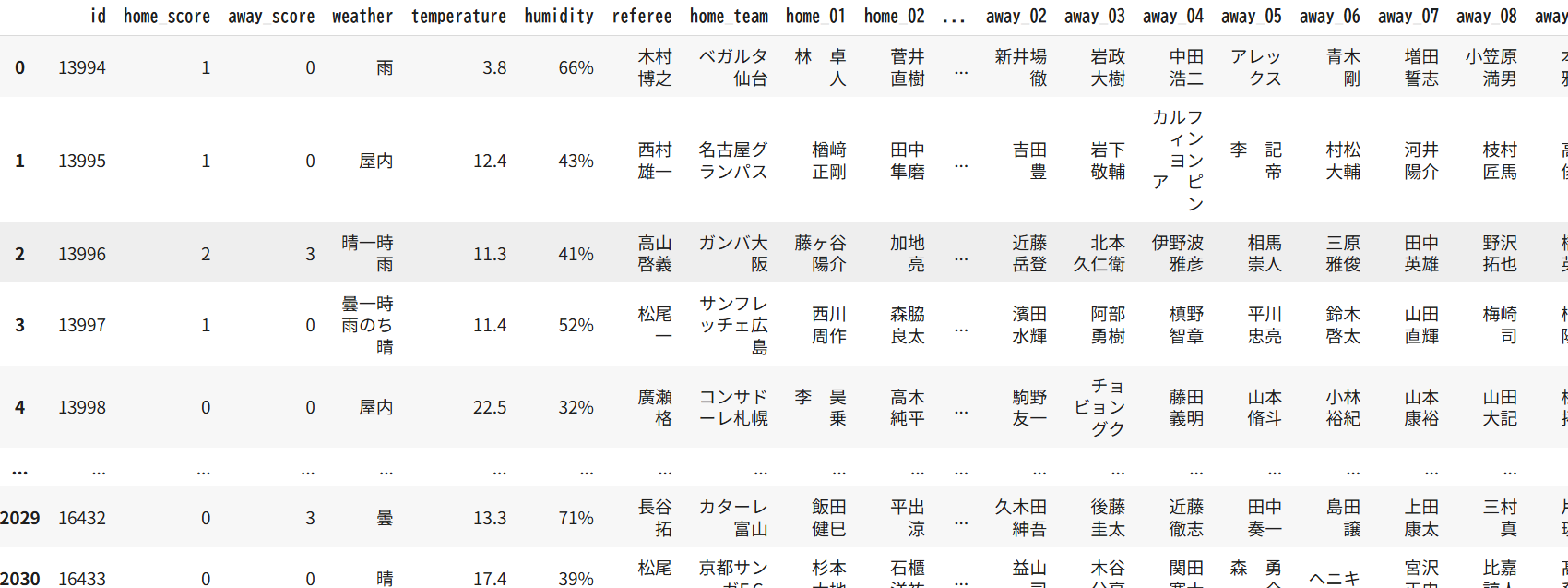
このデータにはホームとアウェイの全ての選手や審判が記載されており,データを予測する上での特徴量が多すぎることが見て取れる.そもそもあまりに多くの変数を学習させると過学習という現象が起こり,予測精度が落ちるとされているので予測精度という観点でも特徴量を減らすことが望ましい.そのため特徴量を順位付けして,順位が低い特徴量を振るい落とすことが必要となる.具体的な特徴量の順位付け方法は後述する.
また,データに欠損値が存在することもしばしば存在する.この場合,欠損値を補うためにいくつかの方法が存在する(その他のデータの中央値,平均値などで代替するなど)が,今回は欠損値が存在する時,その行(データ)を削除するという一番簡単な方法を紹介する.
dataframe_name.dropna(axis=0)
このコードはstadium_dataというDataFrame型のデータに対して,dropna(drop_not_available:利用不可のデータを削除する)という操作を行ったものであり,axis=0は横(行)方向に削除するという指令である.仮に,axis=1であるならば縦(列)方向に削除が起こってしまい,欠損値が存在する特徴量の列が全て消えてしまうので,注意.
データの特徴量を適切なサイズにして,欠損値を持つデータを処理したら,次にデータに存在する特徴量と目的変数(Jリーグの予想コンペでいうと,特徴量が天気,湿度,曜日etc..で目的変数が来場者数)をそれぞれ別に抽出する必要がある.
目的変数では,ドット記法が用いられる.
dataframe_name.column_name
というコードによりdataframe_nameというDataFrameのcolumn_nameという名前の特定の1列が選択され抽出される.ドット記法でデータはSeries型という1列のDataFrame型ともいうべき型として格納される.
次に,特徴量の抽出では,列のリストを使った選択が行われる.ここでは複数の特徴量を抽出するために,
dataframe_name[["特徴量A","特徴量B",...]]
というコードを用いて必要な特徴量を抽出している.全ての特徴量をここに盛り込んで学習⇒予測することもできるが,前述したように特徴量が多いために過学習を起こし予測精度が落ちることがしばしば起きるので注意.
ここまでで特徴量や目的変数が整理出来たら,
dataframe_name.head() #先頭5行を表示
dataframe_name.describe() #平均,分散,中央値などデータの分布を数値的に表示
dataframe_name.hist #ヒストグラムを描くことでデータの分布を可視化
上のコードのようにして,データの全体像を把握しよう.
モデル構築
モデル構築ではpythonのライブラリであり,DataFrameに格納されたデータをモデル化するのに最も便利なライブラリである「sklearn」が主に用いられる.
(sklearnの由来は,Scientific toolkit learn⇒Scikit learn⇒sklearn)
モデル構築は,
1.Define 2.Fit 3.Predict 4.Evaluate という4ステップで行う.
1.Define;モデルの種類を定義する.
まず,どのようなモデルでデータを予測するのかを定める.モデルの構築と一言で言っても,前述した決定木やそれを組み合わアンサンブル学習を行ったランダムフォレストをはじめ最小二乗法による線形回帰,ロジスティック回帰など様々なモデルが存在している.
ここでは同時にモデルの複雑さや学習方法を決定するハイパーパラメータを設定する.例えば,
dataframe_name = DecisionTreeRegressor(random_state=1)
というコードによって,dataframe_nameというDataFrameをDecisionTreeRegressor(回帰の決定木)によってモデリングすることができ,また,ハイパーパラメータであるrandom_stateをある値に設定することで,学習過程で内部的に乱数を使用する一般的なモデルと異なり,コードの実行毎に毎回同じ結果が返すように設定できる.
2.Fit;機械学習の「学習」を表す部分.モデルに学習用データ(特徴量x,目的変数y)を与えることで,データ内のパターンを学習させる.モデルのフィットには以下のように記述する
model.fit(x,y)
3.Predict;学習済みのモデルに新しいデータを与え,目的変数の値を予測させる.モデルを用いた目的変数の予想は以下のように記述する.
model.predict(x)
4.Evaluate;予測結果と実際の値を比べる.
以下は,回帰の決定木をモデルとしてDefineし,特徴量データX,目的変数データyを用いてmodel_newという名前のモデルをfitし,そのモデルを用いてXの先頭5行の値をpredictさせるコードである.
from sklearn.tree import DecisionTreeRegressor #DecisionTreeRegressorは回帰の決定木を示している
model_new = DecisionTreeRegressor(random_state=1) #random_stateというハイパーパラメータをある値に固定することでコードの実行毎に毎回同じ結果が返すように設定できる.
model_new.fit(X,y) #特徴量データX,目的変数データyを用いてモデルをfitさせる.
print(model_new.predict(X.head()) #Xの先頭5行のデータから導かれる目的変数を構築したモデルをもとにpredictする.
随時更新中